图解MySQL索引(三)—如何正确使用索引?
MySQL使用了B+Tree作为底层数据结构,能够实现快速高效的数据查询功能。工作中可怕的是没有建立索引,比这更可怕的是建好了索引又没有使用到。
本文将围绕着如何优雅的使用索引,图文并茂地和大家一起探讨索引的正确打开姿势,不谈底层原理,只求工作实战。
1. 索引的特点
page之间是双链表形式,而每个page内部的数据则是单链表形式存在。当进行数据查询时,会限定位到具体的page,然后在page中通过二分查找具体的记录。
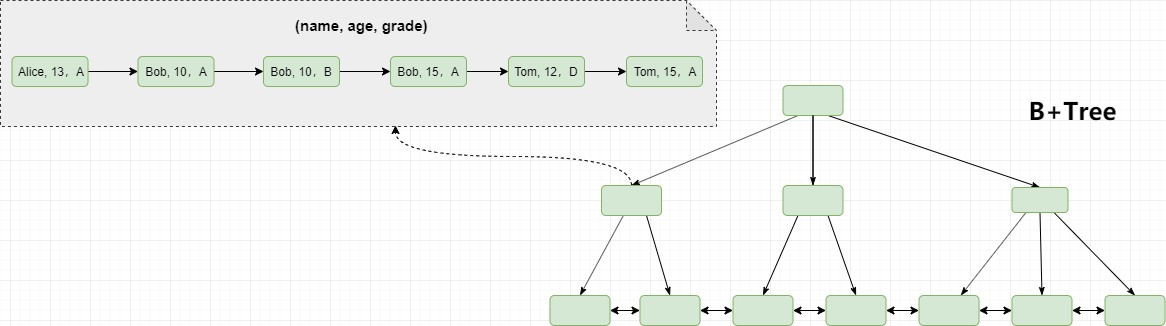
并且索引的顺序不同,数据的存储顺序则也不同。所以在开发过程中,一定要注意索引字段的先后顺序。
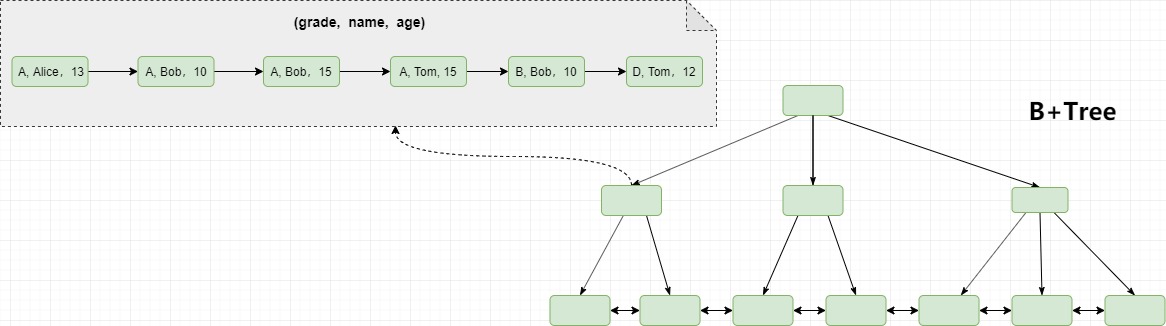
最左匹配原则
当一个索引中包含多个字段时,可以称之为组合索引。MySQL中有个很重要的规则,即最左匹配原则用来定义组合索引的命中规则,它是指在检索数据时从联合索引的最左边开始匹配。假设对用户表建立一个联合索引(a,b,c),那么条件a,(a,b),(a,b,c)都会用到索引。
在匹配过程中会优先根据最左前面的字段a进行匹配,然后再判断是否用到了索引字段b,直到无法找到对应的索引字段,或者对应的索引被”破坏“(下文中会介绍)。
以下是本文中操作实践用到的初始化语句,有条件的同学可以再本地执行,建议使用MySQL5.6+版本,毕竟实操才是学习的最佳途径。
SET NAMES utf8mb4;
-- ----------------------------
-- Table structure for test_table
-- ----------------------------
DROP TABLE IF EXISTS `test_table`;
CREATE TABLE `test_table` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`a` varchar(255) COLLATE utf8mb4_bin NOT NULL,
`b` varchar(255) COLLATE utf8mb4_bin NOT NULL,
`c` varchar(255) COLLATE utf8mb4_bin NOT NULL,
`d` varchar(255) COLLATE utf8mb4_bin NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_a_b_c` (`a`,`b`,`c`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
-- ----------------------------
-- Records of test_table
-- ----------------------------
BEGIN;
INSERT INTO `test_table` VALUES
(1, 'zhangsan', '12222222222', '23', 'aafasd'),
(2, 'lisi', '13333333333', '21', 'cxvcxv'),
(3, 'wanger', '14444444444', '24', 'dfdf'),
(4, 'liqiang', '18888888888', '18', 'ccsdf');
COMMIT;
2. 正确创建索引
尽量使用自增长主键
使用自增长主键的原因笔者认为有两个。首先能有效减少页分裂,MySQL中数据是以页为单位存储的且每个页的大小是固定的(默认16kb),如果一个数据页的数据满了,则需要分成两个页来存储,这个过程就叫做页分裂。
如果使用了自增主键的话,新插入的数据都会尽量的往一个数据页中写,写满了之后再申请一个新的数据页写即可(大多数情况下不需要分裂,除非父节点的容量也满了)。
自增主键
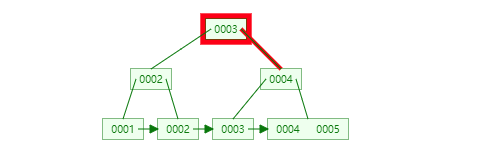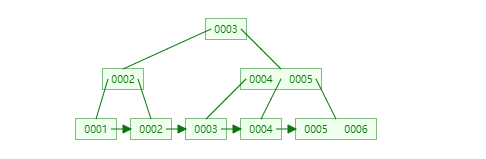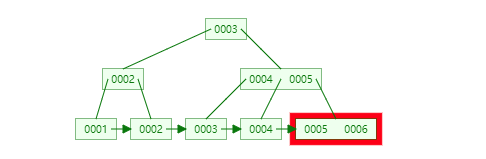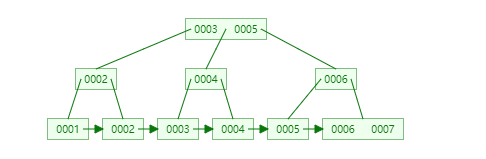
非自增主键

其次,对于缓存友好。系统分配给MySQL的内存有限,对于数据量比较多的数据库来说,通常只有一小部分数据在内存中,而大多数数据都在磁盘中。如果使用无序的主键,则会造成随机的磁盘IO,影响系统性能。
选择性高的列优先
关注索引的选择性。索引的选择性,也可称为数据的熵。在创建索引的时候通常要求将选择性高的列放在最前面,对于选择性不高的列甚至可以不创建索引。如果选择性不高,极端性情况下可能会扫描全部或者大多数索引,然后再回表,这个过程可能不如直接走主键索引性能高。
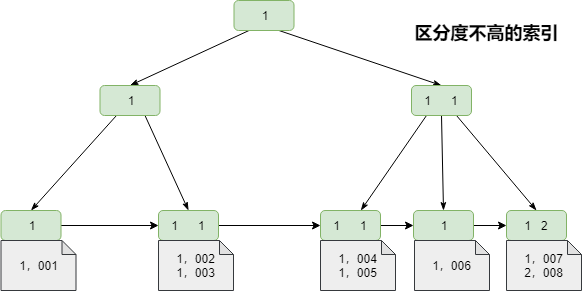
索引列的选择往往需要根据具体的业务场景来选择,但是需要注意的是索引的区分度越高则价值就越高,意味着对于检索的性价比就高。索引的区分度等于count(distinct 具体的列) / count(*),表示字段不重复的比例。
唯一键的区分度是1,而对于一些状态值,性别等字段区分度往往比较低,在数据量比较大的情况下,甚至有无限接近0。假设一张表中用data_status来表示数据的状态,1-有效,2-删除,则数据的区分度为 1/500000。如果100万条数据中只有1条被删除,并且在查询数据时查找data_status = 0 的数据时,需要进行全表扫描。由于索引也是需要占用内存的,所以在内存较为有限的环境下,区分度不高的索引几乎没有意义。
联合索引优先于多列独立索引
联合索引优先于多列独立索引, 假设有三个字段a,b,c, 索引(a)(a,b),(a,b,c)可以使用(a,b,c)代替。MySQL中的索引并不是越多越好,各个公司的规定中往往会限制单表中的索引的个数。原因在于,索引本身也会占用一定的空间,并且维护一个索引时有一定的代码的,所以在满足需求的情况下一定要尽可能创建更少的索引。
执行语句:
explain select * from test_table where a = "zhangsan";
explain select * from test_table where a = "zhangsan" and b = "188466668888";
explain select * from test_table where a = "zhangsan" and b = "188466668888" and c = "23";
执行结果分析:



实际上建立(a, b, c)联合索引时,其作用相当于(a), (a, b), (a, b, c) 三个索引。所以以上三种查询方式均会命中索引。
覆盖索引避免回表
覆盖索引如果执行的语句是 select ID from T where k between 3 and 5,这时只需要查 ID 的值,而 ID 的值已经在 k 索引树上了,因此可以直接提供查询结果,不需要回表。也就是说,在这个查询里面,索引 k 已经“覆盖了”我们的查询需求,我们称为覆盖索引。由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
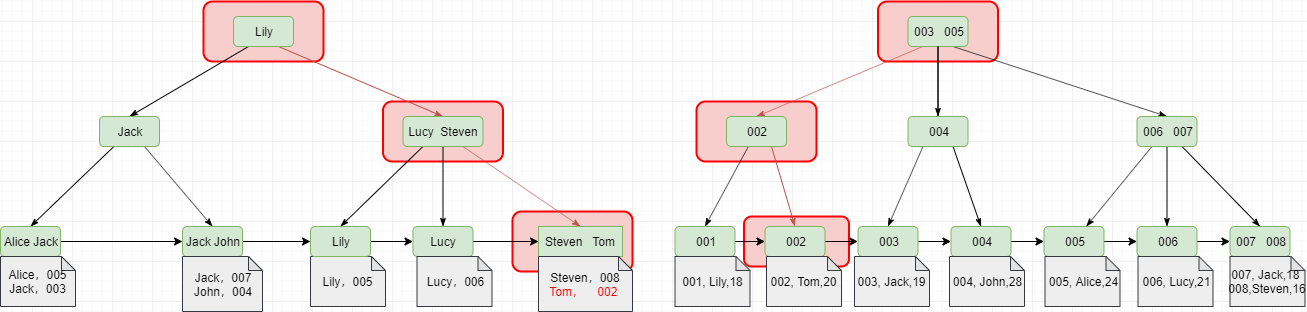
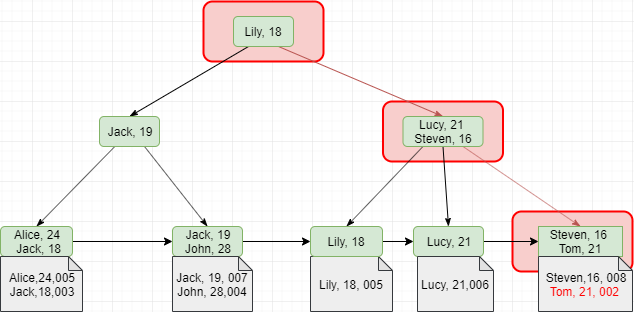
覆盖索引的查询优化
覆盖索引同时还会影响索引的选择,对于(a,b,c)索引来说,理论上来说不满足最左匹配原则,但是实际上也会走索引。原因在于,优化器认为(a,b,c)索引的性能会高于全表扫描,实际情况也是这样的,感兴趣的小伙伴不妨分析一下上文中介绍的数据结构。
explain select a,b,c from test_table where b = "188466668888" and c = "23";
执行结果:

满足查询和排序
索引要满足查询和排序。大部分同学在创建索引时,通常第一反应是查询条件来选择索引列,需要注意的是查询和排序同样重要,我们建立的索引要同时满足查询和排序的需求.
包含要排序的列
select c, d from test_table where a = 1 and b = 2 order by c;
虽然查询条件只使用了a,b两个字段,但是由于排序用到了c字段,我们能可以建立(a,b,c)联合索引来进行优化。
保证索引字段顺序
如上文中的介绍,索引的字段顺序决定了索引数据的组织顺序。要想更高性能的检索数据,一定要尽可能的借助底层数据结构的特点来进行。如,索引(a, b)的默认组织形式就是先根据a排序,在a相同的情况下再根据b排序。
考虑索引的大小
内存中的空间十分宝贵,而索引往往又需要在内存中。为了在有限的内存中存储更多的索引,在设计索引时往往要考虑索引的大小。比如我们常用的邮箱,xxxx@xx.com, 假设都是abc公司的,则邮箱后缀完全一致为@abc.com, 索引的区分度完全取决于@前面的字符串。
针对上述情况,MySQL 是支持前缀索引的,也就是说,你可以定义字符串的一部分作为索引。默认地,如果你创建索引的语句不指定前缀长度,那么索引就会包含整个字符串。
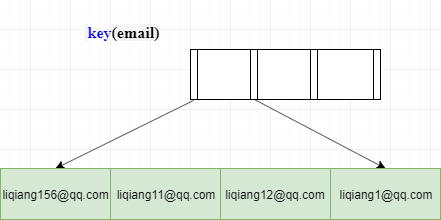
如果使用的 email 整个字符串的索引结构执行顺序是这样的:从 index1 索引树找到满足索引值是’liqiang156@11.com’的这条记录,取得 id (主键)的值ID2;到主键上查到主键值是ID2的行,将这行记录加入结果集;
取 email 索引树上刚刚查到的位置的下一条记录,发现已经不满足 email='liqiang156@qq.com’的条件了,循环结束。这个过程中,只需要回主键索引取一次数据,所以系统认为只扫描了一行。但是它的问题就是索引的后半部分都是重复的,浪费内存。
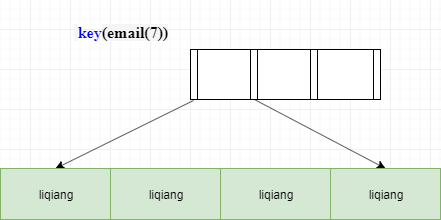
这时我们可以考虑使用前缀索引,如果使用的是 index2 (email(7) 索引结构),执行顺序是这样的:从 index2 索引树找到满足索引值是’liqiang’的记录,找到的第一个是 ID1,到主键上查到主键值是 ID1 的行,判断出 email 的值是’liqiang156@xxx.com’,加入结果集。
取 index2 上刚刚查到的位置的下一条记录,发现仍然是’liqiang’,取出 ID2,再到 ID 索引上取整行然后判断,这次值仍然不对,则丢弃继续往下取。
重复上一步,直到在 index2 上取到的值不是’liqiang’或者索引搜索完毕之后,循环结束。在这个过程中,要回主键索引取 4 次数据,也就是扫描了 4 行。通过这个对比,你很容易就可以发现,使用前缀索引后,可能会导致查询语句读数据的次数变多。
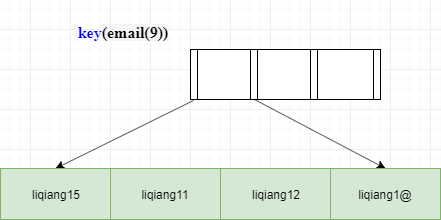
不过方法总比困难多,我们在建立索引时可以先通过语句查看一下索引的区分度,或者提前预估余下前缀长度,对于上述问题我们可以将前缀长度调整为9即可达到效果。索引,在使用前缀索引时,一定要充分考虑数据的特征,选择合适的
对于一些比较长的字段的等值查询,我们也可以采用其他方式来缩短索引的长度。比如url一般都是比较长,我们可以冗余一列存储其Hash值。
select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'
对于我们国家的身份证号,一共 18 位,其中前 6 位是地址码,所以同一个县的人的身份证号前 6 位一般会是相同的。为了提高区分度,我们可以将身份证号码倒序存储。
select field_list from t where id_card = reverse('input_id_card_string');
3. 正确使用索引
建立合适的索引是前提,想要取得理想的查询性能,还应保证能够用到索引。避免索引失效即是优化。
不在索引上进行任何操作
索引上进行计算,函数,类型转换等操作都会导致索引从当前位置(联合索引多个字段,不影响前面字段的匹配)失效,可能会进行全表扫描。
explain select * from test_table where upper(a) = "ZHANGSAN"

对于需要计算的字段,则一定要将计算方法放在“=”后面,否则会破坏索引的匹配,目前来说MySQL优化器不能对此进行优化。
explain select * from test_table where a = lower("ZHANGSAN")

隐式类型转换
需要注意的是,在查询时一定要注意字段类型问题,比如a字段时字符串类型的,而匹配参数用的是int类型,此时就会发生隐式类型转换,相当于相当于在索引上使用函数。
explain select * from test_table where a = 1;

a是字符串类型,然后使用int类型的1进行匹配,此时就发生了隐式类型转换,破坏索引的使用。
只查询需要的列
在日常开发中很多同学习惯使用 select * … 来构建查询语句,这种做法也是极不推荐的。主要原因有两个,首先查询无用的列在数据传输和解析绑定过程中会增加网络IO,以及CPU的开销,尽管往往这些消耗可以被忽略,但是我们也要避免埋坑。
explain select a,b,c from test_table where a="zhangsan" and b = "188466668888" and c = "23";

其次就是会使得覆盖索引"失效", 这里的失效并非真正的不走索引。覆盖索引的本质就是在索引中包含所要查询的字段,而 select * 将使覆盖索引失去意义,仍然需要进行回表操作,毕竟索引通常不会包含所有的字段,这一点很重要。
explain select * from test_table where a="zhangsan" and b = "188466668888" and c = "23";

不等式条件
查询语句中只要包含不等式,负向查询一般都不会走索引,如 !=, <>, not in, not like等。
explain select * from test_table where a !="1222" and b="12222222222" and c = 23;
explain select * from test_table where a <>"1222" and b="12222222222" and c = 23;

explain select * from test_table where a not in ("xxxx");

模糊匹配查询
最左前缀在进行模糊匹配时,一般禁止使用%前导的查询,如like “%zhangsan”。
explain select * from test_table where a like "zhangsan";
explain select * from test_table where a like "%zhangsan";
explain select * from test_table where a like "zhangsan%";



最左匹配原则
索引是有顺序的,查询条件中缺失索引列之后的其他条件都不会走索引。比如(a, b, c)索引,只使用b, c索引,就不会走索引。
explain select * from test_table where b = "188466668888" and c = "23";

如果索引从中间断开,索引会部分失效。这里的断开指的是缺失该字段的查询条件,或者说满足上述索引失效情况的任意一个。不过这里的仍然会使用到索引,只不过只能使用到索引的前半部分。
explain select * from test_table where a="zhangsan" and b != 1 and c = "23"

值得注意的是,如果使用了不等式查询条件,会导致索引完全失效。而上一个例子中即使用了不等式条件,也使用了隐式类型转换却能用到索引。

同理,根据最左前缀匹配原则,以下如果使用b,c作为查询条件则不会使用(a, b, c)索引。
执行语句:
explain select * from test_table where b = "188466668888" and c = "23";
执行结果:

索引下推
在说索引下推之前,我们先执行一下SQL。
执行语句:
explain select * from test_table where a = "zhangsan" and c = "23";

上述的最左前缀匹配原则相信大家都能很容易的理解,那么使用(a, c)条件查询能够利用(a, b, c)吗?答案是肯定的,正如上图所示。即使没有索引下推也会会根据最左匹配原则,使用到索引中的a字段。有了索引下推之后会增加查询的效率。
在面试中通常会问到这样一个问题,已知有索引(a,b,c)则根据条件(a,c)查询时会不会走索引呢?答案是肯定的,但是是有版本限制的。
而 MySQL 5.6 引入的索引下推优化(index condition pushdown), 可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数,是对查询的一种优化,感兴趣的同学可以看一下官方说明https://dev.mysql.com/doc/refman/8.0/en/index-condition-pushdown-optimization.html。

上述是没有索引下推,每次查询完之后都会回表,取到对应的字段进行匹配。
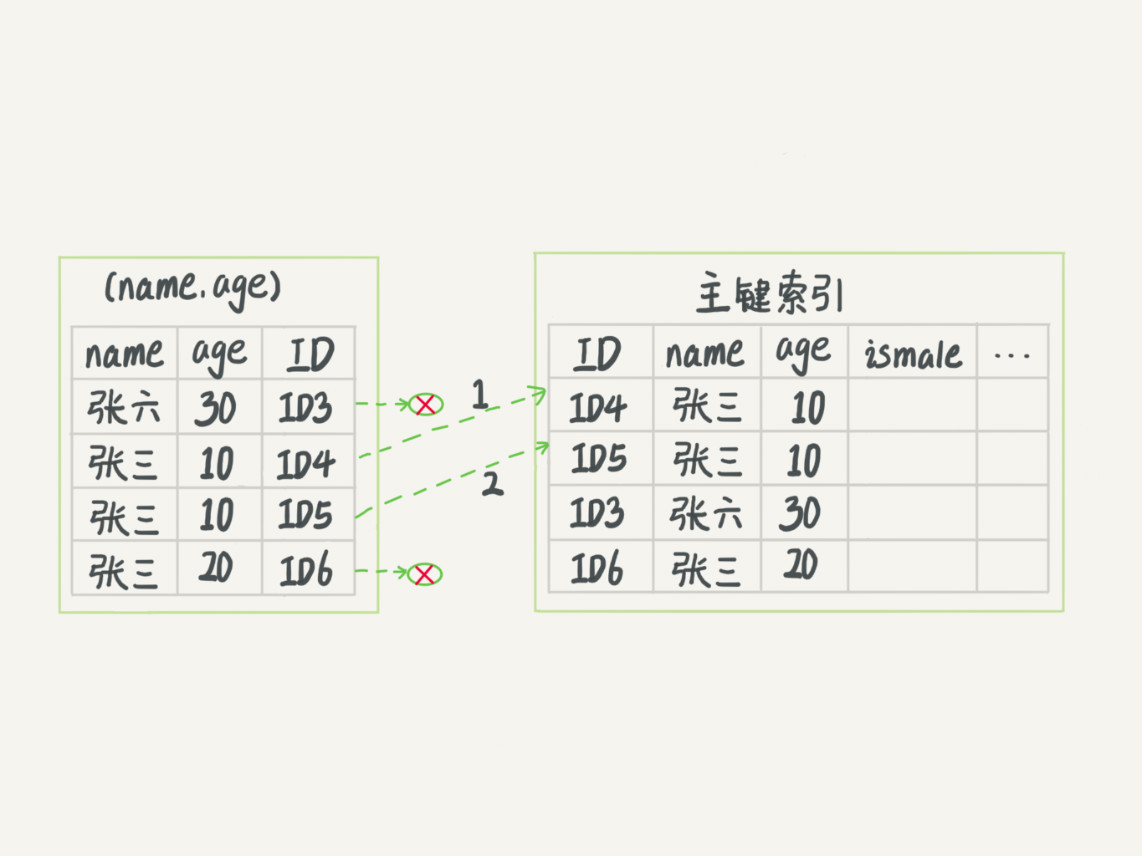
利用索引下推,每次尽可能在辅助索引中将不符合条件数据过滤掉。比如,索引中已经包含了name和age,索引不妨暂且忽略破坏索引匹配的条件直接匹配。
查询优化-自适应索引顺序
查询时,mysql的优化器会优化sql的执行,即使查询条件的顺序没有按照定义顺序来使用,也是可以使用索引的。但是需要注意的是优化本身也会消耗一定的性能,所以还是推荐按照索引的定义来书写sql。
explain select * from test_table where b="12222222222" and a="zhangsan" and c = 23;
explain select * from test_table where a="zhangsan" and b="12222222222" and c = 23;

4. 总结
索引并不是什么高深的技术,从底层来看,不过是一个数据结构罢了。要想使用好索引,一定要先将B+Tree理解透彻,在此基础上对于日常使用和面试则是信手拈来。
脱离业务的设计都是耍流氓,技术的意义在于服务业务。所以,索引的设计需要充分考虑业务的需求与设计原则之间做一些取舍,满足需求是基础。
在工作中,各个公司的版本可能大不相同,会存在一些奇奇怪怪,不确定的问题。所以为了验证索引的有效性,强烈推荐把主要的查询sql都通过explain查看一下执行计划,是否会用到索引。
参考资料:
[1] 《MySQL 45讲》—极客时间
[2] 《InnoDB存储引擎》
[3] 《高性能MySQL》
[4] https://dev.mysql.com/doc/refman/8.0/en/
图解MySQL索引(三)—如何正确使用索引?的更多相关文章
- 图解MySQL索引(二)—为什么使用B+Tree
失踪人口回归,近期换工作一波三折,耽误了不少时间,从今开始每周更新~ 索引是一种支持快速查询的数据结构,同时索引优化也是后端工程师的必会知识点.各个公司都有所谓的MySQL"军规" ...
- 单表扫描,MySQL索引选择不正确 并 详细解析OPTIMIZER_TRACE格式
单表扫描,MySQL索引选择不正确 并 详细解析OPTIMIZER_TRACE格式 一 表结构如下: 万行 CREATE TABLE t_audit_operate_log ( Fid b ...
- MySQL之索引以及正确使用索引
一.MySQL中常见索引类型 普通索引:仅加速查询 主键索引:加速查询.列值唯一.表中只有一个(不可有null) 唯一索引:加速查询.列值唯一(可以有null) 组合索引:多列值组成一个索引,专门用于 ...
- 图解MySQL索引(上)—MySQL有中“8种”索引?
关于MySQL索引相关的内容,一直是一个让人头疼的问题,尤其是对于初学者来说.笔者曾在很长一段时间内深陷其中,无法分清"覆盖索引,辅助索引,唯一索引,Hash索引,B-Tree索引--&qu ...
- Python全栈开发之MySQL(三)视图,存储过程触发器,函数,事务,索引
一:视图 1:什么是视图? 视图是指存储在数据库中的查询的SQL语句,具有简单.安全.逻辑数据独立性的作用及视点集中简化操作定制数据安全性的优点.视图包含一系列带有名称的列和行数据.但是,视图并不在数 ...
- MySQL (三)-- 字段属性、索引、关系、范式、逆规范化
1 字段属性 主键.唯一键和自增长. 1.1 主键 主键:primary key,一张表中只能有一个字段可以使用对应的键,用来唯一的约束该字段里面的数据,不能重复. 一张表只能有最多一个主键. 1.1 ...
- 图解MySQL索引--B-Tree(B+Tree)
看了很多关于索引的博客,讲的大同小异.但是始终没有让我明白关于索引的一些概念,如B-Tree索引,Hash索引,唯一索引....或许有很多人和我一样,没搞清楚概念就开始研究B-Tree,B+Tree等 ...
- 单表扫描,MySQL索引选择不正确 并 详细解析OPTIMIZER_TRACE格式
一 表结构如下: 万行 CREATE TABLE t_audit_operate_log ( Fid bigint(16) AUTO_INCREMENT, Fcreate_time int(10 ...
- MYSQL学习(三) --索引详解
创建高性能索引 (一)索引简介 索引的定义 索引,在数据结构的查找那部分知识中有专门的定义.就是把关键字和它对应的记录关联起来的过程.索引由若干个索引项组成.每个索引项至少包含两部分内容.关键字和关键 ...
随机推荐
- Java 8 中如何优雅的处理集合
Java 8 中如何优雅的处理集合(Stream API) 在Java中,集合和数组是我们经常会用到的数据结构,需要经常对他们做增.删.改.查.聚合.统计.过滤等操作.相比之下,关系型数据库中也同样有 ...
- Java——DOS命令窗口用命令编译文件夹下所有.java文件
1.进入指定目录 cd 进入用户主目录 cd ~ 进入用户主目录 cd - 返回进入此目录之前所在的目录 cd .. 返回上级目录 cd\ 直接退回到当前盘根目录2. ...
- JedisPool的使用-连接池
为什么要使用JedisPool 1,获取Jedis实例需要从JedisPool中获取 2,用完Jedis实例需要返还给JedisPool 3,如果Jedis在使用过程中出错,则也需要还给JedisPo ...
- 深入理解JS:执行上下文中的this(一)
目录 执行上下文与执行上下文栈 this 全局环境 函数环境 总结 参考 1.执行上下文与执行上下文栈 (1)什么是执行上下文? 在 JavaScript 代码运行时,解释执行全局代码.调用函数或使用 ...
- C# 数据操作系列 - 17 Dapper ——号称可以与ADO.NET 同台飙车的ORM
0. 前言 之前四篇介绍了一个国内开发者开发的优秀框架SqlSugar,给我们眼前一亮的感觉.这一篇,我们将试试另一个出镜率比较高的ORM框架-Dapper. Dapper是一个轻量级的ORM框架,其 ...
- Cypress系列(5)- 自定义 Cypress
如果想从头学起Cypress,可以看下面的系列文章哦 https://www.cnblogs.com/poloyy/category/1768839.html 前言 Cypress 不仅支持用户自定义 ...
- Java实现 LeetCode 824 山羊拉丁文(暴力)
824. 山羊拉丁文 给定一个由空格分割单词的句子 S.每个单词只包含大写或小写字母. 我们要将句子转换为 "Goat Latin"(一种类似于 猪拉丁文 - Pig Latin ...
- Java实现 LeetCode 700 二叉搜索树中的搜索(遍历树)
700. 二叉搜索树中的搜索 给定二叉搜索树(BST)的根节点和一个值. 你需要在BST中找到节点值等于给定值的节点. 返回以该节点为根的子树. 如果节点不存在,则返回 NULL. 例如, 给定二叉搜 ...
- Java实现 LeetCode 543 二叉树的直径
543. 二叉树的直径 给定一棵二叉树,你需要计算它的直径长度.一棵二叉树的直径长度是任意两个结点路径长度中的最大值.这条路径可能穿过根结点. 示例 : 给定二叉树 1 / \ 2 3 / \ 4 5 ...
- Java实现 LeetCode 241 为运算表达式设计优先级
241. 为运算表达式设计优先级 给定一个含有数字和运算符的字符串,为表达式添加括号,改变其运算优先级以求出不同的结果.你需要给出所有可能的组合的结果.有效的运算符号包含 +, - 以及 * . 示例 ...