python---twisted的使用,使用其模拟Scrapy
一:简单使用
from twisted.internet import defer
from twisted.web.client import getPage
from twisted.internet import reactor def one_done(arg):
print(arg) def all_done(arg):
print("all done")
reactor.stop() @defer.inlineCallbacks
def task(url):
res = getPage(bytes(url,encoding="utf-8")) #获取页面,发送http请求,是使用select池将所有socket请求保存,依据此进行计数。
print('',type(res)) #<class 'twisted.internet.defer.Deferred'>
res.addCallback(one_done) #对每一个请求都添加一个回调方法
yield res #返回他 start_url_list = [
'http://www.baidu.com',
'http://www.github.com',
] defer_list = []
for url in start_url_list:
v = task(url) #发送请求后立即返回,不等待返回,v是一个特殊对象,标志你发送到那个请求
print(v,type(v))
defer_list.append(v) d = defer.DeferredList(defer_list) #将上面的特殊对象列表一起放入DeferredList
d.addBoth(all_done) #为所有对象添加回调 reactor.run() #会一直循环,我们需要在任务执行完毕后关闭。含有计数器,执行一个任务,会执行一次one_done,计数减一。单任务执行完毕,计数为0,执行all_done
二:模块了解,getPage创建连接,放入select池中,进行计数,在事件循环时依据计数进行关闭(所以执行后自动关闭)

from twisted.internet import defer
from twisted.web.client import getPage
from twisted.internet import reactor def one_done(arg):
print(arg) def all_done(arg):
print("all done")
reactor.stop() @defer.inlineCallbacks
def task(url):
res = getPage(bytes(url,encoding="utf-8")) #获取页面,发送http请求,创建socket
res.addCallback(one_done) #对每一个请求都添加一个回调方法
yield res #返回他 res = getPage(bytes(url,encoding="utf-8")) #获取页面,发送http请求
res.addCallback(one_done) #对每一个请求都添加一个回调方法
yield res #返回他 start_url_list = [
'http://www.baidu.com',
'http://cn.bing.com',
] defer_list = []
for url in start_url_list:
v = task(url) #发送请求后立即返回,不等待返回,v是一个特殊对象,标志你发送到那个请求
print(v,type(v))
defer_list.append(v) d = defer.DeferredList(defer_list) #将上面的特殊对象列表一起放入DeferredList
d.addBoth(all_done)#为所有对象添加回调 reactor.run()#会一直循环,我们需要在任务执行完毕后关闭。含有计数器,执行一个任务,会执行一次one_done,计数减一。单任务执行完毕,计数为0,执行all_done
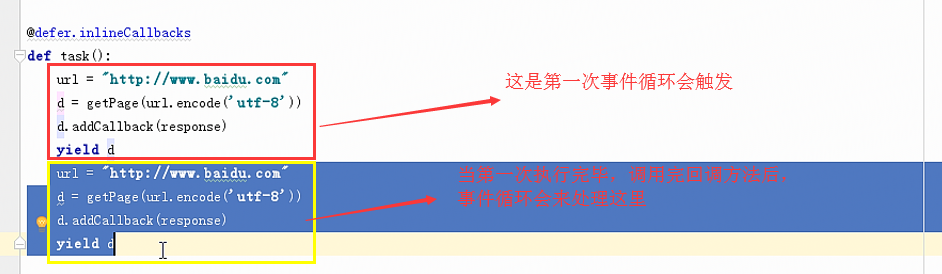
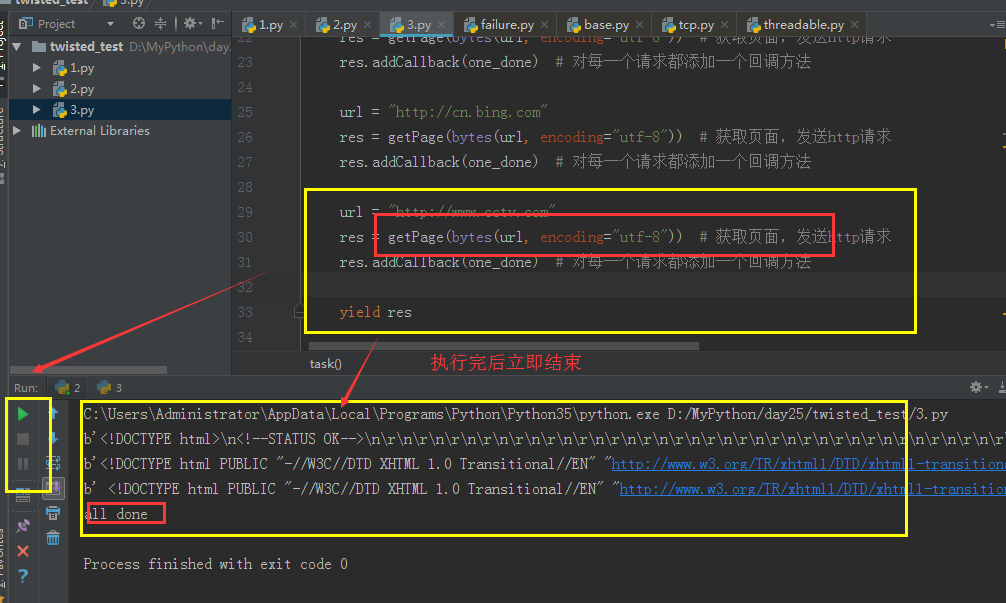
三:Deferred创建一个特殊socket对象,不放人select池,不发送请求,需要我们自己去终止
# coding:utf8
# __author: Administrator
# date: //
# /usr/bin/env python
from twisted.internet import defer
from twisted.web.client import getPage
from twisted.internet import reactor def one_done(arg):
print(arg) def all_done(arg):
print("all done")
reactor.stop() @defer.inlineCallbacks
def task():
url = "http://www.baidu.com"
res = getPage(bytes(url, encoding="utf-8")) # 获取页面,发送http请求
res.addCallback(one_done) # 对每一个请求都添加一个回调方法 url = "http://cn.bing.com"
res = getPage(bytes(url, encoding="utf-8")) # 获取页面,发送http请求
res.addCallback(one_done) # 对每一个请求都添加一个回调方法 url = "http://www.cctv.com"
res = getPage(bytes(url, encoding="utf-8")) # 获取页面,发送http请求
res.addCallback(one_done) # 对每一个请求都添加一个回调方法 yield defer.Deferred() defer_list = []
v = task() # 发送请求后立即返回,不等待返回,v是一个特殊对象,标志你发送到那个请求
defer_list.append(v) d = defer.DeferredList(defer_list) # 将上面的特殊对象列表一起放入DeferredList
d.addBoth(all_done) # 为所有对象添加回调 reactor.run() # 会一直循环,我们需要在任务执行完毕后关闭。含有计数器,执行一个任务,会执行一次one_done,计数减一。单任务执行完毕,计数为0,执行all_done
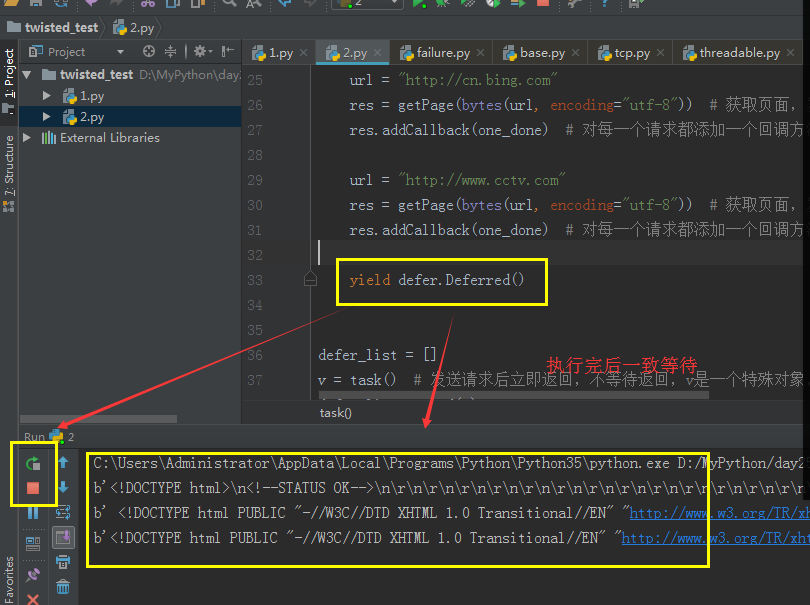
注意:
会执行每个getPage的回调 ,不会执行所有请求的公共回调,所有可以在每个的回调中进行处理,让他(将他设为全局)暂停。
count =
_close = None def one_done(arg):
print(arg)
global count
count += 1
if count == 3: #callback(None)会停止Deferred对象
_close.callback(None) #可以知道获取的响应数据是在事件循环中才去read,task方法只是创建写入socket def all_done(arg):
print("all done")
reactor.stop() @defer.inlineCallbacks #协程预激活器,在装饰器内部先使用send(None)激活协程
def task():
url = "http://www.baidu.com"
res = getPage(bytes(url, encoding="utf-8")) # 获取页面,发送http请求
res.addCallback(one_done) # 对每一个请求都添加一个回调方法 url = "http://cn.bing.com"
res = getPage(bytes(url, encoding="utf-8")) # 获取页面,发送http请求
res.addCallback(one_done) # 对每一个请求都添加一个回调方法 url = "http://www.cctv.com"
res = getPage(bytes(url, encoding="utf-8")) # 获取页面,发送http请求
res.addCallback(one_done) # 对每一个请求都添加一个回调方法 global _close
_close = defer.Deferred()
yield _close defer_list = []
v = task() # 发送请求后立即返回,不等待返回,v是一个特殊对象,标志你发送到那个请求
defer_list.append(v) d = defer.DeferredList(defer_list) # 将上面的特殊对象列表一起放入DeferredList
d.addBoth(all_done) # 为所有对象添加回调 reactor.run() # 会一直循环,我们需要在任务执行完毕后关闭。含有计数器,执行一个任务,会执行一次one_done,计数减一。单任务执行完毕,计数为0,执行all_done
四:简单模拟一次请求
from twisted.internet import defer
from twisted.internet.defer import Deferred _close = None def one_done(arg):
print(arg)
_close.callback(None) #将Deferred对象停止,之后才会去执行all_done,在all_done中终止掉事件循环 def all_done(arg):
print("all done")
reactor.stop() def coro_active(func):
def inner(*args,**kwargs):
gen = func(*args,**kwargs)
deferred = Deferred()
global _close
_close = deferred
result = gen.send(None) #预激活完成,执行到yield res if isinstance(result, Deferred):
# a deferred was yielded, get the result.
return deferred #返回一个特殊socket对象,不会发送请求,阻塞在这,在事件循环中,会被自动停止
return inner @coro_active #协程预激活器
def task():
url = "http://www.baidu.com"
res = getPage(bytes(url, encoding="utf-8")) # 获取页面,发送http请求
#内部对getPage的deferred进行了计数(是使用了队列),当运行一个getPage就会减一self._cancellations-=1,当为0时会退出循环,但是当我们自己返回一个deferred对象,则该对象计数不会自动去销毁,导致一直处于IO循环
res.addCallback(one_done) # 对每一个请求都添加一个回调方法 yield res defer_list = []
v = task() # 发送请求后立即返回,不等待返回,v是一个特殊对象,标志你发送到那个请求
print(v)
defer_list.append(v) d = defer.DeferredList(defer_list) # 将上面的特殊对象列表一起放入DeferredList
d.addBoth(all_done) # 为所有对象添加回调 reactor.run()
注意:在上面正常使中yield getPage(...),@defer.inlineCallbacks预激活器也是返回了一个Deferred对象,他是否在预激活器中使用了一样的方法。
五:Scrapy模拟
from twisted.internet import defer
from twisted.web.client import getPage
from twisted.internet import reactor count =
_close = None def one_done(arg):
print(arg)
global count
count +=
if count == :
_close.callback(None)
pass def all_done(arg):
print("all done")
reactor.stop() @defer.inlineCallbacks
def task(): #一个task相当于一个爬虫
#看做是递归的
#第一个是start_url
url = "http://www.baidu.com"
res = getPage(bytes(url, encoding="utf-8")) # 获取页面,发送http请求
res.addCallback(one_done) # 对每一个请求都添加一个回调方法 #下面两个可以看做parse中yield Request获取的请求
url = "http://cn.bing.com"
res = getPage(bytes(url, encoding="utf-8")) # 获取页面,发送http请求
res.addCallback(one_done) # 对每一个请求都添加一个回调方法 url = "http://www.cctv.com"
res = getPage(bytes(url, encoding="utf-8")) # 获取页面,发送http请求
res.addCallback(one_done) # 对每一个请求都添加一个回调方法 #若是任务没有结束,Deferred对象就一直hold住事件循环,当任务结束,事件循环停止
global _close
if not _close:
_close = defer.Deferred()
yield _close spider1 = task()
spider2 = task()
#两个爬虫都是并发的,内部请求也是并发的 d = defer.DeferredList([spider1,spider2]) # 将上面的特殊对象列表一起放入DeferredList
d.addBoth(all_done) # 为所有对象添加回调 reactor.run() # 会一直循环,我们需要在任务执行完毕后关闭。含有计数器,执行一个任务,会执行一次one_done,计数减一。单任务执行完毕,计数为0,执行all_done
六:Lower版Scrapy
from twisted.internet import defer
from twisted.internet import reactor
from twisted.web.client import getPage
import queue #放置url,是调度器
Q = queue.Queue() #定义的请求类,封装请求数据
class Request:
def __init__(self,url,callback):
self.url = url
self.callback = callback #定义响应类,将获取的数据进行封装处理
class HttpResponse:
def __init__(self,content,request):
self.content = content
self.request = request
self.url = request.url
self.text = str(content,encoding="utf-8") #定义的爬虫
class ChoutiSpider:
name = "chouti"
start_url = ["http://www.baidu.com","http://www.baidu.com"] def start_request(self):
for url in self.start_url:
yield Request(url,self.parse) def parse(self,response):
print(response.text)
yield Request("http://www.baidu.com",callback=self.parse) #引擎中心
class Engine:
def __init__(self):
self._close = None
self.max = #最大并发数限制
self.crawlling = [] #我们不直接去调用用户的回调函数,我们先调用自定义的回调方法,在这个方法中去调用用户的回调,所以我们可以完善用户的方法
def get_response_callback(self,content,request):
#request中含有请求,content是响应
# 1.crawlling移除
# 2.获取parse yield值
# 3.再次去队列中获取
self.crawlling.remove(request)
req = HttpResponse(content=content,request=request)
result = request.callback(req) #若是回调parse中只有输出,返回None,有yield则返回生成器
import types
if isinstance(result,types.GeneratorType): #若是生成器,代表用户又发送了请求,我们需要去迭代获取请求,放入调度器,等待获取
for req in result: #多个yield
Q.put(req) def _next_request(self):
if Q.qsize() == and len(self.crawlling) == :
self._close.callback(None)
return if len(self.crawlling) >= self.max:
return
while len(self.crawlling) < self.max:
try:
req = Q.get(block=False)
self.crawlling.append(req)
d = getPage(req.url.encode("utf-8"))
#任务下载完成,get_response_callback,调用用户spider中定义的parse方法,并且将新请求添加到调度器
d.addCallback(self.get_response_callback,req)
#因为上面处理将移除一个请求,所以现在未达到最大并发数,可以再去调度器中获取Request
# d.addCallback(self._next_request) #上面的addCallback可能会在向队列中发送请求
d.addCallback(lambda _:reactor.callLater(,self._next_request)) #可以交给reactor调用,内部维护,防止死循环
except Exception as e:
return @defer.inlineCallbacks
def crawl(self,spider):
#开始进行下载
#将初始Request对象添加到调度器
start_request = iter(spider.start_request())
while True:
try:
request = next(start_request) #next激活,获取request对象,两步含有url和回调方法,我们将其放入调度器,等待去下载数据
Q.put(request)
except StopIteration as e:
break #反复去调度器中去任务,并发送请求,下载数据
# self._next_request()
reactor.callLater(, self._next_request) #0秒后调用_next_request方法 self._close = defer.Deferred()
yield self._close _active = set()
engine = Engine() spider = ChoutiSpider()
d = engine.crawl(spider) #由于返回的是Deferred对象,会阻塞在此,等待close后进行
_active.add(d) dd = defer.DeferredList(_active)
dd.addBoth(lambda _:reactor.stop()) reactor.run()

七:完善版Scrapy
from twisted.internet import defer
from twisted.internet import reactor
from twisted.web.client import getPage
from queue import Queue #定义的请求类,封装请求数据
class Request:
def __init__(self,url,callback):
self.url = url
self.callback = callback #定义响应类,将获取的数据进行封装处理
class HttpResponse:
def __init__(self,content,request):
self.content = content
self.request = request
self.url = request.url
self.text = str(content,encoding="utf-8") class Scheduler(object):
"""
任务调度器
"""
def __init__(self):
self.q = Queue() def open(self):
pass def next_request(self):
try:
req = self.q.get(block=False)
except Exception as e:
req = None
return req def enqueue_request(self,req):
self.q.put(req) def size(self):
return self.q.qsize() class ExecutionEngine:
'''引擎:负责所有调度'''
def __init__(self):
self._close = None
self.scheduler = None
self.max =
self.crawlling = [] def get_response_callback(self,content,request):
self.crawlling.remove(request)
response = HttpResponse(content,request)
result = request.callback(response)
import types
if isinstance(result,types.GeneratorType):
for req in result:
self.scheduler.enqueue_request(req) def _next_request(self):
if self.scheduler.size() == and len(self.crawlling) == :
self._close.callback(None)
return while len(self.crawlling) < self.max:
req = self.scheduler.next_request()
if not req:
return
self.crawlling.append(req)
d = getPage(req.url.encode('utf-8'))
d.addCallback(self.get_response_callback,req)
d.addCallback(lambda _:reactor.callLater(,self._next_request)) @defer.inlineCallbacks
def open_spider(self,start_requests):
self.scheduler = Scheduler()
yield self.scheduler.open() #yield None只是为了不报错,因为在defer.inlineCallbacks需要当前函数是生成器
while True:
try:
req = next(start_requests)
except StopIteration as e:
break
self.scheduler.enqueue_request(req)
reactor.callLater(,self._next_request) @defer.inlineCallbacks
def start(self):
self._close = defer.Deferred()
yield self._close class Crawler:
'''用户封装调度器以及引擎'''
def _create_engine(self):
return ExecutionEngine() def _create_spider(self,spider_cls_path):
module_path,cls_name = spider_cls_path.rsplit(".",maxsplit=)
import importlib
m = importlib.import_module(module_path)
cls = getattr(m,cls_name)
return cls() @defer.inlineCallbacks
def crawl(self,spider_cls_path):
engine = self._create_engine()
print(engine) #每个爬虫创建一个引擎,一个调度器,去并发爬虫中的请求
spider = self._create_spider(spider_cls_path)
start_requests = iter(spider.start_requests())
yield engine.open_spider(start_requests)
yield engine.start() class CrawlerProcess:
'''开启事件循环'''
def __init__(self):
self._active = set() def crawl(self,spider_cls_path):
crawler = Crawler()
d = crawler.crawl(spider_cls_path)
self._active.add(d) def start(self):
dd = defer.DeferredList(self._active)
dd.addBoth(lambda _:reactor.stop()) reactor.run() class Command:
'''命令'''
def run(self):
crawl_process = CrawlerProcess()
spider_cls_path_list = ['spider.chouti.ChoutiSpider','spider.baidu.BaiduSpider']
for spider_cls_path in spider_cls_path_list:
crawl_process.crawl(spider_cls_path)
crawl_process.start() if __name__ == "__main__":
cmd = Command()
cmd.run()
spider目录下两个爬虫
from engine import Request
class ChoutiSpider(object): name = 'chouti' def start_requests(self):
start_url = ['http://www.baidu.com','http://www.bing.com',]
for url in start_url:
yield Request(url,self.parse) def parse(self,response):
print(response) #response是下载的页面
yield Request('http://www.cnblogs.com',callback=self.parse)
ChoutiSpider
from engine import Request
class CnblogsSpider(object): name = 'baidu' def start_requests(self):
start_url = ['http://www.baidu.com',]
for url in start_url:
yield Request(url,self.parse) def parse(self,response):
print(response) #response是下载的页面
yield Request('http://www.baidu.com',callback=self.parse)
BaiduSpider
python---twisted的使用,使用其模拟Scrapy的更多相关文章
- twisted 模拟scrapy调度循环
"""模拟scrapy调度循环 """from ori_test import pr_typeimport loggingimport ti ...
- Python Twisted、Reactor
catalogue . Twisted理论基础 . 异步编程模式与Reactor . Twisted网络编程 . reactor进程管理编程 . Twisted并发连接 1. Twisted理论基础 ...
- 【转】Python Twisted介绍
Python Twisted介绍 作者:Jessica McKellar 原文链接 Twisted是用Python实现的基于事件驱动的网络引擎框架.Twisted诞生于2000年初,在当时的网络游戏开 ...
- Python twisted article
学习python twisted 的好文章 An Introduction to Asynchronous Programming and Twisted Reference: http://kron ...
- python twisted教程[资料]
python twisted教程 一,异步编程 http://www.douban.com/note/232200511/ python twisted教程 二:缓慢的诗 http://www.d ...
- Python Twisted系列教程12:改进诗歌下载服务器
作者:dave@http://krondo.com/a-poetry-transformation-server/ 译者:杨晓伟(采用意译) 你可以从这里从头阅读这个系列. 新的服务器实现 这里我们 ...
- python网络爬虫(1)——安装scrapy框架的常见问题及其解决方法
Scrapy是为了爬取网站数据而编写的一款应用框架,出名,强大.所谓的框架其实就是一个集成了相应的功能且具有很强通用性的项目模板. 其实在Linux和 Mac安装,就简单的pip命令即可: pip i ...
- Python之爬虫(十五) Scrapy框架的命令行详解
这篇文章主要是对的scrapy命令行使用的一个介绍 创建爬虫项目 scrapy startproject 项目名例子如下: localhost:spider zhaofan$ scrapy start ...
- Python之爬虫(十四) Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
随机推荐
- Scrum立会报告+燃尽图(Beta阶段第六次)
此作业要求参见:https://edu.cnblogs.com/campus/nenu/2018fall/homework/2388 项目地址:https://coding.net/u/wuyy694 ...
- ASP.NET Zero--2.如何启动
1.直接启动 VS中直接启动 2.IIS站点 IIS中配置一个站点来启动(推荐) 3.登录 系统默认创建2个用户 默认用户名:admin 密码:123qwe 租户:Default 默认用户名:adm ...
- EF 联合查询
EF 文章表和标签表联合查询标签id在dis中的文章,还不知道性能如何 var query = tagRepo.Entities.Include("Tags").Where(t = ...
- MySQL 备份和恢复 理论知识
为什么要备份 数据无价 制定备份策略的注意点 1:可容忍丢失多少数据 2:恢复需要在多长时间内完成 3:备份的对象 数据.二进制日志和InnoDB的事务日志.SQL代码(存储过 ...
- JS高级 2
递归:函数自己调用自己 在JavaScript中唯一能产生作用域的东西是 函数!js中只有函数可以创建作用域 词法作用域,也叫做静态作用域 //就是在代码写好的那一刻,变量和函数的作用域就已经确定了, ...
- 利用书签功能对TDBGrid控件中多个记录的处理
DELPHI 的TDBGrid 控 件 主 要 用 来 处 理 数 据 表, 它 的 属 性 中 有 一 个dgMultiSelect, 若 此 属 性 设 定 为TRUE, 则 可 以 选 中 多 ...
- Delphi下使用指针的简单总结
由于最近公司太忙,好久没有更新我的BLOG了.原来想着写写关于HOOK驱动的文章,可是最后想想好久已经没有做驱动的东西了,怕写出来有错误,于是作罢.开发游戏也有一段时间了,发现使用DELPHI来开发网 ...
- 第180天:HTML5——本地存储
本地存储 客户端存储数据的方法 cookie 方法 localStorage方法 sessionStorage方法 一.localStorage 1.存储特点: localStorage方法存储的数据 ...
- 第79天:jQuery事件总结(二)
上一篇讲到jQuery中的事件,深入学习了加载DOM和事件绑定的相关知识,这篇主要深入讨论jQuery事件中的合成事件.事件冒泡和事件移除等内容. 一.合成事件 jQuery有两个合成事件——hove ...
- 最大流Dinic算法模板(pascal)
program rrr(input,output); const inf=; type pointer=^nodetype; nodetype=record t,c:longint; next,rev ...