大数据开发实战:MapReduce内部原理实践
下面结合具体的例子详述MapReduce的工作原理和过程。
以统计一个大文件中各个单词的出现次数为例来讲述,假设本文用到输入文件有以下两个:
文件1:
big data
offline data
online data
offline online data
文件2
hello data
hello online
hello offline
目标是统计这两个文件中各个单词的出现次数,很容易用肉眼算出各个词出现的次数:
big:1
data:5
offline:3
online:3
hello:3
但是想象一下,如果是数以百万级的文献资料,每个文献资料数以十万字或百万字计,还能用肉眼算吗?而这正是Hadoop擅长的,对应Hadoop来说只需要定义简单的Map逻辑和Reduce逻辑,然后把输入文件和处理逻辑提交
给Hadoop即可,Hadoop将会自动完成所有的分布式计算任务。
1、MapReduce逻辑开发
Hadoop开发人员需要定义Map逻辑和Reduce逻辑,下面用伪代码来描述词频统计具体的Map逻辑和Reduce逻辑。
词频统计任务的Map逻辑为:
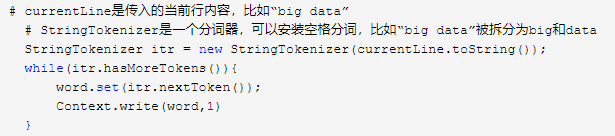
以上述实例文件1为例,上述Map逻辑执行后,将会输出:
big:1
data:1
offline:1
data:1
online:1
data:1
offline:1
online:1
data:1
Hadoop的shuffle过程会把Map任务的输出组织成<word,{1,1,1,1....}形式的数据并输入给Reduce任务,然后Reduce任务会对这种形式的数据执行Reduce逻辑,相应的Reduce逻辑为:

至此,所有Map代码和Reduce代码都完成了,将此代码打包并提及给Hadoop执行即可。
2、MapReduce任务提交详解
从大数据开发实战:HDFS和MapReduce优缺点分析的MapReduce架构可以看出,MapReduce作业执行主要由JobTrackerTaskTracker负责完成。
客户端编写好的MapReduce程序并配置好的MapReduce作业是一个Job,Job被提交给JobTracker后,JobTracker会给该Job一个新的ID值,接着检查该Job指定的输出目录是否存在、输入文件是否存在,
如果不存在,则抛出错误。同时,JobTracker会根据输入文件计算输入分片(input split),这些都检查通过后,JobTracker就会配置Job需要的资源并分配资源,然后JobTracker就会初始化作业,
也就是将Job放入一个内部的队列,让配置好的作业调度器能调度这个作业,作业调度器会初始化这个Job,初始化就是创建一个正在执行的Job对象(封装任务和记录信息),以便JobTracker 跟踪Job的状态和进程。
该Job被作业调度器调度时,作业调度器会获取输入分片信息,每个分片创建一个Map任务,并根据TaskTracker的忙闲情况和空闲资源等分配Map任务和Reduce任务到TaskTracker,同时通过心跳机制也可以监控到TaskTracker
的状态和进度,也能计算出整个Job的状态和进度。当JobTracker获得最后一个完成指定任务的TaskTracker操作成功通知的时候,JobTracker会把整个Job状态置为成功,然后当查询Job运行状态时(注意:这是个异步操作),客户端
会查到Job完成的通知。如果job中途失败,MapReduce也会有相应的机制处理。一般而言,如果不是程序员程序本身有bug,MapReduce错误处理机制都能保证提交的Job能正常完成。
3、MapReduce内部执行原理详解
那么,MapReduce到底是如何运行的呢? 按照时间顺序,MapReduce任务执行包括:输入分片Map、Shuffle和Reduce等阶段,一个阶段的输出正好是下一个阶段的输入,上述各个阶段的关系和流程如下:
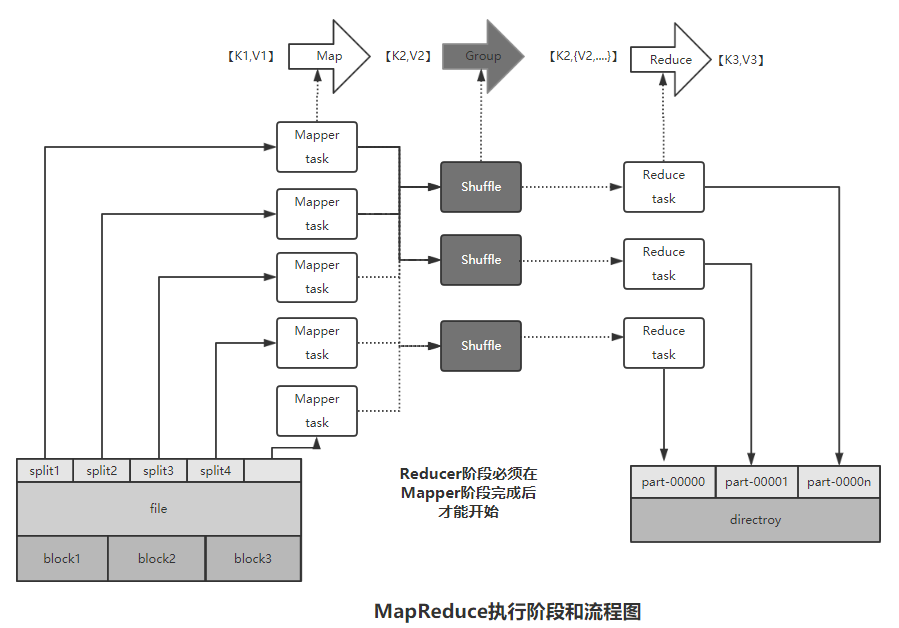
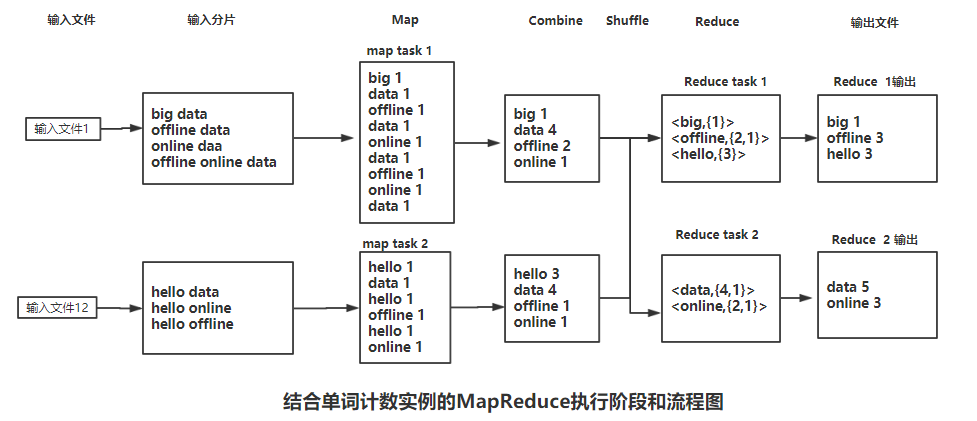
下面结合上文的实例问更加深入和详细地介绍上述过程,如下图:
4、各环节介绍
4.1、输入分片
在进行Map计算之前,MapReduce会根据输入文件计算输入分片。每个输入分片对应一个Map任务,输入分片存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组。输入分片往往和HDFS和block(块)
关系密切,假如设定的HDFS的块的大小是64MB,如果输入只有一个150MB,那么MapReduce会把此大文件切分为三片(分别为:64MB、64MB和22MB),同样,如果输入为两个文件,其大小分别是22MB和100MB,那么
MapReduce会把20MB文件作为一个输入分片,100MB则切分为两个即64MB和36MB的输入分片。对于上述实例文件1和文件2,由于非常小,因此分别被作为split1和split2输入Map任务1和2中(此处只为说明问题,实际处理
中应该将小文件进行合并,否则如果输入多个文件而且文件大小均远小于块大小,会导致生成多个不必要的Map任务,这也是MapReduce优化计算的一个关键点)。
4.2、Map阶段
在Map阶段,各个Map任务会接收到所分配的split,并调用Map函数,逐行执行并输出键值。比如对于上面的例子,map task1 将会接收到input split1,并调用Map函数,其输出如下的键值对:
big 1, data 1, offline 1, data 1, online 1, data 1, offline 1, online 1, data 1
4.3、Combiner 阶段
Combiner 阶段是可选的的,Combiner其实也是一种Reduce操作,但它是一个本地化的Reduce操作,是Map运算的本地后续操作,主要是在Map计算出中间文件前做的一个简单的合并重复键值的操作,
例如上述文件1中data出现了4次,Map计算时如果碰到一个data的单词就会记录1,这样就重复了4次,Map任务输出就有冗余,这样后续处理和网络传输都被消耗不必要的资源,一次通过Combiner操作可以解决和
优化次问题。但这一操作是有风险的,使用它的原则是Combiner的输出不会影响到Reduce 计算的的最终输入,例如,如果计算只是求总数、最大值及最小值,可以用Combiner操作,但是如果做平均值计算使用Combiner,
最终Reduce计算结果就会出错。
4.4、Shuffle阶段
Map任务的输出必须经过一个名叫Shuffle的阶段才能交给Reduce处理。Shuffle阶段是MapReduce的核心,也是奇迹发生的地方,同时Shuffle阶段的性能直接影响整个MapReduce的性能。
那什么是Shuffle呢?一般理解为数据从Map Task输出到Reduce Task输入的过程,它决定了Map Task的输出如何且高效第传输给Reduce Task。
总的来说,Shuffle阶段包含在Map和Reduce两个阶段中,在Map阶段的Shuffle阶段是对Map的结果进行分区(partition)、排序(sort)和分隔(spill),然后将同一分区的输出合并在一起(merge)并写在磁盘上,同时按照不同的
分区划分发送给对应的Reduce(Map输出的划分和Reduce任务的对应关系由JobTracker确定)的整个过程;Reduce阶段的Shuffle又会将各个Map输出的同一个分区划分的输出进行合并,然后对合并的结果进行排序,最后交给
Reduce处理的整个过程。
下面从Map和Reduce两端详细介绍Shuffle阶段。
4.4.1、Map阶段Shuffle
通常MapReduce计算的都是海量数据,而且Map输出还需要对结果进行排序,内存开销很大,因此完全在内存中完成是不可能的也是不现实的,所以Map输出时会在内存里开启一个环形内存缓存区,并且在配置文件里为
这个缓存区设置了一个阀值(默认是80%,可以自定义修改此配置)。同时,Map还为输出操作启动了一个守护线程,如果缓存区的内存使用达到了阀值,那么这个守护线程就会把80%的内存区内容写到磁盘上,这个过程叫分隔
(spill),另外的20%内存可以供Map输出继续使用,写入磁盘和写入内存操作是互不干扰的,如果缓存区被撑满了,那么Map就会阻塞写入内存的操作,待写入磁盘操作完成后再继续执行写入内存操作。
缓存区内容分隔到磁盘前,会首先进行分区操作,分区的数目由Reduce的数目决定。对应本例,Reduce的数目为2个,那么分区数就是2个,然后对每个分区,后台线程还会按照键值对需要写出的数据进行排序,如果配置了
Combiner函数,还会进行Combiner操作,以使得更少地数据被写入磁盘并发送给Reducer。
每次的分隔操作都会生成一个分隔文件,全部的Map输出完成后,可能会有很多的分隔文件,因此在map 任务结束前,还要进行合并操作,即将这些分隔文件按照分区合并为单独的文件。在合并过程中,同样也会进行排序,
如果定义了Combiner,也会进行Combiner操作。
至此,Map阶段的所有工作都已经结束,最终生成的文件也会存放在TaskTracker能访问的某个本地目录内。每个Reduce Task不断地从JobTracker那里获取Map Task是否完成的信息,如果Reduce task得到通知,获知某台
TaskTracker上的Map Task执行完成,Shuffle的后半段过程,也就是Reduce阶段的Shuffle,便开始启动。
4.4.2、Reduce阶段Shuffle
Shuffle 在Reduce阶段可以分为三个阶段:Copy Map输出、Merge阶段和Reduce处理。
1、Copy Map输出:
如上文所述,Map任务完成后,会通知TaskTracker状态已完成,TaskTracker进而通知JobTracker(这些通知一般通过心跳机制完成)。对Job来说,JobTracker记录了Map输出和TaskTracker的映射关系,同时
Reduce也会定期向JobTracker获取Map的输出与否以及输位置,一旦拿到输出位置Reduce就会启动Copy线程,通过HTTP方式请求Mask Task所在的TaskTracker获取其输出文件。因为Map Task早已结束,这些文件就被TaskTracker
存储在Map Task所在的本地磁盘中。
2、Merge阶段:
此处的合并和Map阶段的合并类似,复制过来的数据会首先放入内存缓存区中,这里的内存缓存区比Map阶段的要灵活很多,它基于JVM的heap size设置,因为Shuffle阶段Reduce task并不运行,因此大部分内存
应该给Shuffle使用;同时此Shuffle的合并阶段根据要处理的数据量的不同,也可能会有分隔到磁盘的过程,如果设置了Combiner函数,Combiner操作也会执行。
从Map阶段的Shuffle过程到Reduce阶段的Shuffle过程,都提到了合并,那么合并究竟是怎样的呢?如上面的例子,Map Task1对于offline的键值是2,而Map Task2的offline键值是1,那么合并就是将offline的键值合并为group,
本例即为:<offline,{2,1}>。
3、Reduce Task的输入:
不到合并后,最后会生成一个最终结果(可能在内存,也可能在磁盘),至此,Reduce Task的输入准备完毕,下一步就是真正的Reduce操作。
4.5、Reduce阶段
经过Map和Reduce阶段的Shuffle过程后,Reduce任务的输入的准备完毕,相关的数据已经被合并和汇总,Reduce任务只需要调用Reduce函数即可,对于本例即对每个键,调用sum逻辑合并value并输出到HDFS即可,比如对于
Reduce Task1的offline的键,只需要将集合{2,1}相加,输出offline 3即可。
至此,整个MapReduce的详细流程和原理介绍完毕,从上述过程中,Shuffle是整个流程中最为核心的部分,也是最复杂的部分。
参考资料:《离线和实时大数据开发实战》
大数据开发实战:MapReduce内部原理实践的更多相关文章
- 大数据开发实战:HDFS和MapReduce优缺点分析
一. HDFS和MapReduce优缺点 1.HDFS的优势 HDFS的英文全称是 Hadoop Distributed File System,即Hadoop分布式文件系统,它是Hadoop的核心子 ...
- 大数据开发实战:Spark Streaming流计算开发
1.背景介绍 Storm以及离线数据平台的MapReduce和Hive构成了Hadoop生态对实时和离线数据处理的一套完整处理解决方案.除了此套解决方案之外,还有一种非常流行的而且完整的离线和 实时数 ...
- 大数据开发实战:Storm流计算开发
Storm是一个分布式.高容错.高可靠性的实时计算系统,它对于实时计算的意义相当于Hadoop对于批处理的意义.Hadoop提供了Map和Reduce原语.同样,Storm也对数据的实时处理提供了简单 ...
- 大数据开发实战:Hive优化实战1-数据倾斜及join无关的优化
Hive SQL的各种优化方法基本 都和数据倾斜密切相关. Hive的优化分为join相关的优化和join无关的优化,从项目的实际来说,join相关的优化占了Hive优化的大部分内容,而join相关的 ...
- 大数据开发实战:离线大数据处理的主要技术--Hive,概念,SQL,Hive数据库
1.Hive出现背景 Hive是Facebook开发并贡献给Hadoop开源社区的.它是建立在Hadoop体系架构上的一层SQL抽象,使得数据相关人员使用他们最为熟悉的SQL语言就可以进行海量数据的处 ...
- 大数据开发实战:Stream SQL实时开发二
1.介绍 本节主要利用Stream SQL进行实时开发实战,回顾Beam的API和Hadoop MapReduce的API,会发现Google将实际业务对数据的各种操作进行了抽象,多变的数据需求抽象为 ...
- 大数据开发实战:Stream SQL实时开发一
1.流计算SQL原理和架构 流计算SQL通常是一个类SQL的声明式语言,主要用于对流式数据(Streams)的持续性查询,目的是在常见流计算平台和框架(如Storm.Spark Streaming.F ...
- 大数据开发实战:Hive表DDL和DML
1.Hive 表 DDL 1.1.创建表 Hive中创建表的完整语法如下: CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [ (col_nam ...
- 大数据开发实战:Stream SQL实时开发三
4.聚合操作 4.1.group by 操作 group by操作是实际业务场景(如实时报表.实时大屏等)中使用最为频繁的操作.通常实时聚合的主要源头数据流不会包含丰富的上下文信息,而是经常需要实时关 ...
随机推荐
- HDU 5908 Abelian Period 暴力
Abelian Period 题目连接: http://acm.hdu.edu.cn/showproblem.php?pid=5908 Description Let S be a number st ...
- ibatis的缓存机制
Cache 在特定硬件基础上(同时假设系统不存在设计上的缺漏和糟糕低效的SQL 语句)Cache往往是提升系统性能的最关键因素). 相对Hibernate 等封装较为严密的 ...
- Android笔记(一):this 的表示范围和 Context
this 的表示范围 this 指的是它所在的直接所在的类. 例如: public class MyClass{ int num; public MyClass(int num){ this.num ...
- 性能优化:使用SparseArray代替HashMap<Integer,Object>(转)
HashMap是java里比较常用的一个集合类,我比较习惯用来缓存一些处理后的结果.最近在做一个Android项目,在代码中定义这样一个变量,实例化时,Eclipse却给出了一个 performanc ...
- POJ 2337 Catenyms (有向图欧拉路径,求字典序最小的解)
Catenyms Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 8756 Accepted: 2306 Descript ...
- setInterval设置停止和循环
原文链接:http://caibaojian.com/setinterval-times.html 需要知道已经经过了多少次或者说过多久就会停止 var timesRun = 0; var inter ...
- SQL Server 2000 绿色精简版gsql适用于xp/win7/win8/win10
老的程序员肯定都用过sql2000数据库,我在2006-2010年之间,做的不少网站也都是sql2000数据库的,但是后来随着mysql的兴起,就逐渐不再使用sql数据库了.但是最近有个客户的网站要修 ...
- 在Visual Studio中使用活动图描述业务流程
当希望描述某个流程的时候,用活动图表示. 在项目中添加一个名称为"Shopping"的文件夹. 把"Orders Model"这个UML类图拖放到Shoppin ...
- CLR是如何被加载并工作的
当运行Windows应用程序的时候,CLR总是默默地为服务着.CLR到底是如何被加载并运行呢? 首先,Microsoft专门为CLR定义了一个标准的COM接口. 安装某个版本的.NET Framewo ...
- C#判断字符串的是否是汉字
//第一种方法:正则表达式 private bool IsChinese(string Text) { ; i < Text.Length; i++) { if (Regex.IsMatch(T ...