非参数估计——核密度估计(Parzen窗)
核密度估计,或Parzen窗,是非参数估计概率密度的一种。比如机器学习中还有K近邻法也是非参估计的一种,不过K近邻通常是用来判别样本类别的,就是把样本空间每个点划分为与其最接近的K个训练抽样中,占比最高的类别。
直方图
首先从直方图切入。对于随机变量$X$的一组抽样,即使$X$的值是连续的,我们也可以划分出若干宽度相同的区间,统计这组样本在各个区间的频率,并画出直方图。下图是均值为0,方差为2.5的正态分布。从分布中分别抽样了100000和10000个样本:
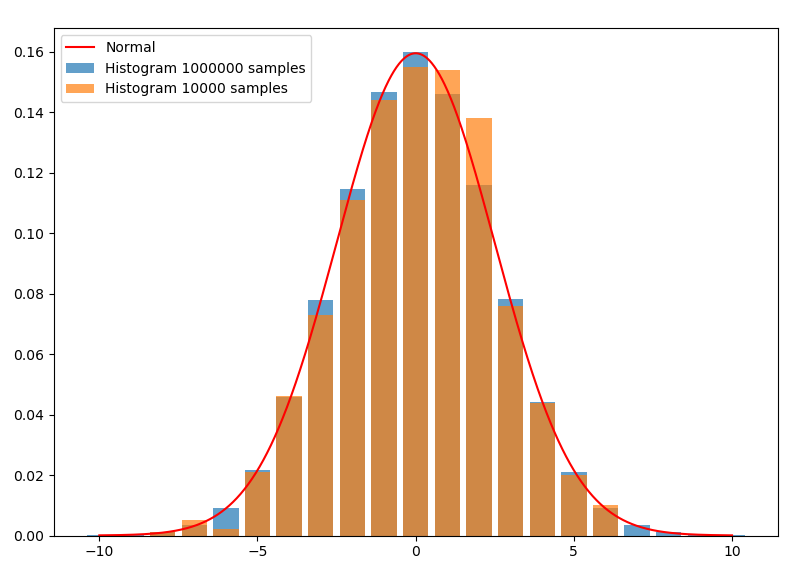
这里的直方图离散地取了21个相互无交集的区间:$[x-0.5,x+0.5), x=-10,-9,...,10$,单边间隔$h=0.5$。$h>0$在核函数估计中通常称作带宽,或窗口。每个长条的面积就是样本在这个区间内的频率。如果用频率当做概率,则面积除以区间宽度后的高,就是拟合出的在这个区间内的平均概率密度。因为这里取的区间宽度是1,所以高与面积在数值上相同,使得长条的顶端正好与密度函数曲线相契合。如果将区间中的$x$取成任意值,就可以拟合出实数域内的概率密度(其中$N_x$为样本$x_i\in [x-h,x+h),i=1,...,N$的样本数):
$\displaystyle\hat{f}(x)=\frac{N_x}{N}\cdot\frac{1}{2h}$
这就已经是核函数估计的一种了。显然,抽样越多,这个平均概率密度能拟合得越好,正如蓝条中上方几乎都与曲线契合,而橙色则稂莠不齐。另外,如果抽样数$N\to \infty$,对$h$取极限$h\to 0$,拟合出的概率密度应该会更接近真实概率密度。但是,由于抽样的数量总是有限的,无限小的$h$将导致只有在抽样点处,才有频率$1/N$,而其它地方频率全为0,所以$h$不能无限小。相反,$h$太大的话又不能有效地将抽样量用起来。所以这两者之间应该有一个最优的$h$,能充分利用抽样来拟合概率密度曲线。容易推理出,$h$应该和抽样量$N$有关,而且应该与$N$成反比。
核函数估计
为了便于拓展,将拟合概率密度的式子进行变换:
$\displaystyle\hat{f}(x)=\frac{N_x}{2hN} = \frac{1}{hN}\sum\limits_{i=1}^{N}\begin{cases}1/2& x-h\le x_i < x+h\\ 0& else \end{cases}$
$\displaystyle = \frac{1}{hN}\sum\limits_{i=1}^{N}\begin{cases} 1/2,& -1\le \displaystyle\frac{x_i-x}{h} < 1\\ 0,& else \end{cases}$
$\displaystyle = \frac{1}{hN}\sum\limits_{i=1}^{N}\displaystyle K(\frac{x_i-x}{h}),\;\; where \; K(x) =\begin{cases} 1/2,& -1\le x < 1\\ 0,& else \end{cases}$
得到的$K(x)$就是uniform核函数(也又叫方形窗口函数),这是最简单最常用的核函数。形象地理解上式求和部分,就是样本出现在$x$邻域内部的加权频数(因为除以了2,所以所谓“加权”)。核函数有很多,常见的还有高斯核函数(高斯窗口函数),即:
$\displaystyle K(x) = \frac{1}{\sqrt{2\pi}}e^{-x^2/2}$
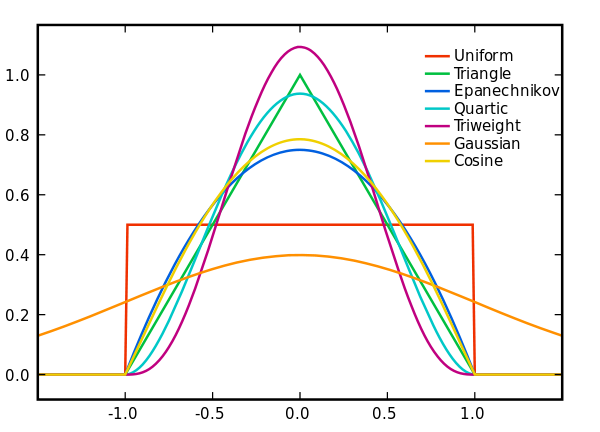
各种核函数如下图所示:
核函数的条件
并不是所有函数都能作为核函数的,因为$\hat{f}(x)$是概率密度,则它的积分应该为1,即:
$\displaystyle\int\limits_{R}\hat{f}(x) dx = \int\limits_{R}\frac{1}{hN}\sum\limits_{i=1}^{N} K(\frac{x_i-x}{h})dx =\frac{1}{hN}\sum\limits_{i=1}^{N} \int_{-\infty}^{\infty} K(\frac{x_i-x}{h})dx$
令$\displaystyle t = \frac{x_i-x}{h}$
$\displaystyle =\frac{1}{N}\sum\limits_{i=1}^{N} \int_{\infty}^{-\infty} -K(t)dt$
$\displaystyle=\frac{1}{N}\sum\limits_{i=1}^{N} \int_{-\infty}^{\infty} K(t)dt=1$
因积分部分为定值,所以可得$K(x)$需要的条件是:
$\displaystyle\int_{-\infty}^{\infty} K(x)dx=1$
通常$K(x)$是偶函数,而且不能小于0,否则就不符合实际了。
带宽选择与核函数优劣
正如前面提到的,带宽$h$的大小关系到拟合的精度。对于方形核函数,$N\to \infty$时,$h$通常取收敛速度小于$1/N$的值即可,如$h=1/\sqrt{N}$。对于高斯核,有证明指出$\displaystyle h=\left ( \frac{4 \hat{\sigma}^5 }{3N} \right )^{\frac{1}{5}}$时,有较优的拟合效果($\hat{\sigma}^2$是样本方差)。具体的带宽选择还有更深入的算法,具体问题还是要具体分析,就先不细究了。使用高斯核时,待拟合的概率密度应该近似于高斯分布那样连续平滑的分布,如果是像均匀分布那样有明显分块的分布,拟合的效果会很差。我认为原因应该是它将离得很远的样本也用于拟合,导致本该突兀的地方都被均匀化了。
Epanechnikov在均方误差的意义下拟合效果是最好的。这也很符合直觉,越接近$x$的样本的权重本应该越高,而且超出带宽的样本权重直接为0也是符合常理的,它融合了均匀核与高斯核的优点。
多维情况
对于多维情况,假设随机变量$X$为$m$维(即$m$维向量),则拟合概率密度是$m$维的联合概率密度:
$\displaystyle \hat{f}(x)= \frac{1}{h^mN}\sum\limits_{i=1}^{N}\displaystyle K(\frac{x_i-x}{h})$
其中的$K(x)$也变成了$m$维的联合概率密度。另外,既然$\displaystyle\frac{1}{N}\sum\limits_{i=1}^{N} K(\frac{x_i-x}{h})$代表的是概率,$m$维的概率密度自然是概率除以$h^m$而不是$h$。
实验拟合情况
非参数估计——核密度估计(Parzen窗)的更多相关文章
- 非参数估计:核密度估计KDE
http://blog.csdn.net/pipisorry/article/details/53635895 核密度估计Kernel Density Estimation(KDE)概述 密度估计的问 ...
- R语言与非参数统计(核密度估计)
R语言与非参数统计(核密度估计) 核密度估计是在概率论中用来估计未知的密度函数,属于非参数检验方法之一,由Rosenblatt (1955)和Emanuel Parzen(1962)提出,又名Parz ...
- parzen 窗的matlab实现
用一下程序简单实现使用parzen窗对正态分布的概率密度估计: (其中核函数选用高斯核) %run for parzen close all;clear all;clc; x=normrnd(0,1, ...
- 作图直观理解Parzen窗估计(附Python代码)
1.简介 Parzen窗估计属于非参数估计.所谓非参数估计是指,已知样本所属的类别,但未知总体概率密度函数的形式,要求我们直接推断概率密度函数本身. 对于不了解的可以看一下https://zhuanl ...
- 机器学习 —— 基础整理(三)生成式模型的非参数方法: Parzen窗估计、k近邻估计;k近邻分类器
本文简述了以下内容: (一)生成式模型的非参数方法 (二)Parzen窗估计 (三)k近邻估计 (四)k近邻分类器(k-nearest neighbor,kNN) (一)非参数方法(Non-param ...
- kdeplot(核密度估计图) & distplot
Seaborn是基于matplotlib的Python可视化库. 它提供了一个高级界面来绘制有吸引力的统计图形.Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图 ...
- 核密度估计 Kernel Density Estimation (KDE) MATLAB
对于已经得到的样本集,核密度估计是一种可以求得样本的分布的概率密度函数的方法: 通过选取核函数和合适的带宽,可以得到样本的distribution probability,在这里核函数选取标准正态分布 ...
- <轻量算法>根据核密度估计检测波峰算法 ---基于有限状态自动机和递归实现
原创博客,转载请联系博主! 希望我思考问题的思路,也可以给大家一些启发或者反思! 问题背景: 现在我们的手上有一组没有明确规律,但是分布有明显聚簇现象的样本点,如下图所示: 图中数据集是显然是个3维的 ...
- Generative Adversarial Nets (GAN)
目录 目标 框架 理论 数值实验 代码 Generative Adversarial Nets 这篇文章,引领了对抗学习的思想,更加可贵的是其中的理论证明,证明很少却直击要害. 目标 GAN,译名生成 ...
随机推荐
- python爬虫的数据库连接问题
1.需要导的包 import pymysql 2.# mysql连接信息(字典形式) db_config ={ 'host': '127.0.0.1',#连接的主机id(107.0.0.1是本机id) ...
- MySQL 【常识与进阶】
MySQL 事物 InnoDB事务原理 事务(Transaction)是数据库区别于文件系统的重要特性之一,事务会把数据库从一种一致性状态转换为另一种一致性状态. 在数据库提交时,可以确保要么所有修改 ...
- css 固比固模型
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- Serverless与微服务
Serverless 是一个更大的范畴,Serverless 不只计算,也包括存储.数据库.中间件等各种服务.Serverless = FaaS(函数即服务) + BaaS(后端即服务).其中 Ser ...
- Spring MVC系列-(2) Bean的装配
2. Bean的装配 Spring容器负责创建应用程序中的bean,并通过DI来协调对象之间的关系.Spring提供了三种主要的装配机制: XML显式配置: Java配置类进行显式配置: 隐式的bea ...
- jQuery万能放大镜插件(普通矩形放大镜)
插件链接:http://files.cnblogs.com/files/whosMeya/magnifier.js 1.在jquery下插入. 2.格式:magnifier("需要插入的位置 ...
- C#读取静态类常量属性和值
1.背景最近项目中有一个需求需要从用户输入的值找到该值随对应的名字,由于其它模块已经定义了一份名字到值的一组常量,所以想借用该定义.2.实现实现的思路是采用C#支持的反射.首先,给出静态类中的常量属性 ...
- 都2020年了 还要学JSP吗?
前言 2020年了,还需要学JSP吗?我相信现在还是在大学的同学肯定会有这个疑问. 其实我在18年的时候已经见过类似的问题了「JSP还应该学习吗」.我在18年发了几篇JSP的文章,已经有不少的开发者评 ...
- Netty Hello World 入门源码分析
第一节简单提了什么是网络编程,Netty 做了什么,Netty 都有哪些功能组件.这一节就具体进入 Netty 的世界,我们从用 Netty 的功能实现基本的网络通信开始分析 各个组件的使用. 1. ...
- Magento2-2.3.4 win10安装完magento无法加载静态资源导致无法进入后台登录页面
后台面无法进入,截图如下