《OSPF和IS-IS详解》一1.5 ARPANET内的路由选择
本节书摘来异步社区《OSPF和IS-IS详解》一书中的第1章,第1.5节,作者: 【美】Jeff Doyle 译者: 孙余强 责编: 傅道坤,更多章节内容可以访问云栖社区“异步社区”公众号查看。
1.5 ARPANET内的路由选择
OSPF和IS-IS详解
1983年,在ARPANET内,人们展开了把网络协议从NCP切换成TCP/IP的割接工作。当时,有两拨研究人员同时都在使用ARPANET,分别来自军方和非军方(大学或企业)。就人数而论,第二拨人要多得多,有很多大学生也在学着掌握或使用计算机网络,这反过来又对整个计算机行业产生了影响。此外,还有很多人出于非研究性的目的而使用计算机网络,比如,玩网络游戏。由于使用网络的用户群日渐庞大,美国国防部开始考虑网络的安全性问题,并将军用节点都迁移进了一个隔离的网络,同时把该网络命名为MILNET(军网)。但国防部仍想让军用节点访问到ARPANET内的节点,因此在两个网络之间部署了一台网关,来实施互连。这种网络隔离方式实际上只是两个网络分别由专人管控;每个网络内的用户根本就感觉不到有任何差别。把网络协议从NCP替换为TCP/IP之后,才使得MILNET与ARPANET“分家”成为可能。
与此同时,在美国和欧洲,其他各种各样的计算机网络也如雨后春笋般涌现,并开始“互联互通”。其中有一个网络最为重要,并对日后产生了深远影响,这就是由美国国家科学基金会(National Science Foundation,NSF)于1985年开始兴建的NSFNET。兴建该网络的初衷,只是要通过速率为56kbit/s的链路,来互连5个超级计算机(supercomputer)站点。该网络的链路分别于1988年和1990年被扩容至T1和T3(45Mbit/s)。NSFNET连接了美国各地的大学和公司;更重要的是,整个美国“涌现”出的各种地区性网络都可以自由地接入NSFNET。ARPANET内的低速链路、老掉牙的联网设备(IMP和TIP)以及限制性的访问策略,迫使大多数用户在20世纪80年代末“转投”其他网络。于是,DARPA决定让这一20岁高龄的网络“退役”。接入该网络的站点也纷纷连接进了地区性的网络或MILNET,到了1990年,ARPANET便彻底退出了历史舞台。
由上述简短的历史回顾可知,如今在用的网络互连技术几乎都起源自ARPANET。其中包括本书的重点:路由选择技术。20世纪80年代中期,市场上冒出了好几家销售路由器(商业版网关的另一种称谓)厂商,包括:3Com、ACC、Bridge、Cisco、 Proteon、Wellfleet等公司。这些厂商的路由器采用的路由算法都传承自ARPANET。有意思的是,BBN公司的技术人员曾试图说服公司去研发商用路由器,但其市场部门却认为商业用路由器没有任何发展前途。
ARPANET内运行的第一种路由协议由Will Crowther于1969年设计,此人是BBN公司IMP团队的元老级成员。与所有路由协议一样,该路由协议也是基于数学里的图论,采用了Richard Bellman和Lester Randolph Ford算法。Bellman-Ford算法奠定了路由协议里最重要的一类路由协议的基础,多年后,人们将此类路由协议称为距离矢量协议。Crowther设计出的那种路由协议是一种分布式自适应协议(distributed adaptive protocol),其设计理念为:通过调整链路的度量值,让路由器快速适应发生变化的网络特征(自适应);计算通往目的网络的最优路由时,多台路由器要“合力”完成(分布式)。
这种路由协议用延迟(delay)1作为度量路由优劣的标准。在每台IMP上,每隔128毫秒,路由协议进程就会统计一次各直连链路(接口)队列里的数据包的个数,并以此作为估算链路延迟的依据。为了不让空闲链路的度量值为0,上述统计结果还会与一个表示最低链路开销值的常量相加2。测量接口队列深度(即测量缓存在接口队列中被延迟发送的数据包的个数)的频率越高,运行在每台IMP上的路由协议进程就能更快地检测并修改发生变化的链路度量值。就理论而言,在运行这种路由协议的网络中,发往特定目的网络地址的流量应该由所有流量出站方向的链路“平摊”。
运行在IMP上的路由协议进程只要执行了一次延迟统计任务,就会更新一次路由表,然后向邻居IMP通告其路由表。收到路由表之后,邻居IMP会评估(从本机)通往通告(路由表的)IMP的延迟值,将评估结果与所收路由表中的信息相加,用相加的结果去更新本机路由表中通过通告(路由表的)IMP所能访问到的目的网络的信息。邻居IMP在更新完本机路由表中的信息之后,会继续向自己的邻居IMP通告路由表。当时,上述分布式路由计算的特点,要归因于网络内的IMP之间反复的通告路由表,并据此来更新自己的路由表。
这一原始的路由协议在ARPANET运行的头10年里也没出过什么大纰漏。在网络内流量负载很低的情况下,该路由协议做出路由决策的基本方法是:把之前提到的常量与评估而得的延迟值相加。当流量负载攀升到中等程度时,在网络内的个别区域就有可能会出现拥塞状况。在这样的区域内测量出的接口队列深度,会成为让流量改道远离拥塞的某种因素。
随着ARPANET的规模越来越大,加之其内部的流量负载越来越高,这种路由协议所表现出来的问题也就越来越多。某些问题事关测算路由度量值的方式,如下所列。
- 统计出的缓存在IMP接口队列里的数据包的个数是瞬时测量值。在流量很高的网络内,(网络设备接口的)队列深度可谓是瞬息万变,这将会导致路由度量值强烈波动,从而迫使路由表里的路由发生翻动。
- 统计缓存在IMP接口队列里的数据包的个数时,并未考虑不同链路之间可用带宽方面的差异。与低速链路(接口)相比,即便高速链路(接口)所缓存的数据包更多,前者所缓存的数据包的发送延迟也会高于后者。
- IMP接口队列里所缓存的数据包的个数(Queuing delay)并不是影响网络链路整体延迟的唯一因素。(网络链路所要转发的)数据包的大小(长度)、IMP处理数据包的时间以及其他因素都会影响到网络链路的延迟。
此外,与距离矢量算法本身有关的各种问题也开始逐渐显现。
- 随着网络内网络节点数的不断增多,网络节点间交换路由表所产生的网络控制流量也会消耗掉链路的不少可用带宽。
- 测量链路延迟值和更新路由表的频率,外加测量的结果为队列的“瞬时深度”,不但有可能会限制网络(设备)对拥塞真正出现时的快速反应,而且还会导致网络(设备)在队列深度发生变化时反应“过激”。
- 分布式路由计算收敛缓慢的天性(也可以说是最大的缺点,即路由传播方式是“好事难出门,坏事传千里[bad news travels fast but good news travels slow]”),会使得距离矢量路由协议易遭受持续性路由环路和错误的影响(第2章会对距离矢量路由协议这一典型的缺陷加以讨论)。
1979年,BBN公司在ARPANET内部署了一种新型路由协议,由John McQuillan、Ira Richer和Eric Rosen共同开发3。比之原始的路由协议,这一新型路由协议有三处重大改变。
- 尽管这一新型路由协议仍旧使用根据延迟值测算出的自适应路由度量值,但在精度方面有所提高,在瞬时程度上则有所下降。
- 路由信息更新的频率和路由更新数据包的长度都急剧下降,所占用的可用链路带宽也就更低。
- 路由算法从分布式路由计算(根据邻居IMP通告的路由数据库进行计算),转变为本机路由计算(根据邻居IMP通告的路由度量值进行计算)。
路由度量值的测算方法经过改进之后,大大降低了路由翻动的几率。IMP会把每个数据包的接收时间“烙在”数据包上(接收数据包时,记录接收时间),而不再对缓存在接口队列里数据包的个数进行统计了。在发送数据包的第一位时,IMP还会把发送时间“烙在”数据包上(发送数据包时,记录发送时间)。收到(目的节点)对该数据包的确认消息之后,IMP会用确认消息的接收时间减去数据包的发送时间。然后,IMP再用一个表示数据包所“走”链路的传播延迟的常量(称为偏差[bias]),与另外一个表示数据包传输延迟的变量(其值要视数据包的长度和线路的带宽而定),跟之前提到的接收时间与发送时间之差,进行三者相加4。上述计算的结果,肯定会更接近于数据包所“走”链路的实际延迟。IMP会针对其附接的每条链路,每10秒钟取一次测量而得的平均延迟值,这一平均值会成为相应链路的度量值。取链路的平均延迟值,就能够避免取瞬时性测量值时所引发的各种问题。
第二处改变——降低路由更新的频率——是通过设置一个始于64毫秒的阈值来实现的。计算出10秒之内的平均延迟值之后,IMP会将该值与上一次(上一个10秒)的计算结果进行比较。若两值之差不超过阈值,IMP便不发送路由更新,但阈值会递减12.8毫秒,然后用于下一次路由计算。若两值之差超过了阈值,路由更新会照常发出,阈值则会被重置为64毫秒。这一阈值衰减机制,可确保IMP在度量值变化幅度较大时,尽快地将路由更新通告出去,若度量值变化甚微,则可以放慢通告路由更新的速度。若度量值未发生改变,则阈值将会在50秒(64/12.8=5;5×10=50秒)内衰减为0,这会促使IMP通告路由更新。拜这一新路由算法所赐,路由更新的频率以及与此相关的链路带宽消耗,都将会直线下降。
新路由协议路由更新消息中所包含的内容同样非常重要。运行新路由协议的每台IMP不再通告整张路由表,而是只向自己的邻居发送本机链路的度量值;路由更新将传遍整个网络(协议设计者将这一机制称为“泛洪”[flooding]),每台IMP都会在数据库中保存路由更新的一份拷贝。这样的好处有两点:路由更新数据包非常短——均长22字节(176位)——这便进一步降低了链路带宽的消耗;由于路由更新消息会迅速泛洪(100毫秒以内)至所有IMP,因此IMP能够更快地“感知”到网络中的发生变化。(在路由更新消息中)设立了序列号、寿命及确认序号(sequence number,age,acknowledgment)等字段,以确保泛洪出去的路由度量值的精确性与可靠性5。
新路由协议的第三处重大改变是,放弃使用Bellman-Ford算法,采用图论专家Edsger Dijkstra发明的算法来执行路由计算(这也是本书的重点)。每台IMP会根据自己的度量值数据库(数据库的内容要通过泛洪机制来“收集”),执行本机路由计算,以求计算出通往其他所有IMP的最短路径。该机制可基本杜绝路由环路,而路由环路问题已经“折磨”了运行原始路由协议的ARPANET很长时间。McQuillan、Richer和Rosen将他们三人根据Dijkstra算法制定出的路由算法,称为最短路径优先(SPF)算法。这就是第一种广泛应用于分组(包)交换网络的链路状态路由协议。
这“第二代”路由协议在ARPANET内整整运行了8年之久,直到再次出现重大故障。该故障要归因于此协议在路由计算方面的缺陷,导致其无法适应网络规模的持续增长。不过,“过错”并不在SPF算法;出问题的只是自适应度量值计算机制。
“第二代”路由协议要根据三个参数,来计算路由的度量值,这三个参数是:(数据包的)排队延迟(其值为收包时间与发包时间相减)、链路传播延迟(这是一个常量[固定值])以及(数据包在链路上的)传输延迟(其值取决于所要发送的数据包的大小和链路速度)。若链路负载很低,排队延迟可忽略不计。若链路负载不高不低,排队延迟不仅会影响到路由度量值的计算,而且还会导致流量在链路之间合理的切换。然而,若链路负载极高,排队延迟势必能“左右”路由度量值的计算。此时,排队延迟可能会引发路由翻动。
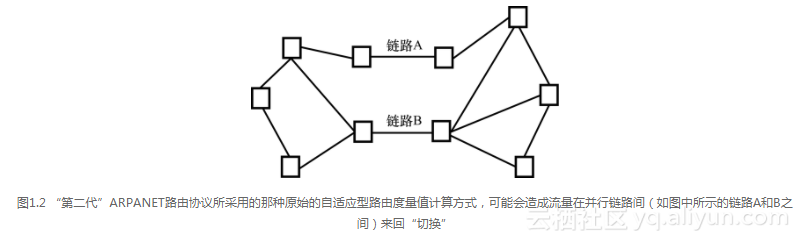
以图1.2所示的网络为例。链路A和B分别用来连接网络的东、西二区。东区和西区之间要想交换流量,链路A、B为必经之路。若大部分流量都由链路A承载,则该链路的排队延迟值定会非常高,这一高排队延迟值也将被通告给所有其他节点。其他节点在执行本机SFP计算时,会或多或少的同时进行,因此可能会得出相同的“结论”:链路A已经过载,而链路B负载较轻。于是,所有流量都将“改道”,由链路B来承载,这迫使链路B的延迟大增;在下一次(延迟值)测量周期内,链路B的高延迟情况将会被“散布”出去,造成所有IMP(路由器)让流量继续“改道”,则链路A将承载所有流量。这样一来,链路A势必会再次过载,流量又会“改走”链路B。上述情形将周而复始,流量在链路A、B间的“切换”也会永不停歇。每次发生流量“切换”时,相关链路的负载状况会导致相应路由的度量值发生巨大改变。也就是说,一旦发生了流量“切换”现象,触发流量切换的相关路由度量值就会变得毫无用处(因为流量将会“改走”另一条链路)。
为了解决上述问题,1978年,由BBN公司Atul Khanna、John Zinky和Frederick Serr设计的新路由度量值算法开始在ARPANET内部署6。这一新算法仍属于自适应型,沿用了间隔时间为10秒的平均延迟测量方法。当链路负载为中等偏下时,新旧两种路由度量值算法的效果差别不大。只有当链路负载较高时,才能看出新算法在功能性上的改进。在新算法中,路由的度量值不再只是链路延迟值,延迟成为影响度量值的因素之一。此外,还限定了度量值的变化范围。上述举措意在将相同介质网络中其他诸元相等的两条路径间的度量值差距限制在两跳之内。该算法的精髓是启用了一个与链路利用率挂钩的函数,当链路利用率较低时,该算法在运作时似乎只考虑链路延迟,可链路利用率一旦增高,路由的度量值将会根据链路的容量来计算。
虽然ARPANET所使用的路由度量值算法发生了改变,但只对路由协议的SPF算法稍作改动,具体的运作方式为:控制流量,令其慢慢“撤离”过载的链路,而不是突然“切换”,这便大大降低了路由频繁“震荡”(流量在不同链路间频繁切换)的可能性。本书不会对这一路由度量值算法做过多纠缠,前文已对自适应路由算法进行了总结:分布式自适应路由协议在运作过程中涉及的东西实在太过复杂。因此,在绝大多数的新型包交换网络中,为追求某些特殊功能(比如,流量工程)而部署的(路由协议的)自适应路由算法都是集中式而非分布式了。如今在用的链路状态路由协议也吸取了早期ARPANET的经验,改用固定的路由度量值,弃用了自适应型路由度量值。
有互联网之父吗
当同胞们把乔治·华盛顿封为美国“国父”时,作者总有那么一点不以为然。作为约翰·亚当斯(John Adams,美国第一任副总统,第二任总统)的忠实拥趸,在作者看来,无论是革命成就,还是后来在外交方面的贡献,约翰·亚当斯都配得上“国父”这一称号(当然,必须承认的是,他并不算是一位好总统)。其他人则可能会把“国父”的头衔安在富兰克林或杰斐逊的头上。把以上几位都视为美国的“开国元勋”,似乎更公道一点。“开国元勋”的意思是:美国的建立靠的是一帮人,而不是靠哪一个人。
互联网的诞生也与此相似。估计大多数人都把Vint Cerf称为“互联网之父”,但是J. C. R. Licklider、Larry Roberts、Len Kleinrock、Bob Kahn、Jon Postel以及其他前辈也配得上“互联网之父”这个头衔。夸大某一个人的贡献,抹杀其余人的功绩,是非常不公平的。互联网并不是只有一个父亲,而是有一大群父亲,外加几个母亲。
在本章陈述的简史中,还有诸多Internet奠基人未曾提及,他们中有很多都已离我们而去。为了撰写这部简史,作者查阅了许多参考资料,但最有用的一本参考书是Where Wizards Stay Up Late: The Origins of the Internet,作者为Katie Hafner 和Matthew Lyon7。要是读者想知道更多与互联网诞生有关的内容,以及有哪些人为此立下过汗马功劳,作者强烈推荐上面这本兼知识性与趣味性于一体的书籍。
《OSPF和IS-IS详解》一1.5 ARPANET内的路由选择的更多相关文章
- linux awk命令详解,使用system来内嵌系统命令, awk合并两列
linux awk命令详解 简介 awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大.简单来说awk就是把文件逐行的读入,以空格为默认分 ...
- OSPF区域间+NAT详解
- NAT+PAT+OSPF+设备互连地址详解
- 详解SQL Server连接(内连接、外连接、交叉连接)
在查询多个表时,我们经常会用“连接查询”.连接是关系数据库模型的主要特点,也是它区别于其它类型数据库管理系统的一个标志. 什么是连接查询呢? 概念:根据两个表或多个表的列之间的关系,从这些表中查询数据 ...
- MSSQL 详解SQL Server连接(内连接、外连接、交叉连接)
在查询多个表时,我们经常会用“连接查询”.连接是关系数据库模型的主要特点,也是它区别于其它类型数据库管理系统的一个标志. 什么是连接查询呢? 概念:根据两个表或多个表的列之间的关系,从这些表中查询数据 ...
- 详解如何挑战4秒内百万级数据导入SQL Server(转)
对于大数据量的导入,是DBA们经常会碰到的问题,在这里我们讨论的是SQL Server环境下百万级数据量的导入,希望对大家有所帮助.51CTO编辑向您推荐<SQL Server入门到精通&g ...
- 《OSPF和IS-IS详解》
<OSPF和IS-IS详解> 基本信息 作者: (美)Jeff Doyle 译者: 孙余强 出版社:人民邮电出版社 ISBN:9787115347886 上架时间:2014-4-25 出版 ...
- Android系统目录结构详解
Android系统基于linux内核.JAVA应用,算是一个小巧精致的系统.虽是开源,但不像Linux一般庞大,娇小可亲,于是国内厂商纷纷开发出自己基于Android的操作系统.在此呼吁各大厂商眼光放 ...
- nginx入门与实战 安装 启动 配置nginx Nginx状态信息(status)配置 正向代理 反向代理 nginx语法之location详解
nginx入门与实战 网站服务 想必我们大多数人都是通过访问网站而开始接触互联网的吧.我们平时访问的网站服务 就是 Web 网络服务,一般是指允许用户通过浏览器访问到互联网中各种资源的服务. Web ...
随机推荐
- 1054 The Dominant Color (20分)(水)
Behind the scenes in the computer's memory, color is always talked about as a series of 24 bits of i ...
- 理解 Hanoi 汉诺塔非递归算法
汉诺塔介绍: 汉诺塔(港台:河内塔)是根据一个传说形成的数学问题: 最早发明这个问题的人是法国数学家爱德华·卢卡斯. 传说越南河内某间寺院有三根银棒,上串 64 个金盘.寺院里的僧侣依照一个古老的预言 ...
- 页面静态化--Thymeleaf
1.Thymeleaf简介 官方网站:https://www.thymeleaf.org/index.html Thymeleaf是用来开发Web和独立环境项目的现代服务器端Java模板引擎. Thy ...
- 在 Array.filter 中正确使用 Async
本文译自How to use async functions with Array.filter in Javascript - Tamás Sallai. 0. 如何仅保留满足异步条件的元素 在第一 ...
- NS网络仿真,小白起步版,模拟仿真之间注意的事项
FTP是基于TCP的,所以FTP应用不可以绑定UDP发送代理 FTP和CBR属于应用流,他们用来绑定TCP和UDP发送代理 TCP用于发送代理时,接收代理为TCPSink,可以绑定FTP应用.CBR流 ...
- js骚操作骂人不带脏
前言 很多小伙伴们觉得javaScript很简单,下面的这行 javaScript代码可能会让你怀疑人生. (!(~+[])+{})[--[~+""][+[]]*[~+[]] + ...
- 34.4 对象流 ObjectOutputStream ObjectInputStream
* 对象操作流:可以用于读写任意类型的对象 * ObjectOutputStream * writeObject * ObjectOutputStream(OutputStream out) * Ob ...
- python3(十四) filter
# 和map()类似,filter()也接收一个函数和一个序列. # 和map()不同的是,filter()把传入的函数依次作用于每个元素, # 然后根据返回值是True还是False决定保留还是丢弃 ...
- CTE(With As)
WITH tabdate(dt) AS ( FROM dual UNION ALL FROM tabdate WHERE dt ) SELECT * FROM TabDate ; 一.With Tab ...
- Sprint 5 summary: UI 界面更新,Azure端部署和用户反馈分析 12/28/2015
本次sprint主要完成的任务有对手机APP的UI界面的更新,同时对Azure客户端的部署进行了相应的学习和有关的程序设计.同时对于ALPHA release的用户反馈做出相应的分析以确定接下来工作的 ...