2,MapReduce原理及源码解读
MapReduce原理及源码解读
一、分片
灵魂拷问:为什么要分片?
- 分而治之:MapReduce(MR)的核心思想就是分而治之;何时分,如何分就要从原理和源码来入手。做为码农大家都知道,不管一个程序多么复杂,在写代码和学习代码之前最重要的就是搞懂输入和输出,而MR的输入其实就是一个目录。而所谓的分而治之其实也是在把大文件分成小文件,然后一个机器处理一个小文件,最后再合并。所以MR的第一步就是对输入的文件进行分片。
1.1 对谁分片
对每个文件分片:分片是对输入目录中的每一个文件进行分片。后面的分片都是针对单个文件分片。
源码解读(对谁分片):
// 分片的源码位置package org.apache.hadoop.mapreduce.lib.input;abstract class FileInputFormat.java;// 下面代码所在方法method getSplits();// InputStatus表示一个切片类List<InputSplit> splits = new ArrayList<InputSplit>();// 得到所有输入文件List<FileStatus> files = listStatus(job);// 遍历每个文件。 根据每个文件来切片,而不是整个文件夹for (FileStatus file : files) {// 分片1}
1.2 长度是否为0
- 文件长度:当文件长度不为0时才会进行下面的分片操作;如果文件长度为0,则会向分片列表中添加一个空的hosts文件数组和空长度的文件。也就是说,空文件也会创建一个空的分片。
- 源码解读(长度是否为0):
for (FileStatus file : files) {Path path = file.getPath();// 获取文件大小long length = file.getLen();if (length != 0) {// 分片2} else {// 如果文大小为空,默认就创建一个空的hosts文件数组和空长度的文件//Create empty hosts array for zero length filessplits.add(makeSplit(path, 0, length, new String[0]));}}
1.3 是否可以分片
- 压缩格式:并不是所有的文件都可以分片,有一些压缩格式的文件是不可以分片的。因此只会对可以分片的文件进行分片,而不可以分片的文件即使再大也会作为一个整体来处理,相当于一个片。
- 源码解读(是否可以分片):
// 如果可以分片if (isSplitable(job, path)) {// 分片3} else { // not splitablesplits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),blkLocations[0].getCachedHosts()));}// 判断一个文件是否可以切片// FileInputFormat抽象类中默认返回true,子类TextInputFormat中实现如下@Overrideprotected boolean isSplitable(JobContext context, Path file) {final CompressionCodec codec =new CompressionCodecFactory(context.getConfiguration()).getCodec(file);if (null == codec) {// 如果一个文件的压缩编码为null,那么表示可以切片return true;}// 如果一个文件的压缩编码是SplittableCompressionCodec的子类,那么表示当前文件也可以切片return codec instanceof SplittableCompressionCodec;}
1.4 分片的大小
- 分片大小:分片太大就失去了分片的意义;如果分片很小,则管理和构建map任务的时间就会增多,效率变低。并且如果分片跨越两个数据块,那么分片的部分数据需要通过网络传输到map任务运行的节点上,效率会更低。所以分片的最佳大小应该和HDFS的分块大小一致。Hadoop2默认128M。
- 源码解读(分片大小):
// FormatMinSplitSize是 1, MinSplitSize如果没配置默认是 1long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));// 如果没配置,则默认是 Long类型的最大值long maxSize = getMaxSplitSize(job);// 块大小,Hadoop2是128M,本地模式为32Mlong blockSize = file.getBlockSize();// 分片大小计算公式。默认就是blockSize的大小long splitSize=Math.max(minSize, Math.min(maxSize, blockSize));
- 自定义分片大小:由上面的公式可知,默认的分片大小就是blockSize的大小。如果要自定义大于blockSize,比如改为200M,就把minSize改为200;小于blockSize,比如20M,就把maxSize改为20
- 1.1倍:最常见的问题就是:一个大小为130M的文件,在分片大小为128M的集群上会分成几片?答案是1片;因为 128*1.1>130,准确来说应该是130 / 128 < 1.1 (源码的公式)。也就是说,如果剩下的文件大小在分片大小的1.1倍以内,就不会再分片了。要这个1.1倍,是为了优化性能;试想如果不这样,当还剩下130M大小的时候,就会分成一块128M,一块2M,后面还要为这个2M的块单独开一个map任务,不划算。至于为什么是1.1,这个1.1是专家们通过反复试验得出来的结果。
- 源码解读(1.1倍):
// 当剩余文件的大小,大于分片大小的1.1倍时,才会分片private static final double SPLIT_SLOP = 1.1; // 10% slop// bytesRemaining为文件剩余大小,splitSize为上面计算出的分片大小while (((double) bytesRemaining) / splitSize > SPLIT_SLOP) {// 分片4}
1.5 开始分片
- 终于分片了:经过上面的层层条件,下面就是// 分片4中的分片代码。与HDFS的物理分块不同的是,MapReduce的分片只是逻辑上的分片,即按照偏移量分片。
// 封装一个分片信息(包含文件的路径,分片的起始偏移量,要处理的大小,分片包含的块的信息,分片中包含的块存在哪儿些机器上)int blkIndex = getBlockIndex(blkLocations, length - bytesRemaining);// makeSplit进行切片操作,返回值是一个切片,并且加入到切片列表中splits.add(makeSplit(path, length - bytesRemaining, splitSize,blkLocations[blkIndex].getHosts(),blkLocations[blkIndex].getCachedHosts()));// 剩余文件大小bytesRemaining -= splitSize;
1.6 分片后读取会不会断行
- 不会:由于分片时是按照长度进行分片的,那就有很大可能会把一行数据分在两个片里面,所以分片的时候确实会断行。如果读取并处理断行的数据,就会导致结果不正确,那是肯定不行的。所以LineRecordReader类就充当了读取记录的角色,保证读取不断行;其中nextKeyValue()方法里是真正给Mapper中的key赋值的地方,并且调用了父类LineReader类中的readLine()方法来给value赋值。
- 源码解读(读取时不断行):
public class TextInputFormat extends FileInputFormat<LongWritable, Text> {@Overridepublic RecordReader<LongWritable, Text>createRecordReader(InputSplit split,TaskAttemptContext context) {String delimiter = context.getConfiguration().get("textinputformat.record.delimiter");// 行分隔符byte[] recordDelimiterBytes = null;if (null != delimiter)recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);// 返回LineRecordReader对象return new LineRecordReader(recordDelimiterBytes);}}// 行记录读取类,提供读取片中数据的功能,并且保证不断行public class LineRecordReader extends RecordReader<LongWritable, Text> {// ......其他代码public void initialize(InputSplit genericSplit,TaskAttemptContext context) throws IOException {// ......// 如果不是第一个分片,则开始位置退到下一行记录的开始位置// 因为为了保证读取时不断行,每个块都会向后多读一行(最后一个除外)if (start != 0) {start += in.readLine(new Text(), 0, maxBytesToConsume(start));}}public boolean nextKeyValue() throws IOException {// 给Mapper中输入的key赋值key.set(pos);// 实例化Mapper中输入的valueif (value == null) {value = new Text();}// 注意是<=end,在等于end时还会执行一次,多读了一行,所以不会断行while (getFilePosition() <= end || in.needAdditionalRecordAfterSplit()) {if (pos == 0) {newSize = skipUtfByteOrderMark();} else {// 给Mapper中输入的value赋值。// readLine方法会根据是否自定义行分隔符来调用不同的方法。newSize = in.readLine(value, maxLineLength, maxBytesToConsume(pos));pos += newSize;}}}}
二、Map阶段
2.1 实例化Mapper
各种实例化:上面费了很大的劲来编写分片TextInputFormat,和读取类LineRecordReader;而这一切都是为了把输入数据很好的传给map()方法来运算,所以首先就要实例化我们自定义的Mapper类。
源码解读(各种实例化):
package org.apache.hadoop.mapred;class MapTask.java;method runNewMapper();// 通过反射来获取Mapper。在Job中设置的Mapper,也就是自己定义的继承自Mapper的类org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE> mapper =(org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>)ReflectionUtils.newInstance(taskContext.getMapperClass(), job);// 通过反射来得到 InputFormat。默认是TextInputFormatorg.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE> inputFormat =(org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE>)ReflectionUtils.newInstance(taskContext.getInputFormatClass(), job);// 获得当前MapTask要处理的splitorg.apache.hadoop.mapreduce.InputSplit split = null;split = getSplitDetails(new Path(splitIndex.getSplitLocation()),splitIndex.getStartOffset());LOG.info("Processing split: " + split);// 根据InputFormat对象创建RecordReader对象。默认是LineRecordReaderorg.apache.hadoop.mapreduce.RecordReader<INKEY,INVALUE> input =new NewTrackingRecordReader<INKEY,INVALUE>(split, inputFormat, reporter, taskContext);// 初始化。用来打开文件,并且调整文件的头指针input.initialize(split, mapperContext);// MapTask中调用Mapper的run()方法mapper.run(mapperContext);
2.2 调用map()方法
- 每行数据调用一次:从上面的代码中我们知道,MapTask中会调用Mapper类的run()方法;而run()方法会在while循环中调用map()方法,由退出条件可知,是每一行数据调用一次map()方法。
- 源码解读(怎么调用map()方法):
public void run(Context context) throws IOException, InterruptedException {// 在所有map执行之前初始化,也可以根据业务需要来重写此方法setup(context);try {// context.nextKeyValue()其实就是LineRecordReader中的nextKeyValue()方法;// 在run方法中遍历所有的key,每行数据都执行一次自定义map方法;while (context.nextKeyValue()) {map(context.getCurrentKey(), context.getCurrentValue(), context);}} finally {// 父类Mapper中的setup()和cleanup()方法中什么都没做;// 只执行一次,可以根据业务需要来重写此方法;cleanup(context);}}
三、Shuffle阶段
灵魂拷问:哪来的Shuffle?
- 理论与实现:看过源码的都知道,其实源码中根本就没有什么shuffle;shuffle只是一个过程,确切的来说是连贯Map阶段和reduce阶段的一个理论过程,而它的实现主要在MapTask和ReduceTask类中。shuffle阶段可以说是MapReduce中最核心的一个阶段。
3.1 shuffle的概念
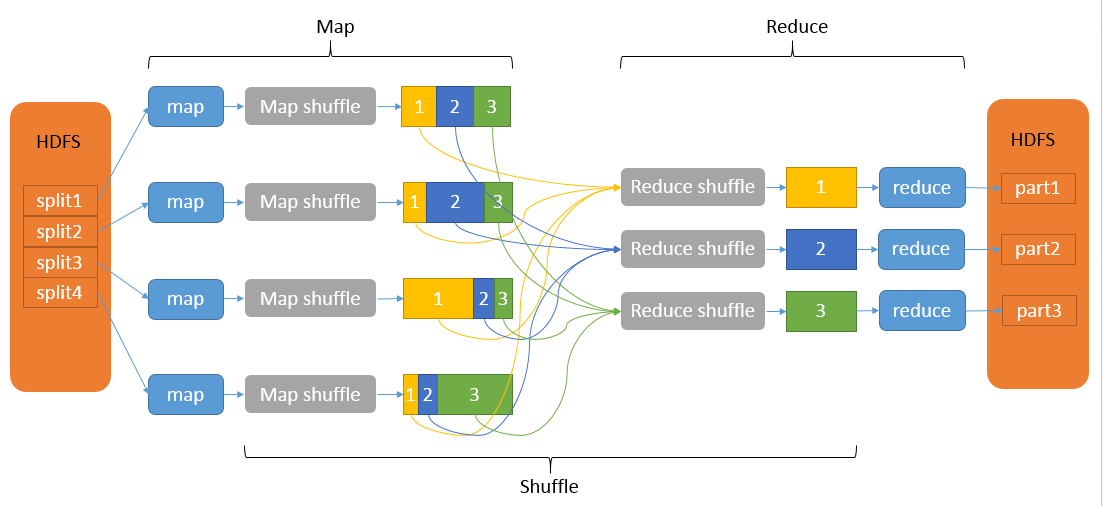
- 作用:shuffle这个单词的本意是洗牌、打乱的意思,而在这里则是:将map端的无规则输出按照指定的规则“打乱”成具有一定规则的数据,以便reduce端接收和处理。
- 流程:shuffle的范围是map输出后到reduce输入前。它的流程主要包括Map端shuffle和reduce端shuffle。
- MapReduce大致流程:
3.2 Map端Shuffle
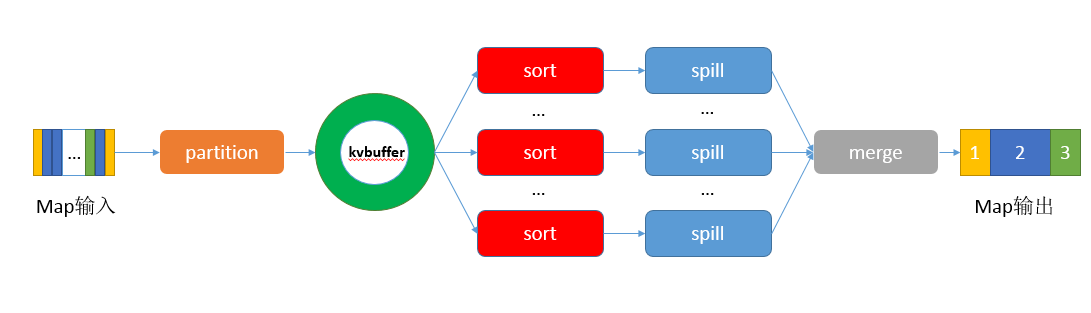
- 作用:Map端的shuffle过程是对Map的结果进行分区、排序、溢写、合并分区,最后写入磁盘;最终会得到一个分区有序的文件,即先按分区排序,再按key排序。
- Map端shuffle大致流程:
3.2.1 分区(partition)
- 概念:对于map的每一个输出的键值对,都会根据key来生成partition再一起写入环形缓冲区。每一个reduceTask会处理一个partition(第0个reduceTask处理partition为0的分区,以此类推)。
- 如何分区:默认情况下,分区号是key的hash值对numReduceTask数量取模的结果。也可以自定义分区。
- 源码解读(如何分区):
// 当设置的reduceTask数大于实际分区数时,可以正常执行,多出的分区为空文件;// 当设置的reduceTask数小于实际分区数时,会报错。job.setNumReduceTasks(4);// 如果设置的 numReduceTasks大于 1,而又没有设置自定义的 PartitionerClass// 则会调用系统默认的 HashPartitioner实现类来计算分区。job.setPartitionerClass(WordCountPartitioner.class);
// 自定义分区public class WordCountPartitioner extends Partitioner<Text, IntWritable> {private static HashMap<String, Integer> map = new HashMap<>();static {map.put("0734", 0);map.put("0561", 1);map.put("0428", 2);}// 当 Mapper的输出要写入环形缓冲区时,会调用此方法来计算当前<K,V>的分区号@Overridepublic int getPartition(Text text, IntWritable intWritable, int numPartitions) {String strText = text.toString();return map.getOrDefault(strText.substring(0, 4), 3);}}
// MapTask.java$NewOutputCollectorpublic void write(K key, V value) throws IOException, InterruptedException {// 把 K,V以及分区号写入环形缓冲区collector.collect(key, value,partitioner.getPartition(key, value, partitions));}
3.2.2 写入环形缓冲区
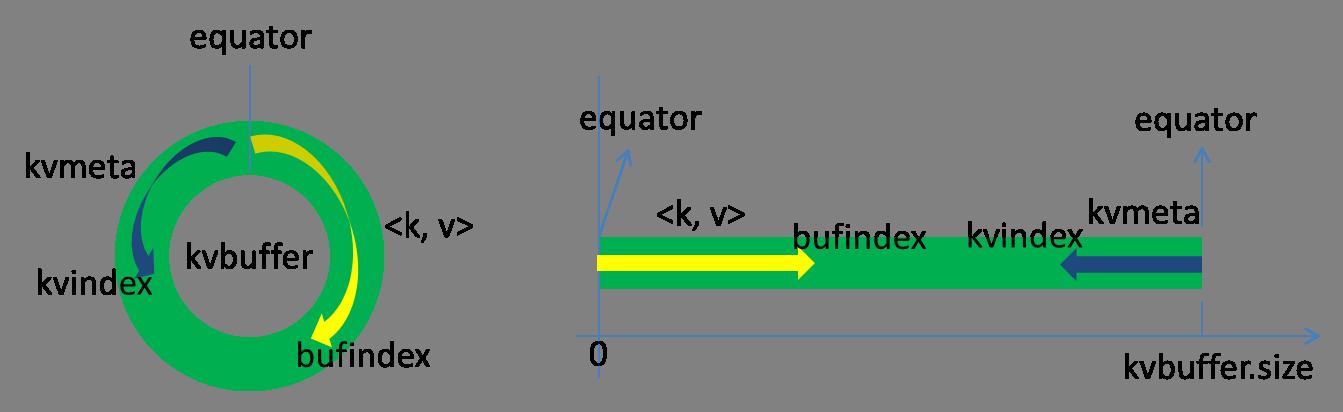
- 概念:环形缓冲区是在内存中的一个字节数组kvbuffer。kvbuffer不仅存放map输出的<k, v>,还在另一端存放了<k, v>的索引(元数据) kvmeta,每个kvmeta包括value的起始位置、key的起始位置、partition值、value的长度,占用4个int长度。上图中的bufindex和kvindex分别表示kvbuffer和kvmeta的指针。环形缓冲区的默认大小是100M,当写入数据大小超过80%(80M)就会触发Spill,溢写到磁盘。
- 源码解读(Spill):
// SpillThread线程在MapTask$MapOutputBuffer类中初始化,在init()方法中启动。// 它会一直监视环形缓冲区,当大小超过80%的时候,就会调用sortAndSpill()方法。protected class SpillThread extends Thread {@Overridepublic void run() {// ....// run方法中调用排序并溢写方法while (true) {// ....sortAndSpill();}//....}}
3.2.3 排序并溢写(sortAndSpill):
- 排序:触发溢写后,会先排序,再溢写。排序是根据partition和key的升序排序,移动的只是索引数据,排序的结果是将kvmeta中到的数据按照partition聚合在一起,同一个partition内再根据key排序。

- 溢写:Spill线程根据排序后的kvmeta文件,将一个个partition输出到文件,在这次溢写过程中,会将环形缓冲区中已计算的数据(80M)写入到一个文件spill.out,所以引入了索引文件spill.index,它记录了partition在spill.out中的位置。
3.2.4 合并(merge):
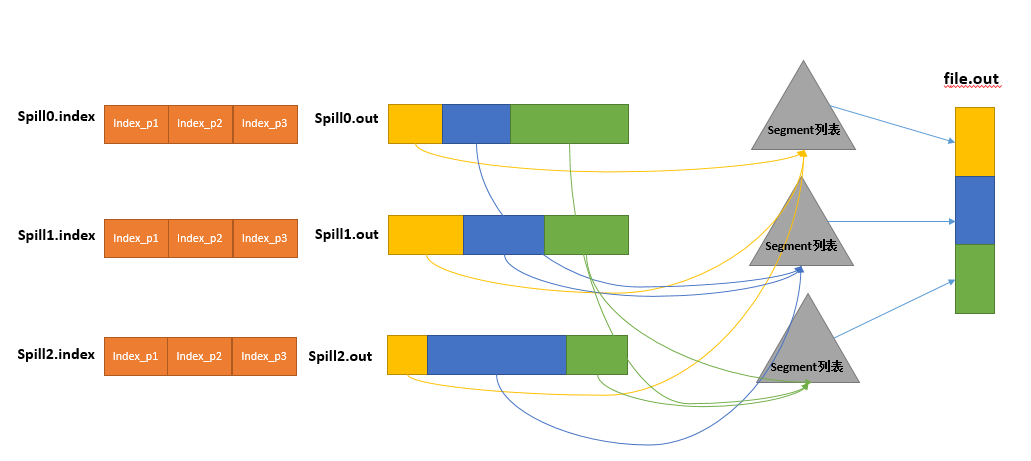
- 概念:如果Map的数据很大,那么就会触发多次Spill,spill.out和spill.index文件也会很多。所以最后就要把这些文件合并,方便Reduce读取。
- 合并过程:合并过程中,首先会根据spill.index文件,将spill.out文件中的partition使用归并排序分别写入到相应的segment中,然后再把所有的segment写入到一个file.out文件中,并用file.out.index来记录partition的索引。由于合并时可能有相同的key,所以如果设置了combine,那么在写入文件之前还会调用自定义的combine方法。
3.3 Reduce端Shuffle
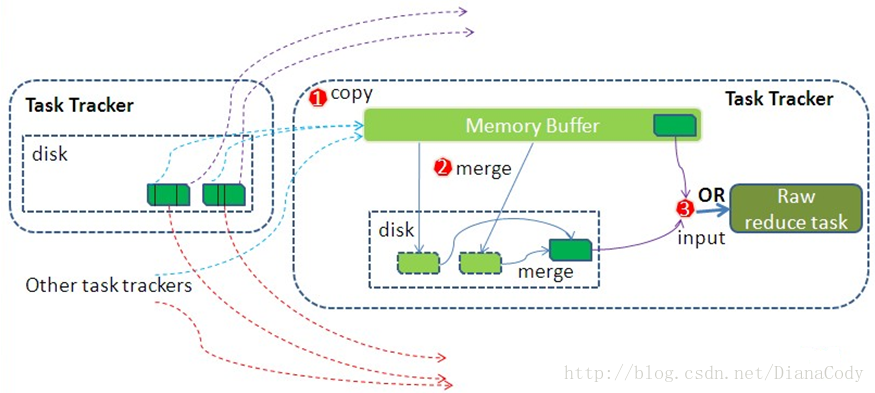
3.3.1 拉取(Copy)
- 前期工作:Reduce任务会通过HTTP向各个Map任务拉取它所需的partition数据。当Map任务成功完成之后会通知 TaskTracker状态已跟新,TaskTracker进而通知JobTracker(都是通过心跳机制实现),所以JobTracker中记录了Map输出和TaskTracker的映射关系。
- 何时拉取:Reduce会定期向JobTracker获取Map的输出位置,一旦拿到输出位置,Reduce任务就会立即从此输出对应的TaskTracker上复制相应的partition数据到本地,而不是等到所有Map任务结束。
3.3.2 排序合并(Merge Sort)
- 合并:copy过来的数据会先放入内存缓冲区中(大小是 JVM的heap size的70%),如果缓冲区放得下就直接把数据写入内存,即内存到内存merge。如果缓冲区中的Map数据达到一定大小(缓冲区的66%)的时候,就会开启内存merge,并将merge后的数据写入磁盘,即内存到磁盘merge。当属于该Reduce任务的map输出全部拉取完成,则会在reduce任务的磁盘上生成多个文件(如果所有map输出的大小没有超过缓冲区大小,则数据只存在于内存中),这时开始最后的合并操作,即磁盘到磁盘merge。如果设置了combine,合并时也会执行。
- 排序:由于map输出的数据已经是有序的,所以reduce在合并时的排序是归并排序,并且reduce端的copy和sort是同时进行的,最终会得到一个整体有序的数据。
3.3.3 归并分组(reduce)
归并分组(reduce):当reduce任务执行完拉取和排序合并后,就会对相同的key进行分组。默认情况下是根据key对象中重写的compareTo()方法来分组,如果设置了GroupingComparator,则会调用它的compare()方法来分组。reduce会把compareTo(或compare)方法计算返回为 0 的key分为一组,最终会得到一个组<key, Iterable<value,>>,其中组的key是这一组的第一个数据的key,Iterable<value,>则是相同key的value迭代器。最后再对每一个组调用Reducer的reduce()方法。
源码解读(分组):
// org.apache.hadoop.mapreduce.Reducer中的run()方法while (context.nextKey()) {// 调用自定义 reduce方法reduce(context.getCurrentKey(), context.getValues(), context);// .....}// org.apache.hadoop.mapreduce.task.ReduceContextImpl中的方法public boolean nextKey() throws IOException,InterruptedException {// 如果当前key与下一个key相同,则继续往下走;// 这一步就是把相同的key放到一组, 他们的value放到一个迭代器中;当下一个key不同时再调用reduce方法while (hasMore && nextKeyIsSame) {nextKeyValue();}if (hasMore) {if (inputKeyCounter != null) {// 计数器inputKeyCounter.increment(1);}// 当nextKeyIsSame为false时,会再调用一次nextKeyValue(),而它的返回值必为true;return nextKeyValue();} else {return false;}}@Overridepublic boolean nextKeyValue() throws IOException, InterruptedException {if (hasMore) {nextKey = input.getKey();// 在执行reduce方法之前调用ReduceContext中定义的GroupComparator// 如果key的compareTo方法返回0则 nextKeyIsSame为true,也就会分到一组nextKeyIsSame = comparator.compare(currentRawKey.getBytes(), 0,currentRawKey.getLength(),nextKey.getData(),nextKey.getPosition(),nextKey.getLength() - nextKey.getPosition()) == 0;} else {nextKeyIsSame = false;}inputValueCounter.increment(1);return true;}
四、Reduce阶段
4.1 执行reduce()方法
- 归并:上面的Shuffle阶段已经将数据分组成了<key, Iteralble<value,>>格式的数据,所以对于相同的key只会调用一次reduce()方法。
- 注意事项:在reduce()方法中,一定要重新创建key对象,不要直接使用参数中的key。
4.2 输出最终结果
- 完结:整个MapReduce的输出和输入有点类似。输出是实例化TextOutputFormat和LineRecordWrite对象。并由LineRecordWrite判断是不是NullWriteable,最后输出到文件
参考文章:
- https://blog.csdn.net/u014374284/article/details/49205885
- https://blog.csdn.net/asn_forever/article/details/81233547
2,MapReduce原理及源码解读的更多相关文章
- 第二十三课:jQuery.event.add的原理以及源码解读
本课主要来讲解一下jQuery是如何实现它的事件系统的. 我们先来看一个问题: 如果有一个表格有100个tr元素,每个都要绑定mouseover/mouseout事件,改成事件代理的方式,可以节省99 ...
- http-proxy-middleware使用方法和实现原理(源码解读)
本文主要讲http-proxy-middleware用法和实现原理. 一 简介 http-proxy-middleware用于后台将请求转发给其它服务器. 例如:我们当前主机A为http://loca ...
- Future、FutureTask实现原理浅析(源码解读)
前言 最近一直在看JUC下面的一些东西,发现很多东西都是以前用过,但是真是到原理层面自己还是很欠缺. 刚好趁这段时间不太忙,回来了便一点点学习总结. 前言 最近一直在看JUC下面的一些东西,发现很多东 ...
- Vue.use原理及源码解读
vue.use(plugin, arguments) 语法 参数:plugin(Function | Object) 用法: 如果vue安装的组件类型必须为Function或者是Object<b ...
- serve-index用法、实现原理(源码解读)
本文主要讲解serve-index的用法和实现原理(源代码分析). 一 说明 serve-index的功能是将文件夹中文件列表显示到浏览器中. serve-index是一个NodeJS模块,可以通过N ...
- HttpClient 4.3连接池参数配置及源码解读
目前所在公司使用HttpClient 4.3.3版本发送Rest请求,调用接口.最近出现了调用查询接口服务慢的生产问题,在排查整个调用链可能存在的问题时(从客户端发起Http请求->ESB-&g ...
- HttpClient4.3 连接池参数配置及源码解读
目前所在公司使用HttpClient 4.3.3版本发送Rest请求,调用接口.最近出现了调用查询接口服务慢的生产问题,在排查整个调用链可能存在的问题时(从客户端发起Http请求->ESB-&g ...
- Vue 源码解读(12)—— patch
前言 前面我们说到,当组件更新时,实例化渲染 watcher 时传递的 updateComponent 方法会被执行: const updateComponent = () => { // 执行 ...
- [Hadoop源码解读](六)MapReduce篇之MapTask类
MapTask类继承于Task类,它最主要的方法就是run(),用来执行这个Map任务. run()首先设置一个TaskReporter并启动,然后调用JobConf的getUseNewAPI()判断 ...
随机推荐
- HDU——算法练习1000 1089-1096
全篇都是讲数字之间的运算的: 由上自下难度逐渐升级 ,没耐心者建议一拉到底: 1000: Problem Description Calculate A + B. Input Each line ...
- linux tc流量控制
tc流量控制 项目背景 vintage3.0接口lookupforupdage增加一个策略,当带宽流量tx或rx超过40%,75%随机返回304:超过60%,此接口均返回304 为了对测试机器进行流量 ...
- win10环境下VS2019配置NTL库
win10环境下VS2019配置NTL库 1.下载 WINNTL库文件 https://www.shoup.net/ntl/download.html 2.创建静态库 文件->新建-&g ...
- 一文看懂js中元素偏移量(offsetLeft,offsetTop,offsetWidth,offsetHeight)
偏移量(offset dimension) 偏移量:包括元素在屏幕上占用的所有可见空间,元素的可见大小有其高度,宽度决定,包括所有内边距,滚动条和边框大小(注意,不包括外边距). 以下4个属性可以获取 ...
- idea导入 spring framework项目
准备的环境:gradle,idea 注意:gradle版本不一致会报各种错误,那么怎么查找依赖的版本呢? 首先在git上把spring framework项目拉取下来, 步骤一:复制URL路径 步骤二 ...
- 由一个项目需求引发的 - textarea中的换行和空格
当我们使用 textarea 在前台编辑文字,并用 js 提交到后台的时候,空格和换行是我们最需要考虑的问题.在textarea 里面,空格和换行会被保存为/s和/n,如果我们前台输入和前台显示的文字 ...
- JZOJ 5258. 友好数对 (Standard IO)
5258. 友好数对 (Standard IO) Time Limits: 1000 ms Memory Limits: 524288 KB Detailed Limits Description I ...
- 谈谈集合.Queue
之前说到,Java中集合的主要作用就是装盛其他数据和实现常见的数据结构.所以当我们要用到"栈"."队列"."链表"和"数组&quo ...
- git删除远程仓库中的文件夹
具体操作如下: git rm -r --cached .history #删除目录 git commit -m”删除.history文件夹” git push -r表示递归所有子目录,如果你要删 ...
- C++ 随笔练习
//例题:求Sn=a+aa+aaa+…+aa…aaa(有n个a)之值,其中a是一个数字,为2. 例如,n=5时=2+22+222+2222+22222,n由键盘输入.//题目来源:https://ww ...