HBase一次客户端读写异常解读分析与优化全过程(干货)
大数据时代,HBase作为一款扩展性极佳的分布式存储系统,越来越多地受到各种业务的青睐,以求在大数据存储的前提下实现高效的随机读写操作。对于业务方来讲,一方面关注HBase本身服务的读写性能,另一方面也需要更多地关注HBase客户端参数的具体意义。这篇文章就从一个具体的HBase客户端异常入手,定位异常发生的原因以及相应的客户端参数优化。
案发现场
最近某业务在使用HBase客户端读取数据时出现了大量线程block的情况,业务方保留了当时的线程堆栈信息,如下图所示:
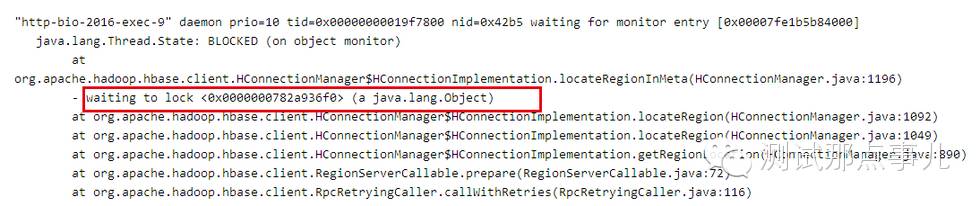
看到这样的问题,首先从日志和监控排查了业务表和region server,确认了在很长时间内确实没有请求进来,除此之外并没有其他有用的信息,同时也没有接到该集群上其他用户的异常反馈,从现象看,这次异常是在特定环境下才会触发的。
案件分析过程
1.根据上图图1所示,所有的请求都block在<0x0000000782a936f0>这把全局锁上,这里需要关注两个问题:
哪个线程持有了这把全局锁<0x0000000782a936f0>?
这是一把什么样的全局锁(对于问题本身并不重要,有兴趣可以参考步骤3)?
2.哪个线程持有了这把锁?
2.1 很容易在jstack日志中通过搜索找到全局锁<0x0000000782a936f0>被如下线程持有:

定睛一看,该线程持有了这把全局锁,而且处于TIMED_WAITING状态,因此这把锁可能长时间不释放,导致所有需要这把全局锁的线程都阻塞等待。好了,那问题就转化成了:为什么这个线程会处于TIME_WAITING状态?
2.2 根据上图提示,查看源码中RpcRetryingCall.java的115行代码,可以确定该线程处于TIME_WAITING状态是因为自己休眠导致,如下图所示:
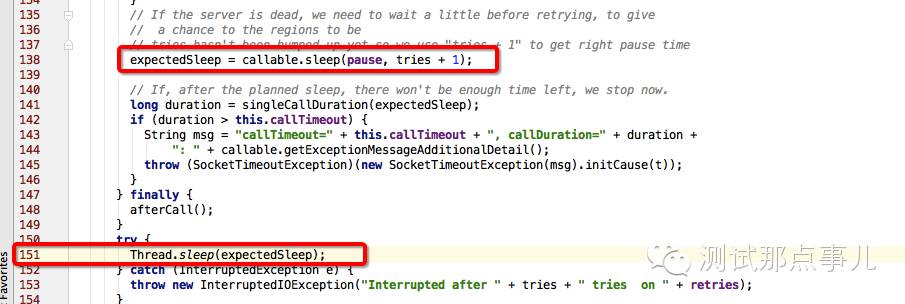
RpcRetryingCall函数是Rpc请求重试机制的实现,所以可以有两点推断:
HBase客户端请求在那个时间段网络有异常导致rpc请求失败,进入重试逻辑
根据HBase的重试机制(退避机制),每两次重试机制之间会休眠一段时间,即上图115行代码,这个休眠时间太长导致这个线程一直处于TIME_WAITING状态。
休眠时间由上图中expectedSleep = callable.sleep(pause,tries + 1)决定,根据hbase算法(见第三部分),默认最大的expectedSleep为20s,整个重试时间会持续8min,这也就是说全局锁会被持有8min,可这并不能解释持续将近几个小时的阻塞无请求。除非有两种情况:
配置有问题:需要客户端检查hbase.client.pause和hbase.client.retries.number两个参数配置出现异常,比如hbase.client.pause参数如果手抖配成了10000,就有可能出现几个小时阻塞的情况
网络持续有问题:如果线程1持有全局锁重试失败之后退出,线程2竞争到这把锁,此时网络依然有问题,线程2会再次进入重试,重试8min之后失败退出,循环下去,也有可能出现几个小时阻塞的情况
和业务方确认配置,所有参数基本属于默认配置,因此猜测一不成立,那最有可能的情况就是猜测二。经过确认,在事发当时(凌晨0点~早上6点)确实存在很多服务因为云网络升级异常发生抖动的情况出现。然而因为没有具体的日志信息,所以并不能完全确认猜测是否正确。但是,通过问题的分析可以进一步明白HBase重试机制以及部分客户端参数优化策略,这也是写这篇文章的初衷之一。
3. 再来看看这把全局锁到底是什么锁,查看源码可知这把锁是下图中红框中的regionLockObject对象:
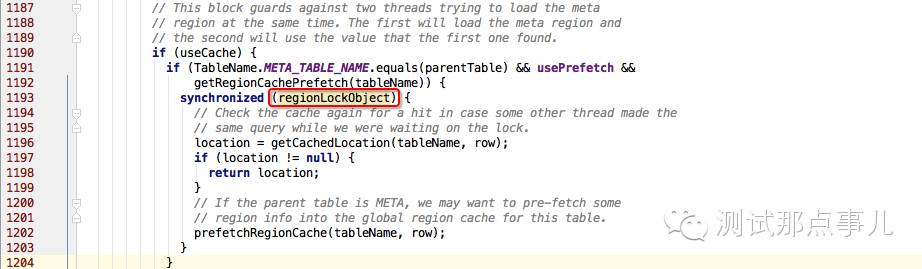
参考源码注释可知,这把锁是为了防止同时多线程并发加载meta分区。全局锁代码块首先会从缓存中查找meta分区,如果不存在会执行prefetchRegionCache方法远程查找并写入缓存,因此如果第一个线程成功加载meta分区数据并写入缓存,后来线程可以直接使用。
正常情况下,prefetchRegionCache方法只有在缓存不存在的情况下会执行,如果此时网络不存在问题,远程查找meta分区信息会很快完成,持锁时间也会很短。一旦网络出现长时间抖动,就有可能出现这把锁一直被持有,阻塞其他线程。
HBase Rpc重试机制
通过上文分析可知,HBase的重试机制是这次异常发生的关键点,有必要对其进行一次解析。HBase执行rpc失败之后会执行重试操作,重试的最大次数可以通过配置文件配置,对应的参数为hbase.client.retries.number,0.98版本中该参数的默认值为31。同时每两次重试之间会sleep一段时间,即上文提到的expectedSleep变量,该变量实现具体算法如下:
public static int RETRY_BACKOFF[] = { 1, 2, 3, 5, 10, 20, 40, 100, 100, 100, 100, 200, 200 };long normalPause = pause * HConstants.RETRY_BACKOFF[ntries];long jitter = (long)(normalPause * RANDOM.nextFloat() * 0.01f); // 1% possible jitterreturn normalPause + jitter;
其中RETRY_BACKOFF是一个重试系数表,由小到大递增表示重试时间会随着重试次数逐渐递增。pause变量可以通过配置文件配置,对应的参数为hbase.client.pause,0.98版本中该参数的默认值为100。
暂时忽略jitter这个小随机变量,默认情况下最大的重试间隔休眠时间 expectedSleep = 100 * 200 = 20s。默认重试次数为31,则每次连接集群重试之间的暂停时间将依次为:
[100,200,300,500,1000,2000,4000,10000,10000,10000,10000,20000,20000,…,20000]
这意味着客户端将在448s内重试30次,然后放弃连接到集群.
客户端参数优化实践
很显然,根据上面第二部分和第三部分的介绍,一旦在网络出现抖动的异常情况下,默认最差情况下一个线程会存在8min左右的重试时间,从而会导致其他线程都阻塞在regionLockObject这把全局锁上。为了构建一个更稳定、低延迟的HBase系统,除过需要对服务器端参数做各种调整外,客户端参数也需要做相应的调整:
1. hbase.client.pause:默认为100,可以减少为20
2. hbase.client.retries.number:默认为31,可以减少为11
修改后,通过上面算法可以计算出每次连接集群重试之间的暂停时间将依次为:
[20,40,60,100,200,400,800,2000,2000,2000,2000,4000,4000]
客户端将会在18s内重试10次,然后放弃连接到集群,进而会再将全局锁交给其他线程,执行其他请求。
总结
这篇文章从一个客户端异常入手,通过堆栈分析、源码追踪、合理推断,一方面整理分享程序异常的定位方法,一方面介绍HBase Rpc的重试机制以及客户端参数优化。最后,希望能和大家一起拥抱大数据时代的到来,也希望通过我们的努力能够让大家更多地了解HBase!
本文章为作者原创
HBase一次客户端读写异常解读分析与优化全过程(干货)的更多相关文章
- keepalived主备节点都配置vip,vip切换异常案例分析
原文地址:http://blog.51cto.com/13599730/2161622 参考地址:https://blog.csdn.net/qq_14940627/article/details/7 ...
- alias导致virtualenv异常的分析和解法
title: alias导致virtualenv异常的分析和解法 toc: true comments: true date: 2016-06-27 23:40:56 tags: [OS X, ZSH ...
- CPU利用率异常的分析思路和方法交流探讨
CPU利用率异常的分析思路和方法交流探讨在生产运行当中,经常会遇到CPU利用率异常或者不符合预期的情况,此时,往往暗示着系统性能问题.那么究竟是核心应用的问题?是监控工具的问题?还是系统.硬件.网络层 ...
- 161220、使用Spring AOP实现MySQL数据库读写分离案例分析
一.前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案,更是最大限度了提高了应用中读取 (Read)数据的速度和并发量. 在进行数据库读写分离的时候,我们首先要进行数据库 ...
- ArcGIS网络分析之Silverlight客户端最近设施点分析(四)
原文:ArcGIS网络分析之Silverlight客户端最近设施点分析(四) 在上一篇中说了如何实现最近路径分析,本篇将讨论如何实现最近设施点分析. 最近设施点分析实际上和路径分析有些相识,实现的过程 ...
- 修改List报ConcurrentModificationException异常原因分析
使用迭代器遍历List的时候修改List报ConcurrentModificationException异常原因分析 在使用Iterator来迭代遍历List的时候如果修改该List对象,则会报jav ...
- HBase新的客户端接口
最近学习接触HBase的东西,看了<Habase in Action>,但里面关于HBase接口都是过时的接口,以下为HBase新的客户端接口: package com.n10k; imp ...
- 网站开发进阶(八)tomcat异常日志分析及处理
tomcat异常日志分析及处理 日志信息如下: 2015-10-29 18:39:49 org.apache.coyote.http11.Http11Protocol pause 信息: Pausin ...
- OutOfMemoryError/OOM/内存溢出异常实例分析--虚拟机栈和本地方法栈溢出
关于虚拟机栈和本地方法栈,在JVM规范中描述了两种异常: 1.如果线程请求的栈深度大于JVM所允许的深度,将抛出StackOverflowError异常: 2.如果虚拟机在扩展栈时无法申请到足够的内存 ...
随机推荐
- Ruby 面向对象知识详解
Ruby 是纯面向对象的语言,Ruby 中的一切都是以对象的形式出现.Ruby 中的每个值都是一个对象,即使是最原始的东西:字符串.数字,甚至连 true 和 false 都是对象.类本身也是一个对象 ...
- 改造phpcms-v9自带的字符串截取函数
1.phpcms-v9自带的字符串截取函数在phpcms/libs/functions/global.func.php文件中: /** * 字符截取 支持UTF8/GBK * @param $stri ...
- MySQL修改密码和忘记ROOT密码
1.关闭数据库 脚本:[root@mysql etc]# service mysql stop 2.使用脚本: mysqld_safe --skip-grant-tables 启动数据库 使用/usr ...
- git 使gitnore立即生效
由于之前有些需要过滤的文件已经提交到版本库了,之后再想起来添加时候已经晚了,使用如下方法 Git忽略规则和.gitignore规则不生效的解决办法 Git忽略规则: 在git中如果想忽略掉某个文件 ...
- js获取视频截图
参考:https://segmentfault.com/q/1010000006717959问题:a.获取的好像是第一帧的图?第一帧为透明图时,获取的个透明图片b.得先加载视频到video,做视频上传 ...
- SpringBoot------使用Fastjson解析Json数据
方法一: 1.在pom.xml文件下添加依赖包 <dependency> <groupId>com.alibaba</groupId> <artifactId ...
- Netty权威指南之AIO编程
由JDK1.7提供的NIO2.0新增了异步的套接字通道,它是真正的异步I/O,在异步I/O操作的时候可以传递信号变量,当操作完成后会回调相关的方法,异步I/o也被称为AIO,对应于UNIX网络编程中的 ...
- 【GIS】ArcGIS JS 4.X
require(["esri/Map", "esri/views/SceneView", "esri/TileLayer/TdtMapLayer/Td ...
- 不作死就不会死,微软强行插入NO-IP
微软啊微软,你这是何苦来着. 事情经过大致是这样的,微软向美国法院提出起诉No-IP名下22个常用的子域名被恶意软件的作者滥用,要求法官裁定由微软接管No-IP名下的这22个子域名,以便其可以过滤恶意 ...
- mybatis 之 parameterType="list"
<!-- 根据货品编号查找货品图片地址,货品ID,商品ID,货品名称 --> <select id="getGoodsInfoByGoodsNo" paramet ...