并发编程---线程 ;python中各种锁
一,概念
在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程
线程顾名思义,就是一条流水线工作的过程,一条流水线必须属于一个车间,一个车间的工作过程是一个进程
--车间负责把资源整合到一起,是一个资源单位,而一个车间内至少有一个流水线
--流水线的工作需要电源,电源就相当于cpu
所以,进程只是用来把资源集中到一起(进程只是一个资源单位,或者说资源集合),而线程才是cpu上的执行单位。
多线程(即多个控制线程)的概念是,在一个进程中存在多个控制线程,多个控制线程共享该进程的地址空间,相当于一个车间内有多条流水线,都共用一个车间的资源。
二,理论知识
1,线程的创建开销小
创建进程的开销要远大于线程?
如果我们的软件是一个工厂,该工厂有多条流水线,流水线工作需要电源,电源只有一个即cpu(单核cpu)
一个车间就是一个进程,一个车间至少一条流水线(一个进程至少一个线程)
创建一个进程,就是创建一个车间(申请空间,在该空间内建至少一条流水线)
而建线程,就只是在一个车间内造一条流水线,无需申请空间,所以创建开销小
进程之间是竞争关系,线程之间是协作关系?
车间直接是竞争/抢电源的关系,竞争(不同的进程直接是竞争关系,是不同的程序员写的程序运行的,迅雷抢占其他进程的网速,360把其他进程当做病毒干死)
一个车间的不同流水线式协同工作的关系(同一个进程的线程之间是合作关系,是同一个程序写的程序内开启动,迅雷内的线程是合作关系,不会自己干自己)
2,为何要用多线程
多线程指的是,在一个进程中开启多个线程,简单的讲:如果多个任务共用一块地址空间,那么必须在一个进程内开启多个线程。详细的讲分为4点:
1. 多线程共享一个进程的地址空间
2. 线程比进程更轻量级,线程比进程更容易创建可撤销,在许多操作系统中,创建一个线程比创建一个进程要快10-100倍,在有大量线程需要动态和快速修改时,这一特性很有用
3. 若多个线程都是cpu密集型的,那么并不能获得性能上的增强,但是如果存在大量的计算和大量的I/O处理,拥有多个线程允许这些活动彼此重叠运行,从而会加快程序执行的速度。
4. 在多cpu系统中,为了最大限度的利用多核,可以开启多个线程,比开进程开销要小的多。(这一条并不适用于python)
Threads share the address space of the process that created it; processes have their own address space.
Threads have direct access to the data segment of its process; processes have their own copy of the data segment of the parent process.
Threads can directly communicate with other threads of its process; processes must use interprocess communication to communicate with sibling processes.
New threads are easily created; new processes require duplication of the parent process.
Threads can exercise considerable control over threads of the same process; processes can only exercise control over child processes.
Changes to the main thread (cancellation, priority change, etc.) may affect the behavior of the other threads of the process; changes to the parent process does not affect child processes.
线程共享创建它的进程的地址空间; 进程有自己的地址空间。
线程可以直接访问其进程的数据段; 进程拥有自己父进程数据段的副本。
线程可以直接与其进程的其他线程通信; 进程必须使用进程间通信来与兄弟进程通信。
新线程很容易创建; 新流程需要复制父流程。
线程可以对同一进程的线程进行相当大的控制; 进程只能控制子进程。
对主线程的更改(取消,优先级更改等)可能会影响进程的其他线程的行为; 对父进程的更改不会影响子进程。
线程与进程的区别
三,开启线程的两种方式
#方式一
from threading import Thread
import time
def sayhi(name):
time.sleep(2)
print('%s say hello' %name) if __name__ == '__main__':
t=Thread(target=sayhi,args=('egon',))
t.start()
print('主线程')
#方式二
from threading import Thread
import time
class Sayhi(Thread):
def __init__(self,name):
super().__init__()
self.name=name
def run(self):
time.sleep(2)
print('%s say hello' % self.name) if __name__ == '__main__':
t = Sayhi('egon')
t.start()
print('主线程')
四,实例
import threading
import time
def func(arg):
print(arg) t = threading.Thread(target=func,args=(11,))
t.start() print(123)
1.线程的基本使用
import time
def func(arg):
time.sleep(arg)
print(arg) t1 = threading.Thread(target=func,args=(3,))
t1.start() t2 = threading.Thread(target=func,args=(9,))
t2.start() print(123)
2.主线程默认等子线程执行完毕
import time
def func(arg):
time.sleep(2)
print(arg) t1 = threading.Thread(target=func,args=(3,))
t1.setDaemon(True)
t1.start() t2 = threading.Thread(target=func,args=(9,))
t2.setDaemon(True)
t2.start() print(123)
3.主线程不再等,主线程终止则所有子线程终止
import time
def func(arg):
time.sleep(0.01)
print(arg) print('创建子线程t1')
t1 = threading.Thread(target=func,args=(3,))
t1.start()
# 无参数,让主线程在这里等着,等到子线程t1执行完毕,才可以继续往下走。
# 有参数,让主线程在这里最多等待n秒,无论是否执行完毕,会继续往下走。
t1.join(2) print('创建子线程t2')
t2 = threading.Thread(target=func,args=(9,))
t2.start()
t2.join(2) # 让主线程在这里等着,等到子线程t2执行完毕,才可以继续往下走。 print(123)
4.开发者可以控制主线程等待子线程(最多等待时间)
def func(arg):
# 获取当前执行该函数的线程的对象
t = threading.current_thread()
# 根据当前线程对象获取当前线程名称
name = t.getName()
print(name,arg) t1 = threading.Thread(target=func,args=(11,))
t1.setName('侯明魏')
t1.start() t2 = threading.Thread(target=func,args=(22,))
t2.setName('刘宁钱')
t2.start() print(123)
5.线程名称
#先打印:11?123?
def func(arg):
print(arg) t1 = threading.Thread(target=func,args=(11,))
t1.start()
# start 是开始运行线程吗?不是
# start 告诉cpu,我已经准备就绪,你可以调度我了。
print(123)
6.线程本质
五,多线程编程
Python多线程情况下:
- 计算密集型操作:效率低。(GIL锁)
- IO操作: 效率高
Python多进程的情况下:
- 计算密集型操作:效率高(浪费资源)。 不得已而为之。
- IO操作: 效率高 (浪费资源)。
以后写Python时:
IO密集型用多线程: 文件/输入输出/socket网络通信
计算密集型用多进程。
v1 = [11,22,33] # +1
v2 = [44,55,66] # def func(data,plus):
for i in range(len(data)):
data[i] = data[i] + plus t1 = threading.Thread(target=func,args=(v1,1))
t1.start() t2 = threading.Thread(target=func,args=(v2,100))
t2.start()
1. 计算密集型多线程无用
import threading
import requests
import uuid url_list = [
'https://www3.autoimg.cn/newsdfs/g28/M05/F9/98/120x90_0_autohomecar__ChsEnluQmUmARAhAAAFES6mpmTM281.jpg',
'https://www2.autoimg.cn/newsdfs/g28/M09/FC/06/120x90_0_autohomecar__ChcCR1uQlD6AT4P3AAGRMJX7834274.jpg',
'https://www2.autoimg.cn/newsdfs/g3/M00/C6/A9/120x90_0_autohomecar__ChsEkVuPsdqAQz3zAAEYvWuAspI061.jpg',
] def task(url):
ret = requests.get(url)
file_name = str(uuid.uuid4()) + '.jpg'
with open(file_name, mode='wb') as f:
f.write(ret.content) for url in url_list: t = threading.Thread(target=task,args=(url,))
t.start()
2. IO操作 多线程有用
六、Python中各种锁
一、全局解释器锁(GIL)
1、什么是全局解释器锁
在同一个进程中只要有一个线程获取了全局解释器(cpu)的使用权限,那么其他的线程就必须等待该线程的全局解释器(cpu)使用权消失后才能使用全局解释器(cpu),即使多个线程直接不会相互影响在同一个进程下也只有一个线程使用cpu,这样的机制称为全局解释器锁(GIL)。
2、全局解释器锁的好处
1、避免了大量的加锁解锁的好处
2、使数据更加安全,解决多线程间的数据完整性和状态同步
3、全局解释器的缺点
多核处理器退化成单核处理器,只能并发不能并行。
4、如图所示:

同一时刻的某个进程下的某个线程只能被一个cpu所处理,所以在GIL锁下的线程只能被并发,不能被并行。
5、实例:

二、同步锁
1、什么是同步锁?
同一时刻的一个进程下的一个线程只能使用一个cpu,要确保这个线程下的程序在一段时间内被cpu执,那么就要用到同步锁。
2、为什么用同步锁?
因为有可能当一个线程在使用cpu时,该线程下的程序可能会遇到io操作,那么cpu就会切到别的线程上去,这样就有可能会影响到该程 序结果的完整性。
3、怎么使用同步锁?
只需要在对公共数据的操作前后加上上锁和释放锁的操作即可。
4、实例:
· 5、扩展知识
1、GIL的作用:多线程情况下必须存在资源的竞争,GIL是为了保证在解释器级别的线程唯一使用共享资源(cpu)。
2、同步锁的作用:为了保证解释器级别下的自己编写的程序唯一使用共享资源产生了同步锁。
线程安全,多线程操作时,内部会让所有线程排队处理.
GIL锁,全局解释器锁。用于限制一个进程中同一时刻只有一个线程被cpu调度。
默认GIL锁在执行100个cpu指令(过期时间)。
Threading模块为我们提供了一个类,Threading.Lock,锁。我们创建一个该类对象,在线程函数执行前,“抢占”该锁,执行完成后,“释放”该锁,则我们确保了每次只有一个线程占有该锁。
GIL VS Lock
首先我们需要达成共识:锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据
然后,我们可以得出结论:保护不同的数据就应该加不同的锁。
最后,问题就很明朗了,GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理,即Lock
过程分析:所有线程抢的是GIL锁,或者说所有线程抢的是执行权限 线程1抢到GIL锁,拿到执行权限,开始执行,然后加了一把Lock,还没有执行完毕,即线程1还未释放Lock,有可能线程2抢到GIL锁,开始执行,执行过程中发现Lock还没有被线程1释放,
于是线程2进入阻塞,被夺走执行权限,有可能线程1拿到GIL,然后正常执行到释放Lock。。。
这就导致了串行运行的效果
既然是串行,那我们执行 t1.start() t1.join t2.start() t2.join() 这也是串行执行啊,为何还要加Lock呢,需知join是等待t1所有的代码执行完,相当于锁住了t1的所有代码,而Lock只是锁住一部分操作共享数据的代码。
锁通常被用来实现对共享资源的同步访问。为每一个共享资源创建一个Lock对象,当你需要访问该资源时,调用acquire方法来获取锁对象(如果其它线程已经获得了该锁,则当前线程需等待其被释放),待资源访问完后,再调用release方法释放锁:
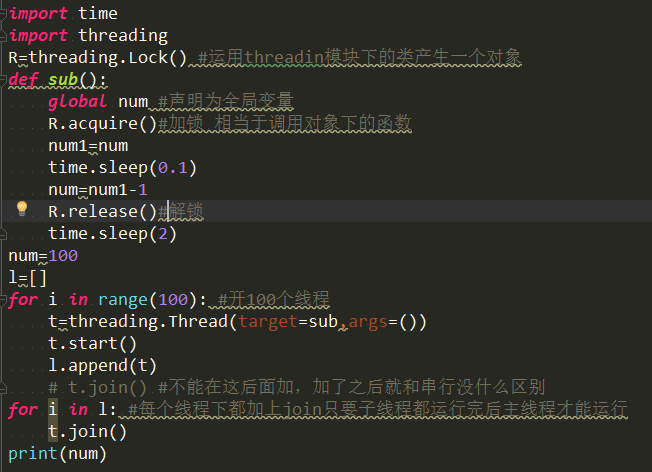
import threading R=threading.Lock() R.acquire()
'''
对公共数据的操作
'''
R.release()
from threading import Thread,Lock
import os,time
def work():
global n
lock.acquire()
temp=n
time.sleep(0.1)
n=temp-1
lock.release()
if __name__ == '__main__':
lock=Lock()
n=100
l=[]
for i in range(100):
p=Thread(target=work)
l.append(p)
p.start()
for p in l:
p.join() print(n) #结果肯定为0,由原来的并发执行变成串行,牺牲了执行效率保证了数据安全
分析:
#1.100个线程去抢GIL锁,即抢执行权限
#2. 肯定有一个线程先抢到GIL(暂且称为线程1),然后开始执行,一旦执行就会拿到lock.acquire()
#3. 极有可能线程1还未运行完毕,就有另外一个线程2抢到GIL,然后开始运行,但线程2发现互斥锁lock还未被线程1释放,于是阻塞,被迫交出执行权限,即释放GIL
#4.直到线程1重新抢到GIL,开始从上次暂停的位置继续执行,直到正常释放互斥锁lock,然后其他的线程再重复2 3 4的过程
GIL锁与互斥锁综合分析(重点!!!)
三、递归锁和死锁
1、什么是死锁?
指两个或两个以上的线程或进程在执行程序的过程中,因争夺资源而相互等待的一个现象,如图所示。

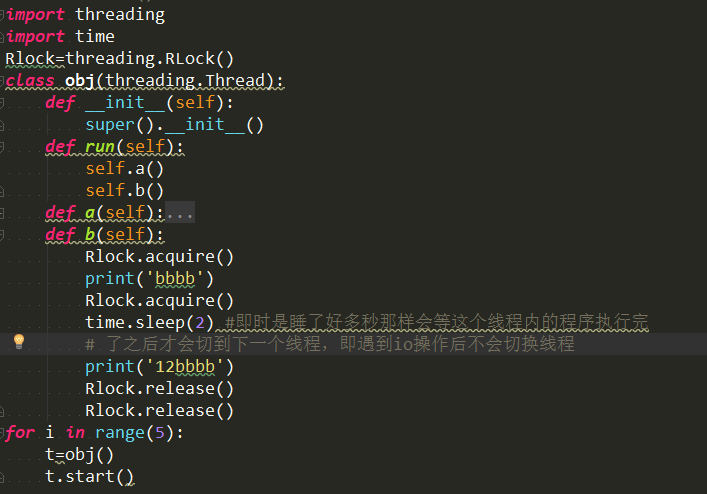
2、什么是递归锁?RLock
在Python中为了支持同一个线程中多次请求同一资源,Python提供了可重入锁。这个RLock内部维护着一个Lock和一个counter
变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获
得资源。
四、信号量(Semaphore)
1、什么是信号量?
同进程的一样,semaphore管理一个内置的计数器,每当调用acquire()时内置函数-1,每当调用release()时内置函数+1。
计数器不能为0,当计数器为0时acquire()将阻塞线程,直到其他线程调用release()。一次处理多个
2、如图所示:

五,Condition锁
动态放量输入几个一次放几个
示例一:
import threading
import time
r = threading.Condition()
def func(arg):
print('线程来了')
r.acquire()
r.wait() #加锁 print(arg)
time.sleep(1)
r.release() for i in range(20):
t = threading.Thread(target=func,args=(i,))
t.start() while True:
inp = int(input(">>>")) #输入几个放几个
r.acquire()
r.notify(inp) # inp为几放几个
r.release()
示例二:
import threading
import time
lock = threading.Condition()
def xxxx():
print('来执行函数了')
input(">>>")
return True def func(arg):
print('线程进来了')
lock.wait_for(xxxx)
print(arg)
time.sleep(1) for i in range(10):
t =threading.Thread(target=func,args=(i,))
t.start()
六,Event 锁
一次放所有,加锁相当红灯,,释放相当于变绿灯
示例:
import time
import threading
lock = threading.Event()
def func(arg):
print('线程来了')
lock.wait() # 加锁:红灯
print(arg) for i in range(10):
t =threading.Thread(target=func,args=(i,))
t.start() input(">>>>")
lock.set() # 绿灯 lock.clear() # 再次变红灯
for i in range(10):
t =threading.Thread(target=func,args=(i,))
t.start() input(">>>>")
lock.set()
并发编程---线程 ;python中各种锁的更多相关文章
- Java并发编程:Java中的锁和线程同步机制
锁的基础知识 锁的类型 锁从宏观上分类,只分为两种:悲观锁与乐观锁. 乐观锁 乐观锁是一种乐观思想,即认为读多写少,遇到并发写的可能性低,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新 ...
- 10 并发编程-(线程)-GIL全局解释器锁&死锁与递归锁
一.GIL全局解释器锁 1.引子 在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势 首先需要明确的一点是GIL并不是Python的特性,它是在实现Pyt ...
- Java并发编程(3) JUC中的锁
一 前言 前面已经说到JUC中的锁主要是基于AQS实现,而AQS(AQS的内部结构 .AQS的设计与实现)在前面已经简单介绍过了.今天记录下JUC包下的锁是怎么基于AQS上实现的 二 同步锁 同步锁不 ...
- 【并发编程】Java中的锁有哪些?
0.死锁 两个或者两个以上的线程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞现象,若无外力作用,他们都将无法让程序进行下去: 死锁条件: 不可剥夺条件: T1持有的资源无法被T2剥夺 请 ...
- 47_并发编程-线程python实现
一.Threading模块 1.线程的创建 - 方式一 from threading import Thread import time def sayhi(name): time.sleep(2 ...
- Python并发编程-线程
Python作为一种解释型语言,由于使用了全局解释锁(GIL)的原因,其代码不能同时在多核CPU上并发的运行.这也导致在Python中使用多线程编程并不能实现并发,我们得使用其他的方法在Python中 ...
- Python并发编程-线程同步(线程安全)
Python并发编程-线程同步(线程安全) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 线程同步,线程间协调,通过某种技术,让一个线程访问某些数据时,其它线程不能访问这些数据,直 ...
- Python 3 并发编程多进程之进程同步(锁)
Python 3 并发编程多进程之进程同步(锁) 进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端,是没有问题的,竞争带来的结果就是错乱,如何控制,就是加锁处理. 1. ...
- 并发编程学习笔记(6)----公平锁和ReentrantReadWriteLock使用及原理
(一)公平锁 1.什么是公平锁? 公平锁指的是在某个线程释放锁之后,等待的线程获取锁的策略是以请求获取锁的时间为标准的,即使先请求获取锁的线程先拿到锁. 2.在java中的实现? 在java的并发包中 ...
随机推荐
- freeswitch由于ext-sip-ip地址填写错误导致32秒拆线问题
通话32秒左右就断掉 检查 profile 的 ext-sip-ip 设置ext-rtp-ip和ext-sip-ip 可以直接设置为外网IP 自建stun-server, 更新后, 过了好几个小时出现 ...
- 我的MBTI性格测试
写在前面: 很多人争论MBTI靠谱不靠谱.一个人的性格肯定不能只用这么几个维度就能描述的,一个人的性格也肯定不是通过这么几个问题就能测出来的,一个人的性格也肯定不是一成不变的,所以MBTI的准确度肯定 ...
- Maven01 环境准备、maven项目结构、编译/测试/打包/清除、安装、
0 前提准备 0.1 安装java开发环境 0.2 安装maven工具 1 maven项目基本结构 如图所示,整个maven项目有业务文件.测试文件.POM依赖管理文件:其实还有一个资源文件resou ...
- 第一个Django应用程序_part3
一.概述 此文延续第一个Django应用程序part2. 官方文档:https://docs.djangoproject.com/en/1.11/intro/tutorial03/ view是Djan ...
- eclipse导入web项目报错 Cannot find the class file for javax.servlet.ServletContext.
当eclipse中新导入的Java Project的时候,往往会碰到各种各样的问题,下面是个典型的问题: Cannot find the class file for javax.servlet.Se ...
- noi2729 Blah数集
Blah数集 大数学家高斯小时候偶然间发现一种有趣的自然数集合Blah,对于以a为基的集合Ba定义如下: (1) a是集合Ba的基,且a是Ba的第一个元素: (2)如果x在集合Ba中,则2x+1和3x ...
- meshconverters
https://github.com/RobotLocomotion/meshConverters meshconverters $ mkdir build && cd build $ ...
- [BAT] 通过批处理加host
echo. >> %WINDIR%\system32\drivers\etc\hosts & echo xxx.xxx.xxx.xx test_host >> %WIN ...
- 【转载】MySQL常用系统表大全
转载地址:http://blog.csdn.net/xlxxcc/article/details/51754524 MySQL5.7 默认的模式有:information_schema, 具有 61个 ...
- 移动端H5页面如何屏蔽双击缩放的功能?(转)
来自大佬的回答: 我在我们的页面中加了很多,除了ios10以上的safari不兼容以外还没有遇到过不兼容的情况. <!-- 视图窗口,移动端特属的标签. --> <meta name ...