Lucene系列一:搜索引擎核心理论
一、为什么需要搜索引擎
问题1:数据库索引的原理是怎样的?
索引原理:对列值创建排序存储,数据结构={列值、行地址}。在有序数据列表中就可以利用二分查找快速找到要查找的行的地址,再根据地址直接取行数据。
问题2:索引的排序,是怎么排的?
数值列
时间列
文本列
问题3:在新闻标题列上建索引,当我们查询 标题 = ‘钓鱼岛’,数据库会怎么去查? 而当我们查询 标题 LIKE ‘%钓鱼岛%’ ,数据库该如何去查?
Like 时索引失效,全表扫描,数据量大时是噩梦。
问题4:在数据库中如何判断一个列是否可以建索引?
基本原则:
表经常被访问,且数据量很大,而每次查询的数据只占很小很小一部分
列的数据值分布范围广泛
列中包含大量空值
列被经常用在查询条件中(不能是包含在表达式中)
注意:文本列需特殊考虑:经常是用作模糊查询,则不适合建索引。精确查询则可。
问题5:如果要对查询出来的结果进行相关度排名,数据库能否做到?
如:要查询 苍老师、tony、火锅有关的新闻:
含有三个关键字(相关度最高)的新闻排前面
含两个关键字(相关度次之),排次之
含一个关键字 的,排次次之。
如果要对搜索的新闻字段设置不同的权重,比如新闻标题中包含这三个关键字的新闻的相关性就远高于新闻内容中包含这三个字。数据库能否做到?
答案:做不到,这个时候就需要搜索引擎了
问题6:常见的数据结构有哪些?
结构化数据: 用表、字段表示的数据
半结构化数据: xml 、html
非结构化数据: 文本、文档、图片、音频、视频等
经过前面的问题的讨论,得出为什么需要搜索引擎的结论:
数据库适合结构化数据的精确查询,而不适合半结构化、非结构化数据的模糊查询及灵活搜索(特别是数据量大时),无法提供想要的实时性。
二、怎样建立反向索引
问题1:如何做才能快速查询到与苍老师有关的新闻?
分析:我们查询时,输入的是苍老师,想要得到标题或内容中包含“苍老师”的新闻列表。
如果标题、内容列上都有一个这样的索引,里面能快速找到与苍老师关键字对应的文章id,再根据文章id就可以快速找到文章了。
标题列索引:
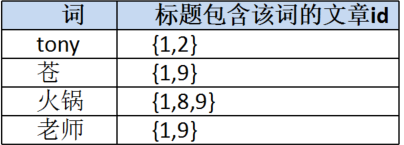
内容列索引:
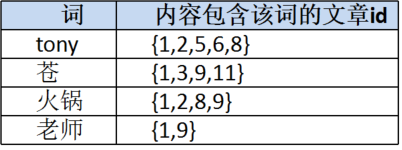
词到文章id的索引,这就是:反向索引(Inverted index)
问题2:问题1的标题列索引和内容列索引两个索引可以合并到一起,这样有什么好处?

合并得好处是:可以减少访问数据库的次数
问题3:反向索引的记录数会不会很大?如果是英文的,最大是多少?如果是中文的,最大可能是多少?
英语单词的大致数量是10万个 汉字的总数已经超过了8万,而常用的只有3500字
《现代汉语规范词典》比《现代汉语词典》收录的字和词数量更多。前者是13000多字,72000多词,后者是11000多字,69000多词
结论:量不会很大,30万以内;通过这个索引找文章会很快
问题4:如何建立问题2中的这样一个反向索引?
数据示例:
新闻id:1
新闻标题:Tony 与苍老师一起吃火锅
新闻内容:2018年4月1日,Tony 在四川成都出席某活动时,碰巧主办方也邀请了苍老师来提高人气,在主办方的邀请下和苍老师一起吃了个火锅,很爽!
如果是英文文章,好不好分?
It’s one thing to find the 10 best documents to match your query
英文好分(有空格),中文则不好分。 但一定得要分,否则无法建立反向索引。
就必须写一套专门的程序来做这个事情:分词器
中文分词器原理:有个词的字典,对语句前后字进行组合,与字典匹配,歧义分析
问题5: java开源中文分词器有很多,如何选择?
准确率、分词效率、中英文混合分词支持
常用中文分词器:
IKAnalyzer、mmseg4j
问题6: 你、我、他、的、地、了、标点符号…..这些需要为其创建索引吗?
这些词称为:停用词。分词器支持指定/添加停用词,不需要为其创建索引
问题7: 当出现了新词了,该怎么办?
撩妹 老司机、软妹子、直男、腿玩年、苍老师
分词器应支持为其词典添加新词。
总结:
根据分词结果,我们创建反向索引,如下所示:
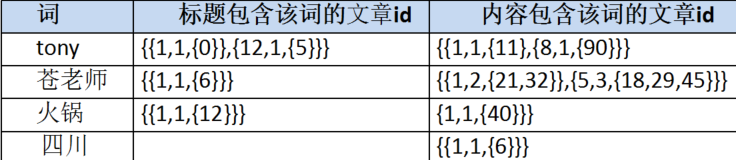

三、有了反向索引了,如何进行搜索?
如想搜索与 “tony OR 苍老师” 相关的新闻,步骤是怎样的?
步骤1: 对搜索输入进行分词
tony 、苍老师
步骤2: 在反向索引中找出包含tony、苍老师的文章列表

步骤3: 合并两个列表,排序输出
{1,12,8,5}
四、如何建立一个相关性评估模型?
利用出现次数来建立模型
规则1: 统计出现次数,根据次数从高到低排

{{1,5},{5,3},{12,1},{8,1}}:文章1出现5次,文章5出现3次,文章12出现1次,文章8出现1次
问题1:标题中出现苍老师,与新闻的内容中出现苍老师,哪个是专门写苍老师的相关度高些?怎么做
规则2: 加入权重,标题权重10,内容权重1,计算权重得分,按高-低排序
{{1,23},{12,10},{5,3},{8,1}}
总结:利用出现次数来建立模型这个相关性模型很简单。有时排序会不是很准确。
复杂的相关性计算模型有:
tf-idf 词频-逆文档率模型
向量空间模型
贝叶斯概率模型,如: BM25
搜索引擎中会提供一种、或多种实现供选择使用,也会提供扩展。
电商网站中的搜索相关性计算会考虑更多,更复杂。
五、反向索引更新:数据更新时,索引是不是必须得更新?好更新吗?
更新情况分析:
问1:新增时,需要怎么更新?
问2:删除时,需要怎么更新?
问3:修改时,需要怎么更新?
六、反向索引是存储在内存中,还是磁盘中合适?
大的放磁盘,小的放内存,同时需要做持久化
七、搜索引擎需要支持精确搜索吗?需要支持像数据库一样的多条件AND OR 组合搜索吗?
如 类别 IN () 数值 > = < 时间
必须要,否则搜索引擎就没人用了
八、总结
1、搜索引擎是什么?
一套可对大量结构化、半结构化数据、非结构化文本类数据进行实时搜索的专门软件
最早应用于信息检索领域,经谷歌、百度等公司推出网页搜索而为大众广知。后又被各大电商网站采用来做网站的商品搜索。现广泛应用于各行业、互联网应用。是大型系统、网站架构师必备技能。
2、搜索引擎是用来解决什么问题的?
专门解决大量结构化、半结构化数据、非结构化文本类数据的实时检索问题。 这种实时搜索数据库做不了。
3、搜索引擎适合什么场景使用?
核心:大量结构化、半结构化、非结构化文本类数据的实时搜索
信息检索(如电子图书馆、电子档案馆)
网页搜索
内容提供网站的内容搜索(如 新闻、论坛、博客网站)
电子商务网站的商品搜索
如果你负责的系统数据量大,通过数据库检索慢,可以考虑用搜索引擎来专门负责检索。
4、搜索引擎由哪些核心部件构成?
数据源、分词器、反向索引(倒排索引)、相关性计算模型
5、搜索引擎的工作原理是怎样的?
1、从数据源加载数据,分词、建立反向索引
2、搜索时,对搜索输入进行分词,查找反向索引
3、计算相关性,排序,输出
6、要实现一个搜索引擎,需要实现哪些?
1、分词器
2、反向索引,索引存储
3、相关性计算模型
7、要去使用一个搜索引擎,需要搞清楚它的哪些方面?
1、分词器
2、反向索引建立、存储、更新
3、相关性计算模型
8、java领域应用广泛的开源搜索引擎组件、系统

Lucene:Apache顶级开源项目,Lucene-core是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的框架,提供了完整的查询引擎和索引引擎,部分文本分词引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Nutch:Apache顶级开源项目,包含网络爬虫和搜索引擎(基于lucene)的系统(同百度、google)。Hadoop因它而生。
Solr:Lucene下的子项目,基于Lucene构建的独立的企业级开源搜索平台,一个服务。它提供了基于xml/JSON/http的api供外界访问,还有web管理界面。
Elasticsearch:基于Lucene的企业级分布式搜索平台,它对外提供restful-web接口,让程序员可以轻松、方便使用搜索平台,而不需要了解Lucene。
问题:如何选择搜索引擎组件或系统?
看成熟度,使用企业量。
Lucene系列一:搜索引擎核心理论的更多相关文章
- VIPS:基于视觉的页面分割算法[微软下一代搜索引擎核心分页算法]
VIPS:基于视觉的页面分割算法[微软下一代搜索引擎核心分页算法] - tingya的专栏 - 博客频道 - CSDN.NET VIPS:基于视觉的页面分割算法[微软下一代搜索引擎核心分页算法] 分类 ...
- Java 并发编程:核心理论
并发编程是Java程序员最重要的技能之一,也是最难掌握的一种技能.它要求编程者对计算机最底层的运作原理有深刻的理解,同时要求编程者逻辑清晰.思维缜密,这样才能写出高效.安全.可靠的多线程并发程序.本系 ...
- Java多线程0:核心理论
并发编程是Java程序员最重要的技能之一,也是最难掌握的一种技能.它要求编程者对计算机最底层的运作原理有深刻的理解,同时要求编程者逻辑清晰.思维缜密,这样才能写出高效.安全.可靠的多线程并发程序.本系 ...
- 【转】Java 并发编程:核心理论
并发编程是Java程序员最重要的技能之一,也是最难掌握的一种技能.它要求编程者对计算机最底层的运作原理有深刻的理解,同时要求编程者逻辑清晰.思维缜密,这样才能写出高效.安全.可靠的多线程并发程序.本系 ...
- (转)Java并发编程:核心理论
原文链接:https://www.cnblogs.com/paddix/p/5374810.html Java并发编程系列: Java 并发编程:核心理论 Java并发编程:Synchronized及 ...
- Java 并发编程:核心理论(一)
前言......... 并发编程是Java程序员最重要的技能之一,也是最难掌握的一种技能.它要求编程者对计算机最底层的运作原理有深刻的理解,同时要求编程者逻辑清晰.思维缜密,这样才能写出高效.安全.可 ...
- 8 个基于 Lucene 的开源搜索引擎推荐
Lucene是一种功能强大且被广泛使用的搜索引擎,以下列出了8种基于Lucene的搜索引擎,你可以想象它们有多么强大. 1. Apache Solr Solr 是一个高性能,采用Java5开发,基于L ...
- Lucene系列五:Lucene索引详解(IndexWriter详解、Document详解、索引更新)
一.IndexWriter详解 问题1:索引创建过程完成什么事? 分词.存储到反向索引中 1. 回顾Lucene架构图: 介绍我们编写的应用程序要完成数据的收集,再将数据以document的形式用lu ...
- C#编写了一个基于Lucene.Net的搜索引擎查询通用工具类:SearchEngineUtil
最近由于工作原因,一直忙于公司的各种项目(大部份都是基于spring cloud的微服务项目),故有一段时间没有与大家分享总结最近的技术研究成果的,其实最近我一直在不断的深入研究学习Spring.Sp ...
随机推荐
- G1 Garbage Collector and Shenandoah
http://www.diva-portal.se/smash/get/diva2:754515/FULLTEXT01.pdf https://is.muni.cz/th/ifz8g/GarbageC ...
- web spring 容器
使用spring的web应用时,不用手动创建spring容器,而是通过配置文件声明式地创建spring容器,因此,在web应用中创建spring容器有如下两种方式: 一.直接在web.xml文件中配置 ...
- 通过Fiddler肆意修改接口返回数据进行测试
[本文出自天外归云的博客园] 方法介绍与比对 在测试的过程中,有的需求是这样的,它需要你修改接口返回的数据,从而检查在客户端手机app内是否显示正确,这也算是一种接口容错测试,接口容错测试属于app性 ...
- JAVA-JSP内置对象之application对象获得服务器版本
相关资料:<21天学通Java Web开发> application对象获得服务器版本1.通过application对象的getMajorVersion()方法和getMinorVersi ...
- 关于正则表达式的“\b”
今天刚刚开始看正则表达式就遇到一个十分头疼的问题,原文是这样的: “不幸的是,很多单词里包含hi这两个连续的字符,比如him,history,high等等.用hi来查找的话,这里边的hi也会被找出来. ...
- [转]jquery.validate.js表单验证
原文地址:https://www.cnblogs.com/si-shaohua/p/3780321.html 一.用前必备官方网站:http://bassistance.de/jquery-plugi ...
- 微服务之springCloud-docker-feign-hystrix-ribbon(七)
简介 在上一节中,我们讨论了feign+hystrix在项目开发中,除了考虑正常的调用之外,负载均衡和故障转移也是关注的重点,这也是feign + ribbon+hystrix的优势所在,本节我们就讨 ...
- 【Android】Android6.0发送短信Demo
整理一下使用SmsManager类发送短信的方法. https://developer.android.com/reference/android/telephony/SmsManager.html ...
- PHP——大话PHP设计模式——SPL数据结构
- Android——用PagerAdapter实现View滑动效果
效果: ViewPage来源于android -support.v4 什么是viewPage?ViewPage 类似于ListView 用于显示多个View集合. 支持页面左右滑动. 如何使用view ...