Python批量合并处理B站视频
源程序可直接到博主github上下载:https://github.com/HuerFu/bilibiliVideoMerge
最近想学习后端,又不想花钱,怎么办呢?于是在手机端B站(哔哩哔哩)上面找到了满意的免费视频教程,但是手机端看起来很不方便啊。于是,我通过在手机端缓存下来后,导入到了电脑端,但是我后面了发现两个问题:
1.本来一集视频按理说一段吧,但是B站下载下来的视频并不是完整的一段,而是被分成了多段blv格式的视频,所以需要想办法把它们拼接成完整的一段视频!
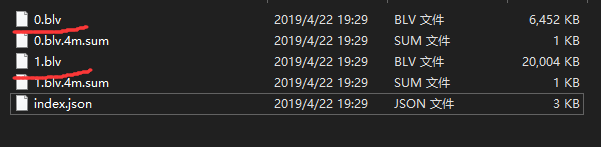
2.视频数量太大,不可能一个一个去修改,得想办法批量处理!(我这里有120个视频文件夹,下图所示,没显示完)

基于上述两个问题,必须用一种方法快速解决!网上百度查了一些资料,觉得可行性很大,于是准备自己动手写代码来实现这一功能。人生苦短,我学Python!哈哈,就是Python没错了,话不多说,直接上自己用python写的批量合并并转换B站视频格式的源代码:
#批量合并特定文件夹下的视频文件,然后输出到指定文件夹下
# 主要是需要moviepy这个库
from moviepy.editor import *
import os
from natsort import natsorted
import json # psutil是一个跨平台库能够轻松实现获取系统运行的进程和系统利用率(包括CPU、内存、磁盘、网络等)信息。它主要用来做系统监控,性能分析,进程管理。它实现了同等命令行工具提供的功能,如ps、top、lsof、netstat、ifconfig、who、df、kill、free、nice、ionice、iostat、iotop、uptime、pidof、tty、taskset、pmap等。目前支持32位和64位的Linux、Windows、OS X、FreeBSD和Sun Solaris等操作系统.
import psutil # 杀死moviepy产生的特定进程
def killProcess():
# 处理python程序在运行中出现的异常和错误
try:
# pids方法查看系统全部进程
pids = psutil.pids()
for pid in pids:
# Process方法查看单个进程
p = psutil.Process(pid)
# print('pid-%s,pname-%s' % (pid, p.name()))
# 进程名
if p.name() == 'ffmpeg-win64-v4.1.exe':
# 关闭任务 /f是强制执行,/im对应程序名
cmd = 'taskkill /f /im ffmpeg-win64-v4.1.exe 2>nul 1>null'
# python调用Shell脚本执行cmd命令
os.system(cmd)
except:
pass
if __name__ == '__main__':
#循环体
for i in range(120):
#提取对应视频标题的json文件路径
myjsondirs = './video/{}/entry.json'.format(i + 1)
#定义拼接完成后视频的标题
vdtitle = ''
with open(myjsondirs, 'r', encoding='UTF-8') as load_f:
# loads方法将json格式数据转换为字典(读取文本用此法)
load_dict = json.load(load_f)
vdtitle = load_dict['page_data']['part']
#视频文件夹路径
mydirs = './video/{}/lua.flv.bili2api.80'.format(i+1)
# 定义拼接视频的数组
L = []
# 访问 video 文件夹
# root指的是当前正在遍历的这个文件夹的本身的地址,dirs是一个 list,内容是该文件夹中所有的目录的名字(不包括子目录),files同样是 list,内容是该文件夹中所有的文件(不包括子目录)
for root, dirs, files in os.walk(mydirs):
# 按文件名排序
# files.sort()
# 自然排序法
files = natsorted(files)
# print(files)
# 遍历所有文件
for file in files:
# os.path.splitext(“文件路径”) 分离文件名与扩展名:默认返回(fname, fextension)元组,可做分片操作
# 如果后缀名为 .blv
if os.path.splitext(file)[1] == '.blv':
# .blv格式视频的完整路径
filePath = os.path.join(root, file)
# 读取视频到内存
myvideo = VideoFileClip(filePath)
# 添加到数组
L.append(myvideo)
# 对多个视频在时长上进行拼接
final_clip = concatenate_videoclips(L)
targetdir = './target/{}.mp4'.format(vdtitle)
# 法一:生成目标视频文件方法
# final_clip.to_videofile(targetdir, fps=24)
#法二:最常规的生成目标视频文件方法
final_clip.write_videofile(targetdir,fps=24, remove_temp=True) #remove_temp=True表示生成的音频文件是临时存放的,视频生成后,音频文件会自动处理掉!若为False表示,音频文件会同时生成!
print("{}---{}---拼接成功!".format(i + 1, vdtitle))
killProcess()
注意:因为moviepy拼接视频特别慢,自己电脑配置也不行,要把120个文件夹下的视频拼接完成需要很多时间!
经过一晚的运行,顺利合并了成了120个视频,结果如下:
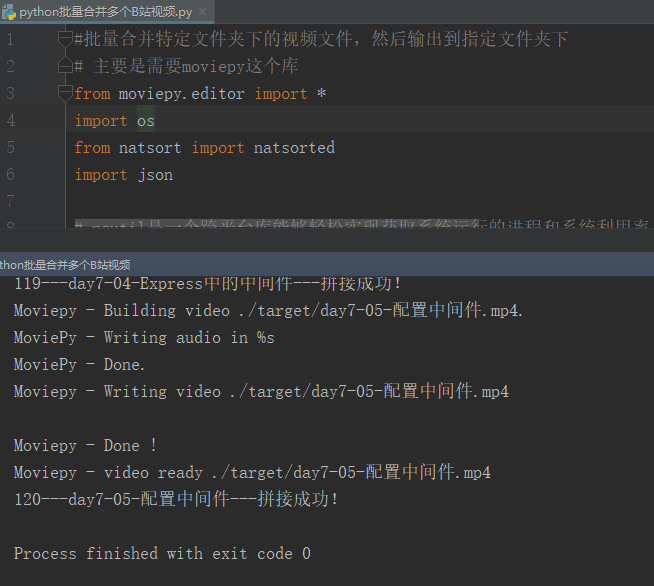

总的来说合并后的视频,画质还是不错的!
过程中遇到的一些问题:
其实我个人觉得写代码,遇到问题才是最有意思的,当把这一个一个的问题都解决掉,这种感觉才是真的nice!显然我自己在处理合并B站视频时遇到了一些问题,这里记录下来,方便自己也方便他人查阅学习!
问题1:真正拼接视频时,发现会报错 OSError: [WinError 6] 句柄无效!
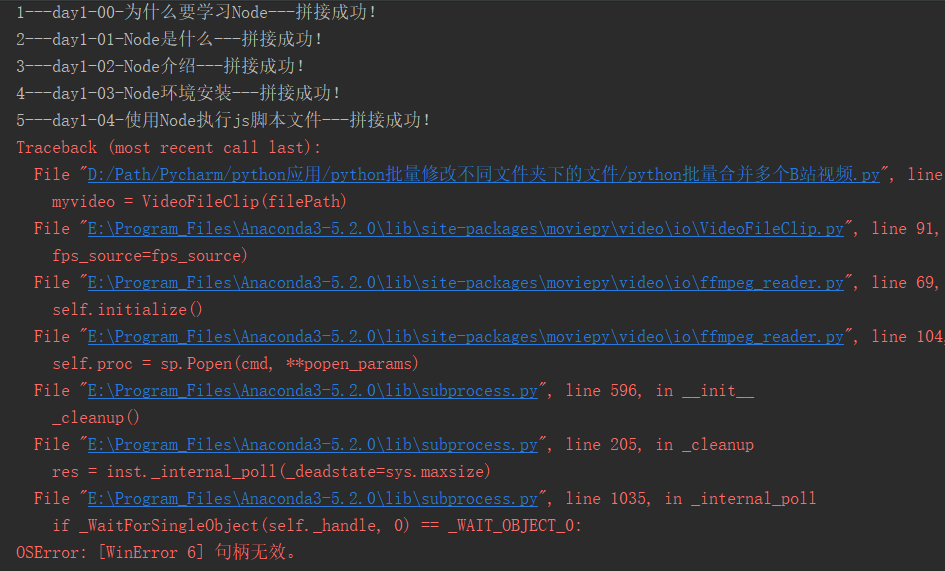
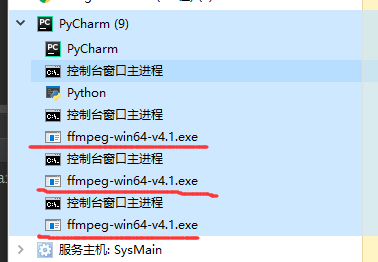
解决办法:调用自定义函数killProcess()杀死moviepy产生的特定进程!
原因:这是因为调用了moviepy的concatenate_videoclips函数,没有及时杀死进程!如果不加杀死进程的程序,循环一次,在任务管理器就会新产生一个ffmpeg-win64-v4.1.exe的进程,这个进程数量过多,windows任务管理器并不会自动杀死这些进程,而运行的python程序就会报错!所以我在程序里添加了杀死ffmpeg-win64-v4.1.exe进程的程序,这样拼接完成一个视频,就调用函数强行杀死ffmpeg-win64-v4.1.exe进程,保证pycharm里面的ffmpeg-win64-v4.1.exe进程不会无限增长下去导致程序报错!
问题2:报错 psutil._exceptions.NoSuchProcess: psutil.NoSuchProcess no process found with pid 5764
解决办法:添加try...except 处理,使python程序能够处理在运行中出现的异常和错误。
原因:没有发现指定的进程引起的程序报错!
注意:命令 cmd = 'taskkill /f /im ffmpeg-win64-v4.1.exe 2>nul 1>null',这里的2>nul:表示不输出错误信息 1>nul:表示不输出成功的信息
--------------------喜欢就点个赞呗,嘻嘻嘻----------------------
Python批量合并处理B站视频的更多相关文章
- 从0实现python批量爬取p站插画
一.本文编写缘由 很久没有写过爬虫,已经忘得差不多了.以爬取p站图片为着手点,进行爬虫复习与实践. 欢迎学习Python的小伙伴可以加我扣群86七06七945,大家一起学习讨论 二.获取网页源码 爬取 ...
- Python 自动爬取B站视频
文件名自定义(文件格式为.py),脚本内容: #!/usr/bin/env python #-*-coding:utf-8-*- import requests import random impor ...
- 使用Python批量合并PDF文件(带书签功能)
网上找了几个合并pdf的软件,发现不是很好用,一般都没有添加书签的功能. 又去找了下python合并pdf的脚本,发现也没有添加书签的功能的. 于是自己动手编写了一个小工具,使用了PyPDF2. 下面 ...
- 大学MOOC课程视频下载、流文件合并、批量重命名、b站视频下载及学习课程视频推荐
计算机行业技术更新快,编程语言种类多,在当今大数据和人工智能的时代,为了能在相关领域有所成就,就必须掌握好python.R等语言,较好的数学基础和深入的行业背景知识.计算机从业人员务必践行" ...
- Python 批量下载BiliBili视频 打包成软件
文章目录 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知识.那么针对这三类人,我给大家 ...
- [原创]Python批量操作文件,批量合并
最近几个小伙伴在手动合并一些文本文件,感觉可以用Python批量实现,就有了这段代码 import os import re import sys def printEnter(f1): #每两个文件 ...
- python 爬取B站视频弹幕信息
获取B站视频弹幕,相对来说很简单,需要用到的知识点有requests.re两个库.requests用来获得网页信息,re正则匹配获取你需要的信息,当然还有其他的方法,例如Xpath.进入你所观看的视频 ...
- 使用ffmpeg批量合并flv文件
title: 使用ffmpeg批量合并flv文件 toc: false date: 2018-10-14 16:08:19 categories: methods tags: ffmpeg flv 使 ...
- django2 用iframe标签完成 网页内嵌播放b站视频功能
前言: 给自己的网站中加入视频资源,有两种方法,一种是用iframe标签引用外站资源,另一种则使用video标签,获取站内资源进行视频播放.其中前者顾名思义,是将视频资源上传到视频网站中,然后通过引用 ...
随机推荐
- vee-validate的使用
官网地址:http://vee-validate.logaretm.com/ 这是一个插件Vue.js可以验证输入字段,显示错误,在一个简单而强大的方法.学习vee-validate,首先可以去阅读官 ...
- jenkins-参数化构建(二)插件:Extended Choice Parameter
一.Extended Choice Parameter插件 这个插件相对丰富,安装过程就不过多介绍了,在点击项目设置后会出现下载的插件名字. 写在文件中构建时效果如下:
- 输入正整数n,求各位数字和
import java.util.Scanner; /** * @author:(LiberHome) * @date:Created in 2019/3/5 10:24 * @description ...
- Python自学知识点----Day01
Linux 次方运算符** 操作系统:1).直接操纵硬件 2).将操纵硬件封装成系统调用,利用应用程序进行调用 操作系统:windows 用户群体大 macos 适用开发人员 Linux ...
- 阿里云服务器Linux CentOS安装配置(11)安装Wordpress
下载wordpress安装包 wget https://cn.wordpress.org/wordpress-4.8.1-zh_CN.zip unzip wordpress-4.8.1-zh_CN.z ...
- linux安装杀毒软件
https://www.cnblogs.com/bingo1024/p/9018212.html
- 关于JDBC的批量操作executeBatch()所引发sql语句异常
java.sql.BatchUpdateException: You have an error in your SQL syntax; check the manual that correspon ...
- django的闪现和增、删、改、查
使用 messages 闪现在views.py中导入 from django.contrib import messages 在html中 {% if messages %} {% for mess ...
- 程序员的沟通之痛https://blog.csdn.net/qq_35230695/article/details/80283720
个人理解: 一般刚工作的程序员总觉得技术最重要.但是当工作年限超过3年.或者岗位需要涉及汇报.需求对接等就会发现沟通非常重要.也许在大公司还不那么明显,但是在小公司.小团队或者创业,沟通甚至可以说是第 ...
- C语言中负数的存储方式
详细介绍负数的文章: https://blog.csdn.net/daiyutage/article/details/8575248 1.以char类型举例,其取值范围是 -128 ~ 127,即-2 ...