【Hadoop离线基础总结】Apache Hadoop的三种运行环境介绍及standAlone环境搭建
Apache Hadoop的三种运行环境介绍及standAlone环境搭建
三种运行环境
- standAlone环境
单机版的hadoop运行环境 - 伪分布式环境
主节点都在一台机器上,从节点分开到其他机器上(可以借助三台机器来实现) - 完全分布式环境
主节点全部分散到不同机器上(NameNode Active,NameNode StandBy,ResourceManager 主节点,ResourceManager 备份节点)
standAlone环境搭建
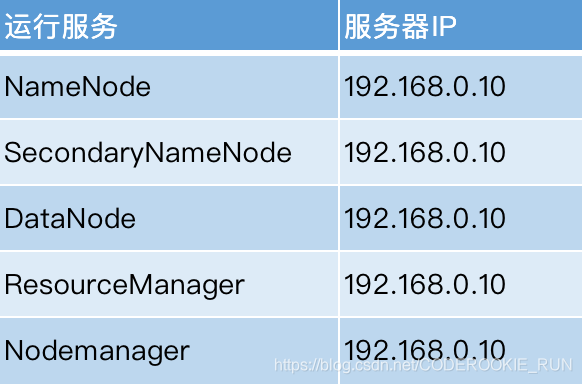
- 第一步:下载apache hadoop并上传到服务器
下载链接:http://archive.apache.org/dist/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gz
上传到/export/softwares/,并解压到/export/servers/
tar -zxvf hadoop-2.7.5.tar.gz -C /export/servers/
Hadoop的本地库:/export/servers/hadoop-2.7.5/lib/native
(很重要,里面集成了一些C程序,包括了一些压缩的支持)
bin/hadoop checknative 检测本地库的支持

- 第二步:修改配置文件
cd /export/servers/hadoop-2.7.5/etc/hadoop
修改core-site.xml(核心配置文件,主要定义了我们的集群是分布式,还是本机运行)
vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.0.10:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.7.5/hadoopDatas/tempDatas</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
修改hdfs-site.xml(分布式文件系统的核心配置,决定了我们数据存放在哪个路径,数据的副本,数据的block块大小)
vim hdfs-site.xml
<configuration>
<!-- NameNode存储元数据信息的路径,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<!-- 集群动态上下线
<property>
<name>dfs.hosts</name>
<value>/export/servers/hadoop-2.7.4/etc/hadoop/accept_host</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/export/servers/hadoop-2.7.4/etc/hadoop/deny_host</value>
</property>
-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas,file:///export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2</value>
</property>
<!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas,file:///export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/nn/edits</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/snn/name</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/dfs/snn/edits</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
修改hadoop-env.sh(配置我们jdk的home路径)
vim hadoop-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
修改mapred-site.xml(定义了我们关于mapreduce运行的一些参数)
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
</configuration>
修改yarn-site.xml(定义我们的yarn集群)
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
修改slaves(定义了我们的从节点是哪些机器,也就是DataNode和NodeManager运行在哪些机器上)
vim slaves
node01
- 第三步:启动集群
要启动Hadoop集群,需要启动HDFS和YARN两个模块
注意:首次启动HDFS时,必须对其进行格式化操作,本质上是一些清理和准备工作,因为此时的HDFS在物理上还是不存在的
hdfs namenode -format或者hadoop namenode -format
启动命令:
创建数据存放文件夹,在第一台机器执行
cd /export/servers/hadoop-2.7.5/
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/tempDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/nn/edits
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/snn/name
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/dfs/snn/edits
准备启动:
cd /export/servers/hadoop-2.7.5/
bin/hdfs namenode -format
sbin/start-dfs.sh
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver
tips
HDFS集群查看界面:node01:50070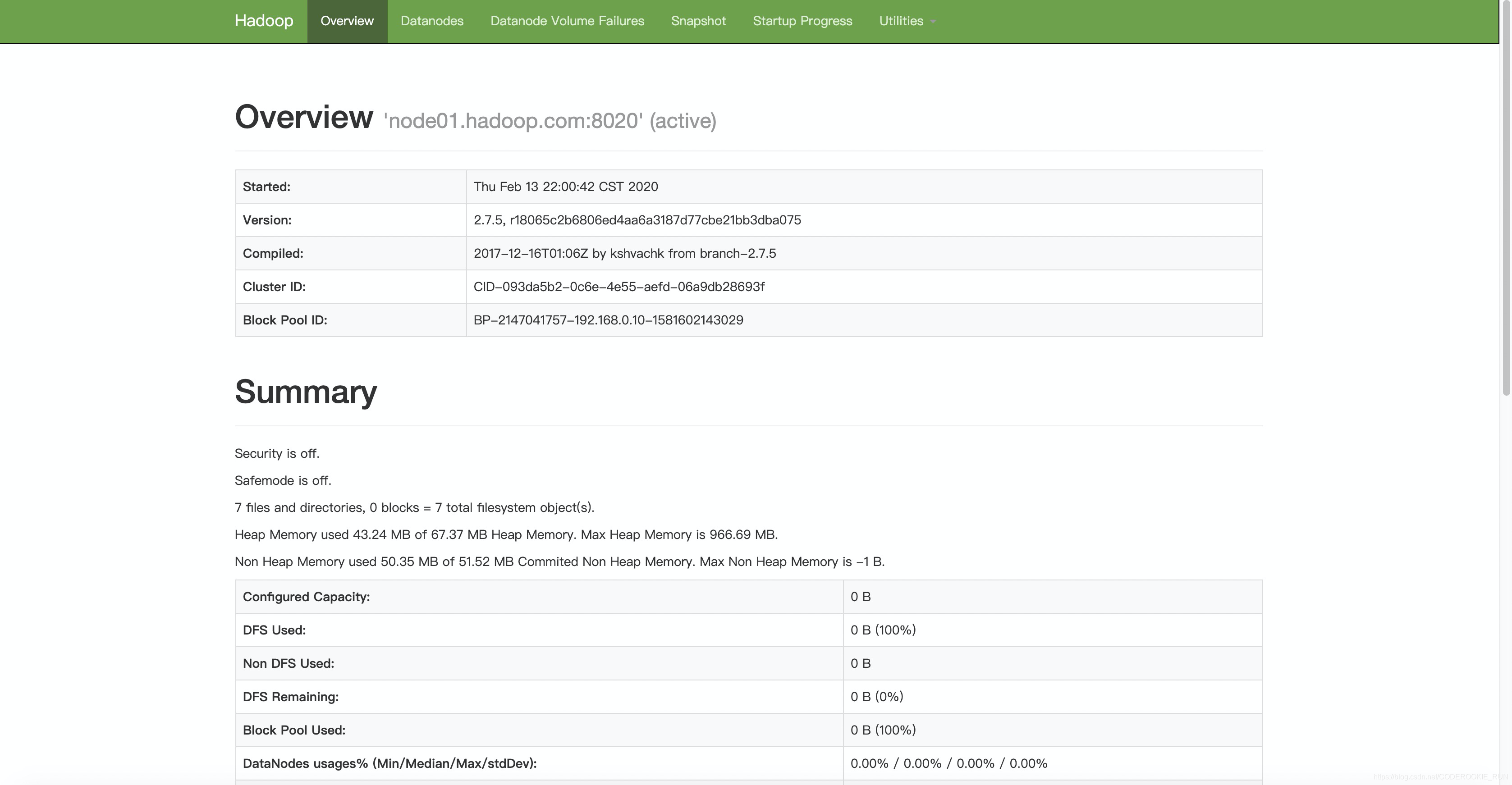
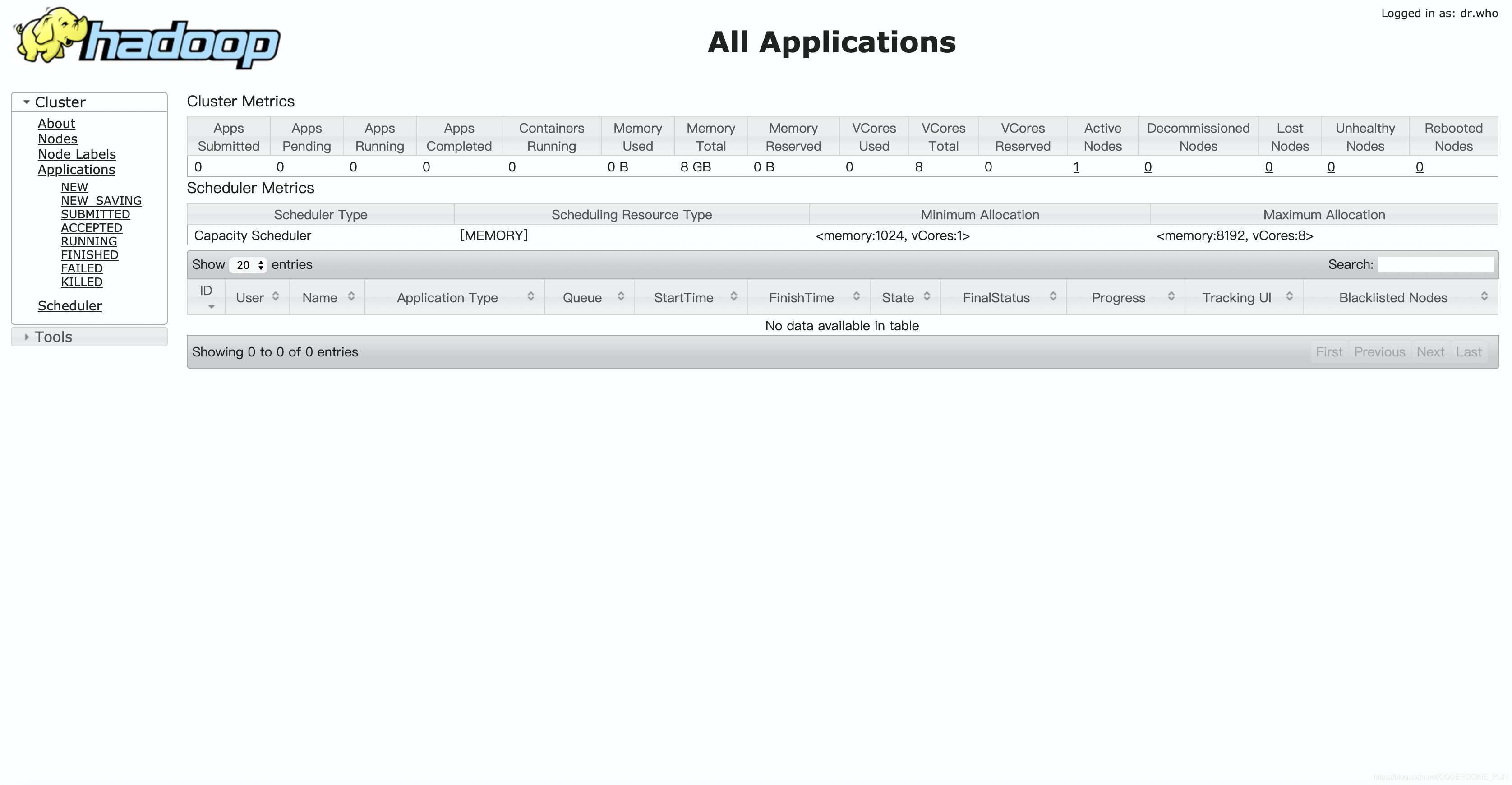
Yarn集群查看界面:node01:8088
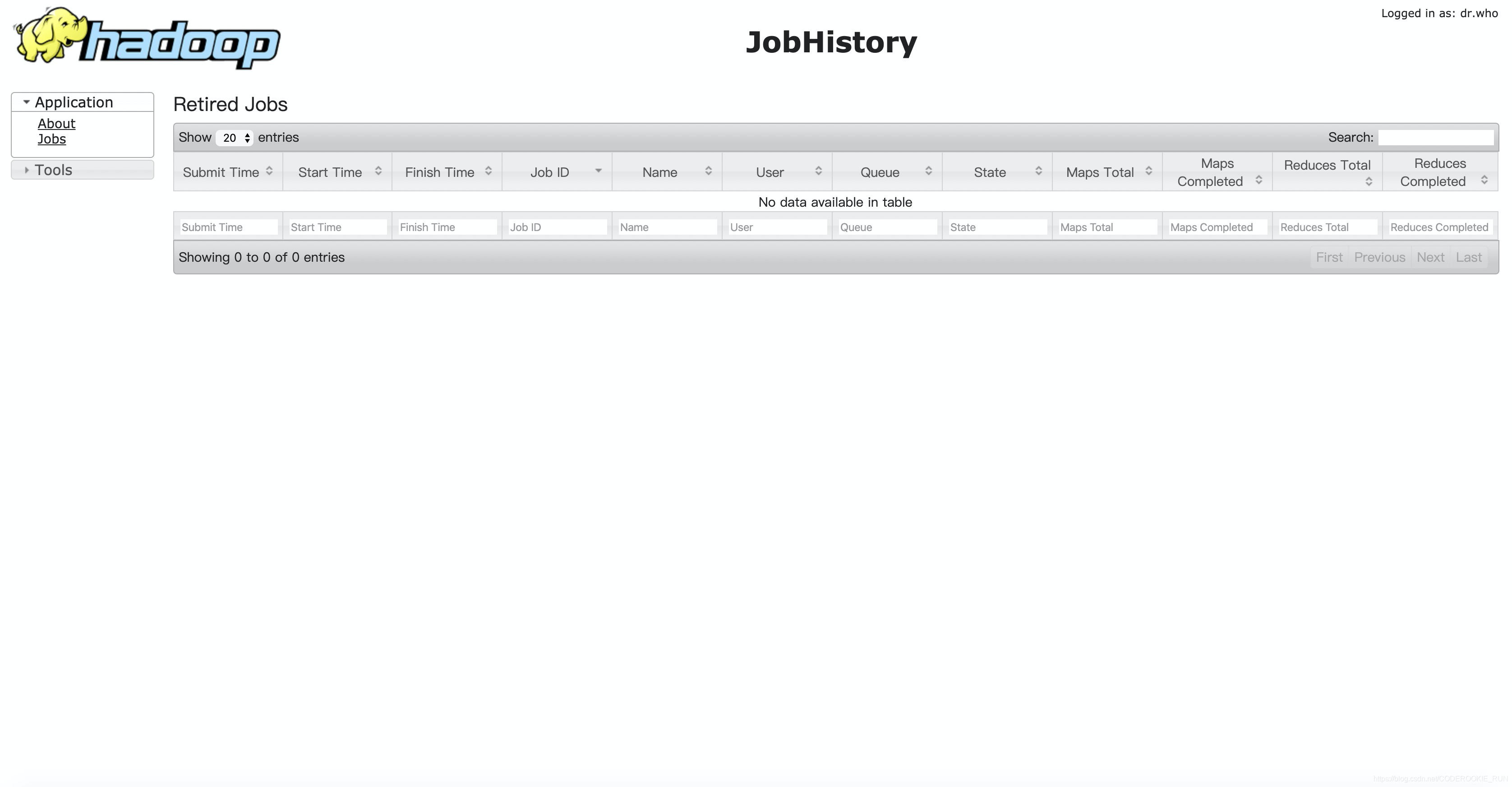
历史任务完成界面:node01:19888
【Hadoop离线基础总结】Apache Hadoop的三种运行环境介绍及standAlone环境搭建的更多相关文章
- 【Hadoop离线基础总结】Hadoop High Availability\Hadoop基础环境增强
目录 简单介绍 Hadoop HA 概述 集群搭建规划 集群搭建 第一步:停止服务 第二步:启动所有节点的ZooKeeper 第三步:更改配置文件 第四步:启动服务 简单介绍 Hadoop HA 概述 ...
- 【Hadoop离线基础总结】Hadoop的架构模型
Hadoop的架构模型 1.x的版本架构模型介绍 架构图 HDFS分布式文件存储系统(典型的主从架构) NameNode:集群当中的主节点,主要用于维护集群当中的元数据信息,以及接受用户的请求,处理用 ...
- 【Hadoop离线基础总结】impala简单介绍及安装部署
目录 impala的简单介绍 概述 优点 缺点 impala和Hive的关系 impala如何和CDH一起工作 impala的架构及查询计划 impala/hive/spark 对比 impala的安 ...
- 【Hadoop离线基础总结】Hive调优手段
Hive调优手段 最常用的调优手段 Fetch抓取 MapJoin 分区裁剪 列裁剪 控制map个数以及reduce个数 JVM重用 数据压缩 Fetch的抓取 出现原因 Hive中对某些情况的查询不 ...
- 【Hadoop离线基础总结】流量日志分析网站整体架构模块开发
目录 数据仓库设计 维度建模概述 维度建模的三种模式 本项目中数据仓库的设计 ETL开发 创建ODS层数据表 导入ODS层数据 生成ODS层明细宽表 统计分析开发 流量分析 受访分析 访客visit分 ...
- 【Hadoop离线基础总结】MapReduce自定义InputFormat和OutputFormat案例
MapReduce自定义InputFormat和OutputFormat案例 自定义InputFormat 合并小文件 需求 无论hdfs还是mapreduce,存放小文件会占用元数据信息,白白浪费内 ...
- 【Hadoop离线基础总结】MapReduce入门
MapReduce入门 Mapreduce思想 概述 MapReduce的思想核心是分而治之,适用于大量复杂的任务处理场景(大规模数据处理场景). 最主要的特点就是把一个大的问题,划分成很多小的子问题 ...
- 【Hadoop离线基础总结】oozie的安装部署与使用
目录 简单介绍 概述 架构 安装部署 1.修改core-site.xml 2.上传oozie的安装包并解压 3.解压hadooplibs到与oozie平行的目录 4.创建libext目录,并拷贝依赖包 ...
- 【Hadoop离线基础总结】Hue的简单介绍和安装部署
目录 Hue的简单介绍 概述 核心功能 安装部署 下载Hue的压缩包并上传到linux解压 编译安装启动 启动Hue进程 hue与其他框架的集成 Hue与Hadoop集成 Hue与Hive集成 Hue ...
随机推荐
- GeoGebra小制作
效果 文件链接https://www.geogebra.org/m/bkxrjymh
- 【Jenkins】插件更改国内源
最近调试脚本,本机安装了Jenkins,但是安装插件时一直失败.更改升级站点也不生效,究其原因是因为default.json中插件下载地址还https://updates.jenkins.io,升级站 ...
- F. Count Prime Pairs
单点时限: 2.0 sec 内存限制: 512 MB 对于数组a,如果i≠j并且ai+aj是一个质数,那么我们就称(i,j)为质数对,计算数组中质数对的个数. 输入格式 第一行输入一个n,表示数组的长 ...
- PIL库之图片处理
(1)对图片生成缩略图 from PIL import Image im = Image.open("C:\Users\litchi\Desktop\picture1.jpg") ...
- Matlab学习-(3)
1. 二维图 绘制完图形以后,可能还需要对图形进行一些辅助操作,以使图形意义更加明确,可读性更强. 1.1 图形标注 title(’图形名称’) (都放在单引号内)xlabel(’x轴说明’)ylab ...
- 详解 ServerSocket与Socket类
(请观看本人博文 -- <详解 网络编程>) 目录 ServerSocket与Socket ServerSocket 类: Socket类: ServerSocket与Socket 首先, ...
- ES6新增的Map和WeakMap 又是什么玩意?非常详细的解释
上一篇文章讲了set和weakSet,这节咱就讲Map和weakMap是什么?这两篇文章并没有什么联系,主要知识用法类似而已.嘿嘿,是不是感觉舒服多了. 什么是Map 介绍什么是Map,就不得不说起O ...
- 萌新带你开车上p站(番外篇)
本文由“合天智汇”公众号首发,作者:萌新 前言 这道题目应该是pwnable.kr上Toddler's Bottle最难的题目了,涉及到相对比较难的堆利用的问题,所以拿出来分析. 登录 看看源程序 程 ...
- Metasploit渗透测试环境搭建
渗透测试实验环境搭建 下载虚拟机镜像 5个虚拟机镜像,其中Linux攻击机我选择用最新的kali Linux镜像,其余的均使用本书配套的镜像. 网络环境配置 VMware虚拟网络编辑器配置: 将VMn ...
- 如何在 Inno Setup 中执行命令行的命令
Pascal Scripting: Exec Prototype: function Exec(const Filename, Params, WorkingDir: String; const Sh ...