pandas中数据框的一些常见用法
1、创建数据框或读取外部csv文件
- 创建数据框数据
""" 设计数据 """
import pandas as pd
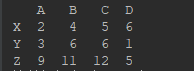
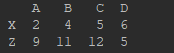
data = {"A": [2,3,9], "B": [4,6,11], "C": [5,6,12], "D": [6,1,5]}
index = ["X","Y","Z"]
df = pd.DataFrame(data=data, index=index)
print(df)
- 读取外部csv文件(关于“header=None”设定的问题参照 pandas.read_csv()函数读取文件时,关于“header=None”影响读取列数区间的右闭合总结)
""" 读取数据 """
import pandas as pd
df = pd.read_csv("data/data.csv", header=None)
2、重置索引
import pandas as pd
""" 设计数据 """
data = {"A": [2,3,9], "B": [4,6,11], "C": [5,6,12], "D": [6,1,5]}
index = ["X","Y","Z"]
df = pd.DataFrame(data=data, index=index)
""" 重置索引,从0开始计数 """
# 获取行数
nrow = df.shape[0]
# 获取列数
ncol = df.shape[1]
print("该数据框有%d行, %d列" %(nrow,ncol))
# 重置行索引
df.index = range(nrow)
# df.index = [1,2,3] # 也可以使用自定义手动方式
# 重置列索引
df.columns = range(ncol)
print(df)

3、行列读取
- 读取列
import pandas as pd
""" 设计数据 """
data = {"A": [2,3,9], "B": [4,6,11], "C": [5,6,12], "D": [6,1,5]}
index = ["X","Y","Z"]
df = pd.DataFrame(data=data, index=index)
""" 读取数据框 """
# 读取列
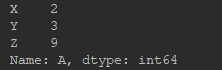
a = df.ix[:, 0] # 读取单列——第0列
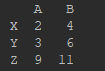
b = df.ix[:, 0:2] # 读取连续列——第0,1,2列
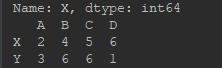
c = df.ix[:, [0,2]] # 读取指定某些列——第0,2列
print(a)
print(b)
print(c)

- 读取行(同理)
# 读取行
d = df.ix[0, :] # 读取单行——第0行
e = df.ix[0:2, :] # 读取连续行——第0,1,2行
f = df.ix[[0,2], :] # 读取指定某些行——第0,2行
print(d)
print(e)
print(f)

4、数据合并
""" 数据合并 """
import pandas as pd
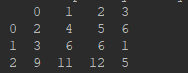
data1 = {"0": [2,3,9], "1": [4,6,11], "2": [5,6,12], "3": [6,1,5]}
index = [0,1,2]
df1 = pd.DataFrame(data=data1, index=index)
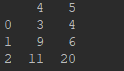
data2 = {"4": [3,9,11], "5": [4,6,20]}
df2 = pd.DataFrame(data=data2, index=index)
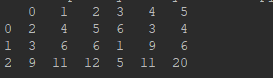
# 合并数据框(合并前需要确保数据是DataFrame格式), 其中,如果axis=1,ignore_index将改变的是列上的索引(属性名)
df = pd.concat([pd.DataFrame(df1), pd.DataFrame(df2)], axis=1) # axis=1 表示横向合并(左右);axis=0 表示纵向合并(上下)
print(df)
df1:
df2:
df:
pandas中数据框的一些常见用法的更多相关文章
- pandas中数据框DataFrame获取每一列最大值或最小值
1.python中数据框求每列的最大值和最小值 df.min() df.max()
- Scala中_(下划线)的常见用法
Scala中_(下划线)的常见用法 地址:https://www.jianshu.com/p/0497583ec538
- Pandas中数据的处理
有两种丢失数据 ——None ——np.nan(NaN) None是python自带的,其类型为python object.因此,None不能参与到任何计算中 Object类型的运算比int类型的运算 ...
- pandas中数据聚合【重点】
数据聚合 数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值. 数据分类处理: 分组:先把数据分为几组 用函数处理:为不同组的数据应用不同的函数以转换数据 合并:把不同组得到的结果合 ...
- JavaWeb_(Hibernate框架)Hibernate中数据查询语句SQL基本用法
本文展示三种在Hibernate中使用SQL语句进行数据查询基本用法 1.基本查询 2.条件查询 3.分页查询 package com.Gary.dao; import java.util.List; ...
- JavaWeb_(Hibernate框架)Hibernate中数据查询语句Criteria基本用法
Criteria进行数据查询与HQL和SQL的区别是Criteria完全是面向对象的方式在进行数据查询,将不再看到有sql语句的痕迹,使用Criteria 查询数据包括以下步骤: 1. 通过sessi ...
- JavaWeb_(Hibernate框架)Hibernate中数据查询语句HQL基本用法
HQL(Hibernate Query Language) 是面向对象的查询语言, 它和 SQL 查询语言有些相似. 在 Hibernate 提供的各种检索方式中, HQL 是使用最广的一种检索方式. ...
- Python3中IO文件操作的常见用法
首先创建一个文件操作对象: f = open(file, mode, encoding) file指定文件的路径,可以是绝对路径,也可以是相对路径 文件的常见mode: mode = “r” # ...
- JAVA中数组Arrays类的常见用法
import java.util.Arrays; int[] array1={7,8,3,2,12,6,5,4}; 1. //克隆clone int[] array2=array1.clone() ...
随机推荐
- 编写高质量代码改善C#程序的157个建议——建议132:考虑用类名作为属性名
建议132:考虑用类名作为属性名 一般来说,若果属性对应一个类型,应该直接用类型名命名属性名.如下: class Person { public Company Company { get; set; ...
- struts2使用验证文件实现校验
原创 struts2框架提供了一种基于验证文件的输入验证方式,将验证规则保存在特定的验证文件中. 验证文件的命名规则 一般情况下,验证文件的命名规则是:Action类名-validation.xml. ...
- 11、Semantic-UI之分割线
11.1 分割线的定义 示例:定义分割线 分割线 <div class="ui divider"></div> 竖线并加入or <div class= ...
- thinkphp里数据嵌套循环
做thinkphp时要用到循环里面嵌套循环的,并第二个循环是和外面的有关联的. thinkphp官网给出的文档为: <volist name="list" id=" ...
- Word页面去除下划线(Office 2017)实现
后面就不用说了吧设置边框无
- 三张图片看懂ZKEACMS的设计思想
前言 如果你还不知道ZKEACMS,不妨先了解一下. ASP.NET MVC 开源建站系统 ZKEACMS 推荐,从此网站“拼”起来 官方地址:http://www.zkea.net/zkeacms ...
- webapi之权限验证
webapi之权限验证 一.概念: 二.demo: 1.登录时生成token: FormsAuthenticationTicket token = , account, DateTime.Now, D ...
- OOM AutoMapper的简单实用
OOM AutoMapper的简单实用 一.前言: OOM顾名思义,Object-Object-Mapping实体间相互转换,AutoMapper也是个老生常谈了,其意义在于帮助你无需手动的转换简单 ...
- 【09】循序渐进学 docker:docker swarm
写在前面的话 至此,docker 的基础知识已经了解的差不多了,接下来就来谈谈对于 docker 容器,我们如何来管理它. docker swarm 在学习 docker swarm 之前,得先知道容 ...
- iOS开发其他相关
1.iOS开发行情 1.1 iOS系统各个版本的占比查询 2.Xcode的使用 开发软件下载 Xcode Help(官方) 2.1 Xcode面板 Xcode面板 2.2 Xcode版本新功能 Xco ...