phoenix 索引实践
准备工作
创建测试表
CREATE TABLE my_table (
rowkey VARCHAR NOT NULL PRIMARY KEY,
v1 VARCHAR,
v2 VARCHAR,
v3 VARCHAR
); UPSERT INTO my_table values('','value1','value2','value3');
UPSERT INTO my_table values('','value1','value2','value3');
UPSERT INTO my_table values('','value1','value2','value3');
UPSERT INTO my_table values('','value1','value2','value3');
UPSERT INTO my_table values('','value1','value2','value3');
开启索引支持
HBase --> 配置 --> 高级 --> 搜索 hbase-site.xml。
在服务端添加下面配置:
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
在这里插入图片描述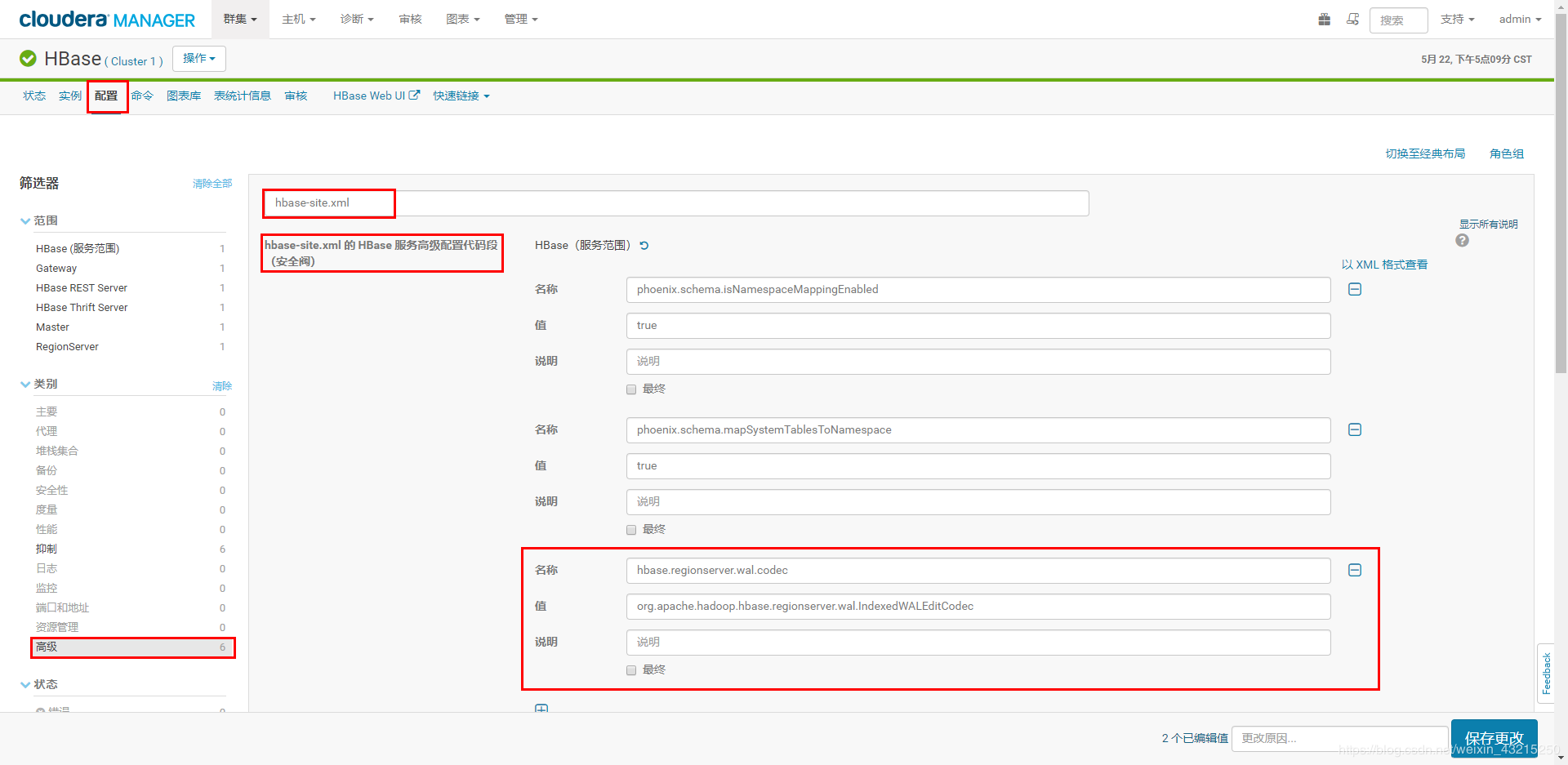
创建索引
全局索引
全局索引适合读多写少的场景。如果使用全局索引,读数据基本不损耗性能,所有的性能损耗都来源于写数据。数据表的添加、删除和修改都会更新相关的索引表(数据删除了,索引表中的数据也会删除;数据增加了,索引表的数据也会增加)。
注意:
对于全局索引在默认情况下,在查询语句中检索的列如果不在索引表中,Phoenix不会使用索引表将,除非使用hint。
创建全局索引
CREATE INDEX my_index ON my_table ( v3 );
查看效果
0: jdbc:phoenix:> select v3 from my_table where v3 = '';
+--------------+
| V3 |
+--------------+
| 13000010030 |
+--------------+
1 row selected (2.155 seconds)
0: jdbc:phoenix:> select * from my_table where v3 = '';
+-------------------+------+--------+--------------+
| ROWKEY | V1 | V2 | V3 |
+-------------------+------+--------+--------------+
| 77a9ede22e169683 | aaa| bbb| 13000010030 |
+-------------------+------+--------+--------------+
1 row selected (2.337 seconds)
0: jdbc:phoenix:> CREATE INDEX my_index ON my_table ( v3 );
1,076,190 rows affected (33.875 seconds)
0: jdbc:phoenix:> select * from my_table where v3 = '';
+-------------------+------+--------+--------------+
| ROWKEY | V1 | V2 | V3 |
+-------------------+------+--------+--------------+
| 77a9ede22e169683 | aaa| bbb| 13000010030 |
+-------------------+------+--------+--------------+
1 row selected (3.296 seconds)
0: jdbc:phoenix:> select v3 from my_table where v3 = '';
+--------------+
| V3 |
+--------------+
| 13000010030 |
+--------------+
1 row selected (0.02 seconds)
本地索引
本地索引适合写多读少的场景,或者存储空间有限的场景。和全局索引一样,Phoenix也会在查询的时候自动选择是否使用本地索引。本地索引因为索引数据和原数据存储在同一台机器上,避免网络数据传输的开销,所以更适合写多的场景。由于无法提前确定数据在哪个Region上,所以在读数据的时候,需要检查每个Region上的数据从而带来一些性能损耗。
注意:
对于本地索引,查询中无论是否指定hint或者是查询的列是否都在索引表中,都会使用索引表。
创建本地索引
CREATE LOCAL INDEX LOCAL_IDEX ON my_table(v3);
查看效果
0: jdbc:phoenix:> select * from my_table where v3 = '';
+-------------------+------+--------+--------------+
| ROWKEY | V1 | V2 | V3 |
+-------------------+------+--------+--------------+
| 77a9ede22e169683 | aaa| bbb| 13000010030 |
+-------------------+------+--------+--------------+
1 row selected (3.545 seconds)
0: jdbc:phoenix:> select v3 from my_table where v3 = '';
+--------------+
| V3 |
+--------------+
| 13000010030 |
+--------------+
1 row selected (2.946 seconds)
0: jdbc:phoenix:> CREATE LOCAL INDEX LOCAL_IDEX ON my_table(v3);
1,076,190 rows affected (24.67 seconds)
0: jdbc:phoenix:> select * from my_table where v3 = '';
+-------------------+------+--------+--------------+
| ROWKEY | V1 | V2 | V3 |
+-------------------+------+--------+--------------+
| 77a9ede22e169683 | aaa| bbb| 13000010030 |
+-------------------+------+--------+--------------+
1 row selected (0.055 seconds)
0: jdbc:phoenix:> select v3 from my_table where v3 = '';
+--------------+
| V3 |
+--------------+
| 13000010030 |
+--------------+
1 row selected (0.013 seconds)
覆盖索引
覆盖索引是把原数据存储在索引数据表中,这样在查询时不需要再去HBase的原表获取数据就,直接返回查询结果。
注意:
查询是 select 的列和 where 的列都需要在索引中出现。
创建覆盖索引
CREATE INDEX my_index ON my_table ( v2,v3 ) INCLUDE ( v1 );
添加索引后提升到毫秒级
0: jdbc:phoenix:> select * from my_table where v3 = '' and v2 = '北京顺义';
+-------------------+-----+-------+--------------+
| ROWKEY | V1 | V2 | V3 |
+-------------------+-----+-------+--------------+
| 3f65283ed7553909 | wenyuan | ccc| 13308117837 |
+-------------------+-----+-------+--------------+
1 row selected (2.42 seconds)
0: jdbc:phoenix:> CREATE INDEX my_index ON my_table (v2,v3) INCLUDE ( v1 );
1,076,190 rows affected (47.432 seconds)
0: jdbc:phoenix:> select * from my_table where v3 = '' and v2 = '北京顺义';
+-------------------+-----+-------+--------------+
| ROWKEY | V1 | V2 | V3 |
+-------------------+-----+-------+--------------+
| 3f65283ed7553909 | wenyuan| ccc| 13308117837 |
+-------------------+-----+-------+--------------+
1 row selected (0.031 seconds)
函数索引
从Phoenix4.3版本就有函数索引,特点是索引的内容不局限于列,能根据表达式创建索引。适用于对查询表时过滤条件是表达式。如果你使用的表达式正好就是索引的话,数据也可以直接从这个索引获取,而不需要从数据库获取。
创建索引
CREATE INDEX my_index ON my_table(substr(v3,1,9)) INCLUDE ( v1 );
查看效果
0: jdbc:phoenix:> select v1,substr(v3,1,9) from my_table where substr(v3,1,9) = '';
+-----+-------------------+
| V1 | SUBSTR(V3, 1, 9) |
+-----+-------------------+
| wenyuan| 130000109 |
+-----+-------------------+
1 row selected (3.656 seconds)
0: jdbc:phoenix:> select v1,v3 from my_table where substr(v3,1,9) = '';
+-----+--------------+
| V1 | V3 |
+-----+--------------+
| wenyuan| 13000010979 |
+-----+--------------+
1 row selected (3.969 seconds)
0: jdbc:phoenix:> CREATE INDEX my_index ON my_table(substr(v3,1,9)) INCLUDE ( v1 );
1,076,190 rows affected (45.833 seconds) 0: jdbc:phoenix:> select v1,v3 from my_table where substr(v3,1,9) = '';
+-----+--------------+
| V1 | V3 |
+-----+--------------+
| wenyuan| 13000010979 |
+-----+--------------+
1 row selected (3.44 seconds)
0: jdbc:phoenix:> select v1,v3,substr(v3,1,9) from my_table where substr(v3,1,9) = '';
+-----+--------------+-------------------+
| V1 | V3 | SUBSTR(V3, 1, 9) |
+-----+--------------+-------------------+
| wenyuan| 13000010979 | 130000109 |
+-----+--------------+-------------------+
1 row selected (3.327 seconds)
0: jdbc:phoenix:> select v1,substr(v3,1,9) from my_table where substr(v3,1,9) = '';
+-----+--------------------+
| V1 | " SUBSTR(V3,1,9)" |
+-----+--------------------+
| wenyuan | 130000109 |
+-----+--------------------+
1 row selected (0.013 seconds)
0: jdbc:phoenix:> select v1 from my_table where substr(v3,1,9) = '';
+-----+
| V1 |
+-----+
| wenyuan|
+-----+
1 row selected (0.011 seconds)
索引Building
同步索引
CREATE INDEX ASYNC_IDX ON SCHEMA_NAME.TABLE_NAME(BASICINFO."s1",BASICINFO."s2") ;
创建同步索引超时怎么办?
在客户端配置文件hbase-site.xml中,把超时参数设置大一些,足够 Build 索引数据的时间。
<property>
<name>hbase.rpc.timeout</name>
<value>60000000</value>
</property>
<property>
<name>hbase.client.scanner.timeout.period</name>
<value>60000000</value>
</property>
<property>
<name>phoenix.query.timeoutMs</name>
<value>60000000</value>
</property>
异步索引
异步Build索引需要借助MapReduce,创建异步索引语法和同步索引相差一个关键字:ASYNC。
创建异步索引
CREATE INDEX ASYNC_IDX ON SCHEMA_NAME.TABLE_NAME ( BASICINFO."s1", BASICINFO."s2" ) ASYNC;
运行MapReduce
执行MapReduce
hbase org.apache.phoenix.mapreduce.index.IndexTool \
--schema SCHEMA_NAME\
--data-table TABLE_NAME\
--index-table ASYNC_IDX \
--output-path ASYNC_IDX_HFILES
日志:
Java HotSpot(TM) 64-Bit Server VM warning: Using incremental CMS is deprecated and will likely be removed in a future release
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-5.12.1-1.cdh5.12.1.p0.3/jars/phoenix-4.14.0-cdh5.12.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-5.12.1-1.cdh5.12.1.p0.3/jars/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
19/05/22 15:38:41 INFO log.QueryLoggerDisruptor: Starting QueryLoggerDisruptor for with ringbufferSize=8192, waitStrategy=BlockingWaitStrategy, exceptionHandler=org.apache.phoenix.log.QueryLoggerDefaultExceptionHandler@dd0c991...
19/05/22 15:38:41 INFO query.ConnectionQueryServicesImpl: An instance of ConnectionQueryServices was created. ... 19/05/22 15:41:19 INFO index.IndexTool: Loading HFiles from INDEX_PERSONAS_TAG_HFILES/MY_SCHEMA.INDEX_PERSONAS_TAG
19/05/22 15:41:19 WARN mapreduce.LoadIncrementalHFiles: Skipping non-directory hdfs://bigdata-dev-41:8020/user/root/INDEX_PERSONAS_TAG_HFILES/MY_SCHEMA.INDEX_PERSONAS_TAG/_SUCCESS
19/05/22 15:41:19 INFO hfile.CacheConfig: CacheConfig:disabled
19/05/22 15:41:19 INFO mapreduce.LoadIncrementalHFiles: Trying to load hfile=hdfs://bigdata-dev-41:8020/user/root/INDEX_PERSONAS_TAG_HFILES/MY_SCHEMA.INDEX_PERSONAS_TAG/0/e1f766365b4f4c7cb6cfc6e0d18328b8 first=0\x0010\x00\xE4\xB8\x9A\xE4\xB8\xBB\x000\x000\x0010\x000\x00\xE6\xAD\xA3\xE5\xB8\xB8\xE4\xB8\x9A\xE4\xB8\xBB\x001001.99\x000\x001\x003\x00\xE8\x80\x81\xE5\xAE\xA2\xE6\x88\xB7\x00\xE6\x9C\xAA\xE7\x9F\xA5\x0042471415705946377 last=2\x009\x00\xE7\xA7\x9F\xE5\xAE\xA2\x002\x002\x009\x002\x00\xE9\x95\xBF\xE6\x9C\x9F\xE4\xB8\x8D\xE4\xBA\xA4\xE7\x89\xA9\xE4\xB8\x9A\xE7\xAE\xA1\xE7\x90\x86\xE8\xB4\xB9\x00988.56\x000\x001\x004\x00\xE6\x9C\xAA\xE7\x9F\xA5\x00\xE5\x9C\x9F\xE8\xB1\xAA\x0044ff3613003558171
19/05/22 15:41:20 INFO index.IndexToolUtil: Updated the status of the index INDEX_PERSONAS_TAG to ACTIVE
遇到问题
Error: Could not find or load main class org.apache.phoenix.mapreduce.index.IndexTool
解决办法
将 phoenix-4.14.0-cdh5.12.2-client.jar 包复制到 hbase 的 lib 目录下
[root@node00 ~]# cd /opt/cloudera/parcels/
[root@node00 parcels]# cd APACHE_PHOENIX/lib/phoenix
[root@node00 phoenix]# cp phoenix-4.14.0-cdh5.12.2-client.jar /opt/cloudera/parcels/CDH/jars/
[root@node00 phoenix]# cd /opt/cloudera/parcels/CDH/lib/hbase/lib/
[root@node00 lib]# ln -s ../../../jars/phoenix-4.14.0-cdh5.12.2-client.jar phoenix-4.14.0-cdh5.12.2-client.jar
索引用法总结
Phoenix 的二级索引主要有两种,即全局索引和本地索引。
全局索引适合读多写少的场景,如果使用全局索引,读数据基本不损耗性能,所有的性能损耗都来源于写数据。
本地索引适合写多读少的场景,或者存储空间有限的场景。
索引定义完之后,一般来说,Phoenix自己会判定使用哪个索引更加有效。
但是,全局索引必须是查询语句中所有列都包含在全局索引中,它才会生效。
索引为:
create index my_index on my_table (v3); select v1 from my_table where v3 = '';
上面语句怎样才能使用索引呢?
有以下三种方法使它使用索引:
使用覆盖索引
CREATE INDEX cover_index ON my_table(v3) INCLUDE (v1);
查看效果
0: jdbc:phoenix:> select v1 from my_table where v3 = '';
+------+
| V1 |
+------+
| wenyuan|
+------+
1 row selected (0.01 seconds)
使用 Hint 强制索引
SELECT /*+ INDEX(my_table my_index) */ v1 FROM my_table WHERE v3 = '';
查看效果
0: jdbc:phoenix:> SELECT /*+ INDEX(my_table my_index) */ v1 FROM my_table WHERE v3 = '';
+------+
| V1 |
+------+
| wenyuan|
+------+
1 row selected (0.044 seconds)
使用本地索引
CREATE LOCAL INDEX local_index on my_table (v3);
查看效果
0: jdbc:phoenix:> select v1 from my_table where v3 = '';
+------+
| V1 |
+------+
| wenyuan|
+------+
1 row selected (0.025 seconds)
phoenix 索引实践的更多相关文章
- Phoenix 索引生命周期
本文主要介绍Phoenix索引状态的生命周期,帮助大家解惑“为什么我的phoenix索引不能正常使用了?” 索引状态 索引总共有以下几个状态,其状态信息存储在SYSTEM.CATALOG表中.可以通过 ...
- MySQL索引实践
数据库索引本质上是一种数据结构(存储结构+算法),目的是为了加快数据检索速度. 1.索引的类型(待完善) 主键索引:给表设置主键,这个表就拥有主键索引. 唯一索引:unique 普通索引:增加某个字段 ...
- Mysql多列索引实践
在网上看到: 定义:最左前缀原则指的的是在sql where 子句中一些条件或表达式中出现的列的顺序要保持和多索引的一致或以多列索引顺序出现,只要 出现非顺序出现.断层都无法利用到多列索引. 该博文有 ...
- phoenix 索引修复-基本流程
索引修复基本流程
- 使用ElasticSearch赋能HBase二级索引 | 实践一年后总结
前言:还记得那是2018年的一个夏天,天气特别热,我一边擦汗一边听领导大刀阔斧的讲述自己未来的改革蓝图.会议开完了,核心思想就是:我们要搞一个数据大池子,要把公司能灌的数据都灌入这个大池子,然后让别人 ...
- Phoenix在2345公司的实践(转)
本文介绍Phoenix在2345公司的实践,主要是实时查询平台的背景.难点.Phoenix解决的问题.Phoenix-Sql的优化以及Phoenix与实时数仓的融合思路.具体内容如下: 实时数据查询时 ...
- spark+phoenix
phoenix作为查询引擎,为了提高查询效率,为phoenix表创建了二级索引,而数据是sparkstreaming通过hbase api直接向hbase插数据.那么问题来了,对于phoenix的二级 ...
- 使用Phoenix将SQL代码移植至HBase
1.前言 HBase是云计算环境下最重要的NOSQL数据库,提供了基于Hadoop的数据存储.索引.查询,其最大的优点就是可以通过硬件的扩展从而几乎无限的扩展其存储和检索能力.但是HBase与传统的基 ...
- [Phoenix] 六、MR在Ali-Phoenix上的使用
摘要: 在云HBASE上利用MR BULKLOAD入库PHOENIX表或通过MR构建PHOENIX索引表. 一.MR在Phoenix上的用途 利用MR对Phoenix表(可带有二级索引表)进行Bulk ...
随机推荐
- GPP(Group Policy Preference)组策略偏好漏洞利用
总结与反思: GPP中管理员给域成员添加的账号信息存在xml,可以直接破解拿到账号密码. Windows Sever 2008 的组策略选项(GPP)是一个新引入的插件,方便管理员管理的同时也引入了安 ...
- Trie树的简单实现
import java.util.ArrayList; import java.util.TreeMap; import util.FileOperation; public class Trie { ...
- java 实现全排列
public List<List<Integer>> permute(int[] nums) { List<List<Integer>> res = n ...
- "xaml+cs"桌面客户端跨平台初体验
"Xaml+C#"桌面客户端跨平台初体验 前言 随着 .Net 5的到来,微软在 .Net 跨平台路上又开始了一个更高的起点.回顾.Net Core近几年的成果,可谓是让.Ne ...
- 搜索引擎如何检索结果:Python和spaCy信息提取简介
概览 像Google这样的搜索引擎如何理解我们的查询并提供相关结果? 了解信息提取的概念 我们将使用流行的spaCy库在Python中进行信息提取 介绍 作为一个数据科学家,在日常工作中,我严重依赖搜 ...
- React源码解析——创建更新过程
一.ReactDOM.render 创建ReactRoot,并且根据情况调用root.legacy_renderSubtreeIntoContainer或者root.render,前者是遗留的 API ...
- 解决Pycharm导入当前项目的.py文件错误
如图所示错误,由左边导航栏可见.py文件存在: 解决办法:右键单击导包错误文件所在目录,选择[Mark Directory as]+[Sources Root] 错误已解决:
- MATLAB 随机过程基本理论
一.平稳随机过程 1.严平稳随机过程 clc clear n=0:1000; x=randn(1,1001); subplot(211),plot(n,x); xlabel('n');ylabel(' ...
- 空间复杂度(Space Complexity)
空间复杂度(Space Complexity) 算法得存储量包括: 1.程序本身所占空间. 2.输入数据所占空间. 3.辅助变量所占空间. 输入数据所占空间只取决于问题本身,和算法无关,则只需分析除输 ...
- Spring装配Bean的三种方式+导入和混合配置
目录 Spring IoC与bean 基于XML的显式装配 xml配置的基本结构 bean实例的三种创建方式 依赖注入的两种方式 构造器注入方式 setter方法注入方式 利用命名空间简化xml 基于 ...