java爬取网页内容 简单例子(1)——使用正则表达式
【本文介绍】
爬取别人网页上的内容,听上似乎很有趣的样子,只要几步,就可以获取到力所不能及的东西,例如呢?例如天气预报,总不能自己拿着仪器去测吧!当然,要获取天气预报还是用webService好。这里只是举个例子。话不多说了,上看看效果吧。
【效果】
我们随便找个天气预报的网站来试试:http://www.weather.com.cn/html/weather/101280101.shtml
从图中可用看出,今天(6日)的天气。我们就以这个为例,获取今天的天气吧!

最终后台打印出:
今天:6日
天气:雷阵雨
温度:26°~34°
风力:微风
【思路】
1、通过url获取输入流————2、获取网页html代码————3、用正则表达式抽取有用的信息————4、拼装成想要的格式
其实最难的一点事第3点,如果正则表示式不熟,基本上在这一步就会挂掉了——例如我T_T。下面为了抽取到正确的数据,我匹配了多次,如果能一次匹配的话,那代码量就少多了!
【代码】
package com.zjm.www.test; import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.regex.Matcher;
import java.util.regex.Pattern; /**
* 描述:趴取网页上的今天的天气
* @author zjm
* @time 2014/8/6
*/
public class TodayTemperatureService { /**
* 发起http get请求获取网页源代码
* @param requestUrl String 请求地址
* @return String 该地址返回的html字符串
*/
private static String httpRequest(String requestUrl) { StringBuffer buffer = null;
BufferedReader bufferedReader = null;
InputStreamReader inputStreamReader = null;
InputStream inputStream = null;
HttpURLConnection httpUrlConn = null; try {
// 建立get请求
URL url = new URL(requestUrl);
httpUrlConn = (HttpURLConnection) url.openConnection();
httpUrlConn.setDoInput(true);
httpUrlConn.setRequestMethod("GET"); // 获取输入流
inputStream = httpUrlConn.getInputStream();
inputStreamReader = new InputStreamReader(inputStream, "utf-8");
bufferedReader = new BufferedReader(inputStreamReader); // 从输入流读取结果
buffer = new StringBuffer();
String str = null;
while ((str = bufferedReader.readLine()) != null) {
buffer.append(str);
} } catch (Exception e) {
e.printStackTrace();
} finally {
// 释放资源
if(bufferedReader != null) {
try {
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(inputStreamReader != null){
try {
inputStreamReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(inputStream != null){
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(httpUrlConn != null){
httpUrlConn.disconnect();
}
}
return buffer.toString();
} /**
* 过滤掉html字符串中无用的信息
* @param html String html字符串
* @return String 有用的数据
*/
private static String htmlFiter(String html) { StringBuffer buffer = new StringBuffer();
String str1 = "";
String str2 = "";
buffer.append("今天:"); // 取出有用的范围
Pattern p = Pattern.compile("(.*)(<li class=\'dn on\' data-dn=\'7d1\'>)(.*?)(</li>)(.*)");
Matcher m = p.matcher(html);
if (m.matches()) {
str1 = m.group(3);
// 匹配日期,注:日期被包含在<h2> 和 </h2>中
p = Pattern.compile("(.*)(<h2>)(.*?)(</h2>)(.*)");
m = p.matcher(str1);
if(m.matches()){
str2 = m.group(3);
buffer.append(str2);
buffer.append("\n天气:");
}
// 匹配天气,注:天气被包含在<p class="wea" title="..."> 和 </p>中
p = Pattern.compile("(.*)(<p class=\"wea\" title=)(.*?)(>)(.*?)(</p>)(.*)");
m = p.matcher(str1);
if(m.matches()){
str2 = m.group(5);
buffer.append(str2);
buffer.append("\n温度:");
}
// 匹配温度,注:温度被包含在<p class=\"tem tem2\"> <span> 和 </span><i>中
p = Pattern.compile("(.*)(<p class=\"tem tem2\"> <span>)(.*?)(</span><i>)(.*)");
m = p.matcher(str1);
if(m.matches()){
str2 = m.group(3);
buffer.append(str2);
buffer.append("°~");
}
p = Pattern.compile("(.*)(<p class=\"tem tem1\"> <span>)(.*?)(</span><i>)(.*)");
m = p.matcher(str1);
if(m.matches()){
str2 = m.group(3);
buffer.append(str2);
buffer.append("°\n风力:");
}
// 匹配风,注:<i> 和 </i> 中
p = Pattern.compile("(.*)(<i>)(.*?)(</i>)(.*)");
m = p.matcher(str1);
if(m.matches()){
str2 = m.group(3);
buffer.append(str2);
}
}
return buffer.toString();
} /**
* 对以上两个方法进行封装。
* @return
*/
public static String getTodayTemperatureInfo() {
// 调用第一个方法,获取html字符串
String html = httpRequest("http://www.weather.com.cn/html/weather/101280101.shtml");
// 调用第二个方法,过滤掉无用的信息
String result = htmlFiter(html); return result;
} /**
* 测试
* @param args
*/
public static void main(String[] args) {
String info = getTodayTemperatureInfo();
System.out.println(info);
}
}
【详解】
34-49行:通过url获取网页的源码,没什么好说的。
96行:在网页上按F12,查看"今天"的html代码,发现如下图,所以我们第一步就是要过滤掉除这一段html代码外的东西。
(.*)(<li class=\'dn on\' data-dn=\'7d1\'>)(.*?)(</li>)(.*) 这个正则表达式,很容易看出可以分为下面5组:
(.*) :匹配除换行符外任意东西0-N次
(<li class=\'dn on\' data-dn=\'7d1\'>) :匹配中间那段heml代码一次
(.*?) : .*?为匹配的懒惰模式,意思是匹配除换行符外任意东西尽可能少次
(</li>) :匹配中间那段html代码一次
(.*) :匹配除换行符外任意东西0-N次
这样,我们就可用m.group(3)拿到匹配中间(.*?)的那一串代码了。即我们需要的“今天”的天气的代码。
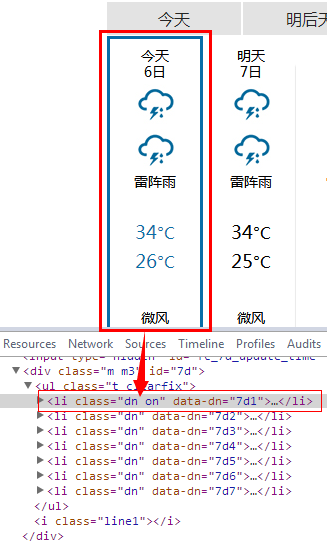
101行:中间那一段代码拿出来后如下图所示、还有很多无用的标签。我们要想办法继续除去。方法同上。

106行:手动拼接上我们需要的字符串。
经过以上的处理,就完成了一个简单的爬取啦。
中间正则表达式部分最不满意,各路网友如果有好的建议麻烦留下宝贵的评论,感激不尽~
java爬取网页内容 简单例子(1)——使用正则表达式的更多相关文章
- java爬取网页内容 简单例子(2)——附jsoup的select用法详解
[背景] 在上一篇博文java爬取网页内容 简单例子(1)——使用正则表达式 里面,介绍了如何使用正则表达式去解析网页的内容,虽然该正则表达式比较通用,但繁琐,代码量多,现实中想要想出一条简单的正则表 ...
- java爬虫爬取网页内容前,对网页内容的编码格式进行判断的方式
近日在做爬虫功能,爬取网页内容,然后对内容进行语义分析,最后对网页打标签,从而判断访问该网页的用户的属性. 在爬取内容时,遇到乱码问题.故需对网页内容编码格式做判断,方式大体分为三种:一.从heade ...
- Java爬取先知论坛文章
Java爬取先知论坛文章 0x00 前言 上篇文章写了部分爬虫代码,这里给出一个完整的爬取先知论坛文章代码. 0x01 代码实现 pom.xml加入依赖: <dependencies> & ...
- Java爬取同花顺股票数据(附源码)
最近有小伙伴问我能不能抓取同花顺的数据,最近股票行情还不错,想把数据抓下来自己分析分析.我大A股,大家都知道的,一个概念火了,相应的股票就都大涨. 如果能及时获取股票涨跌信息,那就能在刚开始火起来的时 ...
- MinerHtmlThread.java 爬取页面线程
MinerHtmlThread.java 爬取页面线程 package com.iteye.injavawetrust.miner; import org.apache.commons.logging ...
- MinerConfig.java 爬取配置类
MinerConfig.java 爬取配置类 package com.iteye.injavawetrust.miner; import java.util.List; /** * 爬取配置类 * @ ...
- Java爬取网络博客文章
前言 近期本人在某云上购买了个人域名,本想着以后购买与服务器搭建自己的个人网站,由于需要筹备的太多,暂时先搁置了,想着先借用GitHub Pages搭建一个静态的站,搭建的过程其实也曲折,主要是域名地 ...
- Java爬取校内论坛新帖
Java爬取校内论坛新帖 为了保持消息灵通,博主没事会上上校内论坛看看新帖,作为爬虫爱好者,博主萌生了写个爬虫自动下载的想法. 嗯,这次就选Java. 第三方库准备 Jsoup Jsoup是一款比较好 ...
- Java爬取B站弹幕 —— Python云图Wordcloud生成弹幕词云
一 . Java爬取B站弹幕 弹幕的存储位置 如何通过B站视频AV号找到弹幕对应的xml文件号 首先爬取视频网页,将对应视频网页源码获得 就可以找到该视频的av号aid=8678034 还有弹幕序号, ...
随机推荐
- LT和ET模式
#include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include &l ...
- jquery获取的html元素和document获取的元素的区别
最近通过ocx做了一个视频插件,然后将插件放到html中(想知道的可以看一下) 因为我要操作这个插件,要播放,停止等,所以我需要获取这个元素,不出意外的,我就用jquery来获取,然后根本无法执行,然 ...
- 树链剖分 + 后缀数组 - E. Misha and LCP on Tree
E. Misha and LCP on Tree Problem's Link Mean: 给出一棵树,每个结点上有一个字母.每个询问给出两个路径,问这两个路径的串的最长公共前缀. analyse: ...
- 2015 Multi-University Training Contest 3 1002 RGCDQ
RGCDQ Problem's Link: http://acm.hdu.edu.cn/showproblem.php?pid=5317 Mean: 定义函数f(x)表示:x的不同素因子个数. 如:f ...
- 构造方法也可以实现overloading
构造方法也可以实现overloading.例: public void teach(){}; public void teach(int a){}; public void teach(String ...
- 基于Unity5的TPS整理
1.游戏管理器 游戏管理器负责管理游戏的整体流程,还可以系统管理用于游戏的全局数据以及游戏中判断胜败的条件.游戏管理器并不是单一的模块,更像是能控制游戏的功能集合.1)怪兽出现逻辑:专门设置一些位置用 ...
- mysql --mysqli::multi_query 和 mysqli_multi_query
语法: 对象化:bool mysqli::multi_query ( string $query ) 过程化:bool mysqli_multi_query ( mysqli $link , stri ...
- poj3301--Texas Trip(最小正方形覆盖)
题目链接:点击打开链接 题目大意:给出n个点的坐标.如今要求一个正方形,全然包围n个点.而且正方形面积最小,求最小的正方形面积. 表示不能理解为什么面积随着角度的变化是一个单峰的函数,等待大牛告诉一下 ...
- MySQL单列索引和组合索引的选择效率与explain分析
一.先阐述下单列索引和组合索引的概念: 单列索引:即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引. 组合索引:即一个索包含多个列. 如果我们的查询where条件只有一个,我们完全可 ...
- openssl之EVP系列之8---EVP_Digest系列函数具体解释
openssl之EVP系列之8---EVP_Digest系列函数具体解释 ---依据openssl doc/crypto/EVP_DigestInit.pod翻译和自己的理解写成 (作 ...