day20 python常用模块
认识模块
什么是模块?
常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。
但其实import加载的模块分为四个通用类别:
1 使用python编写的代码(.py文件)
2 已被编译为共享库或DLL的C或C++扩展
3 包好一组模块的包
4 使用C编写并链接到python解释器的内置模块
为何要使用模块?
如果你退出python解释器然后重新进入,那么你之前定义的函数或者变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时就通过python test.py方式去执行,此时test.py被称为脚本script。
随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理。
这时我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他的模块中,实现了功能的重复利用,
常用模块
1.collections模块
在内置数据类型(dict, list, set, tuple) 的基础上, collections 模块还提供了几个额外的数据类型:namedtuple, deque, OrderedDict, defaultdict, Counter等.
1.namedtuple 生成可以使用名字来访问元素内容的tuple
2.deque 双端队列,可以快速的从另外一侧追加和取出对象
3.OrderedDict 有序字典
4.defaultdict 带有默认值的字典
5.Counter 计数器,主要用来计数
1.namedtuple
我们知道tuple可以表示不变集合, 例如, 一个点的二维坐标就可以表示成: p=(1,2)
但是,看到(1,2)时很难看出这个tuple是用来表示一个坐标的.
这时,namedtuple就派上了用场:
from collections import namedtuple
# namedtuple('名称', [属性list])
Point = namedtuple('Point', ['x', 'y'])
p = Point(1, 2)
print(p.x, p.y) # 1 2
类似的, 如果要用坐标和半径表示一个圆,也可以用namedtuple定义:
# namedtuple('名称', [属性list])
Circle = namedtuple('Circle', ['x', 'y', 'z'])
2.deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低.
deque 是为了高效实现插入和删除操作的双向列表,适合用于队列和堆栈:
from collections import deque
q = deque(['a', 'b', 'c'])
print(q) # deque(['a', 'b', 'c'])
q.append('x') # append 从后面插入元素
print(q) # deque(['a', 'b', 'c', 'x'])
q.appendleft('y') # appendleft 从前面插入元素
print(q) # deque(['y', 'a', 'b', 'c', 'x'])
print(q.pop()) # x pop 从后面删除元素并返回被删除元素
print(q) # deque(['y', 'a', 'b', 'c'])
print(q.popleft()) # y popleft 从前面删除元素并返回被删除元素
print(q) # deque(['a', 'b', 'c'])
q.insert(2, 'xin') # 在指定位置插入元素
print(q) # deque(['a', 'b', 'xin', 'c'])
deque除了实现了list的append() 和 pop() 及 insert()方法外, 还支持 appendleft() 和 popleft() ,这样就可以非常高效的添加和删除元素.
3.OrderedDict
使用dict时,Key是无序的.在对dict做迭代时,我们无法确定Key的顺序.
如果要保持Key的顺序,可以用OrderedDict:
from collections import OrderedDict # dict 的 Key 是无序的
d = dict([('a', 1), ('b', 2), ('c', 3)])
print(d) # {'a': 1, 'c': 3, 'b': 2} # OrderedDict 的 Key 是有序的
od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
print(od) # OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注意,OrderedDict的Key会按照插入的顺序排列, 不是Key本身排序:
from collections import OrderedDict
od = OrderedDict()
od['z'] = 1
od['y'] = 2
od['x'] = 3
print(od.keys()) # 按照插入的Key的顺序返回
# odict_keys(['z', 'y', 'x'])
4.defaultdict
有如下值集合 [11,22,33,44,55,66,77,88,99,90…], 将所有大于66的值保存至字典的第一个key的值中,将小于66的值保存至第二个key的值中.
即: {‘k1’: 大于66, ‘k2’: 小于66}
values = [11, 22, 33, 44, 55, 66, 77, 88, 99, 90]
my_dict = {}
for value in values:
if value > 66:
if my_dict.has_key('k1'): # has_key() 判断字典是否有指定key
my_dict['k1'].append(value)
else:
my_dict['k1'] = [value]
else:
if my_dict.has_key('k2'):
my_dict['k2'].append(value)
else:
my_dict['k2'] = [value]
原生字典解决方法
from collections import defaultdict values = [11, 22, 33,44,55,66,77,88,99,90] my_dict = defaultdict(list) # 指定字典的默认值为列表 for value in values:
if value > 66:
my_dict['k1'].append(value)
else:
my_dict['k2'].append(value)
defaultdict字典解决方法
使用dict时, 如果引用的Key 不存在,就会抛出 KeyError. 如果希望Key不存在时,返回一个默认值,就可以使用defaultdict:
5.Counter
Counter类的目的是用来跟踪值出现的次数. 它是一个无序的容器类型, 以字典的键值对形式存储,其中元素作为key,其计数作为value. 计数值可以使任意的Interger(包括0和负数). Counter类和其他语言的bags 或 multisets 很相似.
from collections import Counter
c = Counter('abcdeabcdabcaba')
print(c) # Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
2.时间模块(time)
和时间有关系的我们就要用到时间模块.在使用模块之前,应该首先导入这个模块.
# 常用方法
1. time.sleep(secs) # (线程)推迟指定的时间运行,单位为秒
2. time.time() # 获取当前时间戳
表示时间的三种方式
在Python中, 通常有这三种方式来表示时间:时间戳,元组(struct_time), 格式化的时间字符串.
(1)时间戳(timestamp): 通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量. 我们运行”type(time.time())”, 返回的是float类型.
(2)格式化的时间字符串(Format String): 例如’1999-12-06’
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00-59)
%s 秒数(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53) 星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53) 星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
Python中的时间日期格式化符号
(3)元组(struct_time): struct_time元组共有9个元素(年,月,日,时,分,秒,一年中第几周,一年中第几天,是否夏令时)
| 索引(Index) | 属性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | 比如2011 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 60 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为0 |
首先,我们先导入time模块,来认识一下python中表示时间的几种格式:
# 导入时间模块
import time # 时间戳
tt = time.time()
print(tt) # 1554174559.539599 # 时间字符串
tf1 = time.strftime('%Y-%m-%d %X')
print(tf1) # 2019-04-02 11:09:19
tf2 = time.strftime('%Y-%m-%d %H-%M-%S')
print(tf2) # 2019-04-02 11-09-19 # 时间元组:localtime将一个时间戳转换为当前时区的struct_time
tl = time.localtime()
print(tl)
# time.struct_time(tm_year=2019, tm_mon=4, tm_mday=2, tm_hour=11,
# tm_min=9, tm_sec=19, tm_wday=1, tm_yday=92, tm_isdst=0)
小结:时间戳是计算机能够识别的时间; 时间字符串是人能看懂的时间; 元组则是用来操作时间的
几种时间格式之间的转换
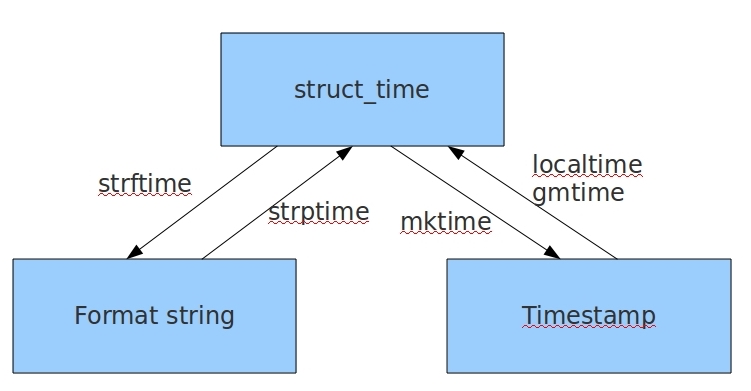
#### 时间戳(timestamp)---> 结构化时间(struct_time) ## 1. time.gmtime(时间戳) UTC时间,与英国伦敦当地时间一致
## 2. time.localtime(时间戳) 当地时间.例如我们现在在北京,执行这个方法,
# 与UTC时间相差8小时,UTC时间+8小时=北京时间 print(time.gmtime(1700000000)) # time.struct_time(tm_year=2023, tm_mon=11, tm_mday=14, tm_hour=22,
# tm_min=13, tm_sec=20, tm_wday=1, tm_yday=318, tm_isdst=0) print(time.localtime(1700000000)) # time.struct_time(tm_year=2023, tm_mon=11, tm_mday=15, tm_hour=6,
# tm_min=13, tm_sec=20, tm_wday=2, tm_yday=319, tm_isdst=0) #### 结构化时间(struct_time)--->时间戳(timestamp) ## time.mktime(struct_time) time_tuple = time.localtime(1700000000)
print(time.mktime(time_tuple)) # 1700000000.0
#### 结构化时间(struct_time)--->字符串时间(Format String)
## time.strftiem('格式定义', '结构化时间') 结构化时间参数若不传,则显示当前时间
print(time.strftime('%Y-%m-%d %X'))
# 2019-04-02 11:30:22
print(time.strftime('%Y=%m=%d', time.localtime(1700000000)))
# 2023=11=15 #### 字符串时间(Format String)--->结构化时间(struct_time)
## time.strptime(时间字符串,字符串对应格式)
print(time.strptime('2023=11=15', '%Y=%m=%d'))
#time.struct_time(tm_year=2023, tm_mon=11, tm_mday=15, tm_hour=0, tm_min=0,
# tm_sec=0, tm_wday=2, tm_yday=319, tm_isdst=-1)
print(time.strptime('07/24/2017', '%m/%d/%Y'))
# time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0,
# tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1)

# 结构化时间 ---> %a %b %d %H:%M:%S %Y 串
# time.asctime(结构化时间) 如果不传参数,直接返回当前时间的格式化串
print(time.asctime(time.localtime(1700000000)))
# Wed Nov 15 06:13:20 2023
print(time.asctime())
# Tue Apr 2 11:40:48 2019 # 时间戳 ---> %a %b %d %H:%M:%S %Y 串
# time.ctime(时间戳) 如果不传参数,直接返回当前时间的格式化串
print(time.ctime())
# Tue Apr 2 11:42:15 2019
print(time.ctime(1700000000))
# Wed Nov 15 06:13:20 2023
import time
true_time=time.mktime(time.strptime('2017-09-11 08:30:00','%Y-%m-%d %H:%M:%S'))
time_now=time.mktime(time.strptime('2017-09-12 11:00:00','%Y-%m-%d %H:%M:%S'))
# time.strptime() 将字符串时间转换为结构化时间
# time.mktime() 将结构化时间转换为时间戳
dif_time=time_now-true_time
struct_time=time.gmtime(dif_time)
print('过去了%d年%d月%d天%d小时%d分钟%d秒'%(struct_time.tm_year-1970,struct_time.tm_mon-1,
struct_time.tm_mday-1,struct_time.tm_hour,
struct_time.tm_min,struct_time.tm_sec))
# 时间戳是从1970年1月1日零点开始的,所以计算时要减去相应的值
计算时间差例子
3.random模块
import random # 随机小数
random.random() # 大于0且小于1之间的小数
random.uniform(1, 3) # 大于1且小于3的小数 # 随机整数
random.randint(1, 5) # 大于等于1且小于等于5之间的整数
random.randrange(1, 10, 2) # 大于等于1且小于10之间的奇数 #随机返回
random.choice([1, '', [4, 5]]) # 随机选择一个返回
random.sample([1, '', [4, 5]], 2) # 随机选择多个返回,返回个数为函数的第二个参数 # 打乱列表排序
item = [1, 3, 5, 7, 9]
random.shuffle(item)
练习:生成随机验证码
import random def v_code():
code = ''
for i in range(6):
num = random.randint(0, 9)
alf = chr(random.randint(65, 90))
add = random.choice([num, alf])
code = ''.join([code, str(add)])
return code print(v_code())
随机验证码
4.os模块
os模块是与操作系统交互的一个接口
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.system("bash command") 运行shell命令,直接显示
os.popen("bash command).read() 运行shell命令,获取执行结果
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.path
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
注意:os.stat(‘path/filename’) 获取文件/目录信息 的结构说明
stat 结构: st_mode: inode 保护模式
st_ino: inode 节点号。
st_dev: inode 驻留的设备。
st_nlink: inode 的链接数。
st_uid: 所有者的用户ID。
st_gid: 所有者的组ID。
st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。
st_atime: 上次访问的时间。
st_mtime: 最后一次修改的时间。
st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。
os模块的属性 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\r\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
5.sys模块
sys模块是与python解释器交互的一个接口
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1)
sys.version 获取Python解释程序的版本信息
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
import sys
try:
sys.exit(1)
except SystemExit as e:
print(e)
6.序列化模块(json, pickle, shelve)
什么叫序列化------将原本的字典,列表等内容转换成一个字符串的过程就叫序列化
比如,我们在python代码中计算的一个数据需要给另外一段程序使用,那我们怎么给?
现在我们能想到的方法就是存在文件里,然后另一个python程序再从文件里读出来。
但是我们都知道,对于文件来说是没有字典这个概念的,所以我们只能将数据转换成字典放到文件中。
你一定会问,将字典转换成一个字符串很简单,就是str(dic)就可以办到了,为什么我们还要学习序列化模块呢?
没错序列化的过程就是从dic 变成str(dic)的过程。现在你可以通过str(dic),将一个名为dic的字典转换成一个字符串,
但是你要怎么把一个字符串转换成字典呢?
聪明的你肯定想到了eval(),如果我们将一个字符串类型的字典str_dic传给eval,就会得到一个返回的字典类型了。
eval()函数十分强大,但是eval是做什么的?e官方demo解释为:将字符串str当成有效的表达式来求值并返回计算结果。
BUT!强大的函数有代价。安全性是其最大的缺点。
想象一下,如果我们从文件中读出的不是一个数据结构,而是一句"删除文件"类似的破坏性语句,那么后果实在不堪设设想。
而使用eval就要担这个风险。
所以,我们并不推荐用eval方法来进行反序列化操作(将str转换成python中的数据结构)
为什么要有序列化模块
序列化的目的
1. 以某种存储形式使自定义对象持久化
2. 将对象从一个地方传递到另一个地方
3. 使程序更具有维护性
json模块
json模块提供了四个功能:dumps, dump, loads, load
import json
dic = {'k1':'v1','k2':'v2','k3':'v3'}
str_dic = json.dumps(dic) #序列化:将一个字典转换成一个字符串
print(type(str_dic),str_dic) #<class 'str'> {"k3": "v3", "k1": "v1", "k2": "v2"}
#注意,json转换完的字符串类型的字典中的字符串是由""表示的 dic2 = json.loads(str_dic) #反序列化:将一个字符串格式的字典转换成一个字典
#注意,要用json的loads功能处理的字符串类型的字典中的字符串必须由""表示
print(type(dic2),dic2) #<class 'dict'> {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'} list_dic = [1,['a','b','c'],3,{'k1':'v1','k2':'v2'}]
str_dic = json.dumps(list_dic) #也可以处理嵌套的数据类型
print(type(str_dic),str_dic) #<class 'str'> [1, ["a", "b", "c"], 3, {"k1": "v1", "k2": "v2"}]
list_dic2 = json.loads(str_dic)
print(type(list_dic2),list_dic2) #<class 'list'> [1, ['a', 'b', 'c'], 3, {'k1': 'v1', 'k2': 'v2'}]
loads和dumps
import json
f = open('json_file','w')
dic = {'k1':'v1','k2':'v2','k3':'v3'}
json.dump(dic,f) #dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件
f.close() f = open('json_file')
dic2 = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回
f.close()
print(type(dic2),dic2)
load和dump
import json
f = open('file','w')
json.dump({'国籍':'中国'},f)
ret = json.dumps({'国籍':'中国'})
f.write(ret+'\n')
json.dump({'国籍':'美国'},f,ensure_ascii=False)
ret = json.dumps({'国籍':'美国'},ensure_ascii=False)
f.write(ret+'\n')
f.close()
ensure_ascii关键字参数
Serialize obj to a JSON formatted str.(字符串表示的json对象)
Skipkeys:默认值是False,如果dict的keys内的数据不是python的基本类型(str,unicode,int,long,float,bool,None),设置为False时,就会报TypeError的错误。此时设置成True,则会跳过这类key
ensure_ascii:,当它为True的时候,所有非ASCII码字符显示为\uXXXX序列,只需在dump时将ensure_ascii设置为False即可,此时存入json的中文即可正常显示。)
If check_circular is false, then the circular reference check for container types will be skipped and a circular reference will result in an OverflowError (or worse).
If allow_nan is false, then it will be a ValueError to serialize out of range float values (nan, inf, -inf) in strict compliance of the JSON specification, instead of using the JavaScript equivalents (NaN, Infinity, -Infinity).
indent:应该是一个非负的整型,如果是0就是顶格分行显示,如果为空就是一行最紧凑显示,否则会换行且按照indent的数值显示前面的空白分行显示,这样打印出来的json数据也叫pretty-printed json
separators:分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(‘,’,’:’);这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。
default(obj) is a function that should return a serializable version of obj or raise TypeError. The default simply raises TypeError.
sort_keys:将数据根据keys的值进行排序。
To use a custom JSONEncoder subclass (e.g. one that overrides the .default() method to serialize additional types), specify it with the cls kwarg; otherwise JSONEncoder is used.
其他参数说明
import json
data = {'username':['李华','二愣子'],'sex':'male','age':16}
json_dic2 = json.dumps(data,sort_keys=True,indent=2,separators=(',',':'),ensure_ascii=False)
print(json_dic2)
json的格式化输出
pickle 模块 与json模块的用法基本相同
json 和 pickle 模块
都是用于序列化的两个模块
json, 用于字符串 和 python数据类型间进行转换
pickle, 用于python特有的类型 和 python的数据类型间进行转换
pickle模块提供了四个功能: dumps, dump(序列化, 存); loads(反序列化, 读),load(不仅可以序列化字典,列表…可以把python中任意的数据类型序列化)
import pickle
dic = {'k1':'v1','k2':'v2','k3':'v3'}
str_dic = pickle.dumps(dic)
print(str_dic) #一串二进制内容 dic2 = pickle.loads(str_dic)
print(dic2) #字典 import time
struct_time = time.localtime(1000000000)
print(struct_time)
f = open('pickle_file','wb')
pickle.dump(struct_time,f)
f.close() f = open('pickle_file','rb')
struct_time2 = pickle.load(f)
print(struct_time2.tm_year)
pickle
json是一种所有的语言都可以识别的数据结构.
所以,如果你序列化的是列表或者字典,推荐使用 json 模块
如果是要序列化其他的数据类型,而未来你还会用python对这个数据进行反序列化的话,就可以使用 pickle 模块.
day20 python常用模块的更多相关文章
- Python常用模块之sys
Python常用模块之sys sys模块提供了一系列有关Python运行环境的变量和函数. 常见用法 sys.argv 可以用sys.argv获取当前正在执行的命令行参数的参数列表(list). 变量 ...
- Python常用模块中常用内置函数的具体介绍
Python作为计算机语言中常用的语言,它具有十分强大的功能,但是你知道Python常用模块I的内置模块中常用内置函数都包括哪些具体的函数吗?以下的文章就是对Python常用模块I的内置模块的常用内置 ...
- python——常用模块2
python--常用模块2 1 logging模块 1.1 函数式简单配置 import logging logging.debug("debug message") loggin ...
- python——常用模块
python--常用模块 1 什么是模块: 模块就是py文件 2 import time #导入时间模块 在Python中,通常有这三种方式来表示时间:时间戳.元组(struct_time).格式化的 ...
- Python常用模块——目录
Python常用模块学习 Python模块和包 Python常用模块time & datetime &random 模块 Python常用模块os & sys & sh ...
- python 常用模块之random,os,sys 模块
python 常用模块random,os,sys 模块 python全栈开发OS模块,Random模块,sys模块 OS模块 os模块是与操作系统交互的一个接口,常见的函数以及用法见一下代码: #OS ...
- python常用模块之时间模块
python常用模块之时间模块 python全栈开发时间模块 上次的博客link:http://futuretechx.com/python-collections/ 接着上次的继续学习: 时间模块 ...
- python常用模块之subprocess
python常用模块之subprocess python2有个模块commands,执行命令的模块,在python3中已经废弃,使用subprocess模块来替代commands. 介绍一下:comm ...
- python常用模块之string
python常用模块string模块,该模块可以帮我们获取字母.数字.特殊符号. import string #打印所有的小写字母 print(string.ascii_lowercase) #打印所 ...
随机推荐
- 【SQL】sql语句在insert一条记录后返回该记录的ID
insert into test(name,age) values(') SELECT @@IDENTITY test是表名 重点是这句SELECT @@IDENTITY
- JAVA时间工具类,在维护的项目里的
package com.inspur.jobSchedule.util; import org.apache.commons.lang3.time.DateUtils; import org.apac ...
- 认识vim 编辑器
vim编辑器 vim编辑器的重点是光标的移动,模式切换,删除,查找,替换,复制,撤销命令的使用. vim 有三种模式: 命令模式,编辑模式,末行模式 vim打开方式: 语法: vim 文件路径 vim ...
- GMA Round 1 新年的复数
传送门 新年的复数 已知$\left\{\begin{matrix}A>B>0\\ AB=1\\ (A+B)(A-B)=2\sqrt{3}\end{matrix}\right.$ 求$(A ...
- laravel之构造器操作数据库
使用构造器来查询的优点是可以方式sql注入 1.插入 2.修改数据库 3.删除 4.查询
- cadence单一原理图库的设计
- react-webpack config webpack@3.4.1
1.最重要的一点 yarn add webpack@3.4.1 -g 2. 解决跨域请求 webpack.json 中添加 https://segmentfault.com/q/1010000008 ...
- mysql - Truncated incorrect DOUBLE value: 'undefined'
mysql - Truncated incorrect DOUBLE value: 'undefined' 我是怎么遇到这个问题的? 我要从多个表里,查询统计数据,保存到统计表里,需要执行下面这种结构 ...
- 终于明白了 C# 中 Task.Yield 的用途
最近在阅读 .NET Threadpool starvation, and how queuing makes it worse 这篇博文时发现文中代码中的一种 Task 用法之前从未见过,在网上看了 ...
- Android手机camera和IMU的标定
https://qingsimon.github.io/post/2018-12-28-android%E6%89%8B%E6%9C%BA%E7%9B%B8camera%E5%92%8Cimu%E7% ...