SVM入门——线性分类器的求解,核函数
一、问题的描述
从最一般的定义上说,一个求最小值的问题就是一个优化问题(也叫寻优问题,更文绉绉的叫法是规划——Programming),它同样由两部分组成,目标函数和约束条件,可以用下面的式子表示:
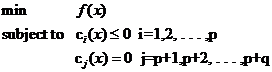 (式1)
(式1)
约束条件用函数c来表示,就是constrain的意思啦。你可以看出一共有p+q个约束条件,其中p个是不等式约束,q个等式约束。
关于这个式子可以这样来理解:式中的x是自变量,但不限定它的维数必须为1(视乎你解决的问题空间维数,对我们的文本分类来说,那可是成千上万啊)。要求f(x)在哪一点上取得最小值(反倒不太关心这个最小值到底是多少,关键是哪一点),但不是在整个空间里找,而是在约束条件所划定的一个有限的空间里找,这个有限的空间就是优化理论里所说的可行域。注意可行域中的每一个点都要求满足所有p+q个条件,而不是满足其中一条或几条就可以(切记,要满足每个约束),同时可行域边界上的点有一个额外好的特性,它们可以使不等式约束取得等号!而边界内的点不行。
关于可行域还有个概念不得不提,那就是凸集,凸集是指有这么一个点的集合,其中任取两个点连一条直线,这条线上的点仍然在这个集合内部,因此说“凸”是很形象的(一个反例是,二维平面上,一个月牙形的区域就不是凸集,你随便就可以找到两个点违反了刚才的规定)。
回头再来看我们线性分类器问题的描述,可以看出更多的东西。
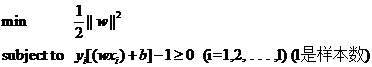 (式2)
(式2)
在这个问题中,自变量就是w,而目标函数是w的二次函数,所有的约束条件都是w的线性函数(哎,千万不要把xi当成变量,它代表样本,是已知的),这种规划问题有个很有名气的称呼——二次规划(Quadratic Programming,QP),而且可以更进一步的说,由于它的可行域是一个凸集,因此它是一个凸二次规划。
一下子提了这么多术语,实在不是为了让大家以后能向别人炫耀学识的渊博,这其实是我们继续下去的一个重要前提,因为在动手求一个问题的解之前(好吧,我承认,是动计算机求……),我们必须先问自己:这个问题是不是有解?如果有解,是否能找到?
对于一般意义上的规划问题,两个问题的答案都是不一定,但凸二次规划让人喜欢的地方就在于,它有解(教科书里面为了严谨,常常加限定成分,说它有 局最优解,由于我们想找的本来就是全局最优的解,所以不加也罢),而且可以找到!(当然,依据你使用的算法不同,找到这个解的速度,行话叫收敛速度,会有 所不同)
对比(式2)和(式1)还可以发现,我们的线性分类器问题只有不等式约束,因此形式上看似乎比一般意义上的规划问题要简单,但解起来却并非如此。
因为我们实际上并不知道该怎么解一个带约束的优化问题。如果你仔细回忆一下高等数学的知识,会记得我们可以轻松的解一个不带任何约束的优化问题(实际上就是当年背得烂熟的函数求极值嘛,求导再找0点呗,谁不会啊?笑),我们甚至还会解一个只带等式约束的优化问题,也是背得烂熟的,求条件极值,记得么,通过添加拉格朗日乘子,构造拉格朗日函数,来把这个问题转化为无约束的优化问题云云(如果你一时没想通,我提醒一下,构造出的拉格朗日函数就是转化之 后的问题形式,它显然没有带任何条件)。
读者问:如果只带等式约束的问题可以转化为无约束的问题而得以求解,那么可不可以把带不等式约束的问题向只带等式约束的问题转化一下而得以求解呢?
聪明,可以,实际上我们也正是这么做的。下一节就来说说如何做这个转化,一旦转化完成,求解对任何学过高等数学的人来说,都是小菜一碟啦。
二、问题的转化,直观视角
让我再一次比较完整的重复一下我们要解决的问题:我们有属于两个类别的样本点(并不限定这些点在二维空间中)若干,如图,
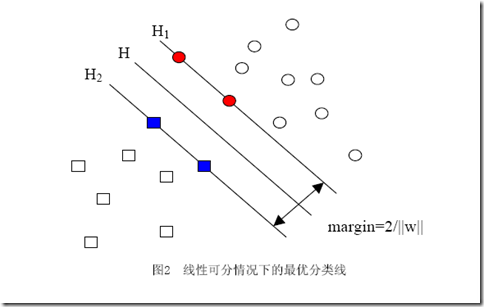
圆形的样本点定为正样本(连带着,我们可以把正样本所属的类叫做正类),方形的点定为负例。我们想求得这样一个线性函数(在n维空间中的线性函数):
g(x)=wx+b
使得所有属于正类的点x+代入以后有g(x+)≥1,而所有属于负类的点x-代入后有g(x-)≤-1(之所以总跟1比较,无论正一还是负一,都是因为我们固定了间隔为1,注意间隔和几何间隔的区别)。代入g(x)后的值如果在1和-1之间,我们就拒绝判断。
求这样的g(x)的过程就是求w(一个n维向量)和b(一个实数)两个参数的过程(但实际上只需要求w,求得以后找某些样本点代入就可以求得b)。因此在求g(x)的时候,w才是变量。
你肯定能看出来,一旦求出了w(也就求出了b),那么中间的直线H就知道了(因为它就是wx+b=0嘛,哈哈),那么H1和H2也就知道了(因为三 者是平行的,而且相隔的距离还是||w||决定的)。那么w是谁决定的?显然是你给的样本决定的,一旦你在空间中给出了那些个样本点,三条直线的位置实际 上就唯一确定了(因为我们求的是最优的那三条,当然是唯一的),我们解优化问题的过程也只不过是把这个确定了的东西算出来而已。
样本确定了w,用数学的语言描述,就是w可以表示为样本的某种组合:
w=α1x1+α2x2+…+αnxn
式子中的αi是一个一个的数(在严格的证明过程中,这些α被称为拉格朗日乘子),而xi是样本点,因而是向量,n就是总样本点的个数。为了方便描述,以下开始严格区别数字与向量的乘积和向量间的乘积,我会用α1x1表示数字和向量的乘积,而用<x1,x2>表示向量x1,x2的内积(也叫点积,注意与向量叉积的区别)。因此g(x)的表达式严格的形式应该是:
g(x)=<w,x>+b
但是上面的式子还不够好,你回头看看图中正样本和负样本的位置,想像一下,我不动所有点的位置,而只是把其中一个正样本点定为负样本点(也就是把一 个点的形状从圆形变为方形),结果怎么样?三条直线都必须移动(因为对这三条直线的要求是必须把方形和圆形的点正确分开)!这说明w不仅跟样本点的位置有 关,还跟样本的类别有关(也就是和样本的“标签”有关)。因此用下面这个式子表示才算完整:
w=α1y1x1+α2y2x2+…+αnynxn (式1)
其中的yi就是第i个样本的标签,它等于1或者-1。其实以上式子的那一堆拉格朗日乘子中,只有很少的一部分不等于0(不等 于0才对w起决定作用),这部分不等于0的拉格朗日乘子后面所乘的样本点,其实都落在H1和H2上,也正是这部分样本(而不需要全部样本)唯一的确定了分 类函数,当然,更严格的说,这些样本的一部分就可以确定,因为例如确定一条直线,只需要两个点就可以,即便有三五个都落在上面,我们也不是全都需要。这部 分我们真正需要的样本点,就叫做支持(撑)向量!(名字还挺形象吧,他们“撑”起了分界线)
式子也可以用求和符号简写一下:
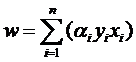
因此原来的g(x)表达式可以写为:
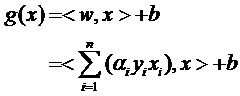
注意式子中x才是变量,也就是你要分类哪篇文档,就把该文档的向量表示代入到 x的位置,而所有的xi统统都是已知的样本。还注意到式子中只有xi和x是向量,因此一部分可以从内积符号中拿出来,得到g(x)的式子为:

发现了什么?w不见啦!从求w变成了求α。
但肯定有人会说,这并没有把原问题简化呀。嘿嘿,其实简化了,只不过在你看不见的地方,以这样的形式描述问题以后,我们的优化问题少了很大一部分不等式约束(记得这是我们解不了极值问题的万恶之源)。但是接下来先跳过线性分类器求解的部分,来看看 SVM在线性分类器上所做的重大改进——核函数。
三、为何需要核函数
生存?还是毁灭?——哈姆雷特
可分?还是不可分?——支持向量机
之前一直在讨论的线性分类器,器如其名(汗,这是什么说法啊),只能对线性可分的样本做处理。如果提供的样本线性不可分,结果很简单,线性分类器的 求解程序会无限循环,永远也解不出来。这必然使得它的适用范围大大缩小,而它的很多优点我们实在不原意放弃,怎么办呢?是否有某种方法,让线性不可分的数 据变得线性可分呢?
有!其思想说来也简单,来用一个二维平面中的分类问题作例子,你一看就会明白。事先声明,下面这个例子是网络早就有的,我一时找不到原作者的正确信息,在此借用,并加进了我自己的解说而已。
例子是下面这张图:
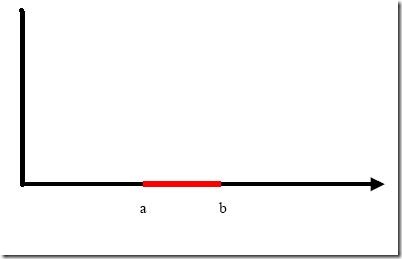
我们把横轴上端点a和b之间红色部分里的所有点定为正类,两边的黑色部分里的点定为负类。试问能找到一个线性函数把两类正确分开么?不能,因为二维空间里的线性函数就是指直线,显然找不到符合条件的直线。
但我们可以找到一条曲线,例如下面这一条:
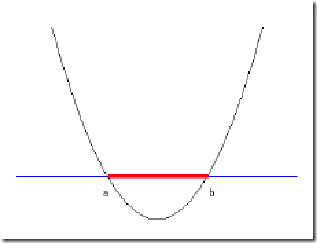
显然通过点在这条曲线的上方还是下方就可以判断点所属的类别(你在横轴上随便找一点,算算这一点的函数值,会发现负类的点函数值一定比0大,而正类的一定比0小)。这条曲线就是我们熟知的二次曲线,它的函数表达式可以写为:
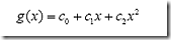
问题只是它不是一个线性函数,但是,下面要注意看了,新建一个向量y和a:
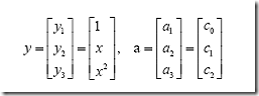
这样g(x)就可以转化为f(y)=<a,y>,你可以把y和a分别回带一下,看看等不等于原来的g(x)。用内积的形式写你可能看不太清楚,实际上f(y)的形式就是:
g(x)=f(y)=ay
在任意维度的空间中,这种形式的函数都是一个线性函数(只不过其中的a和y都是多维向量罢了),因为自变量y的次数不大于1。
看出妙在哪了么?原来在二维空间中一个线性不可分的问题,映射到四维空间后,变成了线性可分的!因此这也形成了我们最初想解决线性不可分问题的基本思路——向高维空间转化,使其变得线性可分。
而转化最关键的部分就在于找到x到y的映射方法。遗憾的是,如何找到这个映射,没有系统性的方法(也就是说,纯靠猜和凑)。具体到我们的文本分类问题,文本被表示为上千维的向量,即使维数已经如此之高,也常常是线性不可分的,还要向更高的空间转化。其中的难度可想而知。
小Tips:为什么说f(y)=ay是四维空间里的函数?大家可能一时没看明白。回想一下我们二维空间里的函数定义
g(x)=ax+b
变量x是一维的,为什么说它是二维空间里的函数呢?因为还有一个变量我们没写出来,它的完整形式其实是
y=g(x)=ax+b
即
y=ax+b
看看,有几个变量?两个。那是几维空间的函数?(作者五岁的弟弟答:五维的。作者:……)
再看看
f(y)=ay
里面的y是三维的变量,那f(y)是几维空间里的函数?(作者五岁的弟弟答:还是五维的。作者:……)
用一个具体文本分类的例子来看看这种向高维空间映射从而分类的方法如何运作,想象一下,我们文本分类问题的原始空间是1000维的(即每个要被分类的文档被表示为一个1000维的向量),在这个维度上问题是线性不可分的。现在我们有一个2000维空间里的线性函数
f(x’)=<w’,x’>+b
注意向量的右上角有个 ’哦。它能够将原问题变得可分。式中的 w’和x’都是2000维的向量,只不过w’是定值,而x’是变量(好吧,严格说来这个函数是2001维的,哈哈),现在我们的输入呢,是一个1000维的向量x,分类的过程是先把x变换为2000维的向量x’,然后求这个变换后的向量x’与向量w’的内积,再把这个内积的值和b相加,就得到了结果,看结果大于阈值还是小于阈值就得到了分类结果。
你发现了什么?我们其实只关心那个高维空间里内积的值,那个值算出来了,分类结果就算出来了。而从理论上说, x’是经由x变换来的,因此广义上可以把它叫做x的函数(有一个x,就确定了一个x’,对吧,确定不出第二个),而w’是常量,它是一个低维空间里的常量w经过变换得到的,所以给了一个w 和x的值,就有一个确定的f(x’)值与其对应。这让我们幻想,是否能有这样一种函数K(w,x),他接受低维空间的输入值,却能算出高维空间的内积值<w’,x’>?
如果有这样的函数,那么当给了一个低维空间的输入x以后,
g(x)=K(w,x)+b
f(x’)=<w’,x’>+b
这两个函数的计算结果就完全一样,我们也就用不着费力找那个映射关系,直接拿低维的输入往g(x)里面代就可以了(再次提醒,这回的g(x)就不是线性函数啦,因为你不能保证K(w,x)这个表达式里的x次数不高于1哦)。
万幸的是,这样的K(w,x)确实存在(发现凡是我们人类能解决的问题,大都是巧得不能再巧,特殊得不能再特殊的问题,总是恰好有些能投机取巧的地方才能解决,由此感到人类的渺小),它被称作核函数(核,kernel),而且还不止一个,事实上,只要是满足了Mercer条件的函数,都可以作为核函数。核函数的基本作用就是接受两个低维空间里的向量,能够计算出经过某个变换后在高维空间里的向量内积值。几个比较常用的核函数,俄,教课书里都列过,我就不敲了(懒!)。
回想我们上节说的求一个线性分类器,它的形式应该是:
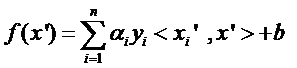
现在这个就是高维空间里的线性函数(为了区别低维和高维空间里的函数和向量,我改了函数的名字,并且给w和x都加上了 ’),我们就可以用一个低维空间里的函数(再一次的,这个低维空间里的函数就不再是线性的啦)来代替,
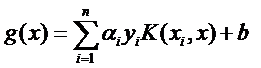
又发现什么了?f(x’)
和g(x)里的α,y,b全都是一样一样的!这就是说,尽管给的问题是线性不可分的,但是我们就硬当它是线性问题来求解,只不过求解过程中,凡是要求内积
的时候就用你选定的核函数来算。这样求出来的α再和你选定的核函数一组合,就得到分类器啦!
明白了以上这些,会自然的问接下来两个问题:
1. 既然有很多的核函数,针对具体问题该怎么选择?
2. 如果使用核函数向高维空间映射后,问题仍然是线性不可分的,那怎么办?
第一个问题现在就可以回答你:对核函数的选择,现在还缺乏指导原则!各种实验的观察结果(不光是文本分类)的确表明,某些问题用某些核函数效果很
好,用另一些就很差,但是一般来讲,径向基核函数是不会出太大偏差的一种,首选。(我做文本分类系统的时候,使用径向基核函数,没有参数调优的情况下,绝
大部分类别的准确和召回都在85%以上,可见。虽然libSVM的作者林智仁认为文本分类用线性核函数效果更佳,待考证)
对第二个问题的解决则引出了我们下一节的主题:松弛变量。
SVM入门——线性分类器的求解,核函数的更多相关文章
- 文本分类学习 (八)SVM 入门之线性分类器
SVM 和线性分类器是分不开的.因为SVM的核心:高维空间中,在线性可分(如果线性不可分那么就使用核函数转换为更高维从而变的线性可分)的数据集中寻找一个最优的超平面将数据集分隔开来. 所以要理解SVM ...
- SVM – 线性分类器
感知机 要理解svm,首先要先讲一下感知机(Perceptron),感知机是线性分类器,他的目标就是通过寻找超平面实现对样本的分类:对于二维世界,就是找到一条线,三维世界就是找到一个面,多维世界就是要 ...
- 2. SVM线性分类器
在一个线性分类器中,可以看到SVM形成的思路,并接触很多SVM的核心概念.用一个二维空间里仅有两类样本的分类问题来举个小例子.如图所示 和是要区分的两个类别,在二维平面中它们的样本如上图所示.中间的直 ...
- cs231n线性分类器作业 svm代码 softmax
CS231n之线性分类器 斯坦福CS231n项目实战(二):线性支持向量机SVM CS231n 2016 通关 第三章-SVM与Softmax cs231n:assignment1——Q3: Impl ...
- SVM中的线性分类器
线性分类器: 首先给出一个非常非常简单的分类问题(线性可分),我们要用一条直线,将下图中黑色的点和白色的点分开,很显然,图上的这条直线就是我们要求的直线之一(可以有无数条这样的直线) 假如说, ...
- 深度学习与计算机视觉系列(3)_线性SVM与SoftMax分类器
作者: 寒小阳 &&龙心尘 时间:2015年11月. 出处: http://blog.csdn.net/han_xiaoyang/article/details/49949535 ht ...
- 线性SVM与Softmax分类器
1 引入 上一篇介绍了图像分类问题.图像分类的任务,就是从已有的固定分类标签集合中选择一个并分配给一张图像.我们还介绍了k-Nearest Neighbor (k-NN)分类器,该分类器的基本思想是通 ...
- SVM入门
前言: 又有很长的一段时间没有更新博客了,距离上次更新已经有两个月的时间了.其中一个很大的原因是,不知道写什么好-_-,最近一段时间看了看关于SVM(Support Vector Machine)的文 ...
- 【转】SVM入门(一)SVM的八股简介
(一)SVM的八股简介 支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本.非线性及高维模式识别中表现出许多特有的优势,并能够 ...
随机推荐
- 【WEB前端开发最佳实践系列】JavaScript篇
一.养成良好的编码习惯,提高可维护性 1.避免定义全局变量和函数,解决全局变量而导致的代码“污染”最简单的额方法就是把变量和方法封装在一个变量对象上,使其变成对象的属性: var myCurrentA ...
- SpringBoot学习之Helloworld
1. 如果使用Spring开发一个"HelloWorld"的web应用 创建一个web项目并且导入相关jar包.SpringMVC Servlet 创建一个web.xml 编写一个 ...
- dirname的用法:获取文件的父级目录路径
命令:dirname 获取文件的路径(到父级目录)用法:dirname file_name [root@bogon opt]# a=$(dirname /mnt/a/b/c/d/a.sh) [root ...
- C语言位操作--不用中间变量交换两数值
1.使用加法与减法交换两数值: #define SWAP(a, b) ((&(a) == &(b)) || \ (((a) -= (b)), ((b) += (a)), ((a) = ...
- Docker 容器管理:rancher
Rancher:https://www.cnrancher.com/ 是一个开源的企业级全栈化容器部署及管理平台. 定位上和 K8s 比较接近,都是通过 web 界面赋予完全的 docker 服务编排 ...
- python nose测试框架全面介绍四
四.内部插件介绍 1.Attrib 标记,用于筛选用例 在很多时候,用例可以分不同的等级来运行,在nose中很增加了这个功能,使用attrib将用例进行划分 有两种方式: ef test_big_do ...
- jQuery 核心 - noConflict() 方法
1.遇到问题: 当我们写jquery时使用$,发现写的jquery全部失效: 2.发现问题: 排查后发现是noConflict()函数在作怪,因为使用noConflict()函数后,重新定义$名字为j ...
- Pyqt中富文本编辑器
对于文本编辑,qt提供了很多控件 QLineEdit:单行文本输入,比如用户名密码等简单的较短的或者具有单一特征的字符串内容输入.使用text.settext读写 QTextEdit:富文本编辑器,支 ...
- 天梯赛 大区赛 L3-014.周游世界 (Dijkstra)
L3-014. 周游世界 时间限制 200 ms 内存限制 65536 kB 代码长度限制 8000 B 判题程序 Standard 作者 陈越 周游世界是件浪漫事,但规划旅行路线就不一定了-- 全世 ...
- Tarjan-LCA算法小记
Tarjan-LCA算法是一种离线算法. 算法描述: DFS遍历每个节点,对于遍历到的当前节点u: ①建立以u为代表元素的集合. ②遍历与u相连的节点v,如果没有被访问过,对于v使用Tarjan-LC ...