Hadoop HA- hadoop集群部署
前期部署,至少准备3台服务器(可以是虚拟机)
1、linux系统环境准备
ip地址配置
hostname配置
hosts映射配置
关闭防火墙 service iptables stop ,也可以设置防火墙不开机自启动 chkconfig iptables off
init启动级别修改
2.java环境的配置
上传jdk,解压,修改/etc/profile
3.zookeeper集群的部署,安装zookeeper,环境变量,发送zookeeper文件,profile文件给其他服务器并刷新他,都创建myid文件,开启3台zookeeper: zkServer.sh start ,出现错误可以检查日志文件
4.解压hadoop安装包,配置PATH环境
5.做免密钥登录SSH
node1到node1-
node2到node1-
注意:namenode之间一定要做免密钥SSH
6.修改hadoop配置文件
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1/</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hdpt</value>
</property> <!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>server01-hosetname:,server02-hostname:,server03-hostname:</value> //server-hostname这里写你实际的服务器主机名
</property>
</configuration>
hdfs-site.xml
configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>server01-hostname:</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>server01-hostname:</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>server02-hostname:</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>server02-hostname:</value>
</property>
<!-- 指定NameNode的edits元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hostname05:8485;hostname06:8485;hostname07:8485/ns1</value> //hostname为3台journalnode服务器的主机名
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/app/hadoop-2.4./journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value> //里面放的值为SSH放密钥地址在你所在的用户家目录下的.ssh文件夹内,root用户在/root/.ssh/ ,加密方式不同可能不是id_rsa,自己选择即可类似的文件即可
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value></value>
</property>
/configuration>
7.同步配置文件
8.启动3台journalnode服务器: hadoop-daemon.sh start journalnode (也可以先不启动)
9.格式化NN(namenode01): hdfs namenode -format ,并启动hdfs: start-dfs.sh 。
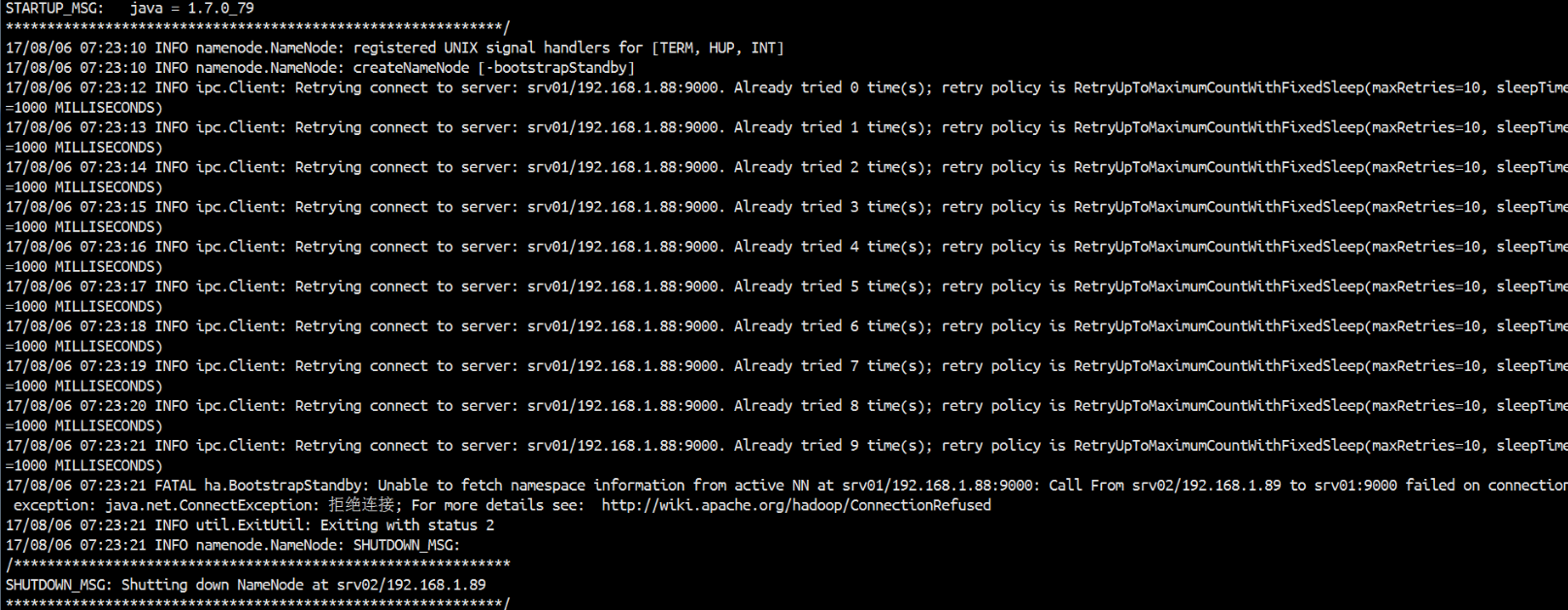
10.同步其他没有格式化的NN(namenode)上执行node2 hdfs namenode -bootstrapStandby
11.开启3台zookeeper,如果开启了忽略。
12.格式化zk, 在一台NN上执行 hdfs zkfc -formatZK
13启动集群 start-dfs.sh
3启动yarn start-yarn.sh 或者 start-all.sh //同时把集群和yarn开启
jps检查namenode是否正常开启,没有的话需要手动单点启动: hadoop-daemon.sh start namenode
报错解决:这样一个情况,在设置了Hadoop的HA模式。每次开启zookeeper之后再输入 start-all.sh 将hdfs 和yarn都开启来。一切启动正常,但是namenode的进程却在很短的时间内就消失了,必须通过hadoop-daemon.sh start namenode 手动才能重新上线namenode。
进检查namenode的日志文件,出现下面的警告:
WARN org.apache.hadoop.hdfs.server.namenode.FSEditLog: Unable to determine input streams from QJM to
jps查看进程,namenode进程已经消失。
肯定NameNode不能正常运行,不是配置错了,而是不能连接上JournalNode、
查看JournalNode的日志没有问题,那么问题就在JournalNode的客户端NameNode。
来分析上句的日志:
NameNode作为JournalNode的客户端发起连接请求,但是失败了,然后NameNode又向其他节点依次发起了请求都失败了,直至到了最大重试次数。
通过实验知道,先启动JournalNode或者再次启动NameNode就可以了,说明JournalNode并没有准备好,而NameNode已经用完了所有重试次数。
三、解决办法
修改core-site.xml中的ipc参数
<property>
<name>ipc.client.connect.max.retries</name>
<value>100</value>
<description>Indicates the number of retries a client will make to establish
a server connection.
</description>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
<description>Indicates the number of milliseconds a client will wait for
before retrying to establish a server connection.
</description>
</property>
Namenode向JournalNode发起的ipc连接请求的重试间隔时间和重试次数,我的虚拟机集群实验大约需要2分钟,NameNode即可连接上JournalNode。连接后很稳定。
注意:仅对于这种由于服务没有启动完成造成连接超时的问题,都可以调整core-site.xml中的ipc参数来解决。如果目标服务本身没有启动成功,这边调整ipc参数是无效的。
Hadoop HA- hadoop集群部署的更多相关文章
- Hadoop(HA)分布式集群部署
Hadoop(HA)分布式集群部署和单节点namenode部署其实一样,只是配置文件的不同罢了. 这篇就讲解hadoop双namenode的部署,实现高可用. 系统环境: OS: CentOS 6.8 ...
- 使用kubeadm进行单master(single master)和高可用(HA)kubernetes集群部署
kubeadm部署k8s 使用kubeadm进行k8s的部署主要分为以下几个步骤: 环境预装: 主要安装docker.kubeadm等相关工具. 集群部署: 集群部署分为single master(单 ...
- 【Hadoop】2、Hadoop高可用集群部署
1.服务器设置 集群规划 Namenode-Hadoop管理节点 10.25.24.92 10.25.24.93 Datanode-Hadoop数据存储节点 10.25.24.89 10.25.24. ...
- hadoop HA分布式集群搭建
概述 hadoop2中NameNode可以有多个(目前只支持2个).每一个都有相同的职能.一个是active状态的,一个是standby状态的.当集群运行时,只有active状态的NameNode是正 ...
- 1、hadoop HA分布式集群搭建
概述 hadoop2中NameNode可以有多个(目前只支持2个).每一个都有相同的职能.一个是active状态的,一个是standby状态的.当集群运行时,只有active状态的NameNode是正 ...
- Hadoop及Zookeeper+HBase完全分布式集群部署
Hadoop及HBase集群部署 一. 集群环境 系统版本 虚拟机:内存 16G CPU 双核心 系统: CentOS-7 64位 系统下载地址: http://124.202.164.6/files ...
- 大数据Hadoop的HA高可用架构集群部署
1 概述 在Hadoop 2.0.0之前,一个Hadoop集群只有一个NameNode,那么NameNode就会存在单点故障的问题,幸运的是Hadoop 2.0.0之后解决了这个问题,即支持N ...
- Hadoop系列之(二):Hadoop集群部署
1. Hadoop集群介绍 Hadoop集群部署,就是以Cluster mode方式进行部署. Hadoop的节点构成如下: HDFS daemon: NameNode, SecondaryName ...
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
- Hadoop记录-Apache hadoop+spark集群部署
Hadoop+Spark集群部署指南 (多节点文件分发.集群操作建议salt/ansible) 1.集群规划节点名称 主机名 IP地址 操作系统Master centos1 192.168.0.1 C ...
随机推荐
- Win7如何自定义鼠标右键菜单 添加在此处打开CMD窗口
将下面文件保存为"右键添加在此处打开CMD窗口.reg"双击导入运行即可 Windows Registry Editor Version 5.00 [HKEY_CLASSES_RO ...
- vue 父子通信过程
1.概述 每个 Vue 实例都实现了事件接口,即: 使用 $on(eventName) 监听事件 使用 $emit(eventName, optionalPayload) 触发事件 2.示例一(未传递 ...
- Chrome 插件 CrxMouse 去除后门优化版
说明 CrxMouse 是一款挺不错的 Chrome 插件.仅仅是据说这个插件会在后台偷偷的上传用户的浏览数据,无论上传的内容是不是涉及隐私数据,总让人认为不放心,可是因为插件本身功能还是挺好用的,所 ...
- mysql主从只同步部分库或表
同步部分数据有两个思路,1.master只发送需要的:2.slave只接收想要的. master端: binlog-do-db 二进制日志记录的数据库(多数据库用逗号,隔开)binlog-i ...
- android位置布局
fill_parent 设置一个构件的布局为fill_parent将强制性地使构件扩展,以填充布局单元内尽可能多的空间.这跟Windows控件的dockstyle属性大体一致.设置一个顶部布局或控件为 ...
- (九)jQuery中的动画(载)
原文链接:http://blog.csdn.net/zfy865628361/article/details/50358367 首先,用jQuery做动画效果要求在标准模式下,否则可能会引起动画抖动. ...
- iPhone X
iPhone X前置深度摄像头带来了Animoji和face ID,同时也将3D Face Tracking的接口开放给了开发者.有幸去Cupertino苹果总部参加了iPhone X的封闭开发,本文 ...
- linux - console/terminal/virtual console/pseudo terminal ...
http://en.wikipedia.org/wiki/System_console System console Knoppix system console showing the boot p ...
- 数据挖掘之pandas
sdata={'语文':89,'数学':96,'音乐':39,'英语':78,'化学':88} #字典向Series转化 @@ >>> studata=Series(sdata) & ...
- VIM中保存编辑的只读文件
如何在VIM中保存编辑的只读文件 你是否会和我一样经常碰到这样的情景:在VIM中编辑了一个系统配置文件,当需要保存时才发现当前的用户对该文件没有写入的权限.如果已 经做了很多修改,放弃保存的确很懊恼, ...