第十四周翻译-《Pro SQL Server Internals, 2nd edition》
《Pro SQL Server Internals, 2nd edition》
作者:Dmitri Korotkevitch
翻译:赖慧芳
译文:
设计和优化索引
定义一种应用于所有地方的索引策略是不可能的。每个系统都是独特的,需要基于工作,业务需求和其他一些因素的自己的索引方法。然而,有几个设计的注意事项和指导方针可以被应用到每个系统。
在我们优化现有的系统时非常正解。虽然优化是一个迭代过程在任何时候都是独特的,但是有一组技术可以用来检测每个数据系统的效率低下。
在本章节,请记住我们将呈现一些重要因素在设计新的索引和优化现有的系统时。
聚集索引设计注意事项
在你改变聚集索引键的值时,将会发生两件事。首先,SQL server移动行到聚集索引页链和数据文件中的不同位置。第二,它更新聚集索引键的行编号。这个行编号被存储,而且被再次更新在非聚集索引里。就I/O而言,这可能非常昂贵,尤其是在批处理更新的情况下。另外,它还会增加聚集索引的碎片,在行编号增加下,还增加非聚集索引的碎片。因此,最好有一个静态聚集索引,让键的值不会改变。
所有非聚集索引使用聚集索引键作为行编号。一个太大的聚集索引键增加非聚集索引行的存储空间。结果,在索引和距离扫描时SQL server不得不处理更多的数据页,这将导致效率低下。
在非唯一非聚集索引情况下,行编号同样存储在非叶索引层上,反过来,这将减少每页的索引记录,并且导致索引中额外的中间级别。在每次SQLserver遍历非聚集索引的二叉树时,尽管非叶索引层缓存在内存中,但是都会引入额外的逻辑读取。
最后,在索引维护时,越来越多的非聚集索引在缓冲池中使用更多空间和引入更多的开销。显然,不可能提供一个通用阈值来定义可以应用于任何表的键的最大可接受大小。但是,一般来说,最好使用一个窄的聚集索引键,索引键越小越好。将索引键定义为唯一的大有益处。这个重要原因并非显而易见的。考虑这个场景,在表没有唯一的索引时,而你希望运行使用执行计划中非聚集索引查询的查询。在这个情况下,如果非聚集索引中的行编号不是惟一的,SQL Server将不知道在键查找操作期间选择哪个聚集索引行。SQL Server通过向非惟一聚集索引中添加另一个名为唯一标识符的可空整数列来解决此类问题。对于键值的第一次出现,SQL Server用NULL填充唯一标识符,并为插入到表中的每个后续重复值自动递增。
©Dmitri Korotkevitch 2016 155
- Korotkevitch,Pro SQL Server内部,DOI 10.1007 /978-1-4842-1964-5_7
■注意 每个聚集索引键的值的可能的重复次数受整型域值的限制。你不能有超过2,147,483,648行使用相同的聚集索引键。这是一个理论上的限制,创建选择性如此差的索引显然不是一个好主意。
让我们看看在非唯一聚集索引中引入唯一标识符的开销。清单7-1所示的代码创建了三个相同结构的不同表,每个表都填充了65,536行。UniqueCI表是唯一被定义了唯一聚集索引。nonuniquecinodups表没有任何重复的键值。最后,NonUniqueCDups表在索引中有大量的副本。
清单7 - 1.非惟一聚集索引:表创建
create table dbo.UniqueCI //创建UniqueCI表
(
KeyValue int not null, //键值不为空
ID int not null, //编号不为空
Data char() null, //数据可空
VarData varchar() not null
constraint DEF_UniqueCI_VarData
default 'Data'
);
create unique clustered index IDX_UniqueCI_KeyValue
on dbo.UniqueCI(KeyValue); //为UniqueCI表创建唯一聚集引索
create table dbo.NonUniqueCINoDups //创建NonUniqueCINoDups表
(
KeyValue int not null,
ID int not null,
Data char() null,
VarData varchar() not null
constraint DEF_NonUniqueCINoDups_VarData
default 'Data'
);
create /*unique*/ clustered index IDX_NonUniqueCINoDups_KeyValue
on dbo.NonUniqueCINoDups(KeyValue); //创建聚集索引
create table dbo.NonUniqueCIDups
(
KeyValue int not null,
ID int not null,
Data char() null,
VarData varchar() not null
constraint DEF_NonUniqueCIDups_VarData
default 'Data'
);
create /*unique*/ clustered index IDX_NonUniqueCIDups_KeyValue
on dbo.NonUniqueCIDups(KeyValue);
-- Populating data //填充数据
;with N1(C) as (select union all select ) -- rows
,N2(C) as (select from N1 as T1 cross join N1 as T2) -- rows
,N3(C) as (select from N2 as T1 cross join N2 as T2) -- rows
,N4(C) as (select from N3 as T1 cross join N3 as T2) -- rows
,N5(C) as (select from N4 as T1 cross join N4 as T2) -- , rows
,IDs(ID) as (select row_number() over (order by (select null)) from N5)
insert into dbo.UniqueCI(KeyValue, ID) //插入UniqueCI表
select ID, ID from IDs;
insert into dbo.NonUniqueCINoDups(KeyValue, ID) //插入NonUniqueCINoDups表
select KeyValue, ID from dbo.UniqueCI;
insert into dbo.NonUniqueCIDups(KeyValue, ID) //插入NonUniqueCINoDups表
select KeyValue % , ID from dbo.UniqueCI;
现在,让我们看看每个表的聚集索引的物理统计信息。代码如清单7-2所示,结果如图7-1所示。
清单7 - 2非唯一聚集索引:检查聚集索引的行大小
select index_level, page_count, min_record_size_in_bytes as [min row size]
,max_record_size_in_bytes as [max row size]
,avg_record_size_in_bytes as [avg row size]
from
sys.dm_db_index_physical_stats(db_id(), object_id(N'dbo.UniqueCI'), , null ,'DETAILED');
select index_level, page_count, min_record_size_in_bytes as [min row size]
,max_record_size_in_bytes as [max row size]
, avg_record_size_in_bytes as [avg row size]
from
sys. dm_db_index_physical_stats(db_id(), object_id(N'dbo.NonUniqueCINoDups'), , null
,'DETAILED');
select index_level, page_count, min_record_size_in_bytes as [min row size]
,max_record_size_in_bytes as [max row size]
,avg_record_size_in_bytes as [avg row size]
from
sys. dm_db_index_physical_stats(db_id(), object_id(N'dbo.NonUniqueCIDups'), , null
,'DETAILED');
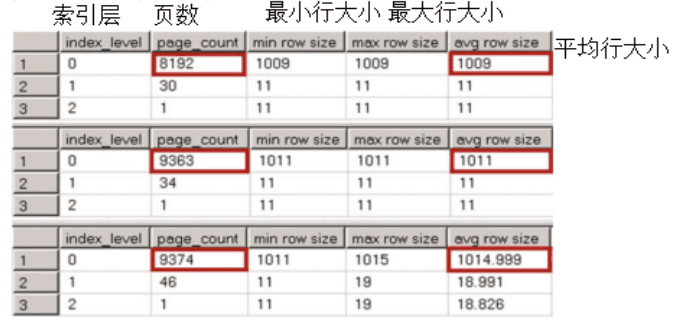
清单7 - 1.非唯一聚集索引:聚集索引的行大小
尽管在表NonUniqueCINoDups没有重复的键,但是行仍然增加了2个额外的字节。SQL Server在数据的变长部分存储一个唯一标识符,这2个字节由变长数据偏移数组中的另一个条目添加。
在这种情况下,当聚集索引具有重复值时,唯一标识符将再添加4个字节,即造成总共6个字节的开销。
值得一提的是,在某些特殊情况下,唯一标识符使用的额外存储空间可以减少数据页上可以容纳的行数。我们的示例演示了这种情况。如你所见,UniqueCI表与其他两个表相比,UniqueCI表使用的数据页少了大约15%。206/5000
现在,让我们看唯一标识符如何影响非聚集索引。清单7-3所示的代码在所有三个表中创建了非集群索引。图7-2显示了这些索引的物理统计信息。
清单7-3.非唯一聚集索引:检查非聚集索引的行大小
create nonclustered index IDX_UniqueCI_ID
on dbo.UniqueCI(ID); //创建UniqueCI表的非聚集索引
create nonclustered index IDX_NonUniqueCINoDups_ID
on dbo.NonUniqueCINoDups(ID); //创建NonUniqueCINoDups表的非聚集索引
create nonclustered index IDX_NonUniqueCIDups_ID
on dbo.NonUniqueCIDups(ID); //创建NonUniqueCIDups表的非聚集索引
select index_level, page_count, min_record_size_in_bytes as [min row size]
,max_record_size_in_bytes as [max row size]
,avg_record_size_in_bytes as [avg row size]
from
sys. dm_db_index_physical_stats(db_id(), object_id(N'dbo.UniqueCI'), , null
,'DETAILED');
select index_level, page_count, min_record_size_in_bytes as [min row size]
,max_record_size_in_bytes as [max row size]
,avg_record_size_in_bytes as [avg row size]
from
sys. dm_db_index_physical_stats(db_id(), object_id(N'dbo.NonUniqueCINoDups'), , null
,'DETAILED');
select index_level, page_count, min_record_size_in_bytes as [min row size]
,max_record_size_in_bytes as [max row size]
,avg_record_size_in_bytes as [avg row size]
from
sys. dm_db_index_physical_stats(db_id(), object_id(N'dbo.NonUniqueCIDups'), , null
,'DETAILED');
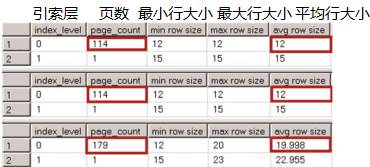
图7 - 2.非唯一聚集索引:非聚集索引的行大小
在NonUniqueCINoDups表没有非聚集索引没有开销。正如你所记得的,SQLserver不会存储偏移量信息到为了存储空数据的尾随列的变长数组中。尽管如此,在NonUniqueCIDups表中唯一标识符引入了8子节的开销。这8个字节由一个4字节的唯一标识符值、一个2字节的变长数据偏移数组条目和一个存储行中变长列数的2字节条目组成。
我们可以用以下方式总结唯一标识符的存储开销。对于唯一标识符为空的行,如果索引中至少有一个存储非空值的变长列,则会有两个字节的开销。这个开销来自变长偏移数组条目为了唯一标识符所在行,否则将不会有开销。
在填充唯一标识符的情况下,如果存在存储非空值的变长列,则开销为6字节。否则,开销是8字节。
■提示 如果期望在聚集索引值中有大量重复,可以将整数标识列作为最右边的列添加到索引中,从而使其惟一。与唯一标识符引入的最多8字节的不可预测存储开销相比,这将为每行增加一个4字节的可预测存储开销。当您通过引用该行的所有聚集索引列时,还可以提高单个查找操作的性能。
以最小化插入新行导致的索引碎片的方式设计聚集索引是有益的。实现这一点的方法之一是使聚集索引值不断增加。标识列上的索引就是这样一个例子。另一个例子是时间列,其中填充了插入时的当前系统时间。
然而,索引不断增长存在两个潜在问题。第一个与统计有关。
正如第三章所学的,当直方图中没有参数值时,SQL Server中的遗留基数估计值会低估基数。您应该将这种因素考虑到系统的统计维护策略中,除非您使用新的SQL Server 2014-2016基数估计值,该估计值假定直方图之外的数据具有类似于表中其他数据的分布。
下一个问题更复杂。随着索引的增加,数据总是插入索引的末尾。一方面,它可以防止页面分裂,减少碎片。另一方面,它可能导致热点,即当多个会话试图修改相同的数据页和分配新的页或区段时发生的序列化延迟。SQL Server不允许多个会话更新相同的数据结构,而是序列化这些操作。
热点通常不是问题,除非系统以非常高的速率收集数据,并且索引每秒处理数百次插入。我们将在第27章“系统故障排除”中讨论如何检测此类问题。
最后,如果系统有一组频繁执行的重要查询,那么考虑聚集索引可能是有益的,它可以优化这些查询。这消除了昂贵的键查找操作,并提高了系统的性能。
尽管可以通过使用覆盖非聚集索引来优化此类查询,但它并不总是理想的解决方案。在某些情况下,需要创建非常大的非聚集索引,这将占用磁盘和缓冲池中的大量存储空间。
另一个重要因素是修改列的频率。将经常修改的列添加到非聚集索引需要SQL Server在多个位置更改数据,这会对系统的更新性能产生负面影响,并增加阻塞。
尽管如此,设计满足所有这些要求的聚集索引并不总是可能的
指导方针。此外,您不应该认为这些指导方针是绝对的需求。你应该
分析系统,业务需求、工作负载和查询,并选择所需的集群索引让你受益,即使他们违反了其中的一些准则。
身份、序列和独特标识符
人们通常选择标识符、序列和惟一标识符作为聚集索引键。与往常一样,这种方法有其优缺点。
在这些列上定义的聚集索引是惟一的、静态的和窄的。此外,恒等式和序列不断增加,这减少了索引碎片。其中一个最理想的用例是目录实体表。例如,可以考虑存储客户、文章或设备列表的表。这些表存储数千行,甚至可能几百万行,尽管数据是相对静态的,因此,热点不是问题。此外,这些表通常由外键引用并用于连接。整数列或大数列上的索引非常紧凑和高效,这将提高查询的性能。
■注意 我们将在第8章“约束”中更详细地讨论外键约束。
标识符或序列列上的聚集索引在事务表的情况下效率较低,事务表以非常高的速率收集大量数据,这是由于它们引入的潜在热点。
另一方面,对于聚集索引和非聚集索引,唯一的标识符很少是一个好的选择。使用NEWID()函数生成的随机值极大地增加了索引碎片。此外,惟一标识符上的索引会降低批处理操作的性能。让我们看一个示例并创建两个表:一个表在标识列上具有聚集索引,另一个表在唯一的标识符列上具有聚集索引。下一步,我们将在两个表中插入65,536行。您可以在清单7-4中看到执行此操作的代码。
清单7 - 4.唯一的标识符:表创建
create table dbo.IdentityCI
(
ID int not null identity(,),
Val int not null,
Placeholder char() null
);
create unique clustered index IDX_IdentityCI_ID
on dbo.IdentityCI(ID);
create table dbo.UniqueidentifierCI
(
ID uniqueidentifier not null
constraint DEF_UniqueidentifierCI_ID
default newid(),
Val int not null,
Placeholder char() null,
);
create unique clustered index IDX_UniqueidentifierCI_ID
on dbo.UniqueidentifierCI(ID)
go
;with N1(C) as (select union all select ) -- rows
,N2(C) as (select from N1 as T1 cross join N1 as T2) -- rows
,N3(C) as (select from N2 as T1 cross join N2 as T2) -- rows
,N4(C) as (select from N3 as T1 cross join N3 as T2) -- rows
,N5(C) as (select from N4 as T1 cross join N4 as T2) -- , rows
,IDs(ID) as (select row_number() over (order by (select null)) from N5)
insert into dbo.IdentityCI(Val)
select ID from IDs;
;with N1(C) as (select union all select ) -- rows
,N2(C) as (select from N1 as T1 cross join N1 as T2) -- rows
,N3(C) as (select from N2 as T1 cross join N2 as T2) -- rows
,N4(C) as (select from N3 as T1 cross join N3 as T2) -- rows
,N5(C) as (select from N4 as T1 cross join N4 as T2) -- , rows
,IDs(ID) as (select row_number() over (order by (select null)) from N5)
insert into dbo.UniqueidentifierCI(Val)
select ID from IDs;
我的计算机上的执行时间和读取次数如表7-1所示。图7-3显示了这两个查询的执行计划。
表7 - 1.将数据插入表中:执行统计信息
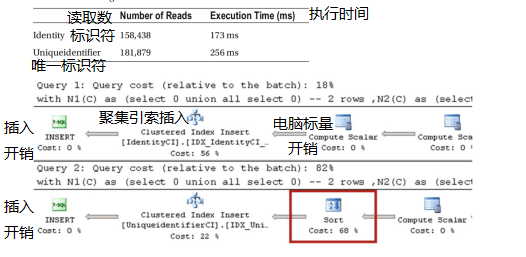
图7-3.将数据插入表:执行计划
如您所见,在唯一的标识符列上的索引的情况下,还有另一个排序操作符。SQL Server在插入之前对随机生成的唯一的标识符值进行排序,这会降低查询的性能。
让我们向表中插入另一批行并检查索引碎片。执行此操作的代码如清单7-5所示。图7-4显示了查询的结果
清单7 - 5.惟一标识符:插入行并检查碎片
;with N1(C) as (select union all select ) -- rows
,N2(C) as (select from N1 as T1 cross join N1 as T2) -- rows
,N3(C) as (select from N2 as T1 cross join N2 as T2) -- rows
,N4(C) as (select from N3 as T1 cross join N3 as T2) -- rows
,N5(C) as (select from N4 as T1 cross join N4 as T2) -- , rows
,IDs(ID) as (select row_number() over (order by (select null)) from N5)
insert into dbo.IdentityCI(Val)
select ID from IDs;
;with N1(C) as (select union all select ) -- rows
,N2(C) as (select from N1 as T1 cross join N1 as T2) -- rows
,N3(C) as (select from N2 as T1 cross join N2 as T2) -- rows
,N4(C) as (select from N3 as T1 cross join N3 as T2) -- rows
,N5(C) as (select from N4 as T1 cross join N4 as T2) -- , rows
,IDs(ID) as (select row_number() over (order by (select null)) from N5)
insert into dbo.UniqueidentifierCI(Val)
select ID from IDs;
select page_count, avg_page_space_used_in_percent, avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.IdentityCI'),,null,'DETAILED');
select page_count, avg_page_space_used_in_percent, avg_fragmentation_in_percent
from sys.dm_db_index_physical_stats(db_id(),object_id(N'dbo.UniqueidentifierCI'),,null
,'DETAILED');
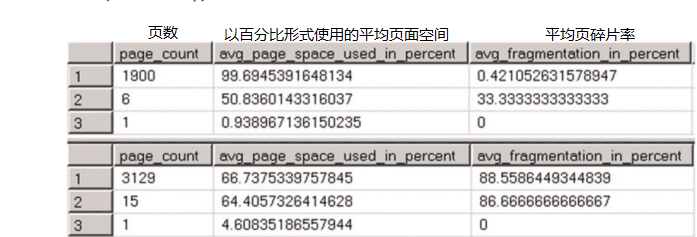
图7 - 4.索引碎片化
正如您所看到的,唯一标识符列上的索引非常分散,与标识符列上的索引相比,它使用的数据页多了大约40%。
在唯一标识符列上的索引中进行批量插入,会在数据文件的不同位置插入数据,对于大型表,这会导致大量随机物理I/O。这样会大大降低操作的效果。
个人经验
不久前,我参与了一个系统的优化,该系统有一个250GB的表,其中有一个聚集索引和三个非聚集索引。其中一个非聚集索引是唯一标识符列上的索引。通过删除这个索引,我们能够将50,000行的批插入从45秒提高到7秒。
当您希望在唯一标识符列上创建索引时,有两个常见的用例。第一个用于支持跨多个数据库的值的惟一性。考虑一个分布式系统,其中行可以插入到每个数据库中。开发人员经常使用唯一标识符来确保每个键值在系统范围内是唯一的。
这种实施方式中的关键要素是如何生成键值正如您已经看到的,NEWID()函数或客户机代码中生成的随机值会对系统性能产生负面影响。但是,您可以使用NEWSEQUENTIALID()函数,该函数生成惟一且通常不断增长的值(SQL Server会不时重置它们的基值)。
NEWSEQUENTIALID()函数生成的唯一标识符上的索引与标识符和序列列上的索引类似;但是,您应该记住,与4字节的int或8字节的长整型数据类型相比,唯一标识符数据类型使用16字节的存储空间。
作为一种替代解决方案,您可以考虑创建一个包含两列(InstallationId、Unique_Id_Within_Installation)的复合索引。这两列的组合保证了跨多个安装和数据库的唯一性,并且比惟一标识符使用更少的存储空间。您可以使用整数标识或序列来生成Unique_Id_Within_Installation值,这将减少索引的碎片。
在需要跨数据库中所有实体生成惟一键值的情况下,可以考虑跨所有实体使用单个sequence对象。这种方法满足了需求,但是使用了比惟一标识符更小的数据类型。
另一个常见的用例是安全性,其中惟一标识符值用作安全令牌或随机对象ID。不幸的是,在这个场景中不能使用NEWSEQUENTIALID()函数,因为可以猜测该函数返回的下一个值。在这个场景中,
一个可能的改进是使用CHECKSUM()函数创建一个计算列,然后索引它,而不需要在uniqueidentifier列上创建索引。代码显示在清单7-6中。
清单7-6.使用CHECKSUM():表结构
create table dbo.Articles
(
ArticleId int not null identity(,),
ExternalId uniqueidentifier not null
constraint DEF_Articles_ExternalId
default newid(),
ExternalIdCheckSum as checksum(ExternalId),
/* Other Columns */
);
create unique clustered index IDX_Articles_ArticleId
on dbo.Articles(ArticleId);
create nonclustered index IDX_Articles_ExternalIdCheckSum
on dbo.Articles(ExternalIdCheckSum);
■注意 您可以索引计算列而不需要持久化它。
尽管IDX_Articles_ExternalIdCheckSum索引将非常分散,但与惟一标识符列上的索引(4字节键与16字节键)相比,它将更加紧凑。它还提高了批处理操作的性能,因为排序速度更快,而且需要更少的内存。您必须记住的一件事是,CHECKSUM()函数的结果不一定是惟一的。应该将这两个谓词包含到查询中,如清单7-7所示。
清单7-7.使用CHECKSUM():选择数据
select ArticleId /* Other Columns */
from dbo.Articles
where checksum(@ExternalId) = ExternalIdCheckSum and ExternalId = @ExternalId
■提示 如果需要索引大于900/ 1700字节的字符串列(这是非聚集索引键的最大大小),可以使用相同的技术。即使这样的索引不支持范围扫描操作,它也可以用于点查找。

第十四周翻译-《Pro SQL Server Internals, 2nd edition》的更多相关文章
- 第十五周翻译-《Pro SQL Server Internals, 2nd edition》
<Pro SQL Server Internals, 2nd edition> 作者:Dmitri Korotkevitch 翻译:赖慧芳 译文: 55-58页 第三章 统计 SQL Se ...
- 第十二周翻译-《Pro SQL Server Internals, 2nd edition》
<Pro SQL Server Internals, 2nd edition> 作者:Dmitri Korotkevitch 翻译:赖慧芳 译文: 专业SQL服务器内部 了解在引擎盖下发生 ...
- 第十三周翻译-《Pro SQL Server Internals, 2nd edition》
<Pro SQL Server Internals, 2nd edition> 作者:Dmitri Korotkevitch 翻译:赖慧芳 译文: 聚集索引 聚集索引指示表中数据的物理顺序 ...
- 《Pro SQL Server Internals, 2nd edition》的CHAPTER 2 Tables and Indexes中的Clustered Indexes一节(翻译)
<Pro SQL Server Internals> 作者: Dmitri Korotkevitch 出版社: Apress出版年: 2016-12-29页数: 804定价: USD 59 ...
- 《Pro SQL Server Internals, 2nd edition》的CHAPTER 3 Statistics中的Introduction to SQL Server Statistics、Statistics and Execution Plans、Statistics Maintenance(译)
<Pro SQL Server Internals> 作者: Dmitri Korotkevitch 出版社: Apress出版年: 2016-12-29页数: 804定价: USD 59 ...
- 《Pro SQL Server Internals, 2nd edition》中CHAPTER 7 Designing and Tuning the Indexes中的Clustered Index Design Considerations一节(译)
<Pro SQL Server Internals> 作者: Dmitri Korotkevitch 出版社: Apress出版年: 2016-12-29页数: 804定价: USD 59 ...
- 《Pro SQL Server Internals, 2nd edition》
设计和优化索引 定义一种应用于所有地方的索引策略是不可能的.每个系统都是独特的,需要基于工作,业务需求和其他一些因素的自己的索引方法.然而,有几个设计的注意事项和指导方针可以被应用到每个系统. 在我们 ...
- 《Pro SQL Server Internals, 2nd edition》的CHAPTER 1 Data Storage Internals中的Data Pages and Data Rows(翻译)
数据页和数据行 数据库中的空间被划分为逻辑8KB的页面.这些页面是以0开始的连续编号,并且可以通过指定文件ID和页号来引用它们.页面编号都是连续的,这样当SQL Server增长数据库文件时,从文件中 ...
- 《Pro SQL Server Internals, 2nd edition》15w
第三章 统计 SQL Server查询优化器在为查询选择执行计划时使用基于成本的模型.它估计不同执行计划的成本,并选择成本最低的一个.但是,请记住,SQL Server并不搜索可用于查询的最佳执行计划 ...
随机推荐
- 压测过程中使用nmon对服务器资源的监控
1.nmon工具的下载和安装: 官网:http://nmon.sourceforge.net/pmwiki.php 下载完成后进行解压,更改权限:chmod 777 2.查看linux系统的版本,再使 ...
- spring环境搭建
1.导入jar包: 2.配置文件 — applicationContext.xml: 添加schema约束,位置:spring-framework-3.2.0.RELEASE—>docs—&g ...
- python3学习笔记
之前一直使用python2.7,最近打算学习下python3教程,再此记录下一些要点(未完待续...) 1.缩进 缩进有利有弊.好处是强迫你写出格式化的代码,但没有规定缩进是几个空格还是Tab.按照约 ...
- unity项目build成webgl时选择生成目录(解决方法)
在unity里点击File>>Build Settings...>>勾选你要生成的Scenes>>选择webgl>>后面Development Buil ...
- 同一个世界(erlang解题答案)
最近玩同一个世界,才几关就把3次提示用完了,十分气愤, 于是写了程序来解~~~ o(^▽^)o 以2-1为例子,题目如下 以0代表白色,1代表黑色,抽象的就是这样的 ----------------- ...
- SpringBoot整合Mybatis注解版---update出现org.apache.ibatis.binding.BindingException: Parameter 'XXX' not found. Available parameters are [arg1, arg0, param1, param2]
SpringBoot整合Mybatis注解版---update时出现的问题 问题描述: 1.sql建表语句 DROP TABLE IF EXISTS `department`; CREATE TABL ...
- robot_framework环境搭建
1.python安装(必须是python2) 下载地址:https://www.python.org/ 2.setuptools安装 下载地址:https://pypi.python.org/pypi ...
- ashx导出dataTable为Excel
一,datatable导出Excel,用户可以选择路径,方法如下: /// <summary> /// DataTable导出到Excel /// </summary> /// ...
- sqlserver isnull函数
isnull(参数1,参数2),判断参数1是否为NULL,如果是,返回参数2,否则返回参数1. select ISNULL(null,'helloword') 返回helloword字符串select ...
- mybatis获取insert插入之后的id
一.为什么要获取insert的id 写了测试类测试插入,插入之后用select查询出来进行Assert 插入成功后,不管Select对比的结果成功还是失败,都希望删除掉测试插入的结果 二.运行环境 m ...