吴裕雄--天生自然python编程:实例(3)
# 返回 x 在 arr 中的索引,如果不存在返回 -1
def binarySearch (arr, l, r, x): # 基本判断
if r >= l: mid = int(l + (r - l)/2) # 元素整好的中间位置
if arr[mid] == x:
return mid # 元素小于中间位置的元素,只需要再比较左边的元素
elif arr[mid] > x:
return binarySearch(arr, l, mid-1, x) # 元素大于中间位置的元素,只需要再比较右边的元素
else:
return binarySearch(arr, mid+1, r, x) else:
# 不存在
return -1 # 测试数组
arr = [ 2, 3, 4, 10, 40 ]
x = 10 # 函数调用
result = binarySearch(arr, 0, len(arr)-1, x) if result != -1:
print ("元素在数组中的索引为 %d" % result )
else:
print ("元素不在数组中")

def search(arr, n, x):
for i in range (0, n):
if (arr[i] == x):
return i;
return -1;
# 在数组 arr 中查找字符 D
arr = [ 'A', 'B', 'C', 'D', 'E' ];
x = 'D';
n = len(arr);
result = search(arr, n, x)
if(result == -1):
print("元素不在数组中")
else:
print("元素在数组中的索引为", result);

def insertionSort(arr):
for i in range(1, len(arr)):
key = arr[i]
j = i-1
while j >=0 and key < arr[j] :
arr[j+1] = arr[j]
j -= 1
arr[j+1] = key
arr = [12, 11, 13, 5, 6]
insertionSort(arr)
print ("排序后的数组:")
for i in range(len(arr)):
print ("%d" %arr[i])

def partition(arr,low,high):
i = ( low-1 ) # 最小元素索引
pivot = arr[high]
for j in range(low , high): # 当前元素小于或等于 pivot
if arr[j] <= pivot: i = i+1
arr[i],arr[j] = arr[j],arr[i] arr[i+1],arr[high] = arr[high],arr[i+1]
return ( i+1 ) # arr[] --> 排序数组
# low --> 起始索引
# high --> 结束索引 # 快速排序函数
def quickSort(arr,low,high):
if low < high: pi = partition(arr,low,high) quickSort(arr, low, pi-1)
quickSort(arr, pi+1, high) arr = [10, 7, 8, 9, 1, 5]
n = len(arr)
quickSort(arr,0,n-1)
print ("排序后的数组:")
for i in range(n):
print ("%d" %arr[i]),

import sys
A = [64, 25, 12, 22, 11] for i in range(len(A)): min_idx = i
for j in range(i+1, len(A)):
if A[min_idx] > A[j]:
min_idx = j A[i], A[min_idx] = A[min_idx], A[i] print ("排序后的数组:")
for i in range(len(A)):
print("%d" %A[i]),

def bubbleSort(arr):
n = len(arr) # 遍历所有数组元素
for i in range(n): # Last i elements are already in place
for j in range(0, n-i-1): if arr[j] > arr[j+1] :
arr[j], arr[j+1] = arr[j+1], arr[j] arr = [64, 34, 25, 12, 22, 11, 90] bubbleSort(arr) print ("排序后的数组:")
for i in range(len(arr)):
print ("%d" %arr[i]),

def merge(arr, l, m, r):
n1 = m - l + 1
n2 = r- m # 创建临时数组
L = [0] * (n1)
R = [0] * (n2) # 拷贝数据到临时数组 arrays L[] 和 R[]
for i in range(0 , n1):
L[i] = arr[l + i] for j in range(0 , n2):
R[j] = arr[m + 1 + j] # 归并临时数组到 arr[l..r]
i = 0 # 初始化第一个子数组的索引
j = 0 # 初始化第二个子数组的索引
k = l # 初始归并子数组的索引 while i < n1 and j < n2 :
if L[i] <= R[j]:
arr[k] = L[i]
i += 1
else:
arr[k] = R[j]
j += 1
k += 1 # 拷贝 L[] 的保留元素
while i < n1:
arr[k] = L[i]
i += 1
k += 1 # 拷贝 R[] 的保留元素
while j < n2:
arr[k] = R[j]
j += 1
k += 1 def mergeSort(arr,l,r):
if l < r:
m = int((l+(r-1))/2)
mergeSort(arr, l, m)
mergeSort(arr, m+1, r)
merge(arr, l, m, r) arr = [12, 11, 13, 5, 6, 7]
n = len(arr)
print ("给定的数组")
for i in range(n):
print ("%d" %arr[i]), mergeSort(arr,0,n-1)
print ("\n\n排序后的数组")
for i in range(n):
print ("%d" %arr[i]),

def heapify(arr, n, i):
largest = i
l = 2 * i + 1 # left = 2*i + 1
r = 2 * i + 2 # right = 2*i + 2 if l < n and arr[i] < arr[l]:
largest = l if r < n and arr[largest] < arr[r]:
largest = r if largest != i:
arr[i],arr[largest] = arr[largest],arr[i] # 交换 heapify(arr, n, largest) def heapSort(arr):
n = len(arr) # Build a maxheap.
for i in range(n, -1, -1):
heapify(arr, n, i) # 一个个交换元素
for i in range(n-1, 0, -1):
arr[i], arr[0] = arr[0], arr[i] # 交换
heapify(arr, i, 0) arr = [ 12, 11, 13, 5, 6, 7]
heapSort(arr)
n = len(arr)
print ("排序后")
for i in range(n):
print ("%d" %arr[i]),
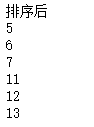
def countSort(arr):
output = [0 for i in range(256)]
count = [0 for i in range(256)]
ans = ["" for _ in arr]
for i in arr:
count[ord(i)] += 1
for i in range(256):
count[i] += count[i-1]
for i in range(len(arr)):
output[count[ord(arr[i])]-1] = arr[i]
count[ord(arr[i])] -= 1
for i in range(len(arr)):
ans[i] = output[i]
return ans arr = "wwwrunoobcom"
ans = countSort(arr)
print ( "字符数组排序 %s" %("".join(ans)) )
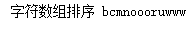
def shellSort(arr):
n = len(arr)
gap = int(n/2)
while gap > 0:
for i in range(gap,n):
temp = arr[i]
j = i
while j >= gap and arr[j-gap] >temp:
arr[j] = arr[j-gap]
j -= gap
arr[j] = temp
gap = int(gap/2) arr = [ 12, 34, 54, 2, 3] n = len(arr)
print ("排序前:")
for i in range(n):
print(arr[i]), shellSort(arr) print ("\n排序后:")
for i in range(n):
print(arr[i]),

from collections import defaultdict class Graph:
def __init__(self,vertices):
self.graph = defaultdict(list)
self.V = vertices def addEdge(self,u,v):
self.graph[u].append(v) def topologicalSortUtil(self,v,visited,stack): visited[v] = True for i in self.graph[v]:
if visited[i] == False:
self.topologicalSortUtil(i,visited,stack) stack.insert(0,v) def topologicalSort(self):
visited = [False]*self.V
stack =[] for i in range(self.V):
if visited[i] == False:
self.topologicalSortUtil(i,visited,stack) print (stack) g= Graph(6)
g.addEdge(5, 2);
g.addEdge(5, 0);
g.addEdge(4, 0);
g.addEdge(4, 1);
g.addEdge(2, 3);
g.addEdge(3, 1); print ("拓扑排序结果:")
g.topologicalSort()

吴裕雄--天生自然python编程:实例(3)的更多相关文章
- 吴裕雄--天生自然python编程:实例
# 该实例输出 Hello World! print('Hello World!') # 用户输入数字 num1 = input('输入第一个数字:') num2 = input('输入第二个数字:' ...
- 吴裕雄--天生自然python编程:实例(1)
str = "www.runoob.com" print(str.upper()) # 把所有字符中的小写字母转换成大写字母 print(str.lower()) # 把所有字符中 ...
- 吴裕雄--天生自然python编程:实例(2)
list1 = [10, 20, 4, 45, 99] list1.sort() print("最小元素为:", *list1[:1]) list1 = [10, 20, 1, 4 ...
- 吴裕雄--天生自然python编程:正则表达式
re.match函数 re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none. 函数语法: re.match(pattern, string, ...
- 吴裕雄--天生自然python编程:turtle模块绘图(3)
turtle(海龟)是Python重要的标准库之一,它能够进行基本的图形绘制.turtle图形绘制的概念诞生于1969年,成功应用于LOGO编程语言. turtle库绘制图形有一个基本框架:一个小海龟 ...
- 吴裕雄--天生自然python编程:turtle模块绘图(1)
Turtle库是Python语言中一个很流行的绘制图像的函数库,想象一个小乌龟,在一个横轴为x.纵轴为y的坐标系原点,(0,0)位置开始,它根据一组函数指令的控制,在这个平面坐标系中移动,从而在它爬行 ...
- 吴裕雄--天生自然python编程:pycharm常用快捷键问题
最近在使用pycharm的时候发现不能正常使用ctrl+c/v进行复制粘贴,也无法使用tab键对大段代码进行整体缩进.后来发现是因为安装了vim插件的问题,在setting里找到vim插件,取消勾选即 ...
- 吴裕雄--天生自然python编程:turtle模块绘图(4)
import turtle bob = turtle.Turtle() for i in range(1,5): bob.fd(100) bob.lt(90) turtle.mainloop() im ...
- 吴裕雄--天生自然python编程:turtle模块绘图(2)
#彩色螺旋线 import turtle import time turtle.pensize(2) turtle.bgcolor("black") colors = [" ...
随机推荐
- miniconda安装jupyter
1.安装jupyter 由于miniconda是anaconda的简化版,只有一个prompt: 安装jupyter,只需要打开prompt的dos窗口,输入命令pip install jupyter ...
- Maven--可选依赖
假设有这样换一个依赖关系,项目 A 依赖于项目 B,项目 B 依赖于项目 X 和 Y,B 对于 X 和 Y的依赖都是可选依赖: A -> B B -> X(可选) B -> Y(可选 ...
- P2P平台疯狂爆雷后,你的生活受到影响了吗?
最近这段时间P2P爆雷的新闻和报道一直占据着各大财经和科技媒体的重要位置.而据网贷之家数据显示,截至2018年7月底,P2P网贷行业累计平台数量达到6385家(含停业及问题平台),其中问题平台累计为2 ...
- Junit单元测试、反射、注解
Junit单元测试: * 测试分类: 1. 黑盒测试:不需要写代码,给输入值,看程序是否能够输出期望的值. 2. 白盒测试:需要写代码的.关注程序具体的执行流程. * Junit使用:白盒测试 * 步 ...
- Django知识点_梳理
- 查看opencv-python编译信息
python -c "import cv2; print(cv2.getBuildInformation())" General configuration for OpenCV ...
- 0x10 - PostgreSQL 安装之 CentOS7 + Patroni
PostgreSQL + CentOS7 + Patroni 背景 PostgreSQL 的高可用环境 环境 CentOS 7 pg01 (192.168.1.120) pg02 (192.168.1 ...
- List集合分组依据集合中对象的属性
直接上代码 用到了Spring的BeanWrapper类 public static <T, K> Map<K, List<T>> groupByProperty( ...
- Java操作redis客户端Jedis连接集群(Cluster)
创建JedisCluster类连接redis集群. @Test public void testJedisCluster() throws Exception { //创建一连接,JedisClust ...
- LIS 问题 二分查找优化
按n=5,a-{4,2,3,1,5}为例 dp的值依次是: INF INF INF INF INF 4 INF INF INF INF 2 INF INF INF INF 2 ...