SQL Server 调优系列玩转篇三(利用索引提示(Hint)引导语句最大优化运行)
前言
本篇继续玩转模块的内容,关于索引在SQL Server的位置无须多言,本篇将分析如何利用Hint引导语句充分利用索引进行运行,同样,还是希望扎实掌握前面一系列的内容,才进入本模块的内容分析。
闲言少叙,进入本篇的内容。
技术准备
数据库版本为SQL Server2012,利用微软的以前的案例库(Northwind)进行分析,部分内容也会应用微软的另一个案例库AdventureWorks。
相信了解SQL Server的朋友,对这两个库都不会太陌生。
一、并行Hint提示 (MAXDOP N Hint)
在当前多核超线程的今天,并行运算已经不算什么稀罕了,所以在SQL Server中也有它自己的并行运算符,来充分的利用现有硬件资源,最大限度的提升运行效率。
在本系列中有两篇文章专门介绍关于SQL Server的并行运算,可以点击查看:SQL Server并行运算总结、SQL Server并行运算总结篇二
所以,在Hint中也给出了关于并行运算的提示:MAXDOP N Hint,这个Hint还是经常用的,尤其索引操作的时候,为了缩短操作时间,我们常常会最大限度的利用并行运算。
另外,此Hint会优先于数据库级别的配置选项。也就说尽管在数据库中设置了MAXDOP 1(强制顺序运行),如果使用了此Hint也会忽略数据库设置的。
当然,并行运算虽然大部分情况能提升运行效率,但是也非绝对,我们知道多线程的操作是需要维护线程之间的数据交换和执行顺序等,所有有时候多线程的执行并不一定会单线程效率高。
来看个例子:

SELECT [KEY],[DATA]
FROM TestMaxDopTable
WHERE DATA<1000
OPTION(MAXDOP 1) SELECT [KEY],[DATA]
FROM TestMaxDopTable
WHERE DATA<1000
OPTION(MAXDOP 4)
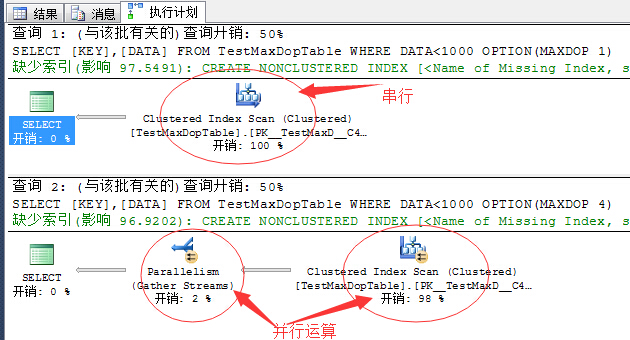
上面为串行运算,下面为4线程的并行运算。
当然,此处几线程运算可以自己设定,最大值推荐为当前系统配置的逻辑核数,当然设置大了也可以只不过没用罢了。
二、索引Hint提示 (INDEX Hint)
所谓的索引Hint提示,就是强制查询优化器为一个查询语句执行扫描或者使用一个指定的索引。
此方式,是我们在调优中经常用到的一种方式,很多时候我们创建的索引是失效的,当然,大部分情况下失效的原因是创建索引不妥当导致的,但是有一些情况下,需要我们来指导下T-SQL的运行方式,这时候就是索引Hint的使用场景了。
当然,这里能利用索引提示的前提就是当前表存在索引了,如果是堆表的情况,根本就谈不上了索引提示了,只能通过表扫描获取数据了。
来看看这个提示的用法:WITH(INDEX(N))
这里的N就是索引的在该表中索引顺序排序号了,来看一张表中的索引序列号:
SELECT * FROM SYS.indexes
WHERE OBJECT_NAME(object_id)='Orders'
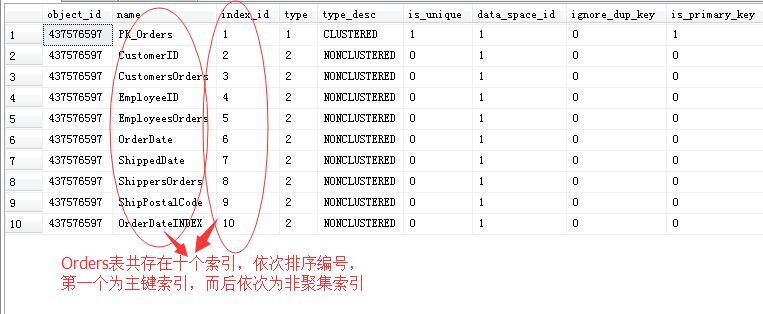
可以看到,该表中存在十个索引,依次排序之后,就是从1至10,第一个就是聚集索引(主键)了,然后是非聚集索引。
所以,我们上面的N的值就是这个数字了,指定几就是要求用哪个索引了。
来看个脚本:
SELECT OrderID,CustomerID
FROM Orders WITH(INDEX(1))
WHERE ShipPostalCode=N'99362' SELECT OrderID,CustomerID
FROM Orders WITH(INDEX(9))
WHERE ShipPostalCode=N'99362'
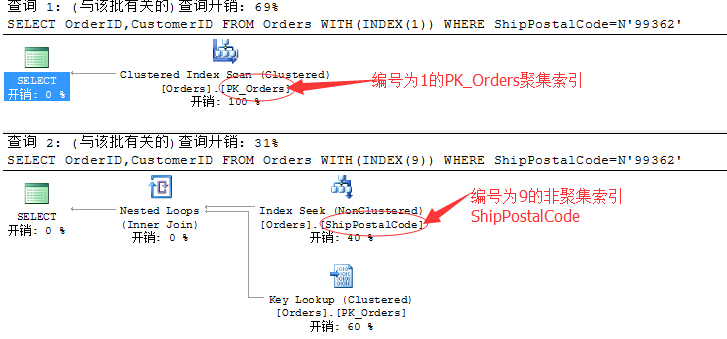
看到了,上面的例子中我们选了两个索引:一个编号1的聚集索引PK_Orders,一个编号为9的非聚集索引了ShipPostalCode。当然,有兴趣也可以玩玩其它几个索引。
我们顺便来分析下这个语句的索引用法:
首先从查询条件来看,我们是根据ShipPostalCode进行查询,所以最好在该列中被索引所覆盖,这样在数据量大的情况下,查询优化器就可以采用索引查找(Index Seek)了,所以,这里我们选择了第9个非聚集索引,恰巧覆盖该列值,从上面的查询计划也可以看出,采用该索引Hint提示后查询开销从69%提升至3%...但是由于这个非聚集索引没有包含CustomerID列,所以不得不又引入书签查找(key Lookup)来获取该列值,并且这个书签查找消耗还比较大:60%,所以最佳的方式就是将该索引Include进CustomerID列。
当然,此方式用起来可能很不爽,因为我们在使用的时候需要查找当前表中的各个索引的排序号。
所以,我们最推荐也是最常用的方式是这样:
WITH(INDEX('IndexName'))
就是我们直接指定索引名称既可以,来看个例子:
SELECT OrderID,CustomerID
FROM Orders WITH(INDEX(CustomersOrders))
WHERE ShipPostalCode=N'99362'
看起来,简单的多了,因为索引的名字我们直接能看到,来看看我们将这个查询语句指定到这个非聚集索引CustomersOrders上的执行计划。
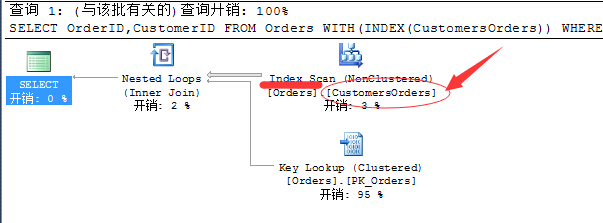
来看看这个查询计划:丫的!.....查询开销直接飙升到100%......原因很简单:这个非聚集索引和这个查询一毛钱关系....但是我们却强制的指定该语句利用索引执行....
首先非聚集索引包含的列为:[OrderID],[CustomerID]
我们要获取的值为按照ShipPostalCode进行筛选,所以要获取结果就必须按照这个非聚集索引进行一次扫描(Index Scan),这个还可以,毕竟非聚集索引都是有序进行的,但是为了进行过滤,就必须引入书签查找(Key Lookup)进行过滤,我们知道书签查找为随机IO,消耗巨大,所以这次过滤就好比在整张表中随机的去查找数据一样,其实效率还不如来一次表扫描(Table Scan)的好,所以此开销飙升到95%!
上面的例子,也是很多新手容易犯的错误。
我记得在玩转模块的第一篇中,我们提到过一个利用OPTIMIZE FOR Hint提示 解决一个引入参数而导致的执行计划评估不准的问题。
文章可以点击此处看到:SQL Server调优系列玩转篇(如何利用查询提示(Hint)引导语句运行)
我们来回顾下:
--普通的查询语句
SELECT OrderID,OrderDate
FROM Orders
WHERE ShipPostalCode=N'51100' --参数化后的查询语句
DECLARE @ShipPostalCode NVARCHAR(50)
SET @ShipPostalCode=N'51100'
SELECT OrderID,OrderDate
FROM Orders
WHERE ShipPostalCode=@ShipPostalCode
完全相同逻辑的查询语句,只是下面那个我们通过参数进行了传值操作。 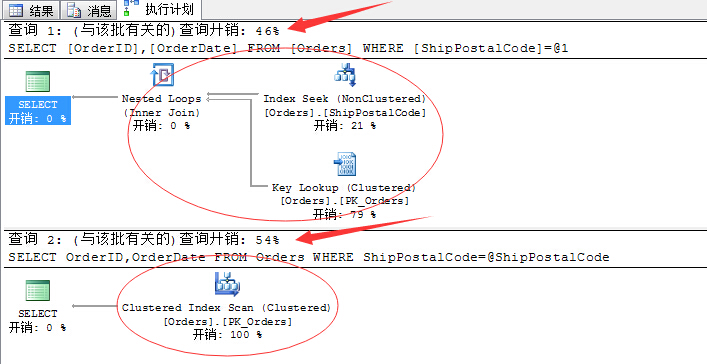
我们只是加了一个参数,SQL Server将相同的查询语句,有以前的索引查找变成了索引扫描了!
消耗一下子从46%提升到54%.....这也是我们写的语句经常遇到的问题,因为很多情况下,我们都是通过传参来实现该语句的重用性。
但是,为什么加了参数使得查询性能变差,显然不是一个好的方式,在第一篇的玩转篇中,我们的解决方式是通过OPTIMIZE FOR Hint提示解决。
这里,我们再来看一个解决方式,也可以通过索引Hint来强制该语句指定按照给定的索引进行查找。
方法如下:
--参数化后的查询语句
DECLARE @ShipPostalCode NVARCHAR(50)
SET @ShipPostalCode=N'51100'
SELECT OrderID,OrderDate
FROM Orders WITH(INDEX(ShipPostalCode))
WHERE ShipPostalCode=@ShipPostalCode
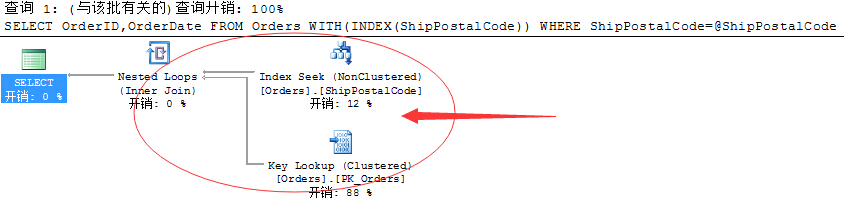
是不是一个很帅的方式。
希望你能理解这些个方式的好处,算作抛砖引玉了。
结语
此篇文章先到此吧,到此玩转篇已经三篇了,关于SQL Server调优工具Hint的使用还有很多内容,后续依次介绍,有兴趣的童鞋可以提前关注。
有问题可以留言或者私信,随时恭候有兴趣的童鞋加入SQL SERVER的深入研究。共同学习,一起进步。
SQL Server 调优系列玩转篇三(利用索引提示(Hint)引导语句最大优化运行)的更多相关文章
- SQL Server调优系列玩转篇三(利用索引提示(Hint)引导语句最大优化运行)
前言 本篇继续玩转模块的内容,关于索引在SQL Server的位置无须多言,本篇将分析如何利用Hint引导语句充分利用索引进行运行,同样,还是希望扎实掌握前面一系列的内容,才进入本模块的内容分析. 闲 ...
- SQL Server调优系列玩转篇二(如何利用汇聚联合提示(Hint)引导语句运行)
前言 上一篇我们分析了查询Hint的用法,作为调优系列的最后一个玩转模块的第一篇.有兴趣的可以点击查看:SQL Server调优系列玩转篇(如何利用查询提示(Hint)引导语句运行) 本篇继续玩转模块 ...
- SQL Server 调优系列玩转篇二(如何利用汇聚联合提示(Hint)引导语句运行)
前言 上一篇我们分析了查询Hint的用法,作为调优系列的最后一个玩转模块的第一篇.有兴趣的可以点击查看:SQL Server调优系列玩转篇(如何利用查询提示(Hint)引导语句运行) 本篇继续玩转模块 ...
- SQL Server调优系列玩转篇(如何利用查询提示(Hint)引导语句运行)
前言 前面几篇我们分析了关于SQL Server关于性能调优的一系列内容,我把它分为两个模块. 第一个模块注重基础内容的掌握,共分7篇文章完成,内容涵盖一系列基础运算算法,详细分析了如何查看执行计划. ...
- SQL Server 调优系列玩转篇一(如何利用查询提示(Hint)引导语句运行)
前言 前面几篇我们分析了关于SQL Server关于性能调优的一系列内容,我把它分为两个模块. 第一个模块注重基础内容的掌握,共分7篇文章完成,内容涵盖一系列基础运算算法,详细分析了如何查看执行计划. ...
- SQL Server调优系列基础篇
前言 关于SQL Server调优系列是一个庞大的内容体系,非一言两语能够分析清楚,本篇先就在SQL 调优中所最常用的查询计划进行解析,力图做好基础的掌握,夯实基本功!而后再谈谈整体的语句调优. 通过 ...
- SQL Server调优系列基础篇(常用运算符总结——三种物理连接方式剖析)
前言 上一篇我们介绍了如何查看查询计划,本篇将介绍在我们查看的查询计划时的分析技巧,以及几种我们常用的运算符优化技巧,同样侧重基础知识的掌握. 通过本篇可以了解我们平常所写的T-SQL语句,在SQL ...
- SQL Server调优系列基础篇(联合运算符总结)
前言 上两篇文章我们介绍了查看查询计划的方式,以及一些常用的连接运算符的优化技巧,本篇我们总结联合运算符的使用方式和优化技巧. 废话少说,直接进入本篇的主题. 技术准备 基于SQL Server200 ...
- SQL Server调优系列基础篇(并行运算总结)
前言 上三篇文章我们介绍了查看查询计划的方式,以及一些常用的连接运算符.联合运算符的优化技巧. 本篇我们分析SQL Server的并行运算,作为多核计算机盛行的今天,SQL Server也会适时调整自 ...
随机推荐
- Online Judge 2014 K-th Number -主席树
You are working for Macrohard company in data structures department. After failing your previous tas ...
- LightOJ 1199 Partitioning Game(sg函数)题解
题意:可以把一堆石子分成不相等的两堆,不能操作为败 思路:把一个石子拆成两个,变成了两个独立的游戏,mex里加上两者的sg异或.sg打表. 代码: #include<set> #inclu ...
- keepalived主从及双主配置
高可用有2中方式. 1.Nginx+keepalived 主从配置 这种方案,使用一个vip地址,前端使用2台机器,一台做主,一台做备,但同时只有一台机器工作,另一台备份机器在主机器不出现故障的时候, ...
- SQLSERVER 内存占用高的处理方式
https://www.cnblogs.com/srsrd/p/6962982.html 方法一: 方法二: 使用以下语句查找出什么语句占内存最高,针对占内存高的语句进行优化SELECT SS.SUM ...
- MongoDB树形结构表示法
http://docs.mongodb.org/manual/tutorial/model-tree-structures/ MongoDB五种树形结构表示法 第一种:父链接结构 db.categor ...
- Jmeter性能测试之一 性能测试的流程和步骤介绍
Step1: 知道在架构上,你要做的性能测试要cover几个部分,如下图,性能测试从用户角度,PC端之后都要要考虑进行的,例如网络,app server,Database等等 N1+N2+N3+N4 ...
- VS2010_x86_编译错误
1.两个头文件 相互include 报出来的错误,没有直接说是 嵌套include,而是这个现象: error: C4430: 缺少类型说明符 - 假定为 int.注意: C++ 不支持默认 int ...
- node 文件、文件夹 增删改查
1. 文件夹 增加文件夹 var fs = require("fs"); console.log("创建目录 tmp"); fs.mkdir("tmp ...
- Java的八种基本类型:(按字节来分)
Java的八种基本类型:(按字节来分) boolean 布尔型 1个字节 8bit(8位) byte 字节类型 1个字节 char 字符类型 2个字节 short ...
- Shell需注意的语法问题
1.文件头声明别漏掉#和! #!/bin/bash 2.赋值语句①=号两端不能有空格(判断语句=号两端必须有空格)②使用变量必须使用符号$ var1=valecho $var1 3.if语句写错下面任 ...