Spark SQL大数据处理并写入Elasticsearch
SparkSQL(Spark用于处理结构化数据的模块)
通过SparkSQL导入的数据可以来自MySQL数据库、Json数据、Csv数据等,通过load这些数据可以对其做一系列计算
下面通过程序代码来详细查看SparkSQL导入数据并写入到ES中:
数据集:北京市PM2.5数据
Spark版本:2.3.2
Python版本:3.5.2
mysql-connector-java-8.0.11 下载
ElasticSearch:6.4.1
Kibana:6.4.1
elasticsearch-spark-20_2.11-6.4.1.jar 下载
具体代码:
# coding: utf-8
import sys
import os pre_current_dir = os.path.dirname(os.getcwd())
sys.path.append(pre_current_dir)
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from pyspark.sql.functions import udf
from settings import ES_CONF current_dir = os.path.dirname(os.path.realpath(__file__)) spark = SparkSession.builder.appName("weather_result").getOrCreate() def get_health_level(value):
"""
PM2.5对应健康级别
:param value:
:return:
"""
if 0 <= value <= 50:
return "Very Good"
elif 50 < value <= 100:
return "Good"
elif 100 < value <= 150:
return "Unhealthy for Sensi"
elif value <= 200:
return "Unhealthy"
elif 200 < value <= 300:
return "Very Unhealthy"
elif 300 < value <= 500:
return "Hazardous"
elif value > 500:
return "Extreme danger"
else:
return None def get_weather_result():
"""
获取Spark SQL分析后的数据
:return:
"""
# load所需字段的数据到DF
df_2017 = spark.read.format("csv") \
.option("header", "true") \
.option("inferSchema", "true") \
.load("file://{}/data/Beijing2017_PM25.csv".format(current_dir)) \
.select("Year", "Month", "Day", "Hour", "Value", "QC Name") # 查看Schema
df_2017.printSchema() # 通过udf将字符型health_level转换为column
level_function_udf = udf(get_health_level, StringType()) # 新建列healthy_level 并healthy_level分组
group_2017 = df_2017.withColumn(
"healthy_level", level_function_udf(df_2017['Value'])
).groupBy("healthy_level").count() # 新建列days和percentage 并计算它们对应的值
result_2017 = group_2017.select("healthy_level", "count") \
.withColumn("days", group_2017['count'] / 24) \
.withColumn("percentage", group_2017['count'] / df_2017.count())
result_2017.show() return result_2017 def write_result_es():
"""
将SparkSQL计算结果写入到ES
:return:
"""
result_2017 = get_weather_result()
# ES_CONF配置 ES的node和index
result_2017.write.format("org.elasticsearch.spark.sql") \
.option("es.nodes", "{}".format(ES_CONF['ELASTIC_HOST'])) \
.mode("overwrite") \
.save("{}/pm_value".format(ES_CONF['WEATHER_INDEX_NAME'])) write_result_es()
spark.stop()
将mysql-connector-java-8.0.11和elasticsearch-spark-20_2.11-6.4.1.jar放到Spark的jars目录下,提交spark任务即可。
注意:
(1) 如果提示:ClassNotFoundException Failed to find data source: org.elasticsearch.spark.sql.,则表示spark没有发现jar包,此时需重新编译pyspark:
cd /opt/spark-2.3.2-bin-hadoop2.7/python
python3 setup.py sdist
pip install dist/*.tar.gz
(2) 如果提示:Multiple ES-Hadoop versions detected in the classpath; please use only one ,
则表示ES-Hadoop jar包有多余的,可能既有elasticsearch-hadoop,又有elasticsearch-spark,此时删除多余的jar包,重新编译pyspark 即可
执行效果:
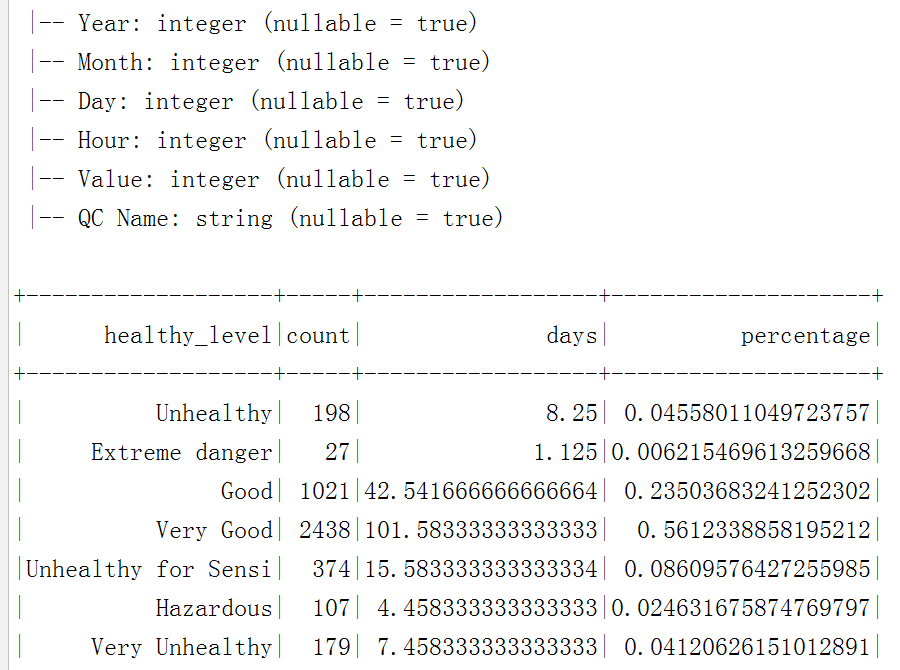
更多源码请关注我的github, https://github.com/a342058040/Spark-for-Python ,Spark相关技术全程用python实现,持续更新
Spark SQL大数据处理并写入Elasticsearch的更多相关文章
- Spark SQL JSON数据处理
背景 这一篇可以说是“Hive JSON数据处理的一点探索”的兄弟篇. 平台为了加速即席查询的分析效率,在我们的Hadoop集群上安装部署了Spark Server,并且与我们的Hive数据仓 ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- Spark官方1 ---------Spark SQL和DataFrame指南(1.5.0)
概述 Spark SQL是用于结构化数据处理的Spark模块.它提供了一个称为DataFrames的编程抽象,也可以作为分布式SQL查询引擎. Spark SQL也可用于从现有的Hive安装中读取数据 ...
- [转] Spark sql 内置配置(V2.2)
[From] https://blog.csdn.net/u010990043/article/details/82842995 最近整理了一下spark SQL内置配.加粗配置项是对sparkSQL ...
- 第五章 大数据平台与技术 第12讲 大数据处理平台Spark
Spark支持多种的编程语言 对比scala和Java编程上节课的计数程序.相比之下,scala简洁明了. Hadoop的IO开销大导致了延迟高,也就是说任务和任务之间涉及到I/O操作.前一个任务完成 ...
- 流式大数据处理的三种框架:Storm,Spark和Samza
许多分布式计算系统都可以实时或接近实时地处理大数据流.本文将对三种Apache框架分别进行简单介绍,然后尝试快速.高度概述其异同. Apache Storm 在Storm中,先要设计一个用于实时计算的 ...
- [转载]流式大数据处理的三种框架:Storm,Spark和Samza
许多分布式计算系统都可以实时或接近实时地处理大数据流.本文将对三种Apache框架分别进行简单介绍,然后尝试快速.高度概述其异同. Apache Storm 在Storm中,先要设计一个用于实时计算的 ...
- 《Spark大数据处理:技术、应用与性能优化 》
基本信息 作者: 高彦杰 丛书名:大数据技术丛书 出版社:机械工业出版社 ISBN:9787111483861 上架时间:2014-11-5 出版日期:2014 年11月 开本:16开 页码:255 ...
- Spark大数据处理技术
全球首部全面介绍Spark及Spark生态圈相关技术的技术书籍 俯览未来大局,不失精细剖析,呈现一个现代大数据框架的架构原理和实现细节 透彻讲解Spark原理和架构,以及部署模式.调度框架.存储管理及 ...
随机推荐
- 07Axios
详情:https://pizzali.github.io/2018/10/30/Axios/ JQuery时代,我们使用ajax向后台提交数据请求,Vue时代,Axios提供了前端对后台数据请求的各种 ...
- C++:位操作基础篇之位操作全面总结
位操作篇共分为基础篇和提高篇,基础篇主要对位操作进行全面总结,帮助大家梳理知识.提高篇则针对各大IT公司如微软.腾讯.百度.360等公司的笔试面试题作详细的解答,使大家能熟练应对在笔试面试中位操作题目 ...
- java 11 不可修改集合API
不可修改集合API 自 Java 9 开始,Jdk 里面为集合(List/ Set/ Map)都添加了 of 和 copyOf 方法,它们两个都用来创建不可变的集合,来看下它们的使用和区别. 示例1: ...
- 金融量化分析【day112】:股票数据分析Tushare1
目录 1.使用tushare包获取某股票的历史行情数据 2.输出该股票所有收盘比开盘上涨3%以上的日期 3.输出该股票所有开盘比前日收盘跌幅超过2%的日期 4.假如我从2010年1月1日开始,每月第一 ...
- SpringBoot系列: Web应用鉴权思路
==============================web 项目鉴权============================== 主要的鉴权方式有:1. 用户名/密码鉴权, 然后通过 Sess ...
- SCI,EI,ISTP
SCI: Science Citation Index EI: The Engineering Index ISTP: Index to Scientific & Technic ...
- FM(Factorization Machines)
摘自 https://www.jianshu.com/p/1687f8964a32 https://blog.csdn.net/google19890102/article/details/45532 ...
- Delete from join 用法
delete (别名) from tblA (别名) left join tblb (别名) on...用法 1.创建使用的表及数据 CREATE TABLE YSHA ( code ), NAME ...
- Contest2154 - 2019-2-28 高一noip基础知识点 测试1 题解版
传送门 预计得分:100+100+100+100=400 实际得分:55+100+60+80=295 细节决定成败啊!!! T1 这道题思路很简单,就是一些细节很变态坑人 首先,数据不一定是有序的,虽 ...
- sessionStorage:写入记事本功能[内容写入sessionStorage中,读取,删除]
知识点: 1.设置sessionStorage----setItem:sessionStorage.setItem(key,data); 存储数据使用key是唯一,不可重复,每触发都生成:如用一个固定 ...