分布式协调服务Zookeeper扫盲篇
分布式协调服务Zookeeper扫盲篇
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
身为运维工程师对kubernetes(k8s)可能比较熟,那么etcd(go语言实现)分布式协调服务应该也有一定的了解吧。在大数据领域中,也有一个分布式协调工具基本上可以和zookeeper分庭抗礼,他就是我们今天要说的zookeeper。
在分布式系统中,服务(或组件)之间的协调是非常重要的,它构成了分布式系统的基础。分布式系统中的leader选举,分布式锁,分布式队列等,均需要通过协调服务(Coordination Service)实现。然而,由于分布式环境的复杂性,尤其是在网络故障,死锁,竞争等已变为常见现象的情况下,实现一个鲁棒的协调服务是极为困难的事情。为了实现一个通用的分布式文件协调服务,避免每个分布式系统从头实现造成不必要的工作冗余,Hadoop生态系统提供了Zookeeper。
Zookeeper通过引入类似于文件系统的层级命名空间,并在此基础上提供了一套简单的易用的原语,能够帮助用户轻易地实现前面提到leader选举,分布式锁,分布式队列等功能。zookeeper已被大量开源系统采用,包括HDFS(leader选举问题),YARN(leader选举问题),HBase(leader选举和分布式锁等)等。
一.Zookeeper概述
1>.zookeeper诞生背景
zookeeper是一款分布式协同管理框架,是Google Ghubby的开源实现,主要用于解决分布式应用中经常会遇到的一些问题。
zookeeper自身拥有很高度的可靠性,可扩展性和容错性,能提供统一命名服务,分布式锁,分布式队列,选举,配置同步,心跳检查等功能。有了zookeeper的帮助,开发实现一个分布式系统就会显得容易很多。像HBase,Kafka,SorlColoud等众多知名框架都是使用zookeeper实现分布式协同管理的。
zookeeper的逻辑架构也是一个典型的主从架构,它和众多Server服务中通过选举产生一个主控节点。
2>.zookeeper核心特性
zookeeper的目标是基于自身去构建更为复杂的分布式应用场景,例如分布式数据库,分布式消息系统和分布式搜索引擎这类实时性要求很高的系统,所以它自身被设计的非常快速,非常简单。同时,为了能够支撑分布式场景下食物的一致性,zookeeper提供了一些核心特性: 顺序一致性:
客户端发送的更新请求将按照发送的顺序进行执行。 原子性:
更新操作只会有更新成功或更新失败两种状态,不会存在其他状态。 单一系统视图:
客户端链接到任意的服务器都将看到相同的数据视图。 可靠性:
一旦一个更新动作被执行,所有的服务都见给执行这个更新动作。 及时性:
客户端看到的视图在一定时间内保证是最新的。
3>.原子消息广播协议
ZAB(Zookeeper Atomic Broadcast)是一种数据分布式一致性算法,是Paxos算法的简化版本。可以说ZAB是zookeeper立足的根本。在说ZAB协议之前,我们先简单回顾一下分布式一致性的发展历史。 一.两阶段提交协议
在单机数据库时代,我们没有分布式数据一致性的问题的困扰。通过数据库事物我们就能轻松达成ACID的特性从而保证数据的一致性。
但是当我们进入分布式时代对时候,单机事务就显得力不从心了。在分布式服务的场景下,我们会有多个物理上独立的数据库分布在不同的服务器。从单机的视角来看,每个独立的数据库内部都能通过单机事务保证数据的一致性,但是如果一个操作同时涉及到多个独立数据库的时候,就会出现数据不一致的情况。
于是人们设计了一个名叫两阶段提交(Two-PhaseConmmit,2PC)的协议来解决这个问题。简单的说两阶段提交就是在客户端和多个数据库之间增加了一个事务协调者,同时将事物的提交分为准备和提交两个阶段。
1>.准备阶段
事务协调者给每个数据库发送prepare消息,每个数据库要在本地执行事务,写本地的redo和undo日志,但不提交事务。大致流程如下:
(1):事务协调者节点向所有数据库询问是否可以执行提交操作,并开始等待各参与者节点的响应。
(2):数据库节点执行询问发起为止的所有事务操作,并将undo信息和redo信息写入日志。
(3):数据库节点响应事务协调者节点发起的询问。如果数据库节点的事务操作实际执行成功,则返回一个“同意”消息;如果数据库节点的事务操作实际执行成功,则返回一个“同意”消息;如果数据库节点的事务操作执行失败,则返回一个“中指”的消息。
2>.提交阶段
如果事务协调者收到了数据库的中止消息或者等待超时,则直接给每个数据库发送rollback消息,要求进行回滚操作;如果事务协调者收到了数据库的同意消息,则发送commit消息,要求进行提交操作。执行完毕之后,释放所有事务处理过程中使用的资源。大致流程如下:
(1):事务协调者节点向所有数据库发起“commit/rollback”请求,并开始等待各参与者节点的响应。
(2):数据库节点执行“commit/rollback”动作并释放事务占用的资源,之后向事务协调者发送完成消息。
(3):事务协调者收到所有数据库的反馈消息后完成或取消事务。
两阶段提交看似解决了分布式数据一致性的问题,其实这个设计存在一个明显的问题:
(1):阻塞执行,速度慢
从刚才描述可以看出,协调者和数据库的一系列提交或回顾动作都是阻塞执行的,这必然导致整个分布式事务运行效率缓慢。
(2):单点问题
两阶段提交的核心枢纽是事务协调者节点,如果这个节点失效了,那么整个事务机制也就瘫痪了。同时由于协调这失效,回导致数据库的资源一直占有无法释放。
(3):数据不一致
试想一下,在提交阶段,当事务协调者向所有数据库发送commit请求之后,由于网络问题只是提供一部分数据库收到了请求信息并执行了commit动作,而另一部分数据库没有收到commit请求信息,多个数据库之间就会产生数据不一致的问题。 二.三阶段提交协议
为了解决两阶段提交协议的缺陷,人们又提出了一个改进版本,这就是三阶段条协议(Three-PhaseCommit ,3PC)。将协调者和数据库都引入超时机制,以解除咋就协调者失效的时候,数据库回一直占有资源无法释放的问题,同时又将准备阶段拆分成了询问和准备两个阶段以增加容错概率。
1>.询问阶段
事务协调者给每个数据库发送CanCommit请求,每个数据库如果可以提交就返回YES消息,否则就返回NO消息。大致流出如下:
(1):事务协调者节点向所有数据库发起CanCommit请求,并开始等待各参与者节点的响应。
(2):数据库节点收到CanCommit请求之后如果可以提交,则返回YES消息并进入准备阶段。否则返回NO消息。
2>.准备阶段
事务协调者收到反馈后会有两种情况产生,如下所示。
数据库返回的消息均为YES消息,则执行预执行。大致流程如下:
(1):事务协调者节点向所有数据库发起PreCommit请求,并开始等待各参与者节点的响应。
(2):数据库节点执行到询问发起为止的所有事物操作,并将undo信息和redo信息写入日志。执行成功后返回ACK应答,并进入等待。
数据库返回的消息含有NO消息或者等待超时,则执行事务中断。大致流程如下:
(1):事务协调者节点向所有的数据库发起abort中断请求。
(2):数据库节点收到abort请求之后,执行事务中断。如果在超时之后还没有收到事务协调者的任何消息,也执行事务中断动作。
3>.提交阶段
事务协调者收到反馈后会有两种情况产生。
协调者收到所有ACK应答,则执行事务提交,大致流程如下:
(1):事务协调者节点下个所有数据库发起DoCommit请求,并开始等待各参与者节点的响应。
(2):数据库节点执行commit动作并释放事务占用的资源,之后向事务协议者发送ACK消息应答。
(3):事务协调者收到所有数据库的反馈消息后完成事务。
协调者没有收到所有ACK应答,则执行事务中断,大致流程如下:
(1):事务协调者节点向所有数据库发起abort中断请求。
(2):数据库节点收到abort请求之后执行事务回滚,并向事务协调者发送ACK消息应答。
(3):事务协调者说到所有数据库反馈消息后完成事务中断。 从三阶段提交的流出来看,已经解决了两阶段提交中的一些问题,但还是会出现数据不一致但问题。因为在进行第三阶段也就是提交阶段,如果数据在超时钱没有收到DoCommit或abort消息,那么它最终会执行commit动作。
试想一下,如果在提交阶段事务协调者没有收到ACK应答,那么它会发送abort中断事务的请求。碰巧这个时候网络发生了抖动导致一部分数据库没有收到abort消息,那么收到消息的数据库会执行事务中断,而没有收到abort消息的数据库最终执行commit动作,这就导致数据不一致了。 三.Paxos协议
为了完美解决分布式场景下数据一致性的问题,Paxos算法诞生了。Paxos算法原文十分难以理解,由于篇幅有限,这里主要是通过作者Leslie Lamport另一篇相对简单的论文《Paxos Mode Simple》来进行简单描述。具体的内容可以看Poxos Mode Simple论文的全文。
假设有一组可以提出提案的进程集合,提案用【编号,值】的形式来进行描述,一致性算法需要保证以下几点:
(1):只有当一个提案被提出后才能会被选定。
(2):这些进程集合中只有一个提案会被选定。
(3):如果某个进程认为某个提案被选定了,那么这个提案确实是已经被选定了。
该一致性算法分为三个角色,我们用proposer,acceptor和leader来表示。proposer可以批准提案,acceptor可以提交提案,而leader只能获取已经被批准的提案。
1>.阶段一
(1):proposer选择一个提交编号n,然后向超过半数的acceptor发送编号n的proposer请求。
(2):如果一个acceptor收到了一个编号为n的prepare请求,并且编号n大于这个acceptor之前已经响应的prepare请求的编号,那么它会将已经批准过的最大编号的提案作为响应发送给proposer,并且承诺不会在批准任何编号小于n的提案。
2>.阶段二
(1):如果proposer收到了半数以上的acceptor对编号n的propare请求的回应,那么它会会发送一个针对[n,v]提案的accept请求答谢acceptor。这里的v的值就是收到响应的编号最大提案的值。
(2):如果accept收到这个针对[n.v]提案的accept请求,只要该acceptor还没有对编号大于n提案进行响应,它就会通过这个提案。
Paxos通过引入过半提交的概念解决了在两个阶段和三阶段提交中会出现的种种问题。正如Chubby的作者Mike Burrows所说的那样,这个世界上只有一种分布式一致性算法,那就是Paxos。 四.ZAB协议
Paxos算法理论上虽然完美,但是实现起来太过复杂,因为它的目标是构建一个去中心化的,通过的分布式一致性算法。而且Paxos算法只在乎数据的一致性而不关心事务请求的顺序,这一点并不难满足Zookeeper的要求。
因为ZOokeeper的命名空间是一个树形结构,对执行的顺序有严格的要求,于是zookeeper借助了了Paxos过半提交的思想将两阶段提交进行优化改造,ZAB就这样诞生了。ZAB协议中有三种角色:
(1):Leader
所有的写请求首先都会转发到Leader节点上,Leader节点上的数据变更会同步到集群的Follower节点上。
(2):Follower
负责同步Leader姐弟啊你的数据,并提供数据的查询能力。当Leader节点失效的时候有权利参与投票选举。
(3):Observer
同步Leader节点的数据,并提供数据的查询功能。没有投票选举,Observer的设计目的是提高集群的查询能力。 和Paxos有所不同,ZAB并不是一个无中心话的架构,在任意时刻ZAB都保持有且仅有一个Leader节点,所有的更新事务都只能由这个Leader发起。并且当一个Leader失效以后,新的Leader只有在之前Leader的事务都被处理之后才能发起新的事务。通过这种机制,ZAB协议保证了全局的事务顺序。在更新阶段ZAB使用的就是一个优化过的两阶段提交,这里借助了Paxos的思想,只要过半的节点prepare成功,就会发起commit请求。
如果想查看ZAB完整协议内容可以定于它的论文:《Zab:High-performance broadcast for primary-backup systems》,链接地址为:https://www.semanticscholar.org/paper/Zab%3A-High-performance-broadcast-for-primary-backup-Junqueira-Reed/b02c6b00bd5dbdbd951fddb00b906c82fa80f0b3
ACID是Atomic(原子性),Consistency(一致性),Isolation(隔离性)和Durability(持久性)的英文缩写。 原子性:
将一组操作视为一个原子操作,操作要么全部执行,要么全部不执行。 一致性:
一个事务在执行之前和执行之后数据库都必须处在一个一致性的状态。 隔离性:
不同事务之间是相互隔离的。 持久性:
一但一个事务被提交,它对数据库中对数据改变应该是永久性对。
ACID知识扩展
二.分布式协调服务的存在意义
分布式协调服务是分布式应用中不可缺少的,通常担任协调者的角色,比如leader选举,负载均衡,服务发现,分布式队列和分布式锁等,接下来以leader选举和负载均衡为例,说明分布式协调服务的存在意义及基本职责。
1>.leader选举
在分布式系统中,常见的一种软件设计架构为master/slave,如下图所示:
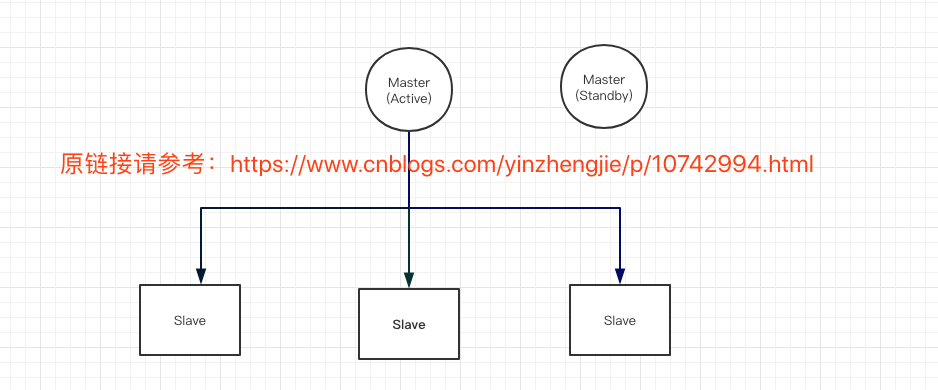
其中master负责集群管理,slave负责执行具体的任务(比如存储,处理数据),典型的服务代表有HDFS,HBase和Kudu均采用了改架构,这种模式存在一个明显的缺陷,即master单点故障。为了避免master出现故障导致整个集群不可用,常见的优化方式是引入多master,比如双master:active master和standby master,其中active master对外对接提供服务,而standby master则作为备用的master,一直处于待命的状态,一旦active master出现故障,自己则切换为active master。
引入双master需要解决如下两个难题:
1>.如何选举处一个master作为active master?不能引入不可靠的第三方组件进行选举,否则又再次引入一个存在单点故障的服务。一种常见的解决思路是实现Paxos一致性协议,让多个对等的服务通过某个方式达成一致性,从而选举处一个master。
2>.如何发现active master出现故障,如何让standby master安全切换为active master?该问题的难点在于如何避免脑裂(split-brain),即集群中同时存在两个active master,造成数据不一致或集群出现混乱的现象。
几乎所有采用master/slave架构的分布式均存在以上问题,为了避免每个分布式系统单独开发这些功能造成工作冗余,构造一个可靠的协调分布式服务势在必行。该协调服务具备leader(master)选举和服务状态获取等基本功能。
2>.负载均衡
如下图所示,在类似于Kafaka的分布式消息队列中,生产者将数据写入分布式队列,消费者从分布式消息队列中读取数据进行处理。

为了实现该功能,需要从架构上解决以下为两个问题:
>.生产者和消费者如何获知最新的消息队列位置?(消息队列是分布式的,通常由一组节点构成,这些节点的状态是动态变化的,比如某个节点因机器故障变得对外不可用,如何让生产者和消费者动态获知最新的消息队列节点是必须要解决的问题)
>.如何让生产者将数据均衡地写入消息队列中各个节点?(消息队列提供了一组可存储数据的节点,需让生产者及时了解各个存储节点的负载,以便智能决策将数据均衡的写入这些节点。) 为了解决以上两个问题,需要引入一个可靠的分布式文艺,我们可以了解到,协调服务对于一个分布式系统而言多重要。为了解决服务协调这一类通用问题,zookeeper出现了,它将服务协调的职责从分布式系统独立出来,以减少系统的耦合性和增强扩展性。
三.zookeeper的数据模型
考虑到分布式协调服务内部实现的复杂性,Zookeeper尝试尽可能简单的数据模型和API暴露给用户,以屏蔽协调服务本身的复杂性。Zookeeper提供了类似于文件系统的层级命名空间,而所有分布式协调功能均可以借助作用在该命名空间上的原语实现。在用户看来,zookeeper非常类似于分布式文件系统。
1>.层级命名空间
zookeeper允许分布式进程通过共享一个分层的命名空间来相互协同,这有点类似Linux问系统的树形目录结构。这种类型结构在zookeeper的术语成为znodes。但与Linux文件系统不同的地方在于,他没有目录和文件之分,所有节点均被称为znode。
znode可以直接挂在数据,znode也可以嵌套znode。与Linux文件系统类似,名称是以斜杠(“/”)分隔的路径元素序列,其中每一个节点都有路径标识。
如下图所示,给出了一个典型的Zookeeper层级命名空间,整个命名方式类似于文件系统,以多叉属性式组织在一起。
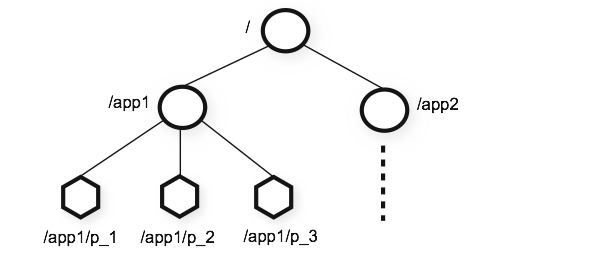
在上图中,每个节点被成为“znode”,它主要包含一下几个属性:
一.data
每个znode拥有一个数据域,记录了用户数据,该域的数据类型为字节数组。zookeeper通过多副本方式保证数据的可靠存储。 二.tpye(数据模型)
zookeeper将znode的数据保存在内存中,这是它能实现高吞吐量和低延迟性能的重要原因。为了增强可靠性,zookeeper会同时将这些数据以操作日志和快照的形式持久化到磁盘之上,以免进程重启的时候数据丢失。znode节点氛围三种类型,具体分为persistent,ephemeral,persistent_sequential和ephemeral_sequential四个基本概念。其含义如下:
>.persistent nodes:持久化节点,能够一直可靠地保存该节点(除非用户显式删除)。
>.ephemeral nodes:临时节点,该节点的生命周期与客户端相关,只要客户端保持与zookeeper server的session不断开,该节点会一直存储,反之,一旦两者之间链接断开,则该节点也将自动删除。
>.sequential nodes:自动在文件名末尾追加一个增量的唯一数字,以记录文件的创建顺序,通常与persistent和ephemeral连用,产生persistent_sequential和ephemeral_sequential两种类型。 三.version
znode中数据的版本号,每次数据的更新会导致其版本加一。 四.children
znode可以包含子节点,但由于ephemeral类型的znode与session的生命周期是绑定的,因此zookeeper不允许ephemeral znode有子节点。 五.ACL
znode访问控制列表,用户可单独设置每个znode的可访问用户列表,以保证znode被安全访问。 zookeeper能够保证数据访问的原子性,即一个znode中的数据要么写成功,要么写失败。
2>.Watcher
简单的说,zookeeper在znode上设计了多种监听事件,例如创建一个子节点,修改节点,删除节点等。我们的客户端程序可以在这些监听事件中注册自己的回调函数。注意,在zookeeper中回调函数是一次性的,这意味着一旦函数被触发,它就会被移出监听列表。如果程序需要永久的监听事件,就需要持续的进行回调函数注册动作。 zookeeper的节点监听机制是一种非常有意思的能力,利用这项能力可以在zookeeper的基础上实现很多炫酷的功能。例如: >.服务发现
微服务架构是现在很热门的一种服务架构模式,其中的服务发现功能就可以通过zookeeper实现。只需要在一个指定Znode上注册并创建子节点的监听事件,例如“/service”节点,当有新的服务上线之后便在“/service”节点下创建一个代表相应服务的子znode,这时就会触发相应的回调事件,我们的主程序就能知晓新上线的服务信息了。 >.配置同步
在分布式系统中,当服务的配置发生变动时,如何快速及时地将配置更新到各个服务器,一直都是一个十分头疼的问题,借助zookeeper的事件监听机制便能轻松实现。
首先,在zookeeper上创建一个指定的znode用于存储配置信息,例如“/app/config”节点。接着,让分布式系统中所有的服务进程监听“/app/config”节点的数据修改事件。当配置发生变化的时候,各个服务进程便会触发配置修改的回调函数,这样便能实现快速,可靠的配置同步功能了。
节点状态监听概述
Watcher是zookeeper提供的发布/订阅机制,用户可以在某个znode上注册watcher以监听它的变化,一旦对应的znode被删除或者更新(包括删除,数据域被修改,子节点发生变化等),zookeeper将以事件的形式将变化内容发送给监听者。需要注意的是,watcher一旦触发后便会被删除,除非用户再次注册该watcher。
3>.Seesion
Session是Zookeeper中的一个重要概念,它是客户端与zookeeper服务端之间的通道。同一个session中的消息是有序的。session具有容错性:如果客户端链接的zookeeper服务器宕机,客户端会自动链接到其他或者的服务器上。
四.zookeeper的基本架构
如下图所示,zookeeper服务通常由技术个zookeeper实力构成,其中一个实例为leader角色,其他为follower角色,他们同时维护了层级目录结构的一个副本,并通过ZAB(Zookeeper Atomic Broadcast)协议维持副本之间的一致性。
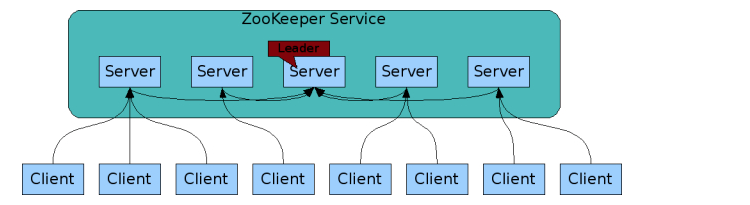
zookeeper将所有数据保存到内存中,具有吞吐率高,延迟低等优点。
当leader出现故障时,zookeeper会通过ZAB协议发起新一轮的leader投票选举,保证集群中始终有一个可用的leader。
zookeeper读写数据的路径如下:
读路径
任意一个zookeeper实例均可为客户端提供读服务,zookeeper实例数目越多,读吞吐率越高。 写路径
任意一个zookeeper实力均可接受客户端的写请求,但需进一步转发给leader协调完成分布式写。zookeeper采用了ZAB协议(可认为是一个简化版但Paxos协议),该协议规定,只要多数zookeeper实例写成功,就认为本次写是成功的。这意味着,如何一个集群中存在2N+1个zookeeper实例写成功,则本次写操作是成功的,从容错的角度看,这种情况下集群的最大容忍失败实例书是N。由于ZAB协议要求多数写成功即可返回,因此2N+1和2N+2个节点的集群具备容错能力是相同的(最大容忍是啊比实例书均为N),这是建议zookeeper部署奇数个实力的主要原因(多一个节点并没有提高容错能力)。需要注意的是,zookeeper实例数目越多,写延迟越高。
zookeeper中多个实例中的内存数据并不是强一致的,它采用的ZAB协议只能保证,同一时刻至少多少节点中的数据是强一致的。它采用的ZAB协议只能保证,同一时刻至少多少节点的数据是强一致的。为了让客户端读到最新的数据,需给对应的zookeeper实例发送同步指令(可通过调用sync接口实现),强制其它leader数据同步。
在zookeeper集群中,随着zookeeper实例数目的增多,读吞吐率升高,但写延迟增加。为了解决集群扩展性导致写性能下降的问题,zookeeper引入了第三个角色:Observer。Observer并不参与投票过程,除此之外,他的功能与follower类似:它可以接入正常的zookeeper集群,接受并处理客户端请求,或将写请求进一步转发给leader处理。由于Observer自身能够保存一份数据提供读服务,因此可通过增加Observer实例数提高系统的读吞吐率。由于Observer不参与投票过程,因此他会出现故障并不影响zookeeper集群的可用性。Observer常见应用场景如下:
1>.作为数据中心间的桥梁
2>.由于数据中心之间的确定性通信延迟,将一个zookeeper部署到两个数据中心会误报网络故障和网络分区导致zookeeper不稳定。然而,如果将整个zookeeper集群部署到单独一个集群中,另一个集群只部署Observer,则可轻易地解决网络分区问题。入下图所示:

3>.作为消息总线
4>.可将zookeeper作为一个可靠的消息总线使用,Observer作为一种天然的可插拔组件能够动态接入zookeeper集群,通过内置的发布订阅机制近实时获取新的信息。
五.Zookeeper应用案例
zookeeper作为一款强大的分布式协调系统,可以帮助分布式系统完成一些难以实现却十分重要的功能。接下来我们从原理和实现角度介绍如何使用zookeeper解决常见的分布式问题,包括leader选举,分布式队列,负载均衡等。
1>.leader选举
基于zookeeper实现leader选举的基本思想是,让各个参与竟选的实例同时在zookeeper上创建指定的znode,比如“/current/leader”,谁先创建成功则谁竟选成功,并将自己的信息(host,port等)写入该znode数据域,之后其他竞选者向该znode注册watcher,以便当前leader出现故障时,第一时间再次参与精选,如下图所示:
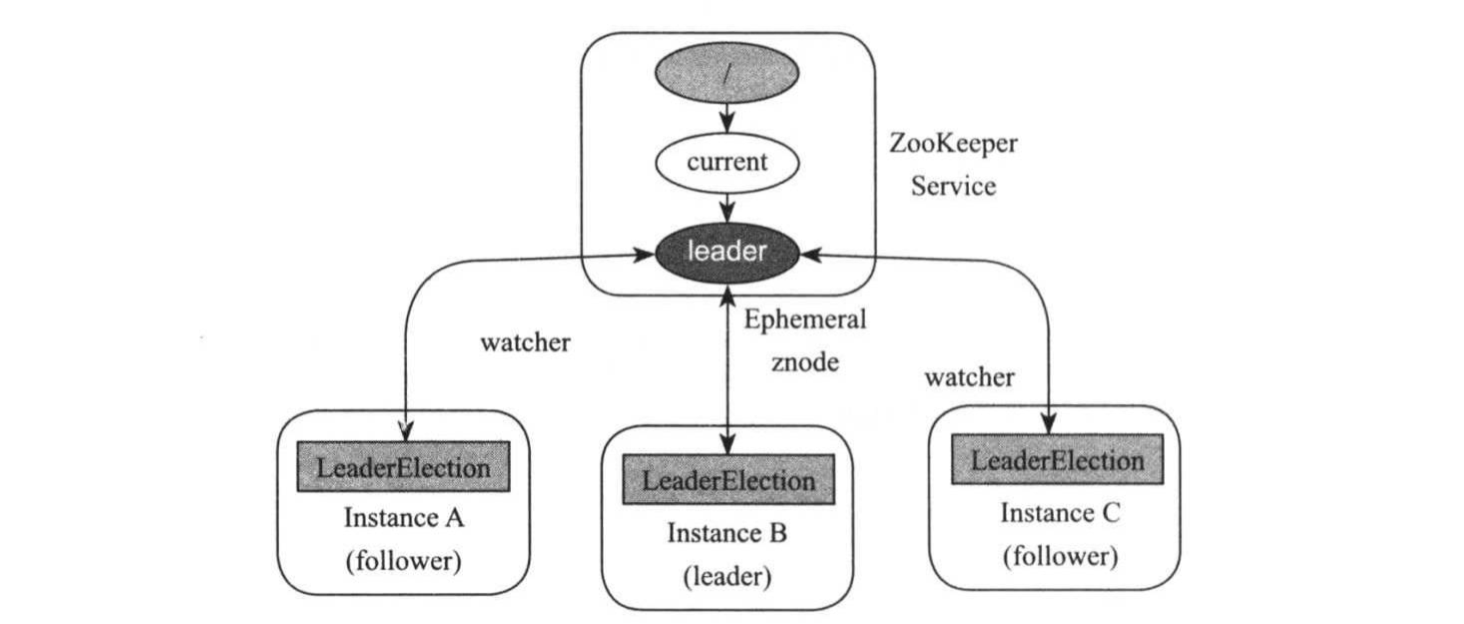
zookeeper能够保证当多个客户端同时创建一个相同路径节点当时候,只会有一个客户端成功。借用这个机制我们可以实现选举功能。因此在同一时刻,有且仅有一个客户端会成功创建节点,这个创建成功的客户端就是选举的胜利者。 基于zookeeper的leader选举流程如下:
>.各实力启动后,尝试在zookeeper上创建ephemeral类型znode节点“/current/leader”,假设实例B创建成功,则将自己的信息写入该znode,并将自己的角色标注为leader,开始执行leader相关的初始化工作。
>.除了B之外的实力得知创建znode失败,则向“/current/leader”注册watcher,并将自己角色标志为follower,开始执行follower相关的初始化工作。
>.系统正常运行,直到实例B因故障退出,此时znode节点“/current/leader”被zookeeper删除,其他follower收到节点被删除的事情,重新转入步骤1,开始新一轮选举。 Hadoop在生态系统中,HBase,YARN,HDFS等系统,采用了类似的机制解决leader选举问题。
2>.分布式队列
在分布式计算系统中,常见的做法是,用户将作业提交给系统的Master,并由Master将之分解成子任务后,调度给各个worker执行。该方法存在一个问题:Master维护了所有作业和Worker信息,一旦Master出现故障,则整个系统集群不可用。为了避免Master维护过多状态,一种改进方式将所有信息保存在zookeeper上,进而让Master变得无状态,这使得leader选举过程更加容易,典型架构如下所示:
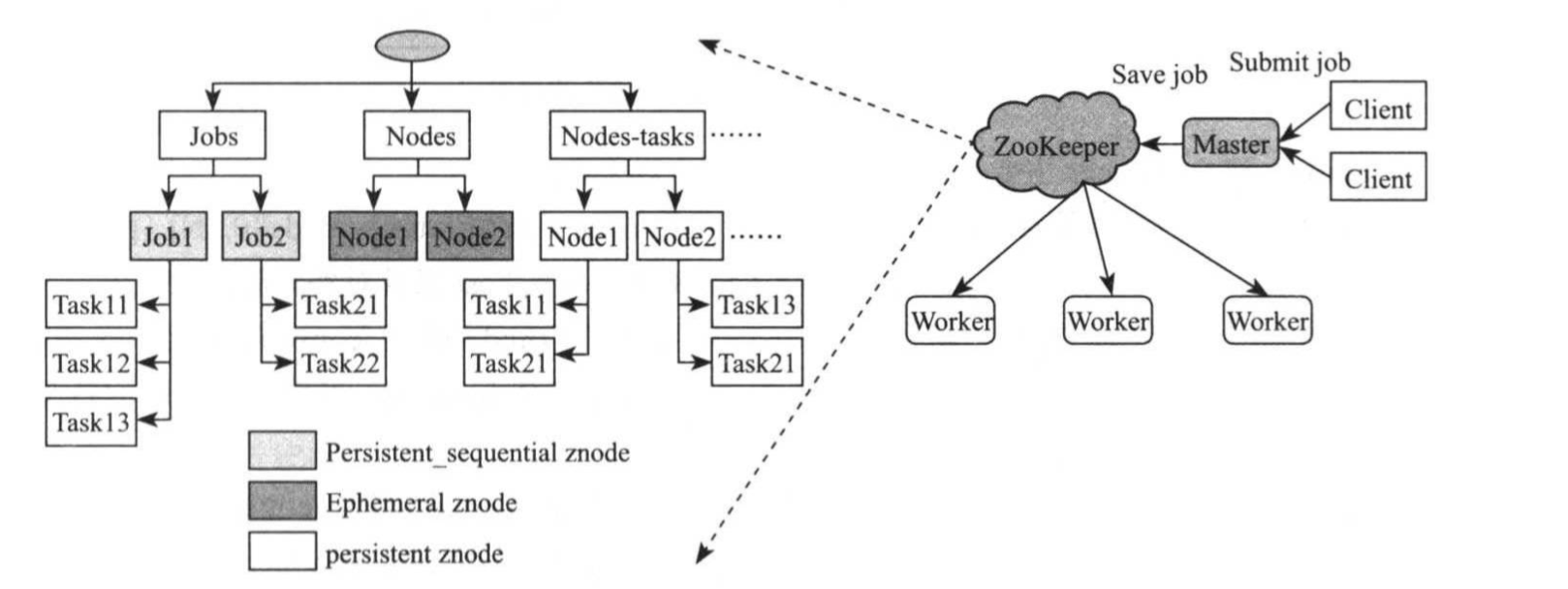
该方案的关键是借助zookeeper实现一个分布式队列,并借助zookeeper自带的特性,维护作业提交顺序,作业优先级,各节点(Worker)负载情况等。借助zookeeper的PersistentSequentialZnode自动编号特性,可轻易实现一个简易的FIFO(First In First Out)队列,在这个队列中,编号小的作业总是先于编号大的作业提交。
Hadoop生态系统中Storm便借助Zookeeper实现了分布式队列,以便可靠地保存拓扑信息和任务调度信息。
3>.负载均衡
分布式系统很容易通过zookeeper实现负载均衡,典型的应用场景是分布式消息队列,如下图所示:
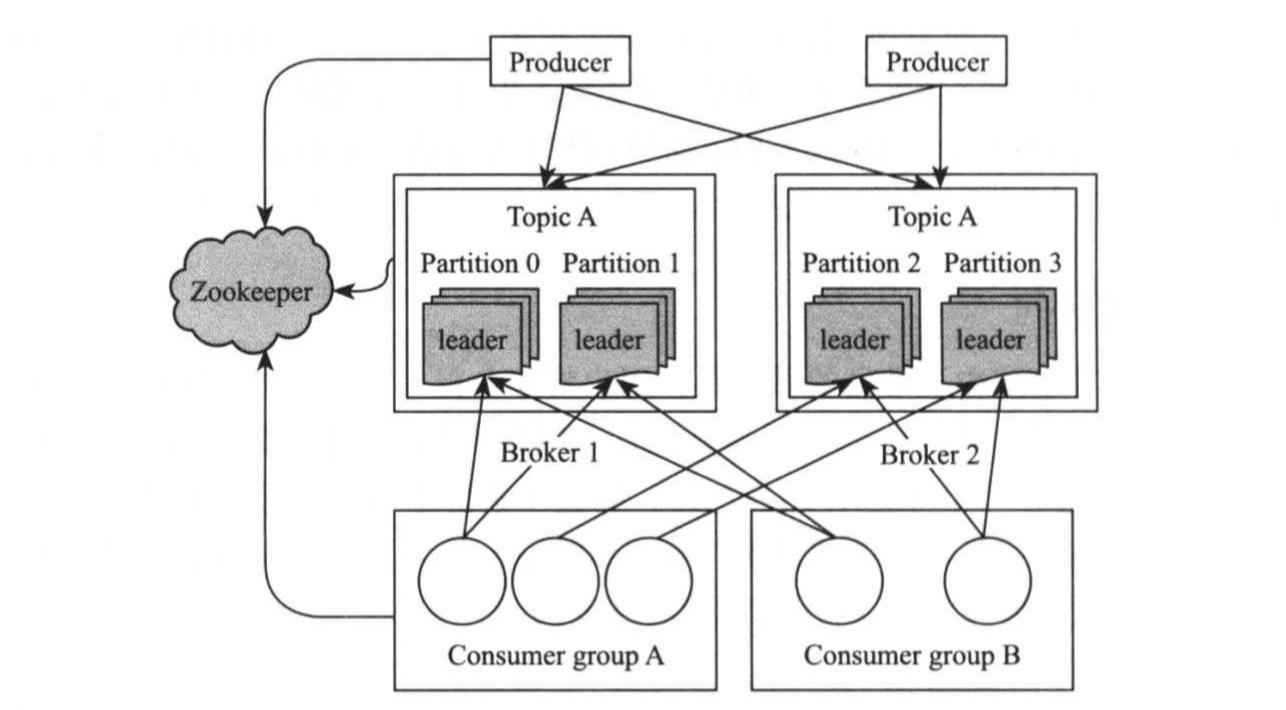
上图描述了Kafka是如何通过zookeeper解决负载均衡和服务发现问题的。在Kafka中,各个Broker和Consumer均会想zookeeper注册,保存自己的信息,组件之间可动态获取对方的信息。
Broker和Consumer主要在zookeeper中写入以下信息:
>.Broker节点注册信息
记录在ephemeral类型的znode路径“/brokers/ids/[0-N](0-N是指0到N之间的某个编号,它一般是一个证书类型,标示broker的唯一ID)”,保存了该Broker所在host以及对外开发的端口号。 >.Consumer注册信息
记录在ephemeral类型的znode路径“/consumers/[group_id]/ids/[consumer_id]”下,保存了consumer group中各个consumer当前正在读取的各个topic及对应的数据流。 >.Consumer Offset追踪信息
记录在persistent类型的znode路径“/consumers/[group_id]/offsets/[topic]/[broker_id-partitio-id]”下,保存了特定consumer group(ID为[group_id])当前读到的特定主题([topic])中特定分片([broker_id-partition_id])的偏移量值。 需要注意的是:在新kafka版本中,0.8.0及以上版本(我在生产环境使用的是0.10.2.1版本),offset的在broker中的__consumer_offsets的topic中有记录,使其自身进行维护。因此我们在使用flume的时候配置的都是broker地址直接取数据,而不需要指定zookeeper地址啦!
4>.统一命名服务
zookeeper的命名空间是一个类似于Linux文件系统的树形结构,它的每个znode都拥有唯一的路径标识符。利用这个特性分布式系统,可以将zookeeper当作统一命名服务来使用,类似于Java中的JNDI。
5>.心跳感知
利用zookeeper中znode临时节点类型的特性,可以实现心跳感知的功能。例如可以在zookeeper上创建一个根目录,如“/cluster1”。利用znode临时节点类型的特点,用以表示其绘会话状态。由于临时节点是回话绑定的,所以当节点存在的时候即代表状态正常,当进程失效的时候,节点客户端会话也会失效,这时临时节点也会被删除。这样,只查看临时节点的存活状态便能一览集群状态了。
看到这里大家应该直到zookeeper是实际生活中的主要角色了,那你知道zookeeper集群是如何选取出来leader几点的么?详情请参考:https://www.cnblogs.com/yinzhengjie/p/9154265.html。
博主推荐阅读1:https://blog.csdn.net/paincupid/article/details/78058087#Zookeeper_1782
博主推荐阅读2:https://www.cnblogs.com/mengchunchen/p/9316776.html
分布式协调服务Zookeeper扫盲篇的更多相关文章
- 分布式协调服务Zookeeper集群之ACL篇
分布式协调服务Zookeeper集群之ACL篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.zookeeper ACL相关知识概览 1>.zookeeper官方文档(h ...
- 分布式协调服务Zookeeper集群监控JMX和ZkWeb应用对比
分布式协调服务Zookeeper集群监控JMX和ZkWeb应用对比 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. JMX是用来远程监控Java应用的框架,这个也可以用来监控其他的J ...
- 分布式协调服务Zookeeper集群搭建
分布式协调服务Zookeeper集群搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.安装jdk环境 1>.操作环境 [root@node101.yinzhengjie ...
- 搞懂分布式技术3:初探分布式协调服务zookeeper
搞懂分布式技术3:初探分布式协调服务zookeeper 1.Zookeepr是什么 Zookeeper是一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现诸如数据发布/订阅,负载均衡, ...
- 分布式协调服务ZooKeeper工作原理
分布式协调服务ZooKeeper工作原理 原创 2016-02-19 杜亦舒 性能与架构 性能与架构 性能与架构 微信号 yogoup 功能介绍 网站性能提升与架构设计 大数据处理框架Hadoop.R ...
- 中小型研发团队架构实践:分布式协调服务ZooKeeper
一.ZooKeeper 是什么 Apache ZooKeeper 由 Apache Hadoop 的子项目发展而来,于 2010 年 11 月正式成为了 Apache 的顶级项目. 相关厂商内容 优秀 ...
- 分布式协调服务-Zookeeper
什么是 zookeeper? Zookeeper 是google的chubby一个开源实现,是hadoop的分布式协调服务 它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名 ...
- 1.9 分布式协调服务-Zookeeper(一)
前言 分布式环境的特点 分布性 并发性 程序运行过程中,并发性操作是很常见的.比如同一个分布式系统中的多个节点,同时访问一个共享资源.数据库.分布式存储 无序性 进程之间的消息通信,会出现顺序不一致问 ...
- 中小型研发团队架构实践八:分布式协调服务ZooKeeper
一.ZooKeeper 是什么 Apache ZooKeeper 由 Apache Hadoop 的子项目发展而来,于 2010 年 11 月正式成为了 Apache 的顶级项目. ZooKeeper ...
随机推荐
- Android launcher 壁纸 wallpaper
壁纸分为动态和静态两种: 如果只需要修改默认静态壁纸,替换frameworks/base/core/res/res/drawable/default_wallpaper.jpg即可,或者在源码中修改对 ...
- Tips on Building WebRTC on Windows
Problem: Git ask me to input git user and password Solution: Set environment variable SET DEPOT_TOOL ...
- 教你一招 | 用Python实现简易可拓展的规则引擎
做这个规则引擎的初衷是用来实现一个可序列号为json,容易拓展的条件执行引擎,用在类似工作流的场景中,最终实现的效果希望是这样的: 简单整理下需求 执行结果最终返回=true= or false 支持 ...
- 【学习记录】第一章 数据库设计-《SQL Server数据库设计和开发基础篇视频课程》
一.课程笔记 1.1 软件开发周期 (1)需求分析阶段 分析客户的业务和数据处理需求. (2)概要设计阶段 设计数据库的E-R模型图,确认需求信息的正确和完整. /* E-R图:实体-关系图(Ent ...
- 《Python 数据科学实践指南》读书笔记
文章提纲 全书总评 C01.Python 介绍 Python 版本 Python 解释器 Python 之禅 C02.Python 基础知识 基础知识 流程控制: 函数及异常 函数: 异常 字符串 获 ...
- python接口自动化-session_自动发文
一.session简介 查看 requests.session() 帮助文档(只贴了一部分内容) import requests help(requests.session()) class Sess ...
- ASP.NET Core 下的依赖注入(一)
本文介绍利用 Microsoft.Extensions.Configuration.Binder.dll 来实现超级简单的注入. 1. appsettings.json 中定义配置 假设我们有如下配置 ...
- selenium跳过webdriver检测并模拟登录淘宝
目录 简介 编写思路 使用教程 演示图片 源代码 @(文章目录) 简介 模拟登录淘宝已经不是一件新鲜的事情了,过去我曾经使用get/post方式进行爬虫,同时也加入IP代理池进行跳过检验,但随着大型网 ...
- MySQL二进预编译制安装
+++++++++++++++++++++++++++++++++++++++++++标题:MySQL二进预编译制安装时间:2019年2月25日内容:MySQL二进制预编译安装重点:MySQL二进制预 ...
- Vue中循环的反人类设计
今天学习Vue到循环那里,表示真是不能理解Vue的反人类设计 具体看代码吧! <!DOCTYPE html> <html> <head> <meta char ...