SQLServer之修改索引
使用SSMS数据库管理工具修改索引
使用表设计器修改索引
表设计器可以修改任何类型的索引,修改索引的步骤相同,本示例为修改唯一非聚集索引。
1、连接数据库,选择数据库,选择数据表-》右键点击表-》选择设计。
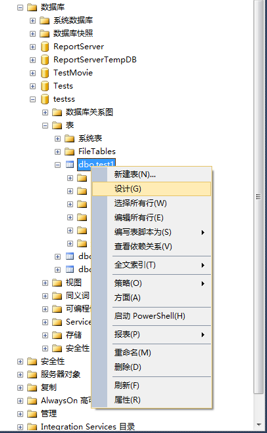
2、在表设计器窗口-》选择要修改的数据列-》右键点击-》选择要修改的索引类型。
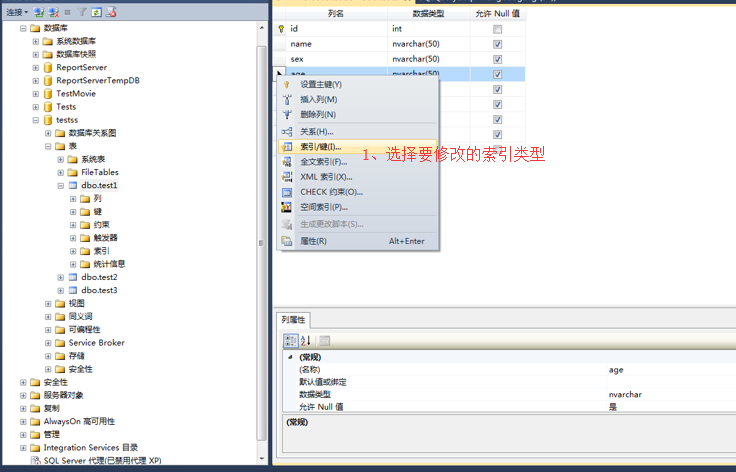
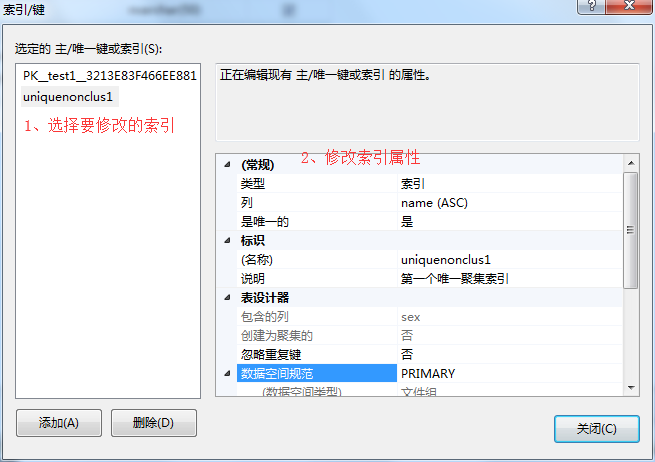
3、在弹出框中-》选择要修改的索引-》找到要修改的索引属性进行修改-》修改完成点击关闭。
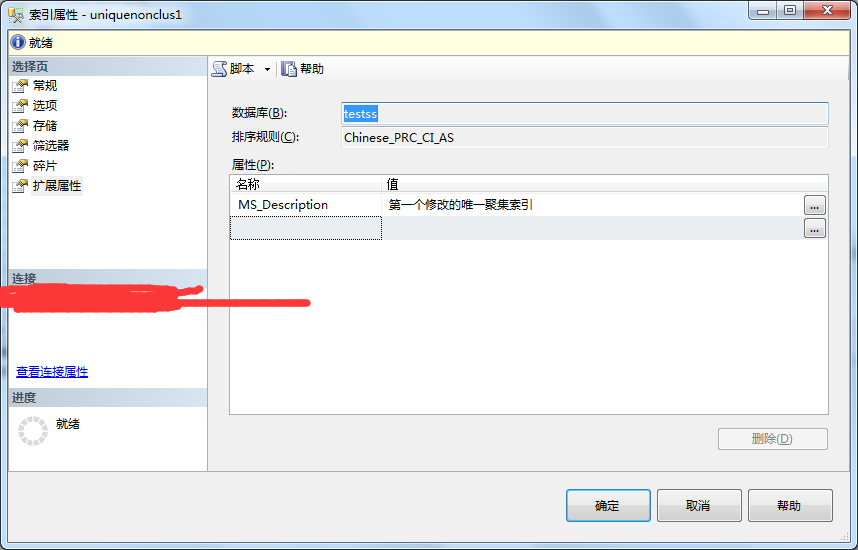
4、点击保存按钮或者ctrl+s》关闭表设计器-》刷新表-》查看结果。
使用对象资源管理器修改索引
1、连接数据库,选择数据库,选择数据表-》展开数据表-》展开索引-》选择要修改的索引-》右键点击-》选择属性(如果展开索引以后不能选择属性,刷新数据库和数据表重新尝试)。
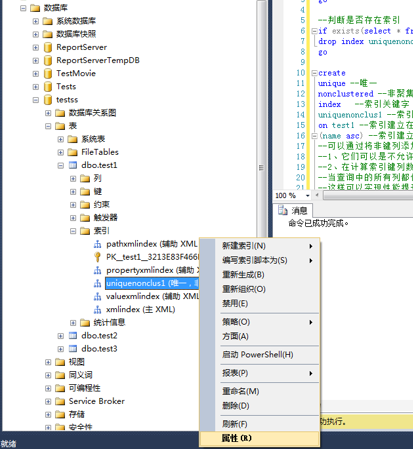
2、在索引属性弹出框-》选择你要修改的属性-》修改完成点击确定。
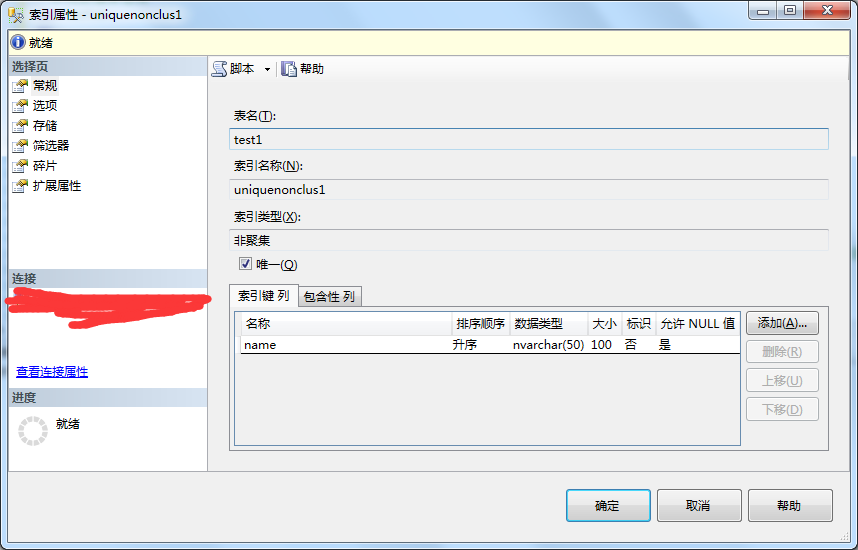
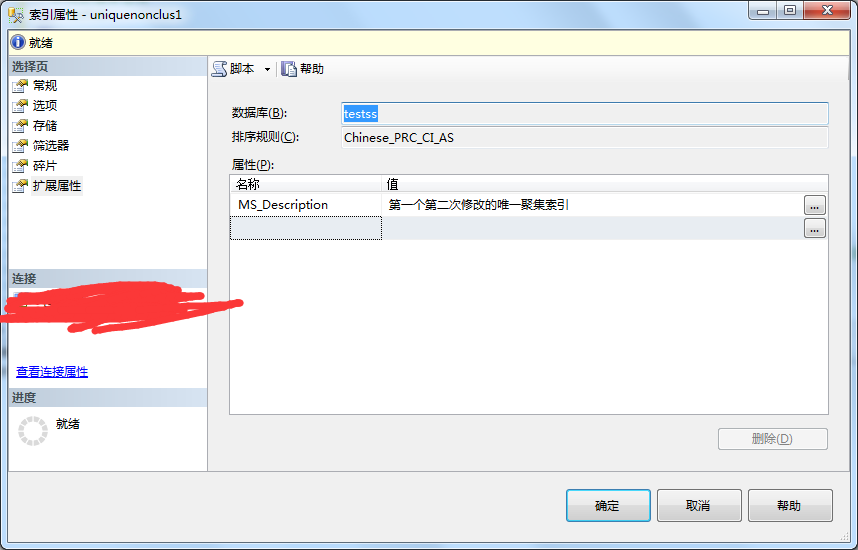
3、再次点开属性查看修改结果。
使用T-SQL脚本修改索引
修改索引列
若要添加、删除或更改索引列的位置,必须删除并重新创建该索引,详细可以参考本人之前写的创建索引。
修改索引属性
使用SQL脚本设置了几个选项
语法:
/**********修改索引部分属性**********/
--声明数据库引用
use 数据库名;
go
--修改索引属性
alter index 索引名
on 表名
set(
--statistics_norecompute:指定是否重新计算统计信息。
--statistics_norecompute=on:过时的统计信息不会自动重新计算。
--statistics_norecompute=off:启用自动统计信息更新。
statistics_norecompute={ on | off },
--ignore_dup_key:指定在插入操作尝试向唯一索引插入重复键值时的响应类型。 IGNORE_DUP_KEY 选项仅适用于创建或重新生成索引后发生的插入操作。 当执行 CREATE INDEX、ALTER INDEX 或 UPDATE 时,该选项无效。 默认为 OFF。
--ignore_dup_key=on:打开,将重复键值插入唯一索引时会出现警告消息。只有违反唯一性的行为才会失败。
--ignore_dup_key=off:关闭,将重复键值插入唯一索引时会出现错误消息。回滚整个INSERT操作。对于对视图创建的索引、非唯一索引、XML 索引、空间索引以及筛选的索引,IGNORE_DUP_KEY 不能设置为 ON
ignore_dup_key={ on | off },
--allow_row_locks:指定是否允许行锁。
--allow_row_locks=on:访问索引时允许行锁。数据库引擎确定何时使用行锁。
--allow_row_locks=off:不使用行锁。
allow_row_locks={ on | off },
--allow_page_locks:指定是否允许使用页锁。
--allow_page_locks=on:访问索引时允许页锁。数据库引擎确定何时使用页锁。
--allow_page_locks=off:不使用页锁。
allow_page_locks={ on | off }
);
go
示例:
/**********修改索引属性**********/
--声明数据库引用
use testss;
go
--修改索引属性
alter index uniquenonclus2
on test1
set(
--statistics_norecompute:指定是否重新计算统计信息。
--statistics_norecompute=on:过时的统计信息不会自动重新计算。
--statistics_norecompute=off:启用自动统计信息更新。
statistics_norecompute=on,
--ignore_dup_key:指定在插入操作尝试向唯一索引插入重复键值时的响应类型。 IGNORE_DUP_KEY 选项仅适用于创建或重新生成索引后发生的插入操作。 当执行 CREATE INDEX、ALTER INDEX 或 UPDATE 时,该选项无效。 默认为 OFF。
--ignore_dup_key=on:打开,将重复键值插入唯一索引时会出现警告消息。只有违反唯一性的行为才会失败。
--ignore_dup_key=off:关闭,将重复键值插入唯一索引时会出现错误消息。回滚整个INSERT操作。对于对视图创建的索引、非唯一索引、XML 索引、空间索引以及筛选的索引,IGNORE_DUP_KEY 不能设置为 ON
ignore_dup_key=off,
--allow_row_locks:指定是否允许行锁。
--allow_row_locks=on:访问索引时允许行锁。数据库引擎确定何时使用行锁。
--allow_row_locks=off:不使用行锁。
allow_row_locks=on,
--allow_page_locks:指定是否允许使用页锁。
--allow_page_locks=on:访问索引时允许页锁。数据库引擎确定何时使用页锁。
--allow_page_locks=off:不使用页锁。
allow_page_locks=on
);
go
使用SQL脚本重新生成现有索引
语法:
/**********修改索引部分属性**********/
--声明数据库引用
use 数据库名;
go
--该示例重新生成现有索引,并在重新生成操作过程中应用指定的填充因子。
alter index 索引名
on 表名
rebuild with(
--pad_index:指定索引填充
--pad_index=on:FILLFACTOR 指定的可用空间百分比应用于索引的中间级页。
--pad_index=off或未指定 fillfactor:考虑到中间级页上的键集,可以将中间级页几乎填满,但至少要为最大索引行留出足够空间。
pad_index={ on | off },
--statistics_norecompute:指定是否重新计算统计信息。
--statistics_norecompute=on:过时的统计信息不会自动重新计算。
--statistics_norecompute=off:启用自动统计信息更新。
statistics_norecompute={ on | off },
--sort_in_tempdb:指定是否将排序结果存储在 tempdb 中。
--sort_in_tempdb=on:在tempdb中存储用于生成索引的中间排序结果。如果tempdb与用户数据库不在同一组磁盘上,就可缩短创建索引所需的时间。但是,这会增加索引生成期间所使用的磁盘空间量。
--sort_in_tempdb=off:中间排序结果与索引存储在同一数据库中。
sort_in_tempdb={ on | off },
--ignore_dup_key:指定在插入操作尝试向唯一索引插入重复键值时的响应类型。 IGNORE_DUP_KEY 选项仅适用于创建或重新生成索引后发生的插入操作。 当执行 CREATE INDEX、ALTER INDEX 或 UPDATE 时,该选项无效。 默认为 OFF。
--ignore_dup_key=on:打开,将重复键值插入唯一索引时会出现警告消息。只有违反唯一性的行为才会失败。
--ignore_dup_key=off:关闭,将重复键值插入唯一索引时会出现错误消息。回滚整个INSERT操作。对于对视图创建的索引、非唯一索引、XML 索引、空间索引以及筛选的索引,IGNORE_DUP_KEY 不能设置为 ON
ignore_dup_key={ on | off },
--online:指定在索引操作期间基础表和关联的索引是否可用于查询和数据修改操作。 默认为 OFF。 REBUILD 可作为 ONLINE 操作执行。
--online=on:在索引操作期间不持有长期表锁。 在索引操作的主要阶段,源表上只使用意向共享 (IS) 锁。
--这使得能够继续对基础表和索引进行查询或更新。
--操作开始时,在很短的时间内对源对象持有共享 (S) 锁。
--操作结束时,如果创建非聚集索引,将在短期内获取对源的 S(共享)锁;
--当联机创建或删除聚集索引时,以及重新生成聚集或非聚集索引时,将在短期内获取 SCH-M(架构修改)锁。 但联机索引锁是短的元数据锁,特别是 Sch-M 锁必须等待此表上的所有阻塞事务完成。
--在等待期间,Sch-M 锁在访问同一表时阻止在此锁后等待的所有其他事务。 对本地临时表创建索引时,ONLINE 不能设置为 ON。
--online=off:在索引操作期间应用表锁。这样可以防止所有用户在操作期间访问基础表。
--创建、重新生成或删除聚集索引或者重新生成或删除非聚集索引的脱机索引操作将对表获取架构修改 (Sch-M) 锁。
--这样可以防止所有用户在操作期间访问基础表。 创建非聚集索引的脱机索引操作将对表获取共享 (S) 锁。 这样可以防止更新基础表,但允许读操作(如 SELECT 语句)。
online={ on | off },
--allow_row_locks:指定是否允许行锁。
--allow_row_locks=on:访问索引时允许行锁。数据库引擎确定何时使用行锁。
--allow_row_locks=off:不使用行锁。
allow_row_locks={ on | off },
--allow_page_locks:指定是否允许使用页锁。
--allow_page_locks=on:访问索引时允许页锁。数据库引擎确定何时使用页锁。
--allow_page_locks=off:不使用页锁。
allow_page_locks={ on | off },
--fillfactor=n:指定一个百分比,指示在数据库引擎创建或修改索引的过程中,应将每个索引页面的叶级填充到什么程度。 指定的值必须是 1 到 100 之间的整数。 默认值为 0。
fillfactor=n,
--maxdop=max_degree_of_parallelism:在索引操作期间替代 max degree of parallelism 配置选项。 有关详细信息,请参阅 配置 max degree of parallelism 服务器配置选项。 使用 MAXDOP 可以限制在执行并行计划的过程中使用的处理器数量。 最大数量为 64 个处理器。
--max_degree_of_parallelism 可以是:
--1 - 取消生成并行计划。
-->1 - 将并行索引操作中使用的最大处理器数量限制为指定数量。
--0(默认值)- 根据当前系统工作负荷使用实际数量的处理器或更少数量的处理器。
--有关详细信息,请参阅 配置并行索引操作。
maxdop=1
--data_compression=row:为指定的表、分区号或分区范围指定数据压缩选项。 选项如下所示:
--none
--不压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--row
--使用行压缩来压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--page
--使用页压缩来压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--columnstore
--适用范围: SQL Server 2014 (12.x) 到 SQL Server 2017。
--仅适用于列存储表。 COLUMNSTORE 指定对使用 COLUMNSTORE_ARCHIVE 选项压缩的分区进行解压缩。 还原数据时,将继续通过用于所有列存储表的列存储压缩对 COLUMNSTORE 索引进行压缩。
--columnstore_archive
--适用范围: SQL Server 2014 (12.x) 到 SQL Server 2017。
--仅适用于列存储表,这是使用聚集列存储索引存储的表。 COLUMNSTORE_ARCHIVE 会进一步将指定分区压缩到更小。 这可用于存档,或者用于要求更少存储并且可以付出更多时间来进行存储和检索的其他情形
--data_compression=row --注意:只有 SQL Server Enterprise Edition 支持压缩。
--on partitions ( { <partition_number_expression> | <range> } [ ,...n ] ) 适用范围: SQL Server 2008 到 SQL Server 2017。
--指定对其应用 DATA_COMPRESSION 设置的分区。 如果表未分区,ON PARTITIONS 参数将生成错误。 如果不提供 ON PARTITIONS 子句,DATA_COMPRESSION 选项将应用于已分区表的所有分区。
--可以按以下方式指定 <partition_number_expression>:
--提供一个分区号,例如:ON PARTITIONS (2)。
--提供若干单独分区的分区号并用逗号将它们隔开,例如:ON PARTITIONS (1, 5)。
--同时提供范围和单个分区,例如:ON PARTITIONS (2, 4, 6 TO 8)。
--<range> 可以指定为以单词 TO 隔开的分区号,例如:ON PARTITIONS (6 TO 8)。
--,请多次指定 DATA_COMPRESSION 选项
--on partitions(1-2) --注意:分区之前表一定要有分区方案
);
go
示例:
/**********修改索引部分属性**********/
--声明数据库引用
use testss;
go
--该示例重新生成现有索引,并在重新生成操作过程中应用指定的填充因子。
alter index uniquenonclus2
on test1
rebuild with(
--pad_index:指定索引填充
--pad_index=on:FILLFACTOR 指定的可用空间百分比应用于索引的中间级页。
--pad_index=off或未指定 fillfactor:考虑到中间级页上的键集,可以将中间级页几乎填满,但至少要为最大索引行留出足够空间。
pad_index=on,
--statistics_norecompute:指定是否重新计算统计信息。
--statistics_norecompute=on:过时的统计信息不会自动重新计算。
--statistics_norecompute=off:启用自动统计信息更新。
statistics_norecompute=off,
--sort_in_tempdb:指定是否将排序结果存储在 tempdb 中。
--sort_in_tempdb=on:在tempdb中存储用于生成索引的中间排序结果。如果tempdb与用户数据库不在同一组磁盘上,就可缩短创建索引所需的时间。但是,这会增加索引生成期间所使用的磁盘空间量。
--sort_in_tempdb=off:中间排序结果与索引存储在同一数据库中。
sort_in_tempdb=off,
--ignore_dup_key:指定在插入操作尝试向唯一索引插入重复键值时的响应类型。 IGNORE_DUP_KEY 选项仅适用于创建或重新生成索引后发生的插入操作。 当执行 CREATE INDEX、ALTER INDEX 或 UPDATE 时,该选项无效。 默认为 OFF。
--ignore_dup_key=on:打开,将重复键值插入唯一索引时会出现警告消息。只有违反唯一性的行为才会失败。
--ignore_dup_key=off:关闭,将重复键值插入唯一索引时会出现错误消息。回滚整个INSERT操作。对于对视图创建的索引、非唯一索引、XML 索引、空间索引以及筛选的索引,IGNORE_DUP_KEY 不能设置为 ON
ignore_dup_key=off,
--online:指定在索引操作期间基础表和关联的索引是否可用于查询和数据修改操作。 默认为 OFF。 REBUILD 可作为 ONLINE 操作执行。
--online=on:在索引操作期间不持有长期表锁。 在索引操作的主要阶段,源表上只使用意向共享 (IS) 锁。
--这使得能够继续对基础表和索引进行查询或更新。
--操作开始时,在很短的时间内对源对象持有共享 (S) 锁。
--操作结束时,如果创建非聚集索引,将在短期内获取对源的 S(共享)锁;
--当联机创建或删除聚集索引时,以及重新生成聚集或非聚集索引时,将在短期内获取 SCH-M(架构修改)锁。 但联机索引锁是短的元数据锁,特别是 Sch-M 锁必须等待此表上的所有阻塞事务完成。
--在等待期间,Sch-M 锁在访问同一表时阻止在此锁后等待的所有其他事务。 对本地临时表创建索引时,ONLINE 不能设置为 ON。
--online=off:在索引操作期间应用表锁。这样可以防止所有用户在操作期间访问基础表。
--创建、重新生成或删除聚集索引或者重新生成或删除非聚集索引的脱机索引操作将对表获取架构修改 (Sch-M) 锁。
--这样可以防止所有用户在操作期间访问基础表。 创建非聚集索引的脱机索引操作将对表获取共享 (S) 锁。 这样可以防止更新基础表,但允许读操作(如 SELECT 语句)。
online=off,
--allow_row_locks:指定是否允许行锁。
--allow_row_locks=on:访问索引时允许行锁。数据库引擎确定何时使用行锁。
--allow_row_locks=off:不使用行锁。
allow_row_locks=on,
--allow_page_locks:指定是否允许使用页锁。
--allow_page_locks=on:访问索引时允许页锁。数据库引擎确定何时使用页锁。
--allow_page_locks=off:不使用页锁。
allow_page_locks=on,
--fillfactor=n:指定一个百分比,指示在数据库引擎创建或修改索引的过程中,应将每个索引页面的叶级填充到什么程度。 指定的值必须是 1 到 100 之间的整数。 默认值为 0。
fillfactor=1,
--maxdop=max_degree_of_parallelism:在索引操作期间替代 max degree of parallelism 配置选项。 有关详细信息,请参阅 配置 max degree of parallelism 服务器配置选项。 使用 MAXDOP 可以限制在执行并行计划的过程中使用的处理器数量。 最大数量为 64 个处理器。
--max_degree_of_parallelism 可以是:
--1 - 取消生成并行计划。
-->1 - 将并行索引操作中使用的最大处理器数量限制为指定数量。
--0(默认值)- 根据当前系统工作负荷使用实际数量的处理器或更少数量的处理器。
--有关详细信息,请参阅 配置并行索引操作。
maxdop=1
--data_compression=row:为指定的表、分区号或分区范围指定数据压缩选项。 选项如下所示:
--none
--不压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--row
--使用行压缩来压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--page
--使用页压缩来压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--columnstore
--适用范围: SQL Server 2014 (12.x) 到 SQL Server 2017。
--仅适用于列存储表。 COLUMNSTORE 指定对使用 COLUMNSTORE_ARCHIVE 选项压缩的分区进行解压缩。 还原数据时,将继续通过用于所有列存储表的列存储压缩对 COLUMNSTORE 索引进行压缩。
--columnstore_archive
--适用范围: SQL Server 2014 (12.x) 到 SQL Server 2017。
--仅适用于列存储表,这是使用聚集列存储索引存储的表。 COLUMNSTORE_ARCHIVE 会进一步将指定分区压缩到更小。 这可用于存档,或者用于要求更少存储并且可以付出更多时间来进行存储和检索的其他情形
--data_compression=row --注意:只有 SQL Server Enterprise Edition 支持压缩。
--on partitions ( { <partition_number_expression> | <range> } [ ,...n ] ) 适用范围: SQL Server 2008 到 SQL Server 2017。
--指定对其应用 DATA_COMPRESSION 设置的分区。 如果表未分区,ON PARTITIONS 参数将生成错误。 如果不提供 ON PARTITIONS 子句,DATA_COMPRESSION 选项将应用于已分区表的所有分区。
--可以按以下方式指定 <partition_number_expression>:
--提供一个分区号,例如:ON PARTITIONS (2)。
--提供若干单独分区的分区号并用逗号将它们隔开,例如:ON PARTITIONS (1, 5)。
--同时提供范围和单个分区,例如:ON PARTITIONS (2, 4, 6 TO 8)。
--<range> 可以指定为以单词 TO 隔开的分区号,例如:ON PARTITIONS (6 TO 8)。
--,请多次指定 DATA_COMPRESSION 选项
--on partitions(1-2) --注意:分区之前表一定要有分区方案
);
go
修改索引名称
语法:
/**********修改索引名称**********/
--声明数据库引用
use 数据库名;
go
--修改索引名称
exec sp_rename N'表名.索引名',N'索引名',N'index';
go
示例:
/**********修改索引名称**********/
--声明数据库引用
use testss;
go
--修改索引名称
exec sp_rename N'test1.uniquenonclus1',N'uniquenonclus2',N'index';
go
SQLServer之修改索引的更多相关文章
- SQLServer Alter 修改表的列名的解决
解决:在SQLServer中修改表的列名,可以调用存储过程sp_rename. [sql]use Test;--使用数据库 sp_rename 'd_s_t.avg_grade','avg_g',' ...
- sqlServer 2008修改字段类型和重命名字段名称的sql语句
sqlServer 2008修改字段类型和重命名字段名称的sql语句 //修改字段的类型 alter table fdi_news alter column c_author nvarchar(50) ...
- SQLSERVER如何查看索引缺失
SQLSERVER如何查看索引缺失 当大家发现数据库查询性能很慢的时候,大家都会想到加索引来优化数据库查询性能, 但是面对一个复杂的SQL语句,找到一个优化的索引组合对人脑来讲,真的不是一件很简单的事 ...
- oracle 修改索引现有表空间
工作日记之<修改索引现有表空间> //dba_indexes可查询所有索引,以及索引部分信息,可以灵活运用于其他用途 //假设用户USER1现有表空间TS1.TS2,需要迁移其下所有表空间 ...
- es手动创建索引,修改索引,删除索引
1.创建索引 创建索引的语法PUT /my_index{ "settings": { ... any settings ... }, "mappings": { ...
- SQLServer 事物与索引
SqlServer 事物与索引 分享by:授客 QQ:1033553122 详情点击百度网盘分享链接: SqlServer 事物与索引.ppt
- 修改索引名称(mysql)
MySQL修改索引名称. 对于MySQL 5.7及以上版本,可以执行以下命令: ALTER TABLE tbl_name RENAME INDEX old_index_name TO new_inde ...
- es修改索引副本个数
es修改索引副本个数 PUT index01/_settings { "number_of_replicas": 2 }
- ms sqlserver数据库建索引
索引分类:从物理结构上可分为两种:聚集索引和非聚集索引 (此外还有空间索引.筛选索引.XML索引) 因为聚集索引是索引顺序与物理存储顺序一致,所以只能建一个. 聚集索引就是把数据按主键顺序存储: 因为 ...
随机推荐
- Hadoop源码篇--Reduce篇
一.前述 Reduce文件会从Mapper任务中拉取很多小文件,小文件内部有序,但是整体是没序的,Reduce会合并小文件,然后套个归并算法,变成一个整体有序的文件. 二.代码 ReduceTask源 ...
- Docker 下载镜像
文章首发个人网站: https://www.exception.site/docker/docker-pull-image 本文中,我们将需要学习 Docker 如何下载镜像? 一.前言 大家都知道, ...
- Mac 下生成keystore,并对apk进行签名
1.查看本机java环境 /usr/libexec/java_home -V 最后一行是Mac默认使用的jdk版本. 2.进入java的环境 /Library/Java/JavaVirtualMach ...
- 死磕 java集合之WeakHashMap源码分析
欢迎关注我的公众号"彤哥读源码",查看更多源码系列文章, 与彤哥一起畅游源码的海洋. 简介 WeakHashMap是一种弱引用map,内部的key会存储为弱引用,当jvm gc的时 ...
- jar文件和aar文件的区别
1. *.jar,JAR 文件就是 JavaArchive File,顾名思意,它的应用是与 Java 息息相关的,是 Java 的一种文档格式.只包含了class文件与清单文件 ,不包含资源文件 ...
- Solr 08 - 在Solr Web管理页面中查询索引数据 (Solr中各类查询参数的使用方法)
目录 1 Solr管理页面的查询入口 2 Solr查询输入框简介 3 Solr管理页面的查询方案 1 Solr管理页面的查询入口 选中需要查询的SolrCore, 然后在菜单栏选择[Query]: 2 ...
- Docker折腾手记-安装
安装 docker红的发紫,所以博主耳闻这么久,也要来折腾折腾了 研究不多,个人目前认为docker给我们带来了以下好处 开发机器因为开发原因,需要配置各种各校的环境,繁琐且耗费资源.配来配去还容易环 ...
- linux磁盘管理系列一:磁盘配额管理
磁盘管理系列 linux磁盘管理系列一:磁盘配额管理 http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_linux_040_quota.html l ...
- eclipse导入别人工程项目后,出现红叉的各种情况
原文:http://www.cnblogs.com/mmzs/p/7662863.html 1.多半是因为jdk版本的原因,调整一下即可: 解决方法:Build Path ==> Configu ...
- 浅谈cookie和session
Cookie简介 Cookie(复数形态Cookies),中文名称为“小型文本文件”,指某些网站为了辨别用户身份或存储用户相关信息而存储在用户本地终端(Client Side) 上的数据(通常为加密数 ...