Python 爬虫-股票数据的Scrapy爬虫
2017-08-06 19:52:21
目标:获取上交所和深交所所有股票的名称和交易信息
输出:保存到文件中
技术路线:scrapy
获取股票列表:
东方财富网:http://quote.eastmoney.com/stocklist.html
获取个股信息:
百度股票:https://gupiao.baidu.com/stock/
单个股票:https://gupiao.baidu.com/stock/sz002439.html
程序框架
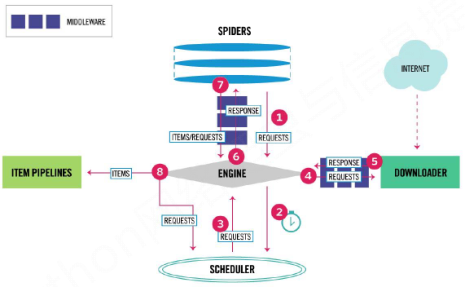
编写spider处理链接爬取和页面解析,编写pipelines处理信息存储。
一、具体流程
步骤1:建立工程和Spider模板
步骤2:编写Spider
步骤3:编写ITEM Pipelines
- 建立工程和Spider模板
\>scrapy startproject BaiduStocks
\>cd BaiduStocks
\>scrapy genspider stocks baidu.com
进一步修改spiders/stocks.py文件
- 编写Spider
- 配置stocks.py文件
- 修改对返回页面的处理
- 修改对新增URL爬取请求的处理
stocks.py修改前

stock.py修改后
# -*- coding: utf-8 -*-
import scrapy
import re
import random class StocksSpider(scrapy.Spider):
name = "stocks"
start_urls = ['http://quote.eastmoney.com/stocklist.html']
user_agent_list = [\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"\
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",\
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",\
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",\
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",\
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3"] def parse(self, response):
ua = random.choice(self.user_agent_list)
headers = {
'Accept-Encoding':'gzip, deflate, sdch, br',
'Accept-Language':'zh-CN,zh;q=0.8',
'Connection':'keep-alive',
'Referer':'https://gupiao.baidu.com/',
'User-Agent':ua
}#构造请求头
for href in response.css('a::attr(href)').extract():
try:
stock = re.findall(r"[s][hz]\d{6}",href)[0]
url = "https://gupiao.baidu.com/stock/"+stock+".html"
yield scrapy.Request(url,callback=self.parse_stock,headers = headers)
except:
continue def parse_stock(self,response):
#itempipline模块接受的是字典类型的数据
infodict = {}
name = response.css('.bets-name').extract()[0]
keylist = response.css('dt').extract()
vallist = response.css('dd').extract()
for i in range(len(keylist)):
key = re.findall(r".*>(.*)</dt>",keylist[i])[0]
try:
val = re.findall(r">[-]?\d+\.?.*</dd>",vallist[i])[0][1:-5]
except:
val = "--"
infodict[key] = val
infodict.update({"股票名称":re.findall(r"\s+.*\(",name)[0].split()[0]+re.findall(r"\d+</s",name)[0][0:-3]})
yield infodict
Scrapy中提供了css选择器,可以使用css选择器进行html页面的提取。
主要的使用方法有:
<HTML>.css('a::attr(href)').extract() : 这样会提取到a标签下的href属性的值,并提取为字符串,返回一个列表
<HTML>.css('a').extract() :这样会提取所有a标签以及全部内容,转成字符串,返回一个列表
<HTML>.css('.calc').extract():这样会提取所有类型为calc的标签及其全部内容,转成字符串,返回一个列表
<HTML>.css('.calc'):不提取的话,会返回一个选择器类型,可以继续对类型为calc的便签内容进行继续提取
- 编写Pipelines
配置pipelines.py文件
定义对爬取项(Scraped Item)的处理类,每一个类处理一个items
配置ITEM_PIPELINES选项
pipelines.py修改前:

pipelines.py修改后
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html #每一个类都是对一个itme进行处理的类
class BaidustocksPipeline(object):
def process_item(self, item, spider):
return item class Baidustocksinfopipeline(object):
def open_spider(self,spider):
self.f = open("Baidustockinfo.txt",'w') def close_spider(self,spider):
self.f.close() def process_item(self,item,spider):
try:
line = str(dict(item))+"\n"
self.f.write(line)
except:
pass
return item
- 配置settings.py文件

- 最后使用 Scrapy crawl stocks 执行爬虫
注意事项:
在实际编写过程中遇到不少的问题,这里提一下其中的需要注意的部分。
(1)爬取的结果为403,爬取失败。这一般是反爬虫程序在作怪,使用自行配置的headers即可解决。
(2)正则表达式的匹配问题,主要是最短匹配的问题里有个更高优先级的是,最先开始匹配的拥有最高优先级。
(3)extract()提取出来的是列表,在使用的时候需要加上 [ i ],同理,re.findall()返回的也是列表,即使仅包含一个元素也需要使用[0]来进行成员的访问。
Python 爬虫-股票数据的Scrapy爬虫的更多相关文章
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- 用Python浅析股票数据
用Python浅析股票数据 本文将使用Python来可视化股票数据,比如绘制K线图,并且探究各项指标的含义和关系,最后使用移动平均线方法初探投资策略. 数据导入 这里将股票数据存储在stockData ...
- Python爬虫 股票数据爬取
前一篇提到了与股票数据相关的可能几种数据情况,本篇接着上篇,介绍一下多个网页的数据爬取.目标抓取平安银行(000001)从1989年~2017年的全部财务数据. 数据源分析 地址分析 http://m ...
- 学好Python不加班系列之SCRAPY爬虫框架的使用
scrapy是一个爬虫中封装好的一个明星框架.具有高性能的持久化存储,异步的数据下载,高性能的数据解析,分布式. 对于初学者来说还是需要有一定的基础作为铺垫的学习.我将从下方的思维导图中进行逐步的解析 ...
- python抓取数据 常见反爬虫 情况
1.报文头信息: User-Agent Accept-Language 防盗链 上referer 随机生成不同的User-Agent构造报头 2.加抓取等待时间 每抓取一页都让它随机休息几秒,加入此 ...
- 使用python抓取数据之菜鸟爬虫1
''' Created on 2018-5-27 @author: yaoshuangqi ''' #本代码获取百度乐彩网站上的信息,只获取最近100期的双色球 import urllib.reque ...
- 一个采用python获取股票数据的开源库,相当全,及一些量化投资策略库
tushare: http://tushare.waditu.com/index.html 为什么是Python? 就跟javascript在web领域无可撼动的地位一样,Python也已经在金融量化 ...
- 如何在vscode中调试python scrapy爬虫
本文环境为 Win10 64bit+VS Code+Python3.6,步骤简单罗列下,此方法可以不用单独建一个Py入口来调用命令行 安装Python,从官网下载,过程略,这里主要注意将python目 ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(下)
前几天小编带大家学会了如何在Scrapy框架下创建属于自己的第一个爬虫项目(上),今天我们进一步深入的了解Scrapy爬虫项目创建,这里以伯乐在线网站的所有文章页为例进行说明. 在我们创建好Scrap ...
随机推荐
- php PDO遇到的坑
<?php $dbConn = new PDO( "mysql:host=localhost;dbname=adtuu",'root','root', array( // 强 ...
- Linux命令: 在线使用linux命令环境
https://www.tutorialspoint.com/unix_terminal_online.php
- linux服务器---配置bind
配置bind 1.确定已经安装bind软件,需要安装3 个bind.bind-chroot.bind-util [root@localhost wj]# yum install –y bind bin ...
- 计算概论(A)/基础编程练习2(8题)/1:求平均年龄
#include<stdio.h> int main() { // 声明与初始化 , s=, age=; // 输入学生人数 scanf("%d", &n); ...
- (一)MySQL登录与退出
mysql登陆: win+r输入cmd按enter进入命令行界面: > mysql -uroot -p -P3306 -h127.0.0.1 > 输入密码后按回车 mysql退出: mys ...
- C++算法原理与实践(面试中的算法和准备过程)
第0部分 简介 1. 举个例子:面试的时候,可能会出一道算法考试题,比如写一个 strstr 函数——字符串匹配. 可能会想到用KMP算法来解题,但是该算法很复杂,不适宜在面试中使用. 1.1 C++ ...
- SVC(STM32)
这两个都是 system level service,有什么区别呢?…… 手册上说 SVC 这个指令是同步的,而 PendSV 是异步的,请问是什么意思呢?…… 高手路过尽请留言啊
- 我们能从 jQuery 的一个正则表达式中学到什么?
注意,该篇文章当前为粗糙的 v0.9 版本,会在稍后润色更新. 让我们来看一道思考题,根据 rejectExp,分析其正则执行过程中如何进行过滤?包含哪些执行步骤? rejectExp 变量的值如下: ...
- UnicodeDecodeError: 'ascii' codec can't decode byte 0xe0 in position 0
Windows 7/8/10机器上安装Python 2.7后,下载一些Package包进行setup时总是报错UnicodeDecodeError,如下: File "C:/Python27 ...
- Ubuntu 14.04 下 OF-Config安装
参考: Github of-config configure.ac - configure file issue OF-Config安装 1.安装OvS v2.3.1: Releases $ tar ...