python3下scrapy爬虫(第五卷:初步抓取网页内容之scrapy全面应用)
现在爬取http://category.dangdang.com/pg1-cid4008149.html网址上的商品价格,名称,评价数量
先准备下下数据:商品名,商品链接,评价数量
第一步:在item.py里进行设置
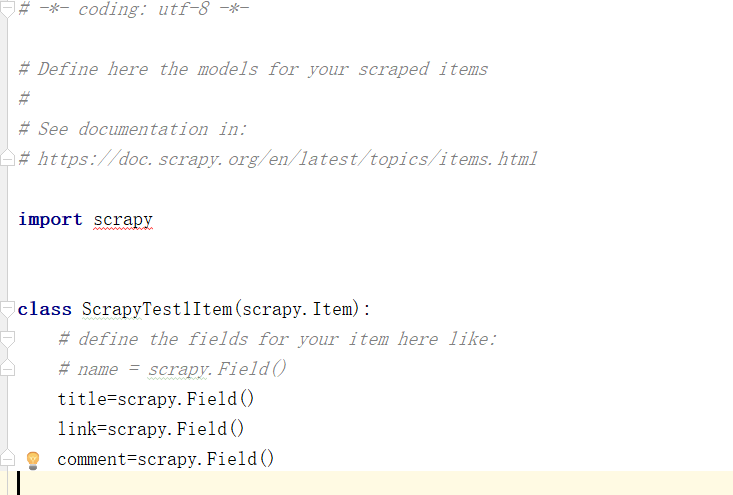
第二步:在setting里设置

将ROBOT文件设置为禁用

在设置里打开数据处理文件
第三步:编写爬虫:

第四步:执行数据处理文件

现在看一下结果:
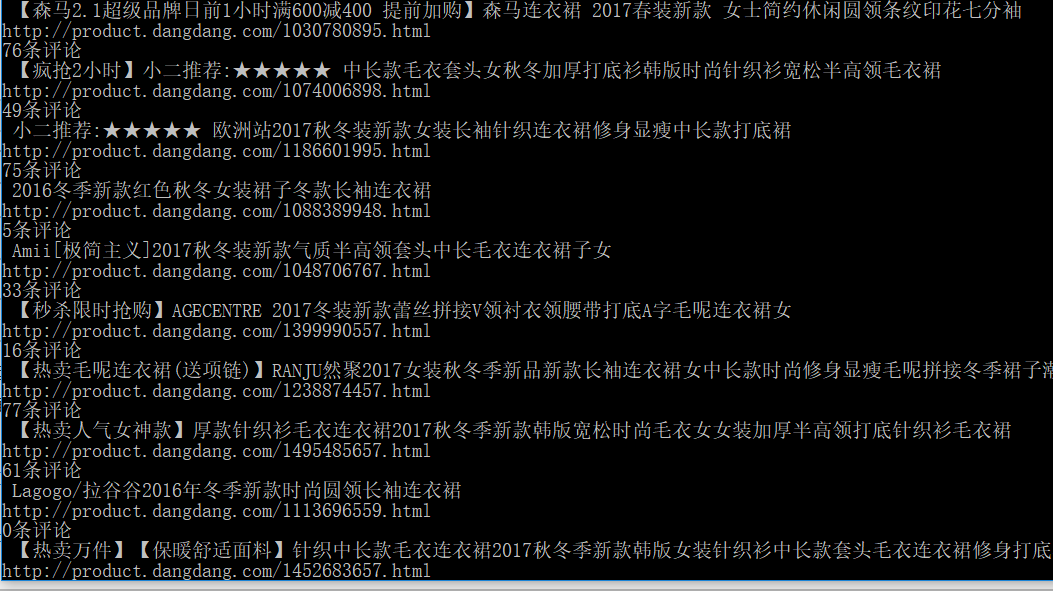
现在一个简单的scrapy爬虫实现了 注意:平时要爬虫的话尽量都把robot协议改为FALSE
python3下scrapy爬虫(第五卷:初步抓取网页内容之scrapy全面应用)的更多相关文章
- python3下scrapy爬虫(第三卷:初步抓取网页内容之抓取网页里的指定数据)
上一卷中我们抓取了网页的所有内容,现在我们抓取下网页的图片名称以及连接 现在我再新建个爬虫文件,名称设置为crawler2 做爬虫的朋友应该知道,网页里的数据都是用文本或者块级标签包裹着的,scrap ...
- python3下scrapy爬虫(第二卷:初步抓取网页内容之直接抓取网页)
上一卷中介绍了安装过程,现在我们开始使用这个神奇的框架 跟很多博主一样我也先选择一个非常好爬取的网站作为最初案例,那么我先用屌丝必备网站http://www.shaimn.com/xinggan/作为 ...
- 爬虫学习一系列:urllib2抓取网页内容
爬虫学习一系列:urllib2抓取网页内容 所谓网页抓取,就是把URL地址中指定的网络资源从网络中读取出来,保存到本地.我们平时在浏览器中通过网址浏览网页,只不过我们看到的是解析过的页面效果,而通过程 ...
- scrapy爬虫成长日记之将抓取内容写入mysql数据库
前面小试了一下scrapy抓取博客园的博客(您可在此查看scrapy爬虫成长日记之创建工程-抽取数据-保存为json格式的数据),但是前面抓取的数据时保存为json格式的文本文件中的.这很显然不满足我 ...
- python3下scrapy爬虫(第八卷:循环爬取网页多页数据)
之前我们做的数据爬取都是单页的现在我们来讲讲多页的 一般方式有两种目标URL循环抓取 另一种在主页连接上找规律,现在我用的案例网址就是 通过点击下一页的方式获取多页资源 话不多说全在代码里(因为刚才写 ...
- python3下scrapy爬虫(第四卷:初步抓取网页内容之抓取网页里的指定数据延展方法)
上卷中我运用创建HtmlXPathSelector 对象进行抓取数据: 现在咱们再试一下其他的方法,先试一下我得最爱XPATH 看下结果: 直接打印出结果了 我现在就正常拼下路径 只求打印结果: 现在 ...
- iOS—网络实用技术OC篇&网络爬虫-使用java语言抓取网络数据
网络爬虫-使用java语言抓取网络数据 前提:熟悉java语法(能看懂就行) 准备阶段:从网页中获取html代码 实战阶段:将对应的html代码使用java语言解析出来,最后保存到plist文件 上一 ...
- iOS开发——网络实用技术OC篇&网络爬虫-使用java语言抓取网络数据
网络爬虫-使用java语言抓取网络数据 前提:熟悉java语法(能看懂就行) 准备阶段:从网页中获取html代码 实战阶段:将对应的html代码使用java语言解析出来,最后保存到plist文件 上一 ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
随机推荐
- RNA分类|技术策略|终极目标
如何在转录水平分类所有RNA分子?可以罗列所有的可能性.技术策略和终极目标. 可能性:见纸 技术策略:RNA单细胞直测技术 终极目标:单细胞水平RNA直测技术决定新的人类RNA组和人类表观组学两个核心 ...
- html中的标签总结
HTML <ul> 元素(或称 HTML 无序列表元素)表示一个内可含多个元素的无序列表或项目符号列表 <ol>元素中的顺序是有意义的 <ul> 元素用来将没有数字 ...
- Ribbon使用及其客户端负载均衡实现原理分析
1.ribbon负载均衡测试 (1)consumer工程添加依赖 <dependency> <groupId>org.springframework.cloud</gro ...
- php速成_day3
一.MySQL关系型数据库 1.什么是数据库 数据库 数据存储的仓库,在网站开发应用当中,需要有一些数据存储起来. 注册的用户信息,使用PHP变量只是一个临时的存储,如果需要永久的存储起来,就把数据存 ...
- Excel Old format or invalid type library 错误原因
Old format or invalid type library 错误原因 调用excel方法失败,Old format or invalid type library 解决方案: 1,这是Exc ...
- 17.3.12---xmlrpclib模块
1----XML-RPC是一种使用xml文本的方式利用http协议传输命令和数据的rpc基址,我们用pythom的想mlrpclib模块可以让程序与其他任何语言编写的XML-RPC服务器进行数据传输 ...
- ruoyi ShiroUtils
package com.ruoyi.framework.util; import org.apache.shiro.SecurityUtils; import org.apache.shiro.cry ...
- java和数据库中所有的锁都在这了
1.java中的锁 1.1 锁的种类 公平锁/非公平锁 可重入锁/不可重入 独享锁/共享锁 读写锁 分段锁 偏向锁/轻量级锁/重量级锁 自旋锁 1.2 锁详细介绍 1.2.1 公平锁,非公平锁 公平锁 ...
- Ubuntu源码编译安装tensorflow
ubuntu14 cuda9.0_384.81 驱动版本384.90 cudnn7.2 tensorflow1.8 https://blog.csdn.net/pkokocl/article/det ...
- Velocity脚本入门教程
下面资料整理自网络 一.Velocity介绍 Velocity是Apache公司的开源产品,是一套基于Java语言的模板引擎,可以很灵活的将后台数据对象与模板文件结合在一起,说的直白一点,就是允许任何 ...