零基础使用Swift学习数据科学
概述
- Swift正迅速成为数据科学中最强大、最有效的语言之一
- Swift与Python非常相似,所以你会发现2种语言的转换非常平滑
- 我们将介绍Swift的基础知识,并学习如何使用该语言构建你的第一个数据科学模型
介绍
Python被广泛认为是数据科学中最好、最有效的语言。近年来我遇到的大多数调查都将Python列为这个领域的领导者。
但事实是数据科学是一个广阔并且不断发展的领域。我们用来构建数据科学模型的语言也会随之发展。还记得R是什么时候的流行语言吗?它很快就被Python超越了。Julia语言去年也出现在数据科学中。目前现在有另一种语言正在蓬勃发展。
是的,我说的是Swift语言。

"我总是希望当我开始学习一门新语言的时候,会有一些开阔思维的新想法,这点Swift绝对不会让我失望。Swift易于解释,并且灵活,简洁,安全,易于使用,快速。大多数其他语言在这些方面都有很大的限制。"——Jeremy Howard
当Jeremy Howard认可一种语言并开始在日常的数据科学工作中使用该语言时,你有必要开始思考这个语言的优点了。
在本文中,我们将了解Swift作为一种编程语言,以及它如何适应数据科学领域。如果你是Python用户,你将注意到两者之间的细微差别和惊人的相似之处。这里也有很多代码,让我们开始吧!
目录
- 为什么选择Swift?
- 数据分析的Swift基础
- 在Swift中使用Python库
- Swift中使用TensorFlow建立基本模型
- 数据科学Swift的未来
为什么选择Swift?
PyTorch是为了克服Tensorflow中的限制。但现在我们正接近Python的极限,而Swift有可能填补这一空白。"——Jeremy Howard
最近,Swift作为一种数据科学语言引起了很多人的兴奋和关注。每个人都在谈论它。以下是你应该学习Swift的几个理由:
- Swift快,很接近C的速度了
- 同时,它有一个非常简单和可读的语法,非常类似Python:

- 与Python相比,Swift是一种更高效、更稳定、更安全的编程语言
- 这也是一种很好的移动语言。事实上,它是为iPhone开发iOS应用程序的官方语言
- 它对自动微分有强大的集成支持,这使它成为为数不多的用于数值计算的高级语言之一
- 它背后有谷歌、Apple、FastAI等的支持!
以下是Jeremy Howard对Swift的评价视频:https://youtu.be/drSpCwDFwnM
数据分析的Swift基础
在我们开始使用Swift执行数据科学的细节之前,让我们简要介绍一下Swift编程语言的基础知识。
Swift的生态系统
当前数据科学的Swift主要由两个生态系统组成:
- 开源生态系统
- 苹果的生态系统

开源生态系统是我们可以下载并在任何操作系统或机器上运行Swift的地方。我们可以使用非常酷的Swift库来构建机器学习应用程序,比如用于TensorFlow的Swift、SwiftAI和SwiftPlot。
Swift还允许我们无缝地从Python中导入成熟的数据科学库,如NumPy、panda、matplotlib和scikit-learn。
另一方面,苹果的生态系统本身就令人印象深刻。有一些有用的库,比如CoreML,可以让我们用Python来训练大型模型,并直接将它们导入到Swift中进行推理。此外,它还提供了大量的预先训练过的先进模型,我们可以直接使用它们来构建iOS/macOS应用程序。

还有其他有趣的库,比如swift ,coreml,transformer,可以让我们在iPhone上运行最先进的文本生成模型,比如GPT-2、BERT等。

当你需要为Apple设备构建基于机器学习的应用程序时,还有许多其他的库可以提供良好的功能。
这两个生态系统之间存在多种差异。但最重要的是,为了使用苹果的生态系统,你需要有一台苹果的机器,你只能为苹果的设备开发,如iOS, macOS等。
既然你已经有了Swift作为数据科学语言的概述,让我们进入代码吧!
为Swift设置环境
Swift可用于谷歌Colab与GPU和TPU版本。我们将使用它,以便你可以快速跟上它的速度,而不必在安装过程中花费太多时间。

你可以按照下面的步骤打开一个Colab笔记本,这是快速激活的:
- 打开一个空白的Swift笔记本(https://colab.research.google.com/github/tensorflow/swift/blob/master/notebooks/blank_swift.ipynb)
- 点击"File",然后选择"Save a copy in Drive"-这将保存一个新的Swift笔记本在你自己的谷歌驱动器上!

- 已经准备好开始写Swift代码了,一下是第一行:
print("hello world from Swift")如果你想在你自己的系统上使用Swift,那么这里有一些你可以打开的链接:
- 如果你想在本地系统上安装Swift,你可以按照安装说明操作:https://swift.org/getting-started/#using-the-repl
- 在Ubuntu上安装Jupyter笔记本,请参考Jeremy Howard安装Swift的说明:https://forums.fast.ai/t/jeremys-harebrained-install-guide/43814
- 在Ubuntu上,你也可以用Docker安装Swift:https://github.com/apple/swift-docker
现在,让我们快速介绍一下一些基本的Swift函数,然后再进入使用它的数据科学功能。
打印功能
我相信你用过这个。它的工作方式与Python中非常相似。只需调用print(),在括号内输入你想打印的内容:
print("Swift is easy to learn!")Swift的变量
Swift提供了两个有用的选项来创建变量:let和var. let用来创建一个"常量",这个常量的值在程序的任何地方都不能改变。var与我们在Python中看到的变量非常相似——你可以在程序的任何时候更改存储在其中的值。
让我们看一个例子来看看区别。创建两个变量a和b:
let a = "Analytics"
var b = "Vidhya"现在,尝试改变a和b的值:
b = "AV"
a = "AV"你会注意到,b能够不报错的更新其值,而a则给出一个错误:

这种创建常量与变量的能力非常有用,可以帮助我们防止代码中出现看不见的bug。你将在本文中进一步看到,我们将使用let来创建存储重要信息并且不需要变更值的常量,
这里有一个技巧:使用var来创建你想使用一些中间计算的结果,因为这些中间计算结果需要改变。类似地,使用let来存储训练数据或者结果,这些数据基本上就是你不想更改或弄乱的值。
此外,Swift还有一个很酷的功能,你甚至可以使用表情符号作为变量名!

这是因为Swift非常支持Unicode,所以我们可以用希腊字母来创建变量:
var π= 3.1415925Swift的数据类型
Swift支持所有常见的数据类型,如整数、字符串、浮点数和双精度。我们可以赋值给任何变量,其类型会被Swift自动检测到:
let marks = 63
let percentage= 70.0
var name = "Sushil"你还可以在创建变量时显式地编写数据类型。这有助于防止程序中的错误,因为如果类型不匹配。Swift将抛出一个错误:
let weight: Double = 72.8可以做个小测验。创建一个显式类型为"Float"的值为4的常量,结果是会报错的。
有一种简单的方法可以将变量的值包含在字符串中,方法是将变量放在括号中,并在括号前写入反斜杠()。例如:

可以对占用多行的字符串使用三个双引号(""")。
列表和字典
Swift支持列表和字典数据结构,就像Python一样(这又是一个比较!)这里与Python不同,我们不需要像字典的"{}"和列表的"[]"这样的单独语法。
让我们用Swift创建一个列表和字典:
var shoppingList = ["catfish", "water", "tulips", "blue paint"]
shoppingList[1] = "bottle of water"
var occupationsDict = [
"Malcolm": "Captain",
"Kaylee": "Mechanic",
]我们可以通过在"[]"括号内写入索引或者键来访问列表或字典的元素(类似于Python):
occupationsDict["Jayne"] = "Public Relations"
print(occupationsDict)上面的代码将把"Jayne"和"Public Relations"的键值对添加到字典中。如果你打印以上的字典以下就是输出:

// Swift中的列表与字典
// 列表
var shoppingList = ["catfish", "water", "tulips", "blue paint"]
shoppingList[1] = "bottle of water"
print("List : ",shoppingList)
// 字典
var occupationsDict = [
"Malcolm": "Captain",
"Kaylee": "Mechanic",
]
occupationsDict["Jayne"] = "Public Relations"
print("Dictionary : " , occupationsDict)使用循环
循环是任何编程语言最重要的特性之一,Swift不会让你失望。它不仅支持所有传统的循环机制(for、while等),而且还实现了它自己的一些变体。
for..in 循环
非常类似于Python,你可以使用在Swift中的list或者range使用for循环:

第一个例子中的三个点表示Swift中的"range"。如果我们想做a到b范围内的事情,我们会使用a…b的语法。
类似地,如果我们想不要最后一个数字,我们可以把这三个点改成"..<"像"a.."。
这里需要注意的另一点是,与Python不同,Swift不使用缩进的概念,而是使用花括号"{}"来表示代码层次结构。
你可以在Swift中以类似的方式使用while和其他类型的循环。你可以这里了解更多关于循环的信息:https://docs.swift.org/swift-book/LanguageGuide/ControlFlow.html。
条件(if-else)
Swift支持条件语句,如if, if..else, if..else..if, 嵌套if甚至switch语句(Python不支持)。if语句的语法非常简单:
if boolean_expression {
/* statement(s) will execute if the boolean expression is true */
}boolean_expression可以是任何比较,只有在比较结果或表达式的计算结果为true时,才会执行if块中编写的语句。你可以在这里阅读其他条件语句:https://docs.swift.org/swift-book/LanguageGuide/ControlFlow.html。
函数
Swift函数在语法上与Python中的函数非常相似。这里的主要区别是我们使用了func关键字而不是def,并且我们明确地提到了参数的数据类型和函数的返回类型。
一个基本的函数如下:

和条件语句一样,我们使用花括号"{}"来表示属于这个函数的代码块。
用代码编写注释
编写注释是优秀代码最重要的方面之一。这适用于任何行业。这是你应该学习的最重要的编程技巧!
在你的代码里包含注释文本,作为对自己的注释或提醒。注释在编译时会被Swift忽略。
单行注释以两个斜杠(//)开头:
// 我是注释.多行注释以一个前斜杠和一个星号(/*)开始,以一个星号和一个前斜杠(*/)结束:
/* 我是多行
注释. */现在你已经熟悉了Swift的基础知识,让我们来学习一个有趣的功能——在Swift中使用Python库!
在Swift中使用Python库
Swift支持与Python的互操作性。这意味着你可以从Swift导入有用的Python库,调用它们的函数,并在Swift和Python之间无缝地切换。
这给了Swift的数据科学生态系统不可思议的力量。这个生态系统还很年轻,还在发展中,你已经可以使用成熟的库,如Numpy、panda和Python的Matplotlib来填补现有Swift产品的空白。
为了在Swift中使用Python的模块,你可以直接导入Python并加载任何你想要使用的库!
import Python
// 从python导入numpy
let np = Python.import("numpy")
// 创建0数组
var zeros = np.ones([2, 3])
print(zeros)这与你在Python中使用NumPy的方式非常相似,不是吗?你可以对其他包做同样的事情,如matplotlib:

你已经学了不少关于Swift的东西。现在是时候构建你的第一个模型了!
使用TensorFlow建立Swift的基本模型

Swift4Tensorflow是Swift开源生态系统中最成熟的库之一。我们可以使用一个非常简单的keras类语法很容易的建立机器学习和深度学习模型。
它变得更加有趣!Swift4Tensorflow不仅仅是对TensorFlow的快速包装,它还被开发为该语言本身的一个特性。人们普遍认为,在不久的将来,它将成为该语言的核心部分。
这意味着来自苹果公司的Swift团队和谷歌的Tensorflow团队的工程师将确保你能够在Swift中进行高性能的机器学习。
该库还向Swift添加了许多有用的特性,比如对自动微分的原生支持(这让我想起了PyTorch中的Autograd),从而使它与数值计算更加兼容。

关于数据集
让我们来理解一下我们将在本节中使用的问题陈述。如果你以前接触过深度学习领域,你可能对它很熟悉。
我们将构建一个卷积神经网络(CNN)模型,使用MNIST数据集将图像分类为数字。该数据集包含6万张训练图像和1万张手写数字测试图像,可用于训练图像分类模型:

这个数据集是处理计算机视觉问题的一个相当常见的数据集,所以我不打算详细描述它。
开始项目
在开始构建模型之前,我们需要下载数据集并对其进行预处理。为了方便你,我已经创建了一个GitHub存储库,里面预处理了代码和数据
下载安装代码,下载数据集,导入必要的库:
%include "EnableIPythonDisplay.swift"
IPythonDisplay.shell.enable_matplotlib("inline")
import Foundation
import Python
let os = Python.import("os")
let plt = Python.import("matplotlib.pyplot")
os.system("git clone https://github.com/mohdsanadzakirizvi/swift-datascience.git")
os.chdir("/content/swift-datascience")你的数据集现在将在Colab上下载。让我们加载数据集:
加载数据集
%include "/content/swift-datascience/MNIST.swift"
// 加载数据集
let dataset = MNIST(batchSize: 128)
// 获取前5张图
let imgs = dataset.trainingImages.minibatch(at: 0, batchSize: 5).makeNumpyArray()
print(imgs.shape)探索MNIST
我们将从数据集绘制一些图像,以了解我们的工作是什么:
// 显示前5张图
# Display first 5 images
for img in imgs{
plt.imshow(img.reshape(28,28))
plt.show()
}这是我们的图像是这样的:
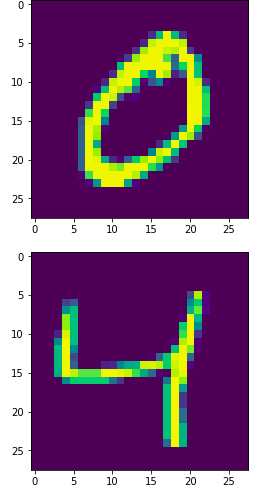
看起来很直观,对吧?第一个数字是手写的0,第二个数字是4。
定义模型的结构
现在让我们定义模型的体系结构。我使用的是LeNet-5架构,这是一个非常基础的CNN模型,使用了2个卷积层,平均池化层和3个全连接层。
最后一个全连接层的形状是10,因为我们有10个目标类,每个数字一个从0到9:
import TensorFlow
let epochCount = 100
let batchSize = 128
// LeNet-5架构
var classifier = Sequential {
Conv2D<Float>(filterShape: (5, 5, 1, 6), padding: .same, activation: relu)
AvgPool2D<Float>(poolSize: (2, 2), strides: (2, 2))
Conv2D<Float>(filterShape: (5, 5, 6, 16), activation: relu)
AvgPool2D<Float>(poolSize: (2, 2), strides: (2, 2))
Flatten<Float>()
Dense<Float>(inputSize: 400, outputSize: 120, activation: relu)
Dense<Float>(inputSize: 120, outputSize: 84, activation: relu)
Dense<Float>(inputSize: 84, outputSize: 10, activation: softmax)
}你可能已经注意到,这些代码看起来非常类似于Keras、PyTorch或TensorFlow等Python框架中。
编写代码的简单性是Swift最大的卖点之一。
Swift4Tensorflow你可以在这里阅读更多关于它的信息:https://www.tensorflow.org/swift/api_docs/Structs
选择梯度下降作为优化器
类似地,我们需要一个优化器函数来训练我们的模型。我们将使用Swift4Tensorflow中提供的随机梯度下降(SGD):
Swift4Tensorflow支持许多额外的优化器。你可以根据你的项目选择:
- AMSGrad
- AdaDelta
- AdaGrad
- AdaMax
- Adam
- Parameter
- RMSProp
- SGD
模型训练
现在一切都设置好了,让我们来训练模型!
print("Beginning training...")
struct Statistics {
var correctGuessCount: Int = 0
var totalGuessCount: Int = 0
var totalLoss: Float = 0
}
// 训练期间存储准确性结果
var trainAccuracyResults: [Float] = []
var testAccuracyResults: [Float] = []
// 训练循环
for epoch in 1...epochCount {
var trainStats = Statistics()
var testStats = Statistics()
// 设置训练环境
Context.local.learningPhase = .training
for i in 0 ..< dataset.trainingSize / batchSize {
// 得到小批量的x和y
let x = dataset.trainingImages.minibatch(at: i, batchSize: batchSize)
let y = dataset.trainingLabels.minibatch(at: i, batchSize: batchSize)
// 计算关于模型的梯度。
let
零基础使用Swift学习数据科学的更多相关文章
- 【转载】salesforce 零基础开发入门学习(六)简单的数据增删改查页面的构建
salesforce 零基础开发入门学习(六)简单的数据增删改查页面的构建 VisualForce封装了很多的标签用来进行页面设计,本篇主要讲述简单的页面增删改查.使用的内容和设计到前台页面使用的 ...
- 【转载】salesforce 零基础开发入门学习(五)异步进程介绍与数据批处理Batchable
salesforce 零基础开发入门学习(五)异步进程介绍与数据批处理Batchable 本篇知识参考:https://developer.salesforce.com/trailhead/for ...
- (转)零基础入门深度学习(6) - 长短时记忆网络(LSTM)
无论即将到来的是大数据时代还是人工智能时代,亦或是传统行业使用人工智能在云上处理大数据的时代,作为一个有理想有追求的程序员,不懂深度学习(Deep Learning)这个超热的技术,会不会感觉马上就o ...
- 【转载】salesforce 零基础开发入门学习(四)多表关联下的SOQL以及表字段Data type详解
salesforce 零基础开发入门学习(四)多表关联下的SOQL以及表字段Data type详解 建立好的数据表在数据库中查看有很多方式,本人目前采用以下两种方式查看数据表. 1.采用schem ...
- 【转载】salesforce 零基础开发入门学习(三)sObject简单介绍以及简单DML操作(SOQL)
salesforce 零基础开发入门学习(三)sObject简单介绍以及简单DML操作(SOQL) salesforce中对于数据库操作和JAVA等语言对于数据库操作是有一定区别的.salesfo ...
- 【转载】salesforce 零基础开发入门学习(二)变量基础知识,集合,表达式,流程控制语句
salesforce 零基础开发入门学习(二)变量基础知识,集合,表达式,流程控制语句 salesforce如果简单的说可以大概分成两个部分:Apex,VisualForce Page. 其中Apex ...
- 零基础要怎么样学习嵌入式Linux--走进嵌入式
零基础要怎么样学习嵌入式希望可以通过这一篇帖子让大家走进嵌入式,对嵌入式的学习不再那么陌生. 嵌入式Linux工程师的学习需要具备一定的C语言基础,因此面对许多朋友只是在大一或者大二学习过C(还不一定 ...
- 零基础如何系统学习Java Web
零基础如何系统学习Java Web? 我来给你说一说 你要下决心,我要转行做开发,这样你才能学成. 你要会打字,我公司原来有一个程序员,打字都是两个手一指禅,身为程序员你一指禅怎么写出的代码,半个 ...
- C#区块链零基础入门,学习路线图 转
C#区块链零基础入门,学习路线图 一.1分钟短视频<区块链100问>了解区块链基本概念 http://tech.sina.com.cn/zt_d/blockchain_100/ 二.C#区 ...
随机推荐
- PHP时区转换(默认中国时区<Asia/Shanghai>转意大利时区<Europe/Rome>)
<?php function changeTimeZone($date_time, $format = 'Y-m-d H:i:s', $to = 'Europe/Rome', $from = ' ...
- Vue2.0组件的继承与扩展
如果有需要源代码,请猛戳源代码 希望文章给大家些许帮助和启发,麻烦大家在GitHub上面点个赞!!!十分感谢 前言 本文将介绍vue2.0中的组件的继承与扩展,主要分享slot.mixins/exte ...
- vue 实现 裁切图片 同时有放大、缩小、旋转功能
实现效果: 裁切指定区域内的图片 旋转图片 放大图片 输出bolb 格式数据 提供给 formData 对象 效果图 大概原理: 利用h5 FileReader 对象, 获取 <input ty ...
- 【工具】---- webpack简析
1. 什么是webpack 一个现代 JavaScript 应用程序的静态模块打包器(module bundler),它会分析你的项目结构,找到JavaScript模块以及其它的一些浏览器不能直接运行 ...
- RAC修改VIP地址
目录 当前环境 1.通过[srvctl config]确认当前VIP地址. 2.关闭dbconsole[对应的em] 3.关闭数据库实例 4.关闭asm实例 5.关闭结点服务 6.修改两个节点的/et ...
- 将root用户权限赋予普通用户
将root用户权限赋予普通用户 普通用户想要拥有root用户的权限,必须修改/etc/sudoers文件 ,还必须使用visudo命令修改.一是因为这个命令能防止多个用户同时修改这个文件,二是能进行有 ...
- 结巴分词demo
#encoding=utf-8 from __future__ import unicode_literals import sys sys.path.append("../") ...
- Druid 0.17 入门(3)—— 数据接入指南
在快速开始中,我们演示了接入本地示例数据方式,但Druid其实支持非常丰富的数据接入方式.比如批处理数据的接入和实时流数据的接入.本文我们将介绍这几种数据接入方式. 文件数据接入:从文件中加载批处理数 ...
- C++ 重载关系操作符
#include <iostream> using namespace std; class AAA { public: AAA() //默认构造 { } AAA(int id, stri ...
- 【WPF学习】第五十九章 理解控件模板
最近工作比较忙,未能及时更新内容,敬请了解!!! 对于可视化树的分析引出了几个有趣问题.例如,控件如何从逻辑树表示扩张成可视化树表示? 每个控件都有一个内置的方法,用于确定如何渲染控件(作为一组更基础 ...