SQL SERVER 中is null 和 is not null 将会导致索引失效吗?
其实本来这个问题没有什么好说的,今天优化的时候遇到一个SQL语句,因为比较有意思,所以我截取、简化了SQL语句,演示给大家看,如下所示
declare @bamboo_Code varchar(3);
set @bamboo_Code='-01';
SELECT DISTINCT yarn_lot
FROM dbo.rsjob WITH ( nolock )
WHERE RIGHT(ges_no, 3) = @bamboo_Code
AND Isnull(yarn_lot, '') <> '';
如上所示,SQL中对列yarn_log 使用了Isnull(yarn_lot, '') <> ''这种写法,我估计书写该SQL语句的人应该是深信了“is null 和 is not null 将会导致索引失效”这条网上流传的教条, 至于这个建议是从哪里流传开来,已经无法考证。 那么我们通过实践来验证一下is null 或 is not null 是否会导致索引失效。
表rsjob是一个堆表,在列yarn_lot上建有索引yarn_lot.那么我们通过实验来验证吧
SELECT DISTINCT yarn_lot
FROM dbo.rsjob WITH(nolock)
WHERE yarn_lot IS NOT NULL;
SELECT DISTINCT yarn_lot
FROM dbo.rsjob WITH(nolock)
WHERE yarn_lot IS NULL
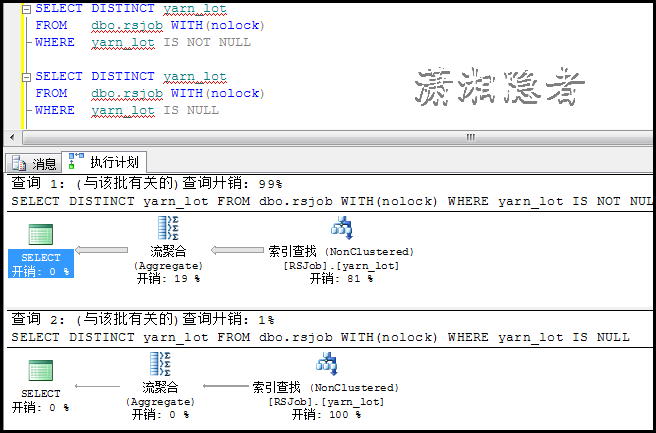
如上所示,不管是IS NULL 或IS NOT NULL都走了索引查找。
declare @bamboo_Code varchar(3);
set @bamboo_Code='-01';
SELECT DISTINCT yarn_lot
FROM dbo.rsjob WITH ( nolock )
WHERE RIGHT(ges_no, 3) = @bamboo_Code
AND Isnull(yarn_lot, '') <> '';
SELECT DISTINCT yarn_lot
FROM dbo.rsjob WITH ( nolock )
WHERE RIGHT(ges_no, 3) = @bamboo_Code
AND yarn_lot IS NOT NULL;
另外我们来看看这两个原始SQL执行计划的开销比值为52:48, 也就是说使用IS NOT NULL性能更好,第一个SQL语句由于做了转换,导致其走索引扫描,而使用IS NOT NULL则走索引查找。
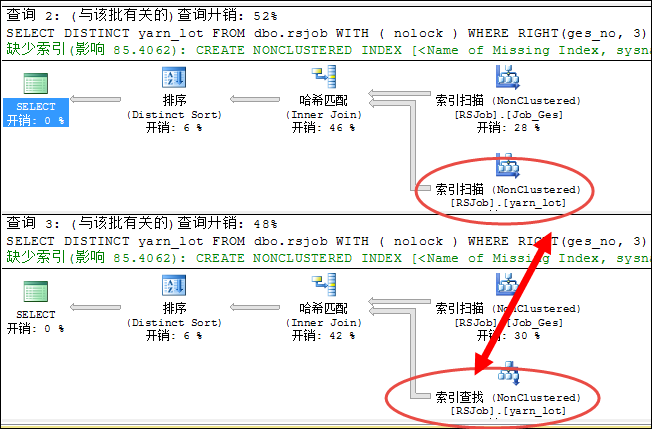
“is null 和 is not null 将会导致索引失效”这种坑人教条直接被推翻了。所以还在信奉这个教条的人真应该自己动手验证一下。
下面我们可以通过实验验证一下,考虑到在真实环境中,可能情况比较复杂。我们可以构建下面几个场景。其实真实环境中情况还会复杂一些。但是基本上大致有如下一些场景
情况1:堆表 谓词上单独索引列
USE Test;
GO
DROP TABLE TEST;
GO
CREATE TABLE TEST (OBJECT_ID INT, NAME VARCHAR(12));
CREATE INDEX PK_TEST ON TEST(OBJECT_ID) INCLUDE(NAME);
DECLARE @Index INT =0;
WHILE @Index < 10000
BEGIN
INSERT INTO TEST
SELECT @Index, 'kerry'+ CAST(@Index AS VARCHAR);
SET @Index = @Index +1;
END
INSERT INTO TEST
SELECT NULL, 'only test1' UNION ALL
SELECT NULL, 'only test2'
UPDATE STATISTICS TEST WITH FULLSCAN;
SELECT * FROM TEST WHERE OBJECT_ID IS NULL;
SELECT * FROM TEST WHERE OBJECT_ID IS NOT NULL;
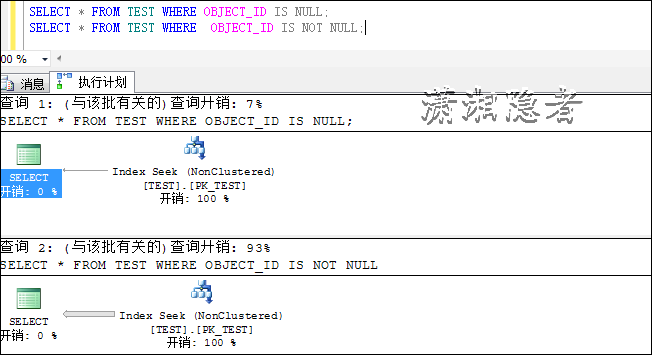
删除索引,建立如下索引。如下所示
DROP INDEX PK_TEST ON TEST;
CREATE INDEX PK_TEST ON TEST(OBJECT_ID)
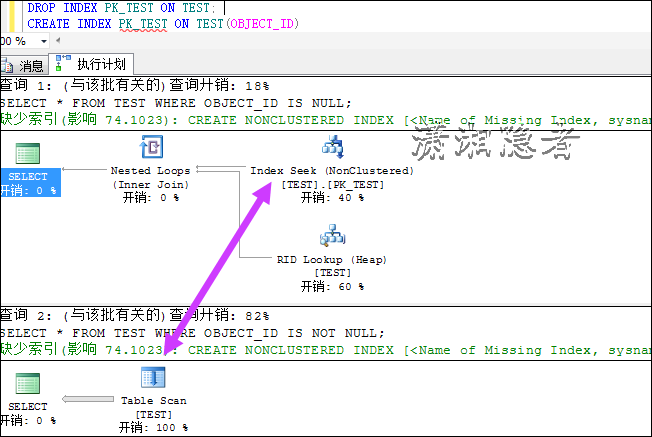
由此可见IS NULL 或IS NOT NULL的执行计划即与索引有关系,还跟数据分布有一定关系。
情况2:堆表 谓词上无索引
USE Test;
GO
DROP TABLE TEST;
GO
CREATE TABLE TEST (OBJECT_ID INT, NAME VARCHAR(12));
DECLARE @Index INT =0;
WHILE @Index < 10000
BEGIN
INSERT INTO TEST
SELECT @Index, 'kerry'+ CAST(@Index AS VARCHAR);
SET @Index = @Index +1;
END
INSERT INTO TEST
SELECT NULL, 'only test1' UNION ALL
SELECT NULL, 'only test2'
UPDATE STATISTICS TEST WITH FULLSCAN;
SELECT * FROM TEST WHERE OBJECT_ID IS NULL;
SELECT * FROM TEST WHERE OBJECT_ID IS NOT NULL;
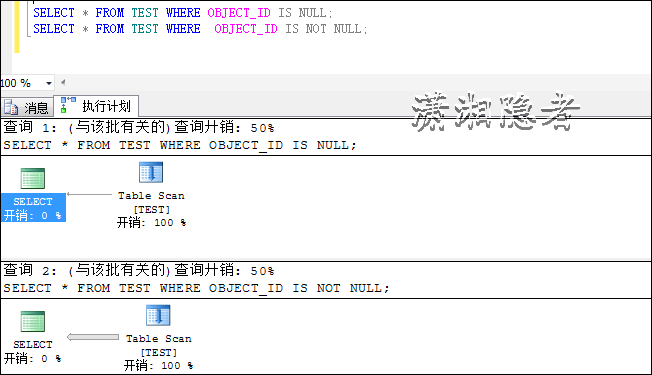
如上所示,如果一个堆表没有建立任何索引,那么使用IS NULL 或IS NOT NULL肯定要走全表扫描,不过这不在我们的讨论范围之内。然后我们看看将索引建立在其它字段上(主要是为了与聚集索引表对比),它依然全表扫描。
CREATE INDEX PK_TEST ON TEST(OBJECT_ID) INCLUDE(NAME);
INSERT INTO TEST
SELECT 10000, NULL UNION ALL
SELECT 10001, NULL ;
SELECT * FROM TEST WHERE NAME IS NULL;
SELECT * FROM TEST WHERE NAME IS NOT NULL;
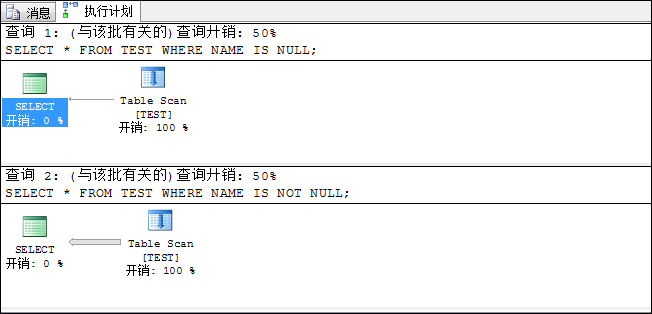
情况3:堆表 联合索引列
USE Test;
GO
DROP TABLE TEST;
GO
CREATE TABLE TEST (OBJECT_ID INT, NAME VARCHAR(12), AGE INT);
CREATE INDEX IDX_TEST_N1 ON TEST(NAME, AGE);
DECLARE @Index INT =0;
WHILE @Index < 10000
BEGIN
INSERT INTO TEST
SELECT @Index, 'kerry'+ CAST(@Index AS VARCHAR), floor(rand()*100) ;
SET @Index = @Index +1;
END
INSERT INTO TEST
SELECT NULL, 'only test1', 12 UNION ALL
SELECT NULL, 'only test2',24
UPDATE STATISTICS TEST WITH FULLSCAN;
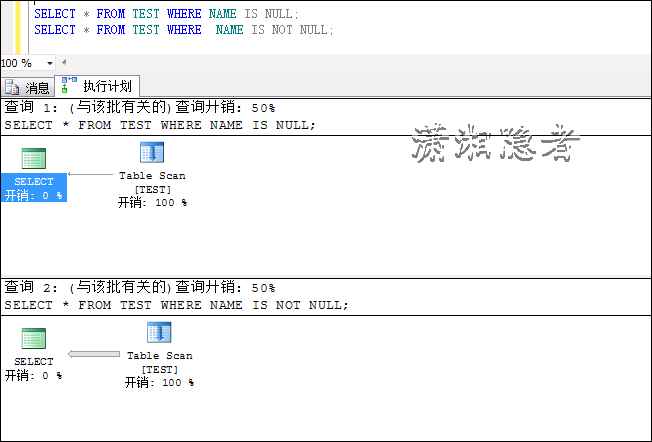
SELECT * FROM TEST WHERE NAME IS NULL;
SELECT * FROM TEST WHERE NAME IS NOT NULL;
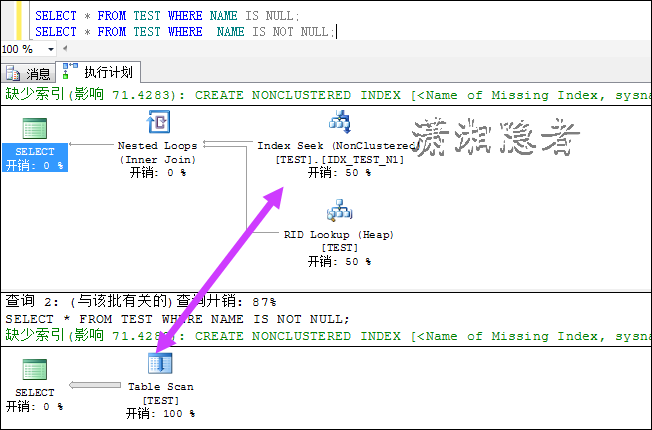
如果联合索引中,谓词位于联合索引的第二或更后位置,那么又是什么情况? 从下面我们可以看到,SQL走全表扫描了。
DROP INDEX IDX_TEST_N1 ON TEST;
CREATE INDEX IDX_TEST_N1 ON TEST( AGE,NAME);
UPDATE STATISTICS TEST WITH FULLSCAN;
4 聚集索引表 单独索引列
USE Test;
GO
DROP TABLE TEST;
GO
CREATE TABLE TEST (OBJECT_ID INT, NAME VARCHAR(12));
CREATE CLUSTERED INDEX PK_TEST ON TEST(OBJECT_ID)
DECLARE @Index INT =0;
WHILE @Index < 10000
BEGIN
INSERT INTO TEST
SELECT @Index, 'kerry'+ CAST(@Index AS VARCHAR);
SET @Index = @Index +1;
END
INSERT INTO TEST
SELECT NULL, 'only test1' UNION ALL
SELECT NULL, 'only test2'
SELECT * FROM TEST WHERE OBJECT_ID IS NULL;
SELECT * FROM TEST WHERE OBJECT_ID IS NOT NULL;

如果我在列NAME上面使用IS NULL 或IS NOT NULL进行查询,你会发现执行计划从聚集索引查找变为了聚集索引扫描。
INSERT INTO TEST
SELECT 10000, NULL UNION ALL
SELECT 10001, NULL ;
SELECT * FROM TEST WHERE NAME IS NULL;
SELECT * FROM TEST WHERE NAME IS NOT NULL;

4 聚集索引表 联合索引列
USE Test;
GO
DROP TABLE TEST;
GO
CREATE TABLE TEST (OBJECT_ID INT, NAME VARCHAR(12), AGE INT);
CREATE CLUSTERED INDEX PK_TEST ON TEST(OBJECT_ID)
DECLARE @Index INT =0;
WHILE @Index < 10000
BEGIN
INSERT INTO TEST
SELECT @Index, 'kerry'+ CAST(@Index AS VARCHAR), floor(rand()*100) ;
SET @Index = @Index +1;
END
INSERT INTO TEST
SELECT 10001, 'NULL', 12 UNION ALL
SELECT 10002, 'NULL',24
CREATE INDEX IDX_TEST_N2 ON TEST(NAME,AGE);
UPDATE STATISTICS TEST WITH FULLSCAN;
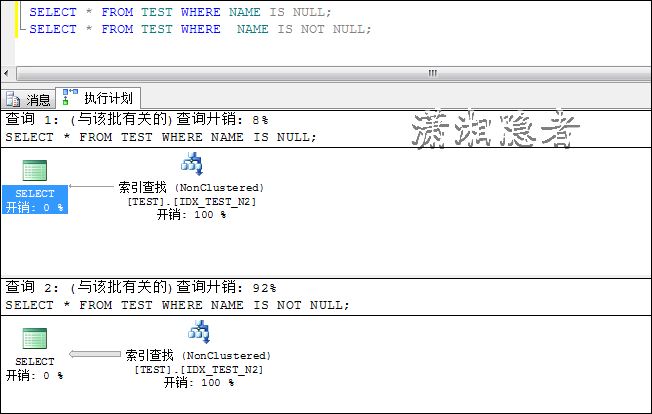
如果联合索引中,谓词位于不位于第一列,那么IS NULL 或IS NOT NULL有会不会走索引呢?
DROP INDEX IDX_TEST_N2 ON TEST;
CREATE INDEX IDX_TEST_N2 ON TEST(AGE,NAME);
UPDATE STATISTICS TEST WITH FULLSCAN;

如上所示,它从索引查找变成索引扫描了。
小结: 1:“is null 和 is not null 将会导致索引失效”这种教条完全是狗屎,SQL Server的索引是包含了null 值,而Oracle的索引是不包含null值的。不同数据库情况有所不同,不要生搬硬套。
2:如果谓词上面建立有索引的话,基本上都会走索引,至于是走索引查找还是索引扫描与索引类型有一定关系,也与字段位于联合索引中位置有关系。另外,数据分布倾斜得非常厉害也会导致其走全表扫描而不走索引,但是这并不是说IS NULL 和 IS NOT NULL导致索引失效。有一点非常重要,通过观察SQL语句而推断执行计划是很不现实的,需要综合考察SQL语句所涉及表的索引、数据分布、统计信息,才能综合判断,用通俗的话来说要结合具体场景。
SQL SERVER 中is null 和 is not null 将会导致索引失效吗?的更多相关文章
- SQL Server中可能为null的变量逻辑运算的时候要小心
DECLARE @a int declare @b int IF(@a<>@b) print('@a<>@b') else print('@a=@b') ) print('b& ...
- sql server中NULL导入decimal字段时报错
sql server中NULL导入decimal字段时报错 在导入CSV文件时,如果decimal字段为null值,导致文本文件入库时失败. 错误现象 构造例子 新建一张表,包含decimal字段. ...
- SQL Server中NULL的一个测试
我们都知道SQL Server中NULL是一个很特殊的存在,因为NULL不会等于任何值,且NULL也不会不等于任何值.对于NULL我们只能使用IS或IS NOT关键字来进行比较. 我们先来看看下面一个 ...
- SQL Server中的高可用性(2)----文件与文件组
在谈到SQL Server的高可用性之前,我们首先要谈一谈单实例的高可用性.在单实例的高可用性中,不可忽略的就是文件和文件组的高可用性.SQL Server允许在某些文件损坏或离线的情况下,允 ...
- 在SQL Server中为什么不建议使用Not In子查询
在SQL Server中,子查询可以分为相关子查询和无关子查询,对于无关子查询来说,Not In子句比较常见,但Not In潜在会带来下面两种问题: 结果不准确 查询性能低下 下面 ...
- sql server中对xml进行操作
一.前言 SQL Server 2005 引入了一种称为 XML 的本机数据类型.用户可以创建这样的表,它在关系列之外还有一个或多个 XML 类型的列:此外,还允许带有变量和参数.为了更好地支持 XM ...
- SQL Server中查询数据库及表的信息语句
/* -- 本文件主要是汇总了 Microsoft SQL Server 中有关数据库与表的相关信息查询语句. -- 下面的查询语句中一般给出两种查询方法, -- A方法访问系统表,适应于SQL 20 ...
- 再谈SQL Server中日志的的作用
简介 之前我已经写了一个关于SQL Server日志的简单系列文章.本篇文章会进一步挖掘日志背后的一些概念,原理以及作用.如果您没有看过我之前的文章,请参阅: 浅谈SQL Server ...
- SQL Server 中的事务与事务隔离级别以及如何理解脏读, 未提交读,不可重复读和幻读产生的过程和原因
原本打算写有关 SSIS Package 中的事务控制过程的,但是发现很多基本的概念还是需要有 SQL Server 事务和事务的隔离级别做基础铺垫.所以花了点时间,把 SQL Server 数据库中 ...
随机推荐
- 用jekyll制作高大上的网站(二)——实际应用
最近公司要制作个文档库,直接就可以将jekyll应用到实际中. 模版使用了Jekyll Clean,这么模版相对内部简单一点,学习成本不会很大,而复杂的Minimal Mistakes就当作参考. 模 ...
- Java基础--反射机制的知识点梳理
什么是反射? 正常编译执行java文件时,会生成一个.class文件,反射就是一个反编译的过程,它可以通过.class文件得到一个java对象.一个类会有很多组成部分,比如成员变量,成员方法,构造方法 ...
- 汽车之家一道SQL 面试题,大家闲来无事都来敲一敲
写在前面 上周去汽车之家面试,拿到这个SQL笔试题顿时感觉到有些陌生,因为好长时间不写SQL语句了,当时只写了表设计,示例数据和SQL语句都没写出来. 汽车之家应该用的SQL Server, 编程题一 ...
- 基于Angularjs实现分页
前言 学习任何一门语言前肯定是有业务需求来驱动你去学习它,当然ng也不例外,在学习ng前我第一个想做的demo就是基于ng实现分页,除去基本的计算思路外就是使用指令封装成一个插件,在需要分页的列表页面 ...
- 数据结构(C语言第2版)-----数组,广义表,树,图
任何一个算法的设计取决于选定的数据结构,而算法的实现依赖于采用的存储结构. 之前线性表的数据元素都是非结构的原子类型,元素的值是不可再分的.下面学习的这两个线性表是很特殊的,其中数据元素本身也可能是一 ...
- SSL介绍与Java实例
有关SSL的原理和介绍在网上已经有不少,对于Java下使用keytool生成证书,配置SSL通信的教程也非常多.但如果我们不能够亲自动手做一个SSL Sever和SSL Client,可能就永远也不能 ...
- 重温Bootstrap
预热 ★ 学习要点 1. 理解其GridSystem(栅格排版): 2. 熟悉其所提供的各种CSS样式及显示效果: 3. 知道提供了哪些直接可用的UI组件,以及如何使用JavaScript去调整其交互 ...
- ROWNUMBER() OVER( PARTITION BY COL1 ORDER BY COL2)用法,先分组,然后在组内排名,分组计算,主表与附表一对多取唯一等
ROWNUMBER() OVER( PARTITION BY COL1 ORDER BY COL2)用法 今天在使用多字段去重时,由于某些字段有多种可能性,只需根据部分字段进行去重,在网上看到了row ...
- Android源码编译make的错误处理
android源码下载:官方下载 或参考android源码下载方式 Android编译版本: PLATFORM_VERSION=4.0.1(最新Android 4.0.1) OS 操作系统平台: Li ...
- Java集合概述
容器,是用来装东西的,在Java里,东西就是对象,而装对象并不是把真正的对象放进去,而是指保存对象的引用.要注意对象的引用和对象的关系,下面的例子说明了对象和对象引用的关系. String str = ...