python中url解析 or url的base64编码
目录
from urllib.parse import urlparse, quote, unquote, urlencode
1、解析url的组成成分:urlparse(url)
2、url的base64编解码:quote(url)、unquote(url)
3、字典变成一个字符串=&连接,并且被base64编码:urlencode(字典)
from urllib.parse import urlparse, quote, unquote, urlencode
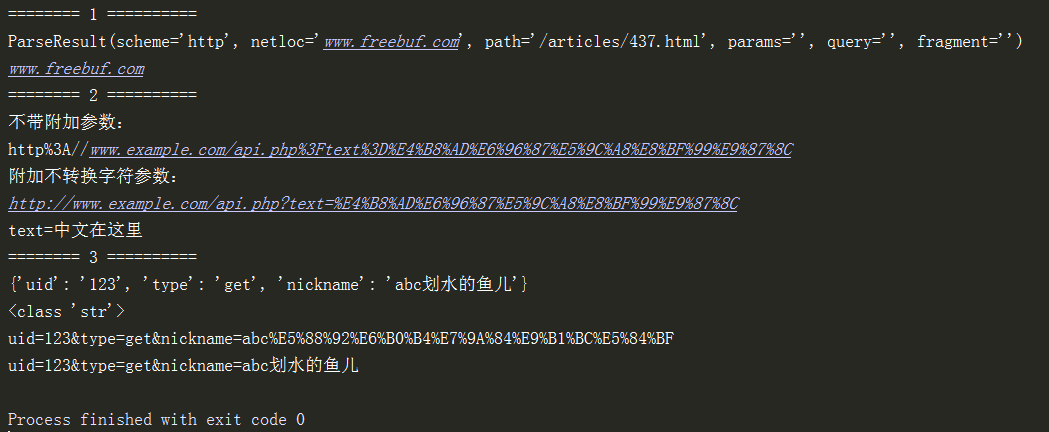
print("======== 1 解析url的组成==========")
url='http://www.freebuf.com/articles/437.html'
url_parse = urlparse(url)
print(url_parse)
print(url_parse.netloc)
print("======== 2 对字符串进行base64编码和反编码==========")
url = 'http://www.example.com/api.php?text=中文在这里'
# 不带附加参数
print('不带附加参数:\n%s' % quote(url))
# 附带不转换字符参数
print('附加不转换字符参数:\n%s' % quote(url, safe='/:?='))
print(unquote("text%3D%E4%B8%AD%E6%96%87%E5%9C%A8%E8%BF%99%E9%87%8C"))
print("======== 3 对字典转换为=&连接的字符串,并且base64编码==========")
params = {
"uid": "123",
"type": "get",
"nickname": "abc划水的鱼儿",
}
print(params)
data_str_base64 = urlencode(params) # 字典转为字符串,并且base64编码
print(type(data_str_base64))
print(data_str_base64)
data_str_unbase64 = unquote(data_str_base64) # 字符串中base64被反解码
print(data_str_unbase64)
输出结果:
到此看懂了,后面就可以不用看了。
1、解析url的组成成分:urlparse(url)
提取域名domain
from urllib.parse import urlparse url = 'http://www.freebuf.com/articles/437.html'
url_parse = urlparse(url)
print(url_parse)
print(url_parse.netloc)
print(url_parse.hostname)
输出:
ParseResult(scheme='http', netloc='www.freebuf.com', path='/articles/437.html', params='', query='', fragment='')
www.freebuf.com
www.freebuf.com
2、url的base64编解码:quote(url)、unquote(url)
url的base64编码 、解码
from urllib.parse import quote
url = 'http://www.example.com/api.php?text=中文在这里' # 不带附加参数
print('\n不带附加参数:\n%s' % quote(url)) # 附带不转换字符参数
print('\n附加不转换字符参数:\n%s' % quote(url, safe='/:?='))
输出结果:

base64解码
print(unquote("text%3D%E4%B8%AD%E6%96%87%E5%9C%A8%E8%BF%99%E9%87%8C"))
(一)字符串转义为base64编码和解码(和上文重复,不用看)
import urllib.parse url_han = 'https://www.baidu.com/s?wd=北京'
print(urllib.parse.quote(url_han)) # base64编码
# https%3A//www.baidu.com/s%3Fwd%3D%E5%8C%97%E4%BA%AC url_base64 = 'https://www.baidu.com/s?wd=%E6%B7%B1%E5%9C%B3'
print(urllib.parse.unquote(url_base64)) # base64反编码
# https://www.baidu.com/s?wd=深圳
3、字典变成一个字符串=&连接,并且被base64编码
(二)字典转化为&连接的字符串
说明:字典转字符串后,发生了2件事
1、冒号变成等号;逗号变成&
2、汉字和特殊字符被base64编码
案例:
源代码:
import urllib.parse
params = {
"uid": "123",
"type": "get",
"nickname": "abc划水的鱼儿",
}
print(params)
data_str_base64 = urllib.parse.urlencode(params) # 字典转为字符串,并且base64编码
print(type(data_str_base64))
print(data_str_base64)
data_str_unbase64 = urllib.parse.unquote(data_str_base64) # 字符串中base64被反解码
print(data_str_unbase64)
输出结果:
{'uid': '123', 'type': 'get', 'nickname': 'abc划水的鱼儿'}
<class 'str'>
uid=123&type=get&nickname=abc%E5%88%92%E6%B0%B4%E7%9A%84%E9%B1%BC%E5%84%BF
uid=123&type=get&nickname=abc划水的鱼儿
python中url解析 or url的base64编码的更多相关文章
- python中html解析-Beautiful Soup
1. Beautiful Soup的简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.pyt ...
- python中unicode、utf8、gbk等编码问题
转自:http://luchanghong.com/python/2012/07/06/python-encoding-with-unicode-and-gbk-and-utf8.html 概要:编码 ...
- Python中xlwt解析
1.导入模块 import xlwt 2.构造excel表 workbook = xlwt.Workbook() #返回一个工作簿对象 3.构造sheet w ...
- python中html解析
import requestsfrom bs4 import BeautifulSoup url = "..." payload =...headers = None respon ...
- Python中配置文件解析模块-ConfigParser
Python中有ConfigParser类,可以很方便的从配置文件中读取数据(如DB的配置,路径的配置).配置文件的格式是: []包含的叫section, section 下有option=value ...
- Python中yield解析
小探yield 查看 python yield 文档 yield expressions: Using a yield expression in a function's body causes t ...
- Python中xlutils解析
1.导入模块 import xlrd import xlutils.copy 2.打开模块表 book = xlrd.open_workbook('test.xls', formatting_info ...
- Python中Json解析的坑
JSON虽好,一点点不对,能把人折腾死: 1.变量必须要用双引号 2.如果是字符串,必须要用引号包起来 Error:Expecting : delimiter: line 1 column 6 (ch ...
- python中xml解析
import xml.dom.minidom input_xml_string = '''<root><a>hello</a></root>'''#打开 ...
随机推荐
- Python的Flask框架与数据库连接的教程
命令行方式运行Python脚本 在这个章节中,我们将写一些简单的数据库管理脚本.在此之前让我们来复习一下如何通过命令行方式执行Python脚本. 如果Linux 或者OS X的操作系统,需要有执行脚 ...
- flask + mysql写的简单监控系统
这里以监控内存使用率为例,写的一个简单demo性程序,具体操作根据51reboot提供的教程写如下. 一.建库建表 创建falcon数据库: mysql> create database fal ...
- MVC中的一些不同之处(WebForm)
一. 路由重定向 /// <summary> /// 路由重定向 /// </summary> /// <returns></returns> publ ...
- Clock skewdetected. Your build may be incomplete.
解决方法: find . -type f | xargs -n touch make clean make
- hdu_1086 You can Solve a Geometry Problem too(计算几何)
http://acm.hdu.edu.cn/showproblem.php?pid=1086 分析:简单计算几何题,相交判断直接用模板即可. 思路:将第k条直线与前面k-1条直线进行相交判断,因为题目 ...
- Python 编码规范(Google)
Python 编码规范(Google) https://blog.csdn.net/q469587851/article/details/54096093 Python 风格规范(Google) 本项 ...
- python基础---->python的使用(一)
这里面记录一些python的一些基础知识,数据类型和变量.幸而下雨,雨在街上泼,却泼不进屋内.人靠在一块玻璃窗旁,便会觉得幸福.这个家还是像个家的. python的一些基础使用 一.python中的数 ...
- python编程中的if __name__ == 'main': 的作用和原理
在大多数编排得好一点的脚本或者程序里面都有这段if __name__ == 'main': ,虽然一直知道他的作用,但是一直比较模糊,收集资料详细理解之后与打架分享. 1.这段代码的功能 一个pyth ...
- ESlint全局变量报错
场景: 在main.js下申明了全局变量: /* eslint no-undef: "error" */ window.vm = new Vue({ el: '#app', rou ...
- Android7.0 PowerManagerService 之亮灭屏(二) PMS 电源状态管理updatePowerStateLocked()
本篇注意接着上篇[Android7.0 PowerManagerService 之亮灭屏(一)]继续分析量灭屏的流程,这篇主要分析PMS的状态计算和更新流程,也是PMS中最为重要和复杂的一部分电源状态 ...