第3节 storm高级应用:1、上次课程回顾,今日课程大纲,storm下载地址、运行过程等
上次课程内容回顾:
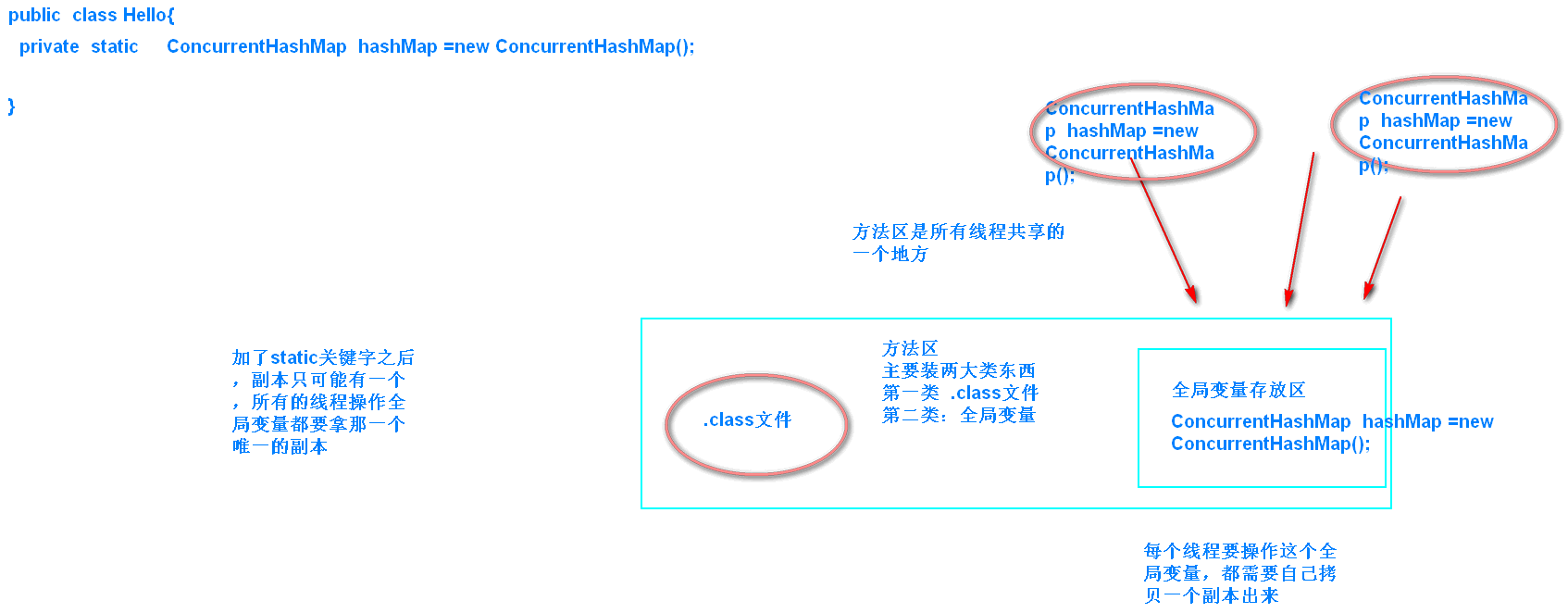
1、storm的基本介绍:strom是twitter公司开源提供给apache的一个实时处理的框架
2、storm的架构模型:主从架构:
nimbus:主节点 接收客户端提交的任务,以及任务的分发
supervisor:从节点,主要用于处理nimbus分配的任务
3、storm的安装 yaml的配置文件比较严格
4、strom的UI管理界面:记得更改ui的端口,默认8088已经被占用了
5、strom的编程模型:
spout:接收数据源
bolt:处理我们的数据的组件
6、storm的入门程序:wordCount
7、storm的并行度。调整进程和线程的数量
8、storm的分发策略
9、storm与kafka的集成 KafkaSpout去消费kafka当中的数据就行了
10、实时看板综合案例
==========================================
==========================================
Storm实时处理第二天
1、Storm源码下载及目录熟悉
1.1、在Storm官方网站上寻找源码地址
http://storm.apache.org/downloads.html

1.2 点击文字标签进入github
点击Apache/storm文字标签,进入github
https://github.com/apache/storm
1.3 拷贝storm源码地址
在网页右侧,拷贝storm源码地址

1.4 使用Subversion客户端下载

https://github.com/apache/storm/tags/v0.9.5
1.5 Storm源码目录分析

扩展包中的三个项目,使storm能与hbase、hdfs、kafka交互

1.6 Storm源码编译

2、Storm原理
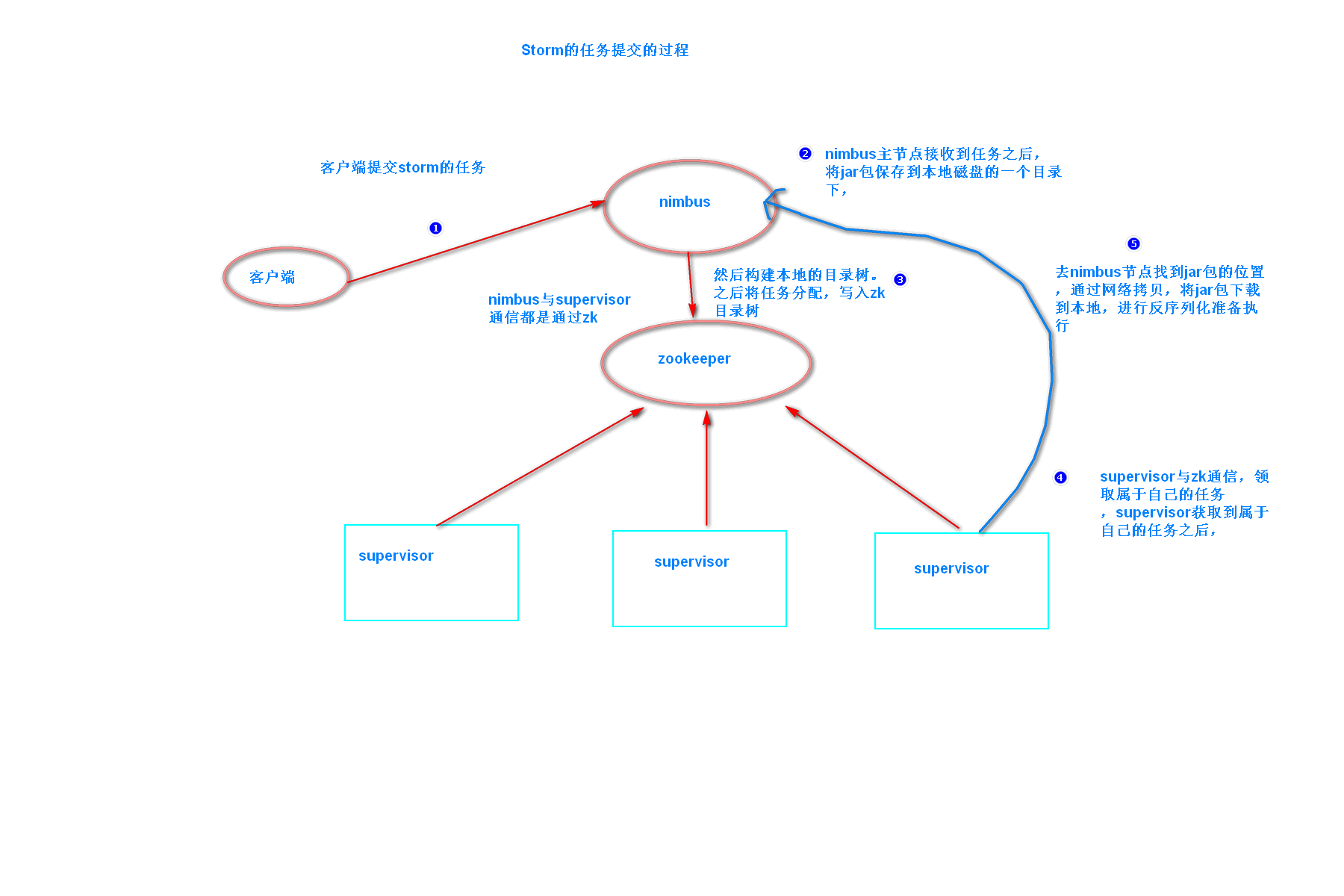
2.1 Storm 任务提交的过程
|
TopologyMetricsRunnable.TaskStartEvent[oldAssignment=<null>,newAssignment=Assignment[masterCodeDir=C:\Users\MAOXIA~1\AppData\Local\Temp\\e73862a8-f7e7-41f3-883d-af494618bc9f\nimbus\stormdist\double11-1-1458909887,nodeHost={61ce10a7-1e78-4c47-9fb3-c21f43a331ba=192.168.1.106},taskStartTimeSecs={1=1458909910, 2=1458909910, 3=1458909910, 4=1458909910, 5=1458909910, 6=1458909910, 7=1458909910, 8=1458909910},workers=[ResourceWorkerSlot[hostname=192.168.1.106,memSize=0,cpu=0,tasks=[1, 2, 3, 4, 5, 6, 7, 8],jvm=<null>,nodeId=61ce10a7-1e78-4c47-9fb3-c21f43a331ba,port=6900]],timeStamp=1458909910633,type=Assign],task2Component=<null>,clusterName=<null>,topologyId=double11-1-1458909887,timestamp=0] |

|
TopologyMetricsRunnable.TaskStartEvent[oldAssignment=<null>,newAssignment=Assignment[masterCodeDir=C:\Users\MAOXIA~1\AppData\Local\Temp\\e73862a8-f7e7-41f3-883d-af494618bc9f\nimbus\stormdist\double11-1-1458909887,nodeHost={61ce10a7-1e78-4c47-9fb3-c21f43a331ba=192.168.1.106},taskStartTimeSecs={1=1458909910, 2=1458909910, 3=1458909910, 4=1458909910, 5=1458909910, 6=1458909910, 7=1458909910, 8=1458909910},workers=[ResourceWorkerSlot[hostname=192.168.1.106,memSize=0,cpu=0,tasks=[1, 2, 3, 4, 5, 6, 7, 8],jvm=<null>,nodeId=61ce10a7-1e78-4c47-9fb3-c21f43a331ba,port=6900]],timeStamp=1458909910633,type=Assign],task2Component=<null>,clusterName=<null>,topologyId=double11-1-1458909887,timestamp=0] |

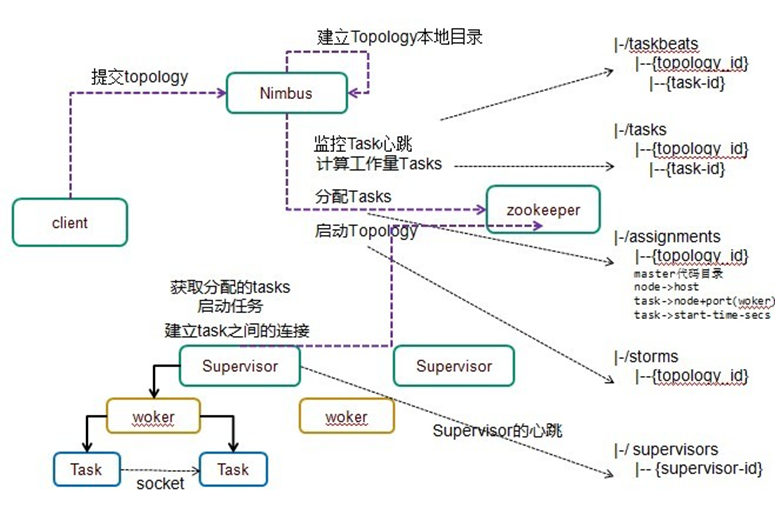
2.2 Storm组件本地目录树

2.3 Storm zookeeper目录树

2.4 Storm启动流程分析
------------程序员client------------------
1、客户端运行storm nimbus时,会调用storm的python脚本,该脚本中为每个命令编写一个方法,每个方法都可以生成一条相应的java命令。
命令格式如下:java -server xxxx.ClassName -args
nimbus---> Running: /export/servers/jdk/bin/java -server backtype.storm.daemon.nimbus
supervisor---> Running: /export/servers/jdk/bin/java -server backtype.storm.daemon.supervisor
--------------nimbus---------------------
2、nibums启动之后,接受客户端提交任务
命令格式:storm jar xxx.jar xxx驱动类 参数
Running: /export/servers/jdk/bin/java -client -Dstorm.jar=/export/servers/storm/examples/storm-starter/storm-starter-topologies-0.9.6.jar storm.starter.WordCountTopology wordcount-28
该命令会执行 storm-starter-topologies-0.9.6.jar 中的storm-starter-topologies-0.9.6.jar的main方法,main方法中会执行以下代码:
StormSubmitter.submitTopology("mywordcount",config,topologyBuilder.createTopology());
topologyBuilder.createTopology(),会将程序猿编写的spout对象和bolt对象进行序列化。
会将用户的jar上传到 nimbus物理节点的 /export/data/storm/workdir/nimbus/inbox目录下。并且改名,改名的规则是添加了一个UUID字符串。
在nimbus物理节点的 /export/data/storm/workdir/nimbus/stormdist目录下。有当前正在运行的topology的jar包和配置文件,序列化对象文件。
3、nimbus接受到任务之后,会将任务进行分配,分配会产生一个assignment对象,该对象会保存到zk中,目录是/storm/assignments ,该目录只保存正在运行的topology任务。
--------supervisor------------------
4、supervisor通过watch机制,感知到nimbus在zk上的任务分配信息,从zk上拉取任务信息,分辨出属于自己任务。
ResourceWorkerSlot[hostname=192.168.1.106,memSize=0,cpu=0,tasks=[1, 2, 3, 4, 5, 6, 7, 8],jvm=<null>,nodeId=61ce10a7-1e78-4c47-9fb3-c21f43a331ba,port=6900]
5、supervisor 根据自己的任务信息,启动自己的worker,并分配一个端口。
'/export/servers/jdk/bin/java' '-server' '-Xmx768m' export/data/storm/workdir/supervisor/stormdist/wordcount1-3-1461683066/stormjar.jar' 'backtype.storm.daemon.worker' 'wordcount1-3-1461683066' 'a69bb8fc-e08e-4d55-b51f-e539b066f90b' '6701' '9fac2805-7d2b-4e40-aabc-1c85c9856d64'
---------worker----------------------
6、worker启动之后,连接zk,拉取任务
ResourceWorkerSlot[hostname=192.168.1.106,memSize=0,cpu=0,tasks=[1, 2, 3, 4, 5, 6, 7, 8],jvm=<null>,nodeId=61ce10a7-1e78-4c47-9fb3-c21f43a331ba,port=6900]
假设任务信息:
1--->spout---type:spout
2--->bolt ---type:bolt
3--->acker---type:bolt
得到对象有几种方式? new ClassName 创建对象、class.forName 反射对象、clone 克隆对象、序列化反序列化
worker通过反序列化,得到程序员自己定义的spout和bolt对象。
7、worker根据任务类型,分别执行spout任务或者bolt任务。
spout的声明周期是:open、nextTuple、outPutFiled
bolt的生命周期是:prepare、execute(tuple)、outPutFiled
2.5 启动流程代码说明
jstorm supervisor如何启动worker,worker如何启动task
1、下载Jstorm源码,在源码包下找到 daemon包,在这个包下有三个子包,分别是nimbus,supervisor,worker。
2、通过架构图,我们已知nimbus分配任务,并将任务信息写入到zk上,supervisor读取zk上的任务后启动自己的worker。所以我们分析supervisor如何启动worker,worker如何启动task。
3、supervisor如何启动worker。打开 com.alibaba.jstorm.daemon.supervisor.Supervisor 发现supervisor有几个方法,方法中有个mkSupervisor方法。
4、进去Supervisor中的mkSupervisor方法,在第144行有以下的代码,改代码创建了SyncSupervisorEvent 对象。
SyncSupervisorEvent syncSupervisorEvent =
new SyncSupervisorEvent(supervisorId, conf, syncSupEventManager, stormClusterState, localState, syncProcessEvent, hb);
5、SyncSupervisorEvent对象实现了RunnableCallback接口,该接口有个run方法会被定时执行。在run方法的191行,有代码如下,主要是要supervisor获取到任务信息,要开始准备启动worker了。
syncProcesses.run(zkAssignment, downloadFailedTopologyIds);
6、syncProcesses是com.alibaba.jstorm.daemon.supervisor.SyncProcessEvent的
引用变量,该类中有个自定义的run方法中有段代码如下,调用的startNewWorkers方法
startNewWorkers(keepPorts, localAssignments, downloadFailedTopologyIds);
7、SyncProcessEvent的startNewWorkers方法有代码片段如下,主要是根据集群模式启动不同模式下的worker。我们跟踪分布式集群模式下的worker启动。
for (Entry<Integer, LocalAssignment> entry : newWorkers.entrySet()) {
if (clusterMode.equals(“distributed”)) {
launchWorker(conf, sharedContext, assignment.getTopologyId(), supervisorId, port, workerId, assignment);
} else if (clusterMode.equals(“local”)) {
launchWorker(conf, sharedContext, assignment.getTopologyId(), supervisorId, port, workerId, workerThreadPids);
}
}
8、在分布式模式下worker启动最终会调用一个类似于java -server xxx.worker 启动worker。由于第7步中,有个for循环,该for循环会迭代出属于当前supervisor的所有worker任务并启动。
JStormUtils.launchProcess(cmd, environment, true);
9、java -server xxx.worker,命令执行之后,会执行Worker的mian方法。worker的main方法有代码如下,其实调用了worker自己内部的静态方法,叫做mk_worker方法。
WorkerShutdown sd = mk_worker(conf, null, topology_id, supervisor_id, Integer.parseInt(port_str), worker_id, jar_path);
sd.join();
10、mk_worker静态方法,会执行以下代码,创建一个worker的实例,并立即执行execute方法。
Worker w = new Worker(conf, context, topology_id, supervisor_id, port, worker_id, jar_path);
return w.execute();
11、execute方法会执行以下代码创建一个RefreshConnections 的实例。
RefreshConnections refreshConn = makeRefreshConnections();
12、makeRefreshConnections 方法会执行以下代码创建一个RefreshConnections 实例。
RefreshConnections refresh_connections = new RefreshConnections(workerData);
13、RefreshConnections 是继承了 RunnableCallback,该实例的会有一个run方法会被定时执行。run方法中有以下代码,其中createTasks(addedTasks)方法用来创建Task任务。
shutdownTasks(removedTasks);
createTasks(addedTasks);
updateTasks(updatedTasks);
14、createTasks方法有代码如下,循环启动属于该worker的Task任务,启动Task任务主要调用Task.mk_task(workerData, taskId);
for (Integer taskId : tasks) {
try {
TaskShutdownDameon shutdown = Task.mk_task(workerData, taskId);
workerData.addShutdownTask(shutdown);
} catch (Exception e) {
LOG.error(“Failed to create task-” + taskId, e);
throw new RuntimeException(e);
}
}
15、Task.mk_task(workerData, taskId)方法实现如下,创建一个Task对象并立即调用execute方法。
Task t = new Task(workerData, taskId);
return t.execute();
16、execute方法实现如下,用来初始化一个Executor,我们知道在默认情况下一个task等于一个executor。
RunnableCallback baseExecutor = prepareExecutor();
17、进入prepareExecutor()方法,代码如下,发现代码调用了mkExecutor方法。
final BaseExecutors baseExecutor = mkExecutor();
18、mkExecutor方法,代码如下,如果当前taskObj是Bolt就创建Bolt的executor,如果当前taskObj是Spout就创建相应的Spout executor。
public BaseExecutors mkExecutor() {
BaseExecutors baseExecutor = null;
if (taskObj instanceof IBolt) {
baseExecutor = new BoltExecutors(this);
} else if (taskObj instanceof ISpout) {
if (isSingleThread(stormConf) == true) {
baseExecutor = new SingleThreadSpoutExecutors(this);
} else {
baseExecutor = new MultipleThreadSpoutExecutors(this);
}
}
return baseExecutor;
}
19、创建完了executor,现在有两条线,分别是bolt executor和spout executor。以
bolt executor 为例,这个executor会实现Disruptor的EventHandler接口。 接口onevent方法需要实现,实现代码中会调用processTupleEvent()方法。下面节选onevent中的部分代码。
if (event instanceof Tuple) {
processControlEvent();
processTupleEvent((Tuple) event);
} else if (event instanceof BatchTuple) {
for (Tuple tuple : ((BatchTuple) event).getTuples()) {
processControlEvent();
processTupleEvent((Tuple) tuple);
}
}
20、进入processTupleEvent方法,发现有代码如下,其实最终是调用了bolt.execute()方法。
private void processTupleEvent(Tuple tuple) {
try {
if (xxx) {
backpressureTrigger.handle(tuple);
} else {
bolt.execute(tuple);
}
} catch (Throwable e) {
error = e;
LOG.error(“bolt execute error “, e);
report_error.report(e);
}
}
第3节 storm高级应用:1、上次课程回顾,今日课程大纲,storm下载地址、运行过程等的更多相关文章
- ASP.NET MVC深入浅出(被替换) 第一节: 结合EF的本地缓存属性来介绍【EF增删改操作】的几种形式 第三节: EF调用普通SQL语句的两类封装(ExecuteSqlCommand和SqlQuery ) 第四节: EF调用存储过程的通用写法和DBFirst模式子类调用的特有写法 第六节: EF高级属性(二) 之延迟加载、立即加载、显示加载(含导航属性) 第十节: EF的三种追踪
ASP.NET MVC深入浅出(被替换) 一. 谈情怀-ASP.NET体系 从事.Net开发以来,最先接触的Web开发框架是Asp.Net WebForm,该框架高度封装,为了隐藏Http的无状态 ...
- 第3节 hive高级用法:16、17、18
第3节 hive高级用法:16.hive当中常用的几种数据存储格式对比:17.存储方式与压缩格式相结合:18.总结 hive当中的数据存储格式: 行式存储:textFile sequenceFile ...
- 最新linux运维高级架构课13期 架构师课程
有会员购买的,分享给大家.完整一套,可以学习一下. ├─L001-2017linux运维高级架构师13期-运维与自动化运维发展-10节 │ 1-1运维职业发展.avi │ ...
- Update(Stage4):Spark原理_运行过程_高级特性
如何判断宽窄依赖: =================================== 6. Spark 底层逻辑 导读 从部署图了解 Spark 部署了什么, 有什么组件运行在集群中 通过对 W ...
- 天草(初级+中级+高级)VIP和黑鹰VIP破解教程(全部iso下载地址)
以下就是我收集的教程地址,之前我收集到的都是一课一课下载的,虽然这样,我也下载完了天草的全部课程.这里分享的是在一起的iso文件,比起一课课下载爽多了.~~ 还有这些教程都是从零起点开始教的,不用担心 ...
- 老李推荐:第8章7节《MonkeyRunner源码剖析》MonkeyRunner启动运行过程-小结
老李推荐:第8章7节<MonkeyRunner源码剖析>MonkeyRunner启动运行过程-小结 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性 ...
- 老李推荐:第8章5节《MonkeyRunner源码剖析》MonkeyRunner启动运行过程-运行测试脚本
老李推荐:第8章5节<MonkeyRunner源码剖析>MonkeyRunner启动运行过程-运行测试脚本 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化 ...
- 老李推荐:第8章1节《MonkeyRunner源码剖析》MonkeyRunner启动运行过程-运行环境初始化
老李推荐:第8章1节<MonkeyRunner源码剖析>MonkeyRunner启动运行过程-运行环境初始化 首先大家应该清楚的一点是,MonkeyRunner的运行是牵涉到主机端和目 ...
- python高级(2)—— 基础回顾2
回顾知识 一 操作系统的作用: 隐藏丑陋复杂的硬件接口,提供良好的抽象接口 管理.调度进程,并且将多个进程对硬件的竞争变得有序 关于操作系统的发展史,可以参考我之前的一篇博文:传送门 二 多道技术: ...
随机推荐
- Unable to create a debugging engine.
用QT Creator调试的时候报如下错误: Unable to create a debugging engine. QT里面打开Tools -> Options -> Kits 发现D ...
- 「题解」「JOISC 2014 Day1」历史研究
目录 题目 考场思考 思路分析及标程 题目 点这里 考场思考 大概是标准的莫队吧,离散之后来一个线段树加莫队就可以了. 时间复杂度 \(\mathcal O(n\sqrt n\log n)\) . 然 ...
- 战争游戏OverTheWire:Bandit(一)
一个用来熟悉linux命令的游戏: Level0 告诉我们使用ssh连接网址,用户名和密码皆为bandit0.使用Xshell或者linux连接都可以 我使用的是Xshell5: Level0-> ...
- 内存泄漏与weakMap、weakSet
“DOM 引用造成内存泄露”这一点我们可以使用WeakMap或者WeakSet存储DOM节点,DOM被移除掉WeakMap或者WeakSet内部的DOM引用会被自动回收清除 https://jueji ...
- 吴裕雄 python 神经网络——TensorFlow训练神经网络:MNIST最佳实践
import os import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data INPUT_N ...
- WLC-Download 3-party CA to WLC
一.基础准备 为了创建和导入第三方SSL-certificate你需要做如下准备:1.一个WLC(随着版本的不同,可能需要准备的也不同)这里以7.0.98版本为例.2.一个外部的证书颁发机构(Cert ...
- 关于转入软件工程专业后第二次java课上作业的某些体会
今天是第二周的java课. 自从转入了软件工程专业后,在我没有学习c++的基础上,直接开始了学习java的过程.不得不说过程很艰辛.今天下午老师让编写一个随机产生作业的软件.而我的基础差到都不知道如何 ...
- 工具,Linux - tree命令,显示程序树型结构
sudo apt-get install tree tree --help
- 使用pandas读取excel
使用pandas读取excel Excel是微软的经典之作,在这里我们介绍使用Python的pandas数据分析包来解决此问题. pd.read_excel(io, sheet_name = 0, h ...
- vue配置、创建项目及运行
首先安装Node.js, npm i -g cnpm --registry=https://registry.npm.taobao.org 安装镜像 安装以后cnpm可以代替npm cnpm i -g ...