MySQL表的碎片整理和空间回收小结
MySQL表碎片化(Table Fragmentation)的原因
关于MySQL中表碎片化(Table Fragmentation)产生的原因,简单总结一下,MySQL Engine不同,碎片化的原因可能也有所差别。这里没有深入理解、分析这些差别。此文仅以InnoDB引擎为主。总结如有不足或错误的地方,敬请指出。
InnoDB表的数据存储在页(page)中,每个页可以存放多条记录。这些记录以树形结构组织,这颗树称为B+树索引。表中数据和辅助索引都是使用B+树结构。维护表中所有数据的这颗B+树索引称为聚簇索引,通过主键来组织的。聚簇索引的叶子节点包含行中所有字段的值,辅助索引的叶子节点包含索引列和主键列。
在InnoDB中,删除一些行,这些行只是被标记为“已删除”,而不是真的从索引中物理删除了,因而空间也没有真的被释放回收。InnoDB的Purge线程会异步的来清理这些没用的索引键和行。但是依然没有把这些释放出来的空间还给操作系统重新使用,因而会导致页面中存在很多空洞。如果表结构中包含动态长度字段,那么这些空洞甚至可能不能被InnoDB重新用来存新的行,因为空间空间长度不足。关于这个你可以参考博客Overview of fragmented MySQL InnoDB tables。
另外,删除数据就会导致页(page)中出现空白空间,大量随机的DELETE操作,必然会在数据文件中造成不连续的空白空间。而当插入数据时,这些空白空间则会被利用起来.于是造成了数据的存储位置不连续。物理存储顺序与逻辑上的排序顺序不同,这种就是数据碎片。
对于大量的UPDATE,也会产生文件碎片化 , Innodb的最小物理存储分配单位是页(page),而UPDATE也可能导致页分裂(page split),频繁的页分裂,页会变得稀疏,并且被不规则的填充,所以最终数据会有碎片。
First at all you must understand that Mysql tables get fragmented when a row is updated, so it's a normal situation. When a table is created, lets say imported using a dump with data, all rows are stored with no fragmentation in many fixed size pages. When you update a variable length row, the page containing this row is divided in two or more pages to store the changes, and these new two (or more) pages contains blank spaces filling the unused space.
表的数据存储也可能碎片化。然而数据存储的碎片化比索引更加复杂。有三种类型的数据碎片化。##下面部分内容摘自【高性能MySQL】##
行碎片(Row fragmentation)
这种碎片指的是数据行被存储为多个地方的多个片段。即使查询只从索引中访问一行记录。行碎片也会导致性能下降。
行间碎片(Intra-row fragmentaion)
行间碎片是指逻辑上顺序的页,或者行在磁盘上不是顺序存储的。行间碎片对诸如全表扫描和聚簇索引扫描之类的操作有很大的影响,因为这些操作原本能够从磁盘上顺序存储的数据中获益。
剩余空间碎片(Free space fragmentation)
剩余空间碎片是指数据页中有大量的空余空间。这会导致服务器读取大量不需要的数据。从而造成浪费。
对于MyISAM表,这三类碎片化都有可能发生。但InnoDB不会出现短小的行碎片;InnoDB会移动短小的行并写到一个片段中。InnoDb会移动短小的行并重写到一个片段中。
官方文档14.15.4 Defragmenting a Table关于降低表的碎片化介绍如下(非常简洁,MySQL官方文档往往简洁,信息量大,但是没有详细介绍):
Random insertions into or deletions from a secondary index can cause the index to become fragmented. Fragmentation means that the physical ordering of the index pages on the disk is not close to the index ordering of the records on the pages, or that there are many unused pages in the 64-page blocks that were allocated to the index.
One symptom of fragmentation is that a table takes more space than it “should” take. How much that is exactly, is difficult to determine. All InnoDB data and indexes are stored in B-trees, and their fill factor may vary from 50% to 100%.
从二级索引中随机插入或删除可能会导致索引碎片化。碎片意味着磁盘上索引页的物理排序不接近页面上记录的索引排序,或者64页块中有许多未使用的页面被分配给索引。
碎片化的一个症状是表格占用的空间比“应该”占用的空间多。多少确切地说,很难确定。所有 InnoDB 数据和索引都存储在 B-trees 中,它们的 fill factor 可能在50%到100%之间变化。碎片的另一个症状是像这样的表扫描需要比“应该”花费更多的时间
MySQL中如何找出碎片化严重的表
关于MySQL中表碎片化,那么如何找出MySQL中的碎片,一般有两种方法。
方法1:使用show table status from xxxx like 'xxxx' \G;
第一个xxx:表所在的数据库名称,第二个xxx:要查询的表名。这个方法其实不太实用。例如,只能单个表的查询碎片化情况(难道一个数据库要一个个表去试?),不能查询某个数据库或整个实例下所有表的碎片化等等。这里仅仅作为一个参考方法而已。
mysql> create table frag_tab_myisam
-> (
-> id int,
-> name varchar(63)
-> ) engine=MyISAM;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into frag_tab_myisam
-> values(1, 'it is only test row 1');
Query OK, 1 row affected (0.00 sec)
mysql>
mysql> insert into frag_tab_myisam
-> values(2, 'it is only test row 2');
Query OK, 1 row affected (0.00 sec)
mysql>
mysql>
mysql> insert into frag_tab_myisam
-> values(3, 'it is only test row 3');
Query OK, 1 row affected (0.00 sec)
mysql>
mysql> insert into frag_tab_myisam
-> values(4, 'it is only test row 4');
Query OK, 1 row affected (0.00 sec)
mysql>
mysql> show table status from kkk like 'frag_tab_myisam' \G;
如下截图所示,如果没有DML操作,Data_free的大小是0
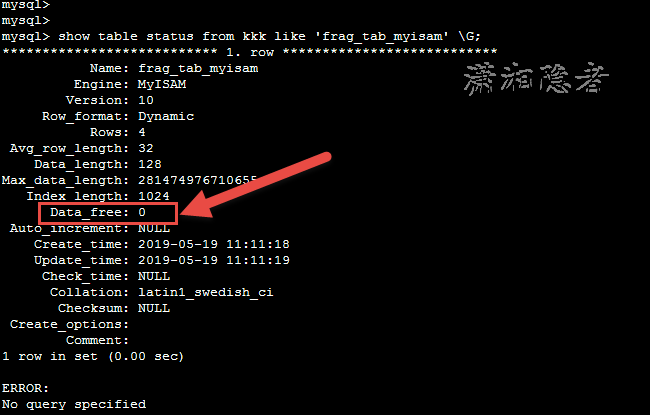
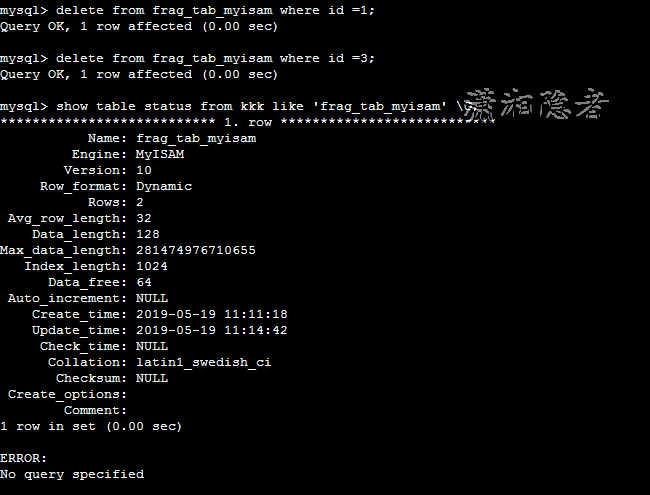
然后我们在数据库上删除掉2条记录,如下所示,Data_free的大小为64KB大小了。
mysql> delete from frag_tab_myisam where id =1;
Query OK, 1 row affected (0.00 sec)
mysql> delete from frag_tab_myisam where id =3;
Query OK, 1 row affected (0.00 sec)
方法2:查询information_schema.TABLES获取表的碎片化信息。
如下所示,这个是我整理的一个查询表碎片化的经典脚本。你可以在上面做很多衍生:例如,查询某个数据库的表碎片化情况。或者空闲空间超过50M大小的表。这个可以根据自己的需求设定查询条件。在此略过。
SELECT CONCAT(table_schema, '.', table_name) AS TABLE_NAME
,engine AS TABLE_ENGINE
,table_type AS TABLE_TYPE
,table_rows AS TABLE_ROWS
,CONCAT(ROUND(data_length / ( 1024 * 1024), 2), 'M') AS TB_DATA_SIZE
,CONCAT(ROUND(index_length / ( 1024 * 1024), 2), 'M') AS TB_IDX_SIZE
,CONCAT(ROUND((data_length + index_length )
/ ( 1024 * 1024 ), 2), 'M') AS TOTAL_SIZE
,CASE WHEN data_length =0 THEN 0
ELSE ROUND(index_length / data_length, 2) END AS TB_INDX_RATE
,CONCAT(ROUND( data_free / 1024 / 1024,2), 'MB') AS TB_DATA_FREE
,CASE WHEN (data_length + index_length) = 0 THEN 0
ELSE ROUND(data_free/(data_length + index_length),2)
END AS TB_FRAG_RATE
FROM information_schema.TABLES
ORDER BY data_free DESC;
SELECT CONCAT(table_schema, '.', table_name) AS TABLE_NAME
,engine AS TABLE_ENGINE
,table_type AS TABLE_TYPE
,table_rows AS TABLE_ROWS
,CONCAT(ROUND(data_length / ( 1024 * 1024), 2), 'M') AS TB_DATA_SIZE
,CONCAT(ROUND(index_length / ( 1024 * 1024), 2), 'M') AS TB_IDX_SIZE
,CONCAT(ROUND((data_length + index_length )
/ ( 1024 * 1024 ), 2), 'M') AS TOTAL_SIZE
,CASE WHEN data_length =0 THEN 0
ELSE ROUND(index_length / data_length, 2) END AS TB_INDX_RATE
,CONCAT(ROUND( data_free / 1024 / 1024,2), 'MB') AS TB_DATA_FREE
,CASE WHEN (data_length + index_length) = 0 THEN 0
ELSE ROUND(data_free/(data_length + index_length),2)
END AS TB_FRAG_RATE
FROM information_schema.TABLES
WHERE ROUND(DATA_FREE/1024/1024,2) >=50
ORDER BY data_free DESC;
SELECT TABLE_SCHEMA
,TABLE_NAME
,ENGINE
,ROUND(((DATA_LENGTH + INDEX_LENGTH) / 1024 / 1024), 2) AS SIZE_MB
,ROUND(DATA_FREE/1024/1024,2) AS FREE_SIZ_MB
FROM information_schema.TABLES
WHERE DATA_FREE >=10*1024*1024
ORDER BY FREE_SIZ_MB DESC;
MySQL中如何减低表的碎片
在MySQL中,可以使用OPTIMIZE TABLE、ALTER TABLE XXXX ENGINE = INNODB这两种方法降低碎片,关于这两者的简单介绍如下:
OPTIMIZE TABLE
OPTIMIZE TABLE 会重组表和索引的物理存储,减少对存储空间使用和提升访问表时的IO效率。对每个表所做的确切更改取决于该表使用的存储引擎
OPTIMIZE TABLE的支持表类型:INNODB,MYISAM, ARCHIVE,NDB;它会重组表数据和索引的物理页,对于减少所占空间和在访问表时优化IO有效果。OPTIMIZE 操作会暂时锁住表,而且数据量越大,耗费的时间也越长。
OPTIMIZE TABLE后,表的变化跟存储引擎有关。
对于MyISAM, PTIMIZE TABLE 的工作原理如下:
· 如果表有已删除的行或拆分行(split rows),修复该表。
· 如果未对索引页面进行排序,对它们进行排序。
· 如果表的统计信息不是最新的(并且无法通过对索引进行排序来完成修复),更新它们。
英文原文如下:
For MyISAM tables, OPTIMIZE TABLE works as follows:
1. If the table has deleted or split rows, repair the table.
2. If the index pages are not sorted, sort them.
3. If the table's statistics are not up to date (and the repair could not be accomplished by sorting the index), update them.
对于InnoDB而言,PTIMIZE TABLE 的工作原理如下
对于InnoDB表, OPTIMIZE TABLE映射到ALTER TABLE ... FORCE(或者这样翻译:在InnoDB表中等价 ALTER TABLE ... FORCE),它重建表以更新索引统计信息并释放聚簇索引中未使用的空间。当您在InnoDB表上运行时,它会显示在OPTIMIZE TABLE的输出中,如下所示:
mysql> OPTIMIZE TABLE foo;
+----------+----------+----------+-------------------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+----------+----------+----------+-------------------------------------------------------------------+
| test.foo | optimize | note | Table does not support optimize, doing recreate + analyze instead |
| test.foo | optimize | status | OK |
+----------+----------+----------+-------------------------------------------------------------------+
OPTIMIZE TABLE对InnoDB的普通表和分区表使用online DDL,从而减少了并发DML操作的停机时间。由OPTIMIZE TABLE触发表的重建,并在ALTER TABLE ... FORCE的掩护下完成。仅在操作的准备阶段和提交阶段期间短暂地进行独占表锁定。在准备阶段,更新元数据并创建中间表。在提交阶段,将提交表元数据更改。
OPTIMIZE TABLE 在以下条件下使用表复制方法重建表:
o 启用old_alter_table系统变量时。
o 启用mysqld --skip-new 选项时。
OPTIMIZE TABLE 对于包含FULLTEXT索引的InnoDB表不支持online DDL。而是使用复制表的方法。
InnoDB使用页面分配方法存储数据,并且不会像传统存储引擎(例如MyISAM)那样受到碎片的影响。在考虑是否运行优化时,请考虑服务器将处理的事务的工作负载:
o 预计会有一定程度的碎片化。 InnoDB仅填充93%的页面,为更新留出空间而无需拆分页面。
o 删除操作可能会留下空白,使页面填充不如预期,这可能使得优化表格变得有价值。
当行有足够的空间时,对行的更新通常会重写同一页面中的数据,具体取决于数据类型和行格式。见 Section 14.9.1.5, “How Compression Works for InnoDB Tables” 和 Section 14.11, “InnoDB Row Formats” 。
高并发工作负载可能会随着时间的推移在索引中留下空白,因为InnoDB通过其MVCC机制保留了相同数据的多个版本。见 Section 14.3, “InnoDB Multi-Versioning” 。
另外,对于innodb_file_per_table=1的InnoDB表,OPTIMIZE TABLE 会重组表和索引的物理存储,将空闲空间释放给操作系统。也就是说OPTIMIZE TABLE [tablename] 这种方式只适用于独立表空间
关于OPTIMIZE TABLE,更多详细细节参考https://dev.mysql.com/doc/refman/8.0/en/optimize-table.html。感觉官方文档相当详细。
ALTER TABLE table_name ENGINE = Innodb;
这其实是一个NULL操作,表面上看什么也不做,实际上重新整理碎片了.当执行优化操作时,实际执行的是一个空的 ALTER 命令,但是这个命令也会起到优化的作用,它会重建整个表,删掉未使用的空白空间.
Running ALTER TABLE tbl_name ENGINE=INNODB on an existing InnoDB table performs a “null” ALTER TABLE operation, which can be used to defragment an InnoDB table, as described in Section 15.11.4, “Defragmenting a Table”. Running ALTER TABLE tbl_name FORCE on an InnoDB table performs the same function.
问题1:那么是用OPTIMIZE TABLE 还是ALTER TABLE xxxx ENGINE= INNODB好呢?
其实对于InnoDB引擎,ALTER TABLE xxxx ENGINE= INNODB是执行了一个空的ALTER TABLE操作。而OPTIMIZE TABLE等价于ALTER TABLE ... FORCE。 参考上面描述,在有些情况下,OPTIMIZE TABLE 还是ALTER TABLE xxxx ENGINE= INNODB基本上是一样的。但是在有些情况下,ALTER TABLE xxxx ENGINE= INNODB更好。例如old_alter_table系统变量没有启用等等。另外对于MyISAM类型表,使用ALTER TABLE xxxx ENGINE= INNODB是明显要优于OPTIMIZE TABLE这种方法的。
问题2:ALTER TABLE xxxx ENGINE= INNODB 表上的索引碎片会整理么
ALTER TABLE ENGINE= INNODB,会重新整理在聚簇索引上的数据和索引。如果你想用实验验证,可以对比执行该命令前后index_length的大小。
其它工具
网友建议使用pt工具或者gh-ost降低表的碎片化,个人暂时还没有使用过这类工具,估计也是封装了上面两个命令。此处不做展开介绍。
参考资料:
【高性能MySQL】
https://dev.mysql.com/doc/refman/8.0/en/optimize-table.html
https://dev.mysql.com/doc/refman/8.0/en/innodb-file-defragmenting.html
https://lefred.be/content/overview-of-fragmented-mysql-innodb-tables/
https://yq.aliyun.com/articles/41166
http://mysql.taobao.org/monthly/2015/08/05/
MySQL表的碎片整理和空间回收小结的更多相关文章
- MYSQL优化之碎片整理
MYSQL优化之碎片整理 在MySQL中,我们经常会使用VARCHAR.TEXT.BLOB等可变长度的文本数据类型.不过,当我们使用这些数据类型之后,我们就不得不做一些额外的工作--MySQL数据 ...
- Virtual box中Ubuntu虚拟机磁盘碎片整理和空间清理方法
虚拟机中,随着不断的使用,增加大文件(例如日志,视频和软件版本),虽然在虚拟机中手动删除了,但是虚拟机占用的空间并不会随之减少,需要手动清理一下. 这里介绍一种Virtual box中Ubuntu碎片 ...
- Mysql Innodb 表碎片整理
一.为什么会产生碎片 简单的说,删除数据必然会在数据文件中造成不连续的空白空间,而当插入数据时,这些空白空间则会被利用起来.于是造成了数据的存储位置不连续,以及物理存储顺序与理论上的排序顺序不同,这种 ...
- MySQL碎片整理小节--实例演示
MYSQL之磁盘碎片整理 清澈,细流涓涓的爱 数据库引擎以InnoDB为主 1.磁盘碎片是什么 InnoDB表的数据存储在页中,每个页可以存放多条记录,这些记录以树形结构组织,这棵树称为B+树. ...
- MySQL--OPTIMIZE TABLE碎片整理
参考:http://blog.51yip.com/mysql/1222.html BLOB和TEXT值会引起一些性能问题,特别是在执行了大量的删除操作时.删除操作会在数据表中留下很大的空洞,以后填入这 ...
- MySQL表碎片整理
MySQL表碎片整理 1. 计算碎片大小 2. 整理碎片 2.1 使用alter table table_name engine = innodb命令进行整理. 2.2 使用pt-online-sch ...
- MySQL InnoDB表的碎片量化和整理(data free能否用来衡量碎片?)
网络上有很多MySQL表碎片整理的问题,大多数是通过demo一个表然后参考data free来进行碎片整理,这种方式对myisam引擎或者其他引擎可能有效(本人没有做详细的测试).对Innodb引擎是 ...
- Oracle表空间碎片整理SHRINK与MOVE
整理表碎片通常的方法是move表,当然move是不能在线进行的,而且move后相应的索引也会失效,oracle针对上述不足,在10g时加入了shrink,那这个方法能不能在生产中使用呢? ...
- MySQL表空间回收的正确姿势
不知道大家有没有遇到这样的一种情况,线上业务在MySQL表上做增删改查操作,随着时间的推移,表里面的数据越来越多,表数据文件越来越大,数据库占用的空间自然也逐渐增长 为了缩小磁盘上表数据文件占用的空间 ...
随机推荐
- Windows窗体间的数据交互
轻松掌握Windows窗体间的数据交互 作者:郑佐 2004-04-05 Windows 窗体是用于 Microsoft Win ...
- Repeater 和 GridView 添加序列号
<tr><asp:Repeater ID="rptOfBrowerInfo" runat="server" > <Heade ...
- [yii]Trying to get property of non-object
今天接触gridview的时候,发现总是报错,如图. array( 'name'=>'user_info.userinfo', 'value'=>'$data->user_info- ...
- 网站特效离不开脚本,javascript是最常用的脚本语言,我们归纳一下常用的基础函数和语法:
转载自网络,非原创 1.输出语句:document.write(""); 2.JS中的注释为//3.传统的HTML文档顺序是:document->html->(head ...
- 渲染路径-Unity5 的新旧推迟渲染Deferred Lighting Rendering Path
Unity5 的新旧延迟渲染Deferred Lighting Rendering Path unity5 的render path ,比4的区别就是使用的新的deferred rendering,之 ...
- Unity中的Lod
http://blog.csdn.net/bigpaolee/article/details/48521371 LOD是( Level of Detail)的缩写,表示细节级别. 这里注意下,Lodg ...
- uoj#340. 【清华集训2017】小 Y 和恐怖的奴隶主(矩阵加速)
传送门 uoj上的数据太毒了--也可能是我人傻常数大的缘故-- 三种血量的奴隶主加起来不超过\(8\)个,可以枚举每种血量的奴隶主个数,那么总的状态数只有\(165\)种,设\(dp_{t,i,j,k ...
- jconsole 本地连接失败
http://limaoyuan.iteye.com/blog/1541745 加jvm 启动参数即可: -Dcom.sun.management.jmxremote -Dcom.sun.manag ...
- 第一个Three.js程序——加入相机
- [题解](组合数学/gcd)luogu_P3166数三角形
首先转化为ans=所有的组合方式 - 在同一水平/竖直线上 - 在同一斜线上 主要考虑在同一斜线上的情况 首先想到枚举斜率然后在坐标系内平移,以(0,0)为起点,每条线上的点数应该是gcd(x,y)比 ...