Kafka 安装及入门
什么是Kafka?
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。
Kafka基本概念
Broker:物理概念,Kafka集群中的每个Kafka节点;
Topic:逻辑概念,Kafka消息的类别,对数据进行区分、隔离;
Partition:物理概念,Kafka下数据存储的基本单元。一个Topic数据,会被分散存储到多个Partition,每一个Partition是有序的;
Replication(副本、备份):同一个Partition可能会有多个Replica,多个Replica之间数据是一样的;
Replication Leader:一个Partitionn的多个Replica上,需要一个Leader负责该Partition上与Producer和Consumer交互;
ReplicaManager:负责管理当前broker所有分区和副本的信息,处理KafkaController发起的一些请求,副本状态的切换、添加/读取消息、Leader的选举等。
Kafka概念延伸
Partition(最小存储单元)
每一个Topic被切分为多个Partitions(Partition属于消费者存储的基本单位);
消费者数目小于或等于Partition的数目(多个消费者若消费同个Partition会出现数据错误,所有Kafka如此设计);
Broker Group中的每一个Broker保存Topic的一个或多个Partitions(一个Broker只会保存一个Partition,若Partition太大则多个Broker保存同个Partition);
Consumer Group中的仅有一个Consumer读取Topic的一个或多个Partitions,并且是唯一的Consumer(避免同一个Partition被多个Consumer消费)。
Replication
当集群中有Broker挂掉的情况,系统可以主动地使Replicas提供服务;
系统默认设置每一个Topic的replication系数为1(即默认没有副本,节省资源),可以在创建Topic时单独设置。
特点:
Replication的基本单位是Topic的Partition;
所有的读和写都从Leader进,Followers只是做为备份(只有Leader管理读写,其他的Replication只做备份);
Follower必须能够及时复制Leader的数据;
增加容错性与可拓展性。
Kafka基本结构
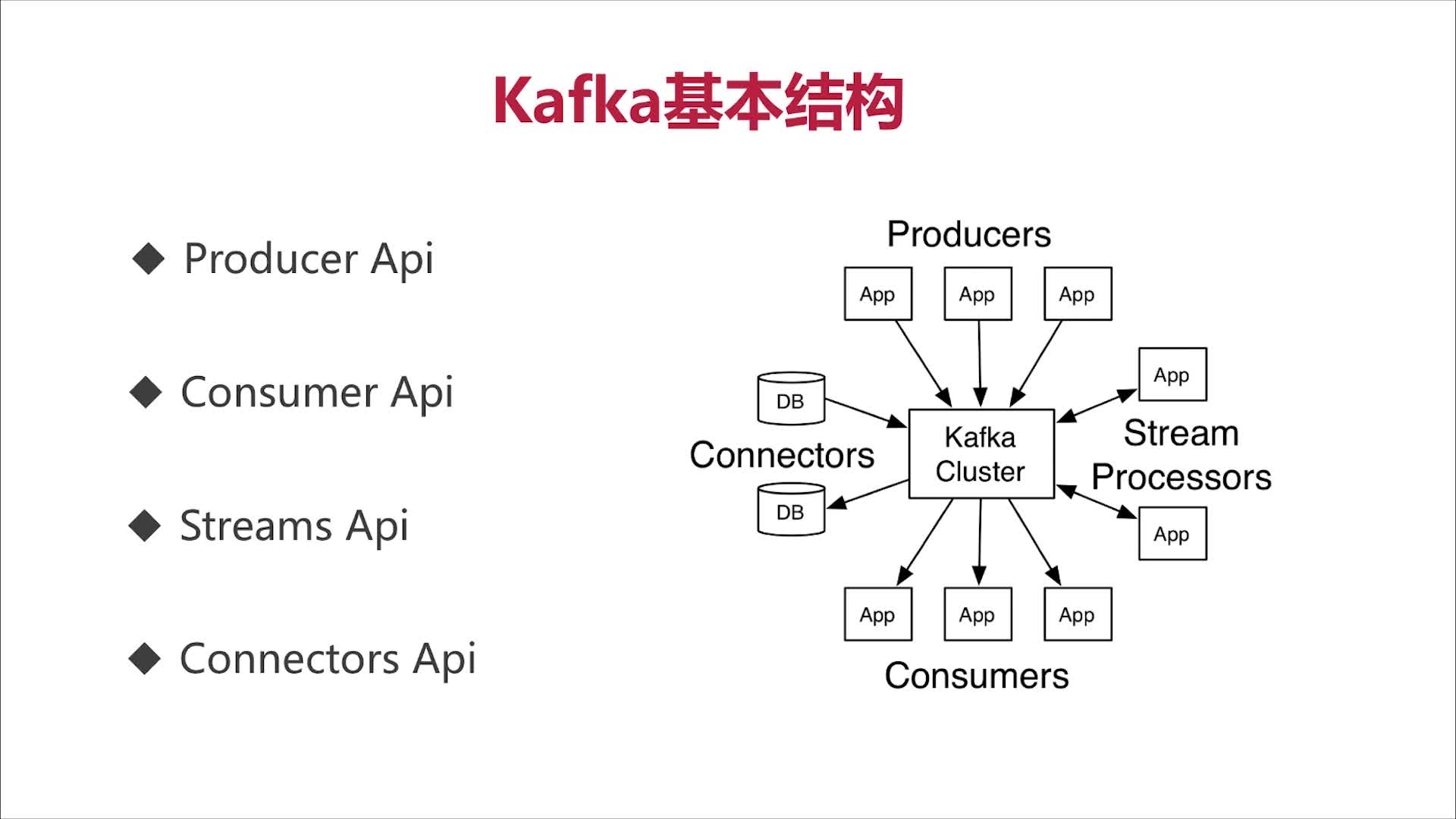
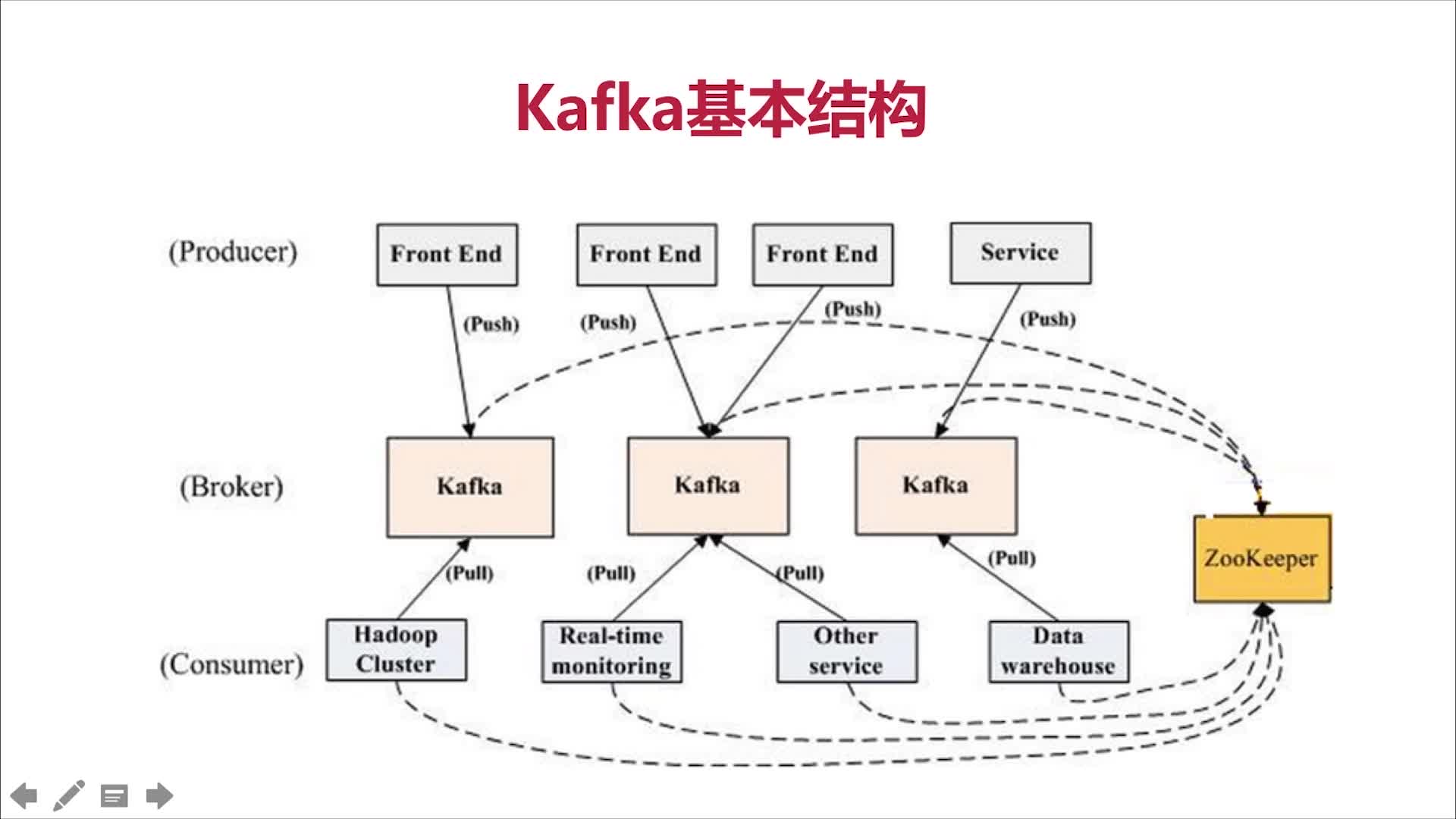
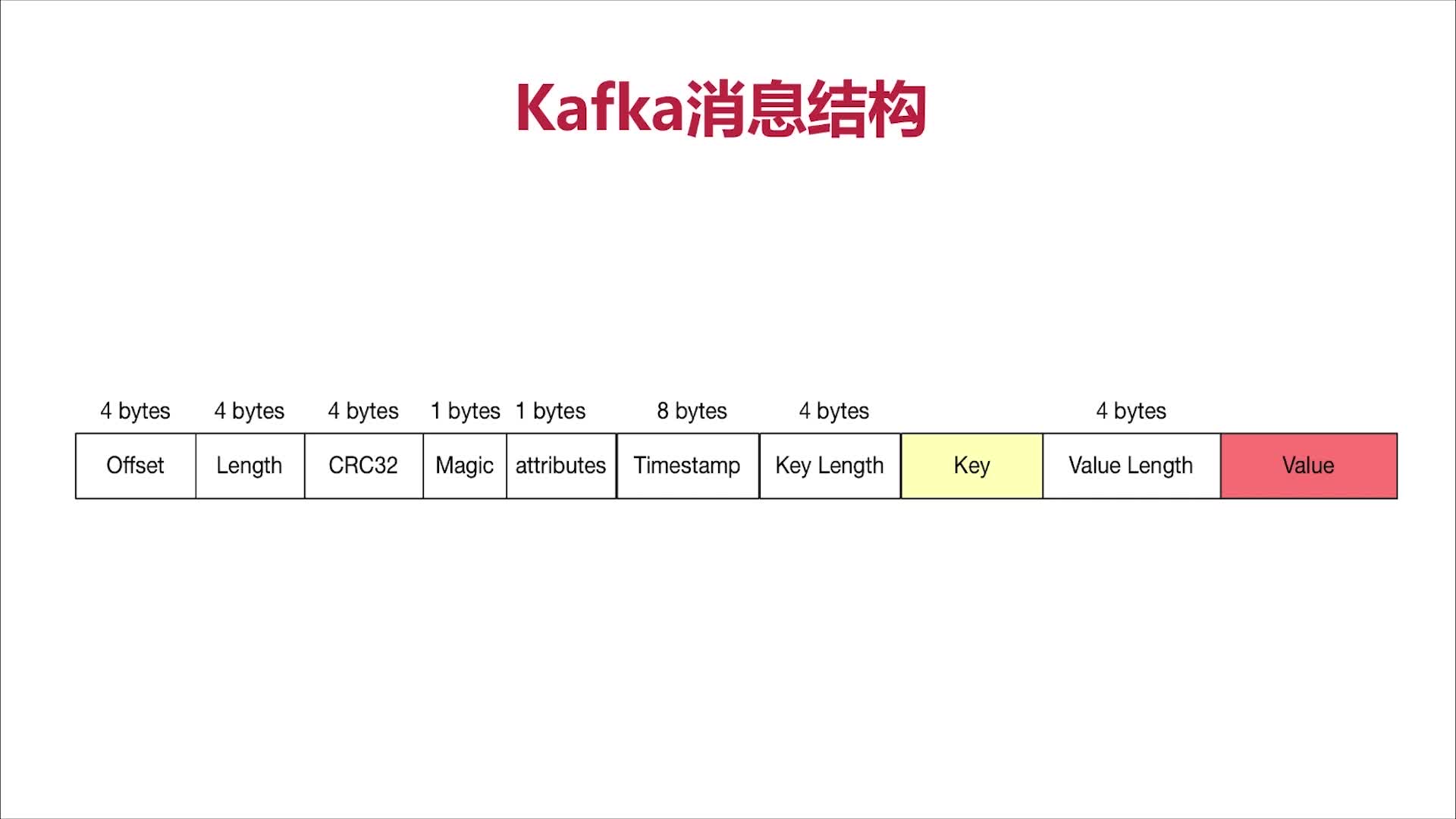
Kafka消息结构
Kafka特点
- 分布式(多分区,多副本,多消费者,基于ZooKeeper调度);
- 高性能(高吞吐,低延时,高并发,时间复杂度为O(1));
- 持久性和扩展性(数据可持久化,容错率,支持在线水平扩展,消息自动平衡)。
Kafka应用场景
消息队列,行为跟踪,元信息监控,日志收集,流处理,事件源,持久性日志(commit log)等。
Kafka安装(Linux下)
需要安装JDK(步骤略过)与ZooKeeper(高版本Kafka自带ZooKeeper)。
ZooKeeper安装:
1. 下载,解压,配置:
wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz
tar -zxvf zookeeper-3.4..tar.gz
# zookeeper-3.4.12/conf中复制zoo_sample.cfg为zoo.cfg
cp zoo_sample.cfg zoo.cfg
# 修改zoo.cfg文件中下面两行(dataDir和dataLogDir后面所指的文件夹必须要存在如果不存在的话,在启动ZooKeeper服务端的时候会报错。这里是单机情况下的配置情况,如果是集群的话,要在clientPort下面添加服务器的ip。如server.1=192.168.180.132:2888:3888
server.2=192.168.180.133:2888:3888...等等。)
dataDir=/tmp/zookeeper
dataLogDir=/tmp/zookeeper/log
2. 配置环境变量(全用户永久更改方式):
修改/etc/profile文件,尾部添加:
ZOOKEEPER_INSTALL=/usr/local/zookeeper-3.4.
PATH=$PATH:$ZOOKEEPER_INSTALL/bin export ZOOKEEPER_INSTALL
export PATH
3. 启动检验:
# 进入zookeeper的bin目录下,启动
./zkServer.sh start
# 查看状态
./zkServer.sh status
# 启动zookeeper的客户端(本地不需要-server参数)
./zkCli.sh -server 192.168.229.128:
注:如拒绝连接,检查防火墙配置。
Kafka安装:
1. 下载,解压:
# curl 文件传输工具,-L 支持重定向链接,-O 把输出写到该文件中,保留远程文件的文件名
curl -L -O http://mirror.bit.edu.cn/apache/kafka/2.0.0/kafka_2.11-2.0.0.tgz
# -x 解压,-z 调用gzip执行,-v 显示细节,-f 指定文件
tar -xzvf kafka_2.-2.0..tgz
2. 配置单节点ZooKeeper(使用自带ZooKeeper时配置):
cd /usr/local/kafka_2.-2.0. # 进入kafka主目录
mkdir -p zk/data # 创建zookeeper数据存放目录
mkdir -p zk/logs # 创建zookeeper存放日志目录
cd config # 进入配置文件所在目录
mv zookeeper.properties zookeeper.properties.bak # 将原配置文件移位.bak备份文件
cat > zookeeper.properties << EOF
tickTime=
dataDir=/usr/local/kafka_2.-2.0./zk/data
dataLogDir=/usr/local/kafka_2.-2.0./zk/logs
clientPort=
EOF
3. 配置单结点Kafka:
cd /usr/local/kafka_2.-2.0. # 进入kafka主目录
mkdir logs # 创建logs目录用于存放日志
cd config # 进入配置文件所在目录
mv server.properties server.properties.bak # 将原配置文件移位.bak备份文件 cat > server.properties << EOF
broker.id=
listeners=PLAINTEXT://192.168.229.128:9092
num.network.threads=
num.io.threads=
socket.send.buffer.bytes=
socket.receive.buffer.bytes=
socket.request.max.bytes=
log.dirs=/usr/local/kafka_2.-2.0./logs
num.partitions=
num.recovery.threads.per.data.dir=
offsets.topic.replication.factor=
transaction.state.log.replication.factor=
transaction.state.log.min.isr=
log.retention.hours=
log.segment.bytes=
log.retention.check.interval.ms=
zookeeper.connect=192.168.229.128:
zookeeper.connection.timeout.ms=
group.initial.rebalance.delay.ms=
EOF
server.properties: 基本为原server.properties的默认配置,安装时主要修改;
broker.id--broker的id: 修改为任意想要的数值(和zookeeper中的id类似);
listeners--监听址址: 修改为kafka要监听的地址;
log.dirs--日志文件存放目录: 修改为要存放日志的目录;
zookeeper.connect--zookeeper监听地址: 修改为zookeeper的监听地址,如果是集群所有地址全写上用逗号(半角)隔开即可。
4. 启动和停止:
启动:
./zookeeper-server-start.sh -daemon ../config/zookeeper.properties # 启动zookeeper (-daemon在后台执行,后接配置文件)
./kafka-server-start.sh -daemon ../config/server.properties # 启动kafka
停止:
./zookeeper-server-stop.sh # 停止zookeeper
./kafka-server-stop.sh # 停止kafka,centos7上可能关不了用kill -9直接杀掉
Kafka基本命令
创建topic:
./kafka-topics.sh --create --zookeeper localhost: --replication-factor --partitions --topic test-kafka-topic
查看topic:
./kafka-topics.sh --list --zookeeper localhost:
生产者命令:
./kafka-console-producer.sh --broker-list 192.168.229.128: --topic test-kafka-topic # 更换成自己的IP
消费者命令:
./kafka-console-consumer.sh --bootstrap-server localhost: --topic test-kafka-topic --from-beginning # 更换成自己的IP,--from-beginning表示重头开始消费
命令效果:
生产:

消费:

Kafka 安装及入门的更多相关文章
- kafka安装以及入门
一.安装 下载最新版kafka,Apache Kafka,然后上传到Linux,我这里有三台机器,192.168.127.129,130,131 . 进入上传目录,解压到/usr/local目录下 - ...
- .net windows Kafka 安装与使用入门(入门笔记)
完整解决方案请参考: Setting Up and Running Apache Kafka on Windows OS 在环境搭建过程中遇到两个问题,在这里先列出来,以方便查询: 1. \Jav ...
- kafka安装和使用
kafka安装和启动 kafka的背景知识已经讲了很多了,让我们现在开始实践吧,假设你现在没有Kafka和ZooKeeper环境. Step 1: 下载代码 下载0.10.0.0版本并且解压它. &g ...
- 【3】Kafka安装及部署
一.环境准备 Linux操作系统 Java运行环境(1.6或以上) zookeeper 集群环境,可参照Zookeeper集群部署 . 服务器列表: 配置主机名映射. vi /etc/hosts ## ...
- Apache Hadoop2.x 边安装边入门
完整PDF版本:<Apache Hadoop2.x边安装边入门> 目录 第一部分:Linux环境安装 第一步.配置Vmware NAT网络 一. Vmware网络模式介绍 二. NAT模式 ...
- hadoop 之 kafka 安装与 flume -> kafka 整合
62-kafka 安装 : flume 整合 kafka 一.kafka 安装 1.下载 http://kafka.apache.org/downloads.html 2. 解压 tar -zxvf ...
- bower安装使用入门详情
bower安装使用入门详情 bower自定义安装:安装bower需要先安装node,npm,git全局安装bower,命令:npm install -g bower进入项目目录下,新建文件1.tx ...
- Kafka安装及部署
安装及部署 一.环境配置 操作系统:Cent OS 7 Kafka版本:0.9.0.0 Kafka官网下载:请点击 JDK版本:1.7.0_51 SSH Secure Shell版本:XShell 5 ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
随机推荐
- macbook 一些php相关操作
开启php: https://jingyan.baidu.com/article/67508eb434539f9cca1ce4da.html 配置多虚拟主机: https://jingyan.bai ...
- QLIKVIEW-SALESORDER\DELIVERYNOTICE\OUTSTOCK\INVOICE
//销售订单SALESORDER_TMP:NoConcatenateLOAD T_SAL_ORDER.LE_ID, [T_SAL_ORDER.LCY CODE], T_SAL_ORDER.SYSTEM ...
- Hadoop_课堂笔记1
1.课程目标 实践性 2.课下需要 在家搭建一个伪分布式 3.大数据概念和意义 08年Nature第一次正式提出大数据概念 常规的数据库:结构化的数据库 TB级的结构化数据管理就很困难,需要分布式 当 ...
- mysql查看变量
在MySQL客户端执行如下命令查看MySQL的数据存放位置: show global variables like "%datadir%"; 查看端口号 show global v ...
- Django的View(视图)-settings源码的解析-模板层-模板语法
FBV与CBV 视图函数并不只是指函数,也可以是类 FBV:基于函数的视图,类似面向函数式编程 CBV:基于类的视图,类似面向对象编程 研究解析render源码: render:返回html页面:并且 ...
- windows10系统激活方法
我使用的是第一种方法,很好用,企业版 https://blog.csdn.net/qq_39146974/article/details/82967054
- 学习4412开发板gdb和gdbserver的调试
因为有很多的小伙伴是从单片机转过来的,用惯了单片机上的JLINK调试程序,换到Linux上非常的不习惯.确实,如果能设置断点,单步调试,查看变量,那确实是太爽了,那么在我们的Linux可以做到吗,答案 ...
- vim模式及基础命令
VIM基本介绍vi和在修改vim命令是linux中强大的文本编辑器,由于linux系统一切皆文件,而配置一个服务就是在修改其配置文件的参数vim其实是vi的升级版yum install -y vim ...
- git 首次提交
git init# 将本地仓库与码云远程仓库进行关联 git remote add origin git的url地址 git add . git commit -m "描述" # ...
- java.lang.NoSuchMethodError: org.springframework.util.Assert.notNull(Ljava/lang/Object;Ljava/util/function/Supplier;)V
分析,jar包冲突,然后看pom.xml文件 原因在于jar包冲突,版本不兼容, 错误的代码: 可以看到有很多不同版本的重复的spring-test依赖 <dependency> < ...