关于scrapy
Scrapy安装
1,Pip install wheel
2,pip install 复制路径+文件名Twisted-18.7.0-cp36-cp36m-win_amd64.whl
3,Pip install scrapy
https://germey.gitbooks.io/python3webspider/content/1.8.2-Scrapy%E7%9A%84%E5%AE%89%E8%A3%85.html
4 出win7api的加 pip install 复制路径+文件名pywin32-223.1-cp36-cp36m-win_amd64.whl
创建项目
1,scrapy startproject scrapy_project
创建spider,
2,cd scrapy_project
3,scrapy genspider bole jobbole.com
#bole jobbole.com 一个是文件名 一个是网站名
创立一个文件夹 main 里面
from scrapy.cmdline import execute
execute('scrapy crawl bole'.split())
#bole是文件名
setting 里面的Trun改成False
通过xpath获取内容, xpath返回的元素内容是selector:
zan = response.xpath('//h10[@id="89252votetotal"]/text()').extract_first()
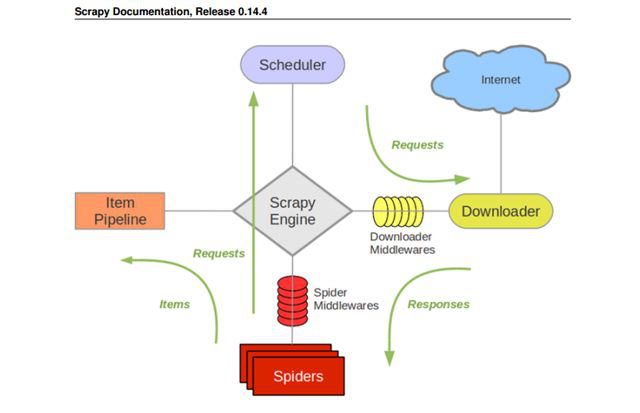
关于scrapy的更多相关文章
- Scrapy框架爬虫初探——中关村在线手机参数数据爬取
关于Scrapy如何安装部署的文章已经相当多了,但是网上实战的例子还不是很多,近来正好在学习该爬虫框架,就简单写了个Spider Demo来实践.作为硬件数码控,我选择了经常光顾的中关村在线的手机页面 ...
- scrapy爬虫docker部署
spider_docker 接我上篇博客,为爬虫引用创建container,包括的模块:scrapy, mongo, celery, rabbitmq,连接https://github.com/Liu ...
- scrapy 知乎用户信息爬虫
zhihu_spider 此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据存储使用mongo,下载这些数据感觉也没什么用,就当为大家学习scrapy提供一个例子吧.代码地 ...
- ubuntu 下安装scrapy
1.把Scrapy签名的GPG密钥添加到APT的钥匙环中: sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 6272 ...
- 网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
上周学习了BeautifulSoup的基础知识并用它完成了一个网络爬虫( 使用Beautiful Soup编写一个爬虫 系列随笔汇总 ), BeautifulSoup是一个非常流行的Python网 ...
- Scrapy:为spider指定pipeline
当一个Scrapy项目中有多个spider去爬取多个网站时,往往需要多个pipeline,这时就需要为每个spider指定其对应的pipeline. [通过程序来运行spider],可以通过修改配置s ...
- scrapy cookies:将cookies保存到文件以及从文件加载cookies
我在使用scrapy模拟登录新浪微博时,想将登录成功后的cookies保存到本地,下次加载它实现直接登录,省去中间一系列的请求和POST等.关于如何从本次请求中获取并在下次请求中附带上cookies的 ...
- Scrapy开发指南
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. Scrapy基于事件驱动网络框架 Twis ...
- 利用scrapy和MongoDB来开发一个爬虫
今天我们利用scrapy框架来抓取Stack Overflow里面最新的问题(),并且将这些问题保存到MongoDb当中,直接提供给客户进行查询. 安装 在进行今天的任务之前我们需要安装二个框架,分别 ...
- python3 安装scrapy
twisted(网络异步框架) wget https://pypi.python.org/packages/dc/c0/a0114a6d7fa211c0904b0de931e8cafb5210ad82 ...
随机推荐
- windows下手动安装composer并配置环境变量
windows下手动安装composer并配置环境变量 转载地址: https://my.oschina.net/7sites/blog/209997 之前发表过一篇如何为composer设置代理 ...
- springboot-yml内list、map组合写法
yml:myProps: varmaplist: key11: - t1 - t2 - t3 key22: - t11 - t22 - t33 list: - topic1 - topic2 - to ...
- spring事务的7种传播行为
https://blog.csdn.net/weixin_39625809/article/details/80707695 一般用于并发,分布式锁.复杂业务情况
- Redis 错误:Failed with result 'start-limit-hit'
Redis 错误:Failed with result 'start-limit-hit' 背景 Redis 版本为 5.0.4: 文件 /etc/systemd/system/redis.servi ...
- 连接MySQL报错The server time zone value 'Öйú±ê׼ʱ¼ä' is unrecognized or represents more than one time zone.
MySQL time zone 时区错误 使用root用户登陆执行命令: ---> show variables like '%time_zone%'; 默认值system为美国时间:如下图: ...
- 20165306 Exp5 MSF基础应用
Exp5 MSF基础应用 一.实践概述 1. 实践内容 本实践目标是掌握metasploit的基本应用方式,重点常用的三种攻击方式的思路.实现: 1.1一个主动攻击实践 ms08-067+window ...
- 初学者易上手的SSH-hibernate04 一对一 一对多 多对多
这章我们就来学习下hibernate的关系关联,即一对一(one-to-one),一对多(one-to-many),多对多(many-to-many).这章也将是hibernate的最后一章了,用于初 ...
- 2.1 maven配置多镜像地址
背景: 自己在平时写项目用的是阿里的镜像地址,而在开发公司的项目是用的是公司提供的镜像地址,这就导致了每次使用的时候 都需要来回的修改maven的settings.xml文件,这样很容易出错,而且还浪 ...
- 操纵Review被封店,申诉信
标签: 测评被封 亚马逊申诉 操纵评价申诉 分类: 亚马逊申诉模板 Hello,We recently contacted you about product review manipulation. ...
- Elasticsearch+Mongo亿级别数据导入及查询实践
数据方案: 在Elasticsearch中通过code及time字段查询对应doc的mongo_id字段获得mongodb中的主键_id 通过获得id再进入mongodb进行查询 1,数据情况: ...