在Cortex-M系列上如何准确地做us级延时?
前几天刚好同事问起在Cortex-M上延时不准的问题,在网上也没找到比较满意的答案,干脆自己对这个问题做一个总结。
根据我们的经验,最容易想到的大概通过计算指令周期来解决。该思路在Cortex上并不是很适用:一方面MCU从Flash取指是有延时的,另一方面Cortex的指令集不是固定周期的,特别从M3加入分支预测后,分支指令在Cortex-M不同型号上的结果都不相同。因此除了指令周期外,我们需要考虑的东西还有很多,才能得到正确的结果。
不带分支预测器的情况
仍然先从不带分支预测器的Cortex-M0开始,通过计算指令周期延时的实现代码如下:
void delay_us(us) {
delay_ntimes((us * sysclk - 8) / 4);
}
__asm void delay_ntimes(unsigned int n)
{
L1
SUBS R0, #1
BCS L1
BX LR
}
从这段代码可发现两个主要问题:
一、delay_us里的公式是怎么来的:
假如想延时us微秒,系统时钟为48MHz,即sysclk=48,那么周期数period_count满足以下公式:
period_count = us * sysclk;
然后再delay_ntimes这个函数,又能推出period_count还满足以下公式(见第二个问题的分析):
period_count = 8 + 4 *n
于是:
n = (us * sysclk - 8 ) / 4;
这就解决了第一个问题,需要注意的是:该公式忽略了跳转到delay_us和(us * sysclk -8 )/4的几个固定周期。
二、delay_ntimes的周期数怎么算:
它的周期数满足以下公式:
period_count = 8 + 4 * n;
这个要根据指令集的周期数来确定,请看下表:
| 操作 | 描述 | 汇编命令 | 周期 |
|---|---|---|---|
| Subtract | Lo to Lo | SUBS Rd,Rn,Rm | 1 |
| 3-bit immediate | SUBS Rd,Rn,#<imm> | 1 | |
| 8-bit immediate | SUBS Rd,Rd,#<imm> | 1 | |
| Branch | Conditional | B<cc> <label> | 1或3 |
| Unconditional | B<label> | 3 | |
| With link | BL<label> | 4 | |
| With exchange | BX Rm | 3 | |
| With link and exchange | BLX Rm | 3 |
先考虑n为0的情况,
SUBS为1周期+BCS为1周期+BX为3周期+外层调用delay_times(相当于BLX指令)的3周期=8周期。
当n不为0时,将再执行n次SUBS和BCS执行,SUBS仍为1周期,BCS有跳转3周期,所以是4n个周期,因此该函数的执行周期数为:
period_count=8+4n;
好了,在了解了原理之后,是时候到真正的板子上去测试了。
然而在MCU上的实测结果却不如预期,延时5MS,实测为7.5MS;延时10MS,实测15MS。为什么会出现这样的现象?
这个跟MCU的设计有关。一般代码都放在FLASH上,MCU中Cortex核要从FLASH上先取出指令,然后才能将指令放到指令流水线上执行。而上面的分析忽略了Cortex核从FLASH取出指令的时间,因此实测值与理论值分析不一致。
不同的MCU从FLASH读取指令的时间消耗各不相同,因此需要根据不同MCU去调整公式,这是一个比较繁琐的过程,比如这款MCU,将公式修改为(us * sysclk - 8) / 6就得到了正确结果。
另外一个做法是不修改公式,将延时代码放到RAM中,许多MCU从RAM取出指令没有等待周期。使用该方法再次测试,延时结果与理论计算一致。
但值得注意的是,不是所有MCU都满足RAM取值零等待周期的条件,因此一定要做测试。
读者若对MCU如何从FLASH读取指令感兴趣,参考资料[4]的分析是比较清楚的。
带分支预测器的情况
将上面的代码放到Cortex-M3和Cortex-M4的芯片上测试,测试结果是错误的,不论在FLASH还是在RAM中,这个是由于Cortex-M3,Cortex-M4上的指令流水线带有分支预测器引起的。
要了解分支预测器,就不得不提指令流水线。Cortex-M3是三级流水线:取指,解码,执行。但是没找到CORTEX方面较好的图,以下讨论就基于下图的4级流水线,该图多了一步:写回。这并不影响我们的讨论。
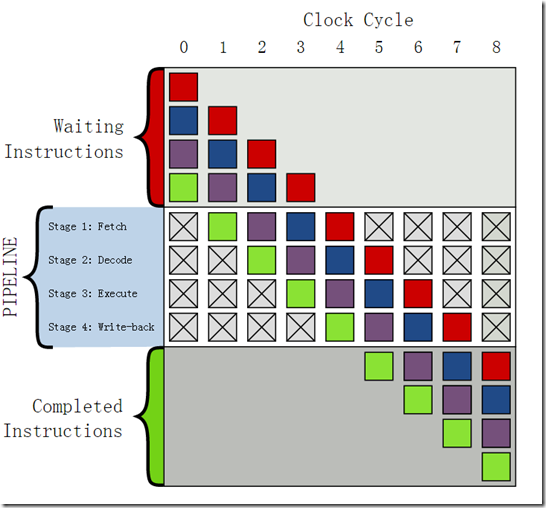
(该图引用自参考资料[1])
假设一条指令从执行开始到执行结束需要4个时钟周期,在没有流水线的情况下,需要等待第一条指令执行结束,才能取第二条指令,这时两条指令就用了8个周期,效率是很低的。
引入4级流水线将指令拆成4个步骤:取指、解码、执行、写回。当第一条指令处于解码时,同时对第二条指令取指;对第一条指令执行时,同时对第二条指令解码,对第三条指令取指;对第一条指令写回时,同时对第二条执行,第三条解码,第四条取指;如此这般。最终达到的效果就如上图所示,只有第一条指令需要4个周期,其他后续的指令都只需要1个周期,极大地提高了处理效率。
流水线的高效率是基于指令顺序执行的前提,在执行跳转指令时,流水线将被清空,又回到了上图中的第一步,跳转后的第一条指令要执行仍然需要4周期。因此如果程序频繁跳转,流水线的作用就大打折扣。
为了解决这个问题,就引入了分支预测器:它会提前检测到跳转指令,并根据预判结果取指。如果预判结果是不跳转,就按顺序取下一条指令;如果预判结果是跳转,就从跳转的目的地址取下一条指令。假如预测对了,那么流水线就不会被清空,仍然可以一条指令1个周期;如果预测错了,下一条指令仍然要4周期。从这里看出,分支预测器对于提高流水线效率是有帮助的。值得一提的是,预判对了能减少指令延迟,但是否是零延迟取决于MCU的设计;预判错了清空流水线也未必是唯一的做法,同样取决于MCU的设计。
回到Cortex-M3的延时问题,网络上找到的资料提到分支预测器将延迟减小到1个周期,没有找到更详细的说明。那么理论上计算公式就应该调整为(us * sysclk - 8) / 3,在两款Cortex-M3和两款Cortex-M4上测试,测试结果与理论值一致。
微秒级精确延时的其他方法
对于Cortex而微秒级延时最通用的方法,大概便是通过比较SysTick的SYST_CVR寄存器来做延时,理论误差在1us内(基于48MHz主频)。以下为实现代码:
/*
* 使用SysTick的CVR实现微秒级精确延时,一般SysTick周期设置为10MS,因此该方法适用于10MS以内的延时
*/
void delay_us(int us) {
unsigned t1, t2, count, delta, sysclk;
sysclk = 48;//假设为48MHz主频
t1 = SYST_CVR;
while (1) {
t2 = SYST_CVR;
delta = t2 < t1 ? (t1 - t2) : (SYST_RVR - t2 + t1) ;
if (delta >= us * sysclk)
break;
}
}
其他补充点
- 本文假设在延时过程中没有产生任何中断,如果有中断产生,将影响延时精确性。
- 这部分的内容属于计算机体系结构。
- 以上测试时间范围在[0,10MS),该范围之外未详细测试,建议采用其他方法。
- 覆盖测试的MCU:1款Cortex-M0,2款Cortex-M3,2款Cortex-M4。
- 在我测试的两款Cortex-M3 MCU上,将代码都放RAM上,测试结果比放在FLASH差,而在Cortex-M4 MCU上,测试结果都一样,目前没有找到合理的解释。
参考资料
- 浅谈分支预测、流水线与条件转移
- Cortex-M0指令集
- CPU性能衡量参数-主频,MIPS,CPI,时钟周期,机器周期,指令周期
- Cortex-M3的周期判断的依据是什么
- 计算机体系结构——流水线中的相关——延迟分支方法
在Cortex-M系列上如何准确地做us级延时?的更多相关文章
- ARM linux电源管理——Cortex A系列CPU(32位)睡眠和唤醒的底层汇编实现
ARM linux电源管理——Cortex A系列CPU(32位)睡眠和唤醒的底层汇编实现 承接 http://www.wowotech.net/pm_subsystem/suspend_and_re ...
- 手牵手,使用uni-app从零开发一款视频小程序 (系列上 准备工作篇)
系列文章 手牵手,使用uni-app从零开发一款视频小程序 (系列上 准备工作篇) 手牵手,使用uni-app从零开发一款视频小程序 (系列下 开发实战篇) 前言 好久不见,很久没更新博客了,前段时间 ...
- 痞子衡嵌入式:揭秘i.MXRTxxx系列上串行NOR Flash双程序可交替启动设计
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是i.MXRT500/600上串行NOR Flash双程序可交替启动设计. 在上一篇文章 <i.MXRT1170上串行NOR Fla ...
- 对服务器上所有Word文件做全文检索的解决方案-Java
一.背景介绍 Word文档与日常办公密不可分,在实际应用中,当某一文档服务器中有很多Word文档,假如有成千上万个文档时,用户查找打开包含某些指定关键字的文档就变得很困难,目前这一问题没有好的解 ...
- 【ABAP系列】SAP ABAP 模拟做成像windows一样的计算器
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[MM系列]SAP ABAP 模拟做成像wind ...
- ARM Cortex M3系列GPIO口介绍(工作方式探讨)
一.Cortex M3的GPIO口特性 在介绍GPIO口功能前,有必要先说明一下M3的结构框图,这样能够更好理解总线结构和GPIO所处的位置. Cortex M3结构框图 从图中可以看出 ...
- 2019 Power BI最Top50面试题,助你面试脱颖而出系列<上>
距离4月还剩11天, 你是否还在投简历找工作而机会寥寥? 你是否还在四处奔波疲于面试而结果不意? ....... 知否知否, 天下武功唯快不破, 传说江湖有本Power BI 面试真香秘籍, 能助你快 ...
- Redis系列9:Geo 类型赋能亿级地图位置计算
Redis系列1:深刻理解高性能Redis的本质 Redis系列2:数据持久化提高可用性 Redis系列3:高可用之主从架构 Redis系列4:高可用之Sentinel(哨兵模式) Redis系列5: ...
- Android开发-mac上使用三星S3做真机调试
之前一直未使用真机进行Android开发,为准备明天的培训,拿出淘汰下来的s3准备环境,竟然发现无法连接mac,度娘一番找到答案,如下:mac 系统开发android,真机调试解决方案(无数的坑之后吐 ...
随机推荐
- Android之仿ele地图定位效果
PS:最近项目要求,希望在选择地址的时候能够仿ele来实现定位效果.因此就去做了一下.不过ele使用高德地图实现的,我是用百度地图实现的.没办法,公司说用百度那就用百度的吧.个人觉得高德应该更加的精准 ...
- Azure ARM (13) 从现有VHD文件,创建新的ARM VM
<Windows Azure Platform 系列文章目录> 本文参考了Git Hub的ARM Template: https://github.com/Azure/azure-quic ...
- 多条asp.net网站的优化建议
一.返回多个数据集 检查你的访问数据库的代码,看是否存在着要返回多次的请求.每次往返降低了你的应用程序的每秒能够响应请求的次数.通过在单个数据库请求中返回多个结果集,可以减少与数据库通信的时间,使你的 ...
- 异步编程系列06章 以Task为基础的异步模式(TAP)
p { display: block; margin: 3px 0 0 0; } --> 写在前面 在学异步,有位园友推荐了<async in C#5.0>,没找到中文版,恰巧也想提 ...
- C#中正则表达式在replace中的应用!
多少年来,许多的编程语言和工具都包含对正则表达式的支持,.NET基础类库中包含有一个名字空间和一系列可以充分发挥规则表达式威力的类,而且它们也都与未来的Perl 5中的规则表达式兼容. 此外, ...
- HTTP文件断点续传的原理
前几天一个同事跑过来找我说,我们在广告素材视频这块想做断点续传,就是这次某个视频缓存到一半,下次不用重头开始,可以在原来停留得位置开始继续下载.以提供更好的用户体验. 同时说需要我们支持吐素材地址的业 ...
- navicat怎么导出和导入数据表
1.选中要导出的数据表,右击,然后点击"导出向导". 2.点击sql脚本文件(*sql)->点击下一步. 3.点击保存位置->下一步->保存 ********** ...
- 【linux草鞋应用编程系列】_4_ 应用程序多线程
一.应用程序多线程 当一个计算机上具有多个CPU核心的时候,每个CPU核心都可以执行代码,此时如果使用单线程,那么这个线程只能在一个 CPU上运行,那么其他的CPU核心就处于空闲状态,浪费了系 ...
- AbstractFactoryPattern(抽象工厂)
/** * 抽象工厂模式 * 分为四部分 * 1.产品接口 * 2.产品实例 * 3.工厂接口(生产同一个产品的不同等级,这里是主要区别) * 4.工厂实例 * 工厂类最好用单例模式,但在这里主要是说 ...
- ABP 初探 之 AbpSession 扩展
Abp的权限管理是基于 Identity,所有的扩展也是基于 claims .claims 有许多默认属性,具体连接 关于 Identity的详细介绍,可以参考园友博客 继承 Microsoft.As ...