论文阅读笔记四十三:DeeperLab: Single-Shot Image Parser(CVPR2019)

论文原址:https://arxiv.org/abs/1902.05093
github:https://github.com/lingtengqiu/Deeperlab-pytorch
摘要
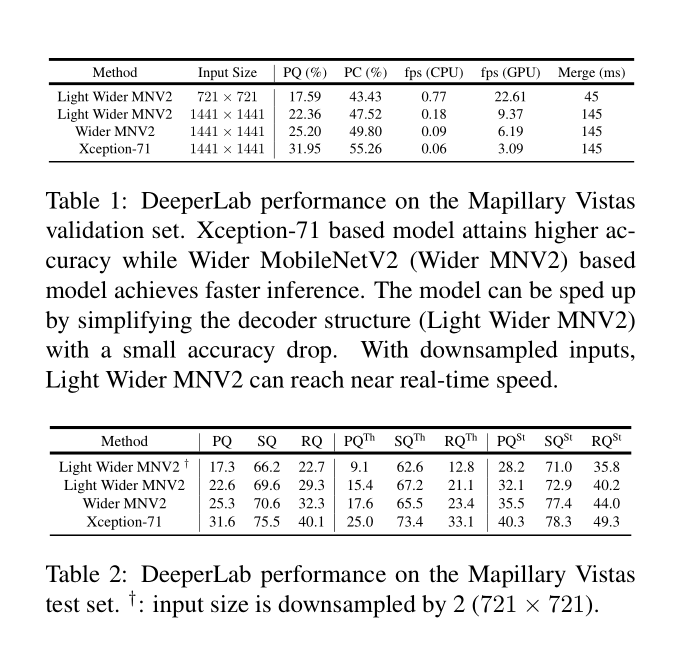
本文提出了一种bottoom-up,single-shot的全景图像分析方法。全景图像分析包含"stuff"形式(类别)的语义分割及“thing”形式(区别不同个体)的实例分割。目前,全景图像分析的经典方法是由语义分割任务及实例分割任务的独立的模块组成,同时其需要进行多次inference操作。与之相反的是,本文提出了用相对简单的全卷积的方式对图像进行场景分析。以single-shot的方式同时处理语义分割及实例分割两种任务,从而得到一个处理速度较快的流线型模型。针对定量分析,本文使用了基于实例的全景质量-PQ度量及基于区域建议覆盖分析-PC度量,其可以更好的捕捉“stuff”类别及更大目标实例的图像分析质量。基于Mapillary Vistas 数据集进行实验,本文的单一模型基于GPU实现了31.95%(val)及31.6%(test)的PQ及55.26%(val)的PC。运行速度为3fps或者接近实时速度22.6fps,但准确率会有所下降。
介绍
本文致力于解决有效的进行全景分析问题,图像解析是计算机视觉任务中的一个长期未解决的问题,同时,也是现实中许多应用的组件之一,比如自动驾驶。图像解析的难点在于统一了语义分割及实例分割两个具有挑战性的任务。语义分割重点是将图像中的区域划分为具有语义信息的几个区域,其语义类别可以是可统计(“thing”)的类,也可以是不可统计("stuff")的类。与之相反的是,实例分割只是处理与“thing”类别相关,但需要区分不同的实例部分。将主题与图像分析进行结合可以将包含“stuff”类与“thing”类的整个图片进行分割,同时,不同分离不同的"thing"实例。
有许多用于解决图像分析中问题的相关工作,但大都未考虑效率问题。而对于将模型部署到实际生活中,其效率是十分重要的。图像解析由于需要经过复杂的网络进行处理,因此会增加计算量,而且,随着输入分辨率的增加,计算量还会继续增加。
本文设计了一种图像解析器,综合考虑了准确率及效率二者之间的关系。提出了一种single-shot,bottom-up的图像解析器-DeeperLab。如下图,DeeperLab基于single-pass的全卷积网络来产生语义及实例分割的预测mask。最后通过一个快速的算法将预测结果进行融合得到解析的结果。DeeperLab在执行时,检测物体的实例个数对其影响甚小,因此,该模型可以适用于更加复杂的场景。
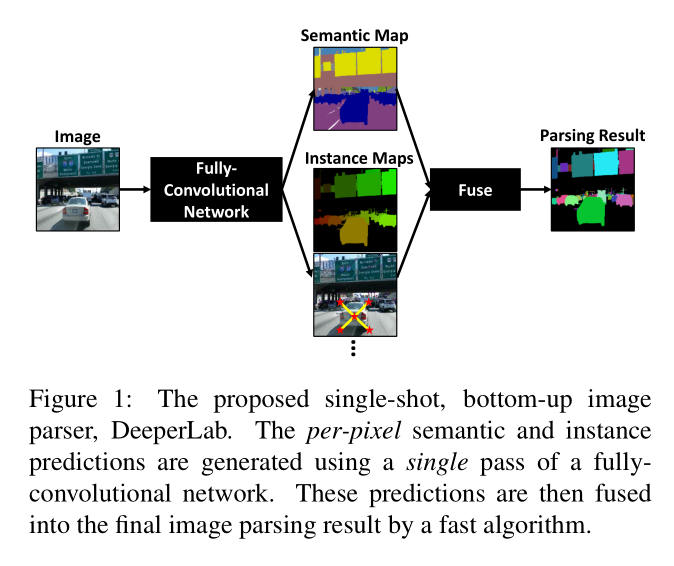 对于定量评估,作者认为最近提出的基于实例的 Panoptic Quality(PQ)评估,过分注重于小物体,其对"thing"类别的关注度要超过“stuff”类别。为了弥补此影响,本文提出了假定的基于区域的Parsing Covering(PC)度量,与适用于类别不匹配评估Covering评估相匹配,针对图像解析任务,本文使用了PQ及PC两个标准进行评估。本文贡献如下:
对于定量评估,作者认为最近提出的基于实例的 Panoptic Quality(PQ)评估,过分注重于小物体,其对"thing"类别的关注度要超过“stuff”类别。为了弥补此影响,本文提出了假定的基于区域的Parsing Covering(PC)度量,与适用于类别不匹配评估Covering评估相匹配,针对图像解析任务,本文使用了PQ及PC两个标准进行评估。本文贡献如下:
a)本文针对图像解析器设计了几种神经网络策略,尤其是对于较高分辨率输入的情形,降低其内存的占用。创新性的做法包括:广泛的使用深度可分离卷积,共享由两层网络组成的预测端。扩大卷积核的大小而不是增加网络的深度,应用space-to-depth及depth-to-space的方法而不是上采样,同时,执行hard data mining,本文也详细介绍了融合的相关研究进而证明本模型在实际应用中的有效性。
b)本文提出了一种高效的signel-shot,bottom-up的图像解析器-DeeperLab。在 Mapillary Vistas数据集上,基于Xception-71,在GPU上实现了 31.95% PQ (val) / 31.6% (test) 及 55.26% PC (val)执行速度为3fps。基于宽度更宽的MobileNetv2则可以实现实时预测(22.61fps),但准确率会有所下降。
c)本文提出了一种交替的评价标准- Parsing Covering,基于区域的角度来评判图像解析结果。
相关工作
Image parsing:Imae parsing的作用是将图像分解为连续的视觉模式,像纹理及检测目标等,其涵盖了分割,检测,识别等任务。首次使用基于贝叶斯框架进行Image parsing,后来基于AND-OR图, Exemplars及条件随机场等方法进行全场景理解任务。早期这些任务的评估标准是独立的,比如,检测有检测的评估标准,分割有分割的评估标准。随着基于实例的全景质量(PQ)评估引入多个benchmarks中,全景分割越来越受到关注。
语义分割:大多数state-of-art的分割模型在基于FCN的基础上进行一些创新性改进得到的。比如,上下文信息对像素级的标记十分重要,因此,有些工作使用图像金字塔对不同尺寸的输入图像进行编码操作。PSPNet提出了基于不同网格尺寸的图像金字塔池化结构,DeepLab提出了使用不同rate的并行的空洞卷积结构(ASPP)从而可以有效的利用上下文信息。另一个有效的方法是使用encoder-decoder结构。在encoder阶段得到图像的上下文信息,而在解码阶段对边界进行恢复。DeeperLab利用FCN,ASPP,encoder-decoder等结构来最大化image parsing的准确率。
实例分割:当前实例分割的方法可以归类为top-down及bottom-up的方法。top-down的方法通过增强state-of-the-art检测器得到的框获得instance masks。其中,FCIS使用位置敏感性score maps。Mask R-CNN基于FPN的基础上进行搭建,在Faster R-CNN上增加了另一个分割分支,取得较好的效果。另一方面,bottom-up的方法采用两阶段的处理过程,由分割模型得到的像素级预测按照实例预测的方式进行聚合。PersonLab预测人体的关键点及进行人体实例分割,而DeNet及CornerNet通过预测边界框的角点来检测实例。
评价标准:语义分割的结果可以通过基于区域或者轮廓的指标来进行评估。基于区域的评估标准定量评价标记正确的像素所占比例,包括:overall pixel accuracy,mean class accuracy,mean IOU。而基于轮廓的度量则关注分割边界的标记精度。比如,在分割边界较窄的三角地带评估像素级的准确率及IOU。对于类别不可知的分割可以使用covering 标准来度量。实例分割可以看作是mask检测,是边界框检测的增强。因此,此类任务通常使用APr进行度量,像计算mask的IOU而不是边界框的IOU。在0.5到0.95不同重叠率阈值下计算AP的平均值进而评估分割结果。基于区域覆盖指标来评估实例分割结果,该方法适用于无法计算预测值重叠率的情形。图像解析结果可以通过Panoptic Quality(PQ)指标进行评估,同时将具有相同“stuff”类别的图像区域作为单个实例。而PQ度量存在的一个问题是,无论目标物的尺寸为多大,都视为相同的,因此,PQ度量可能会过度强调小的物体,像“thing”类别的而不是“stuff”类。
Methodology
本文受DeepLab与PersonLab启发,提出了一种single-shot,bottom-up的有效的神经网络模型用于图像解析。网络结构如下图。
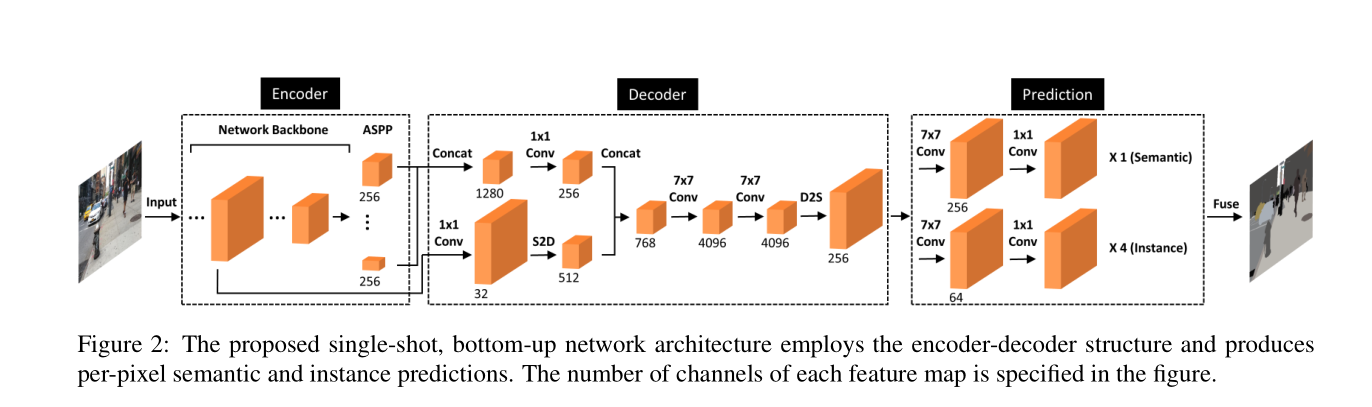 网络结构采用encoder-decoder的形式,为了提高效率,语义分割与实例分割共享decoder的输出,将二者的输出结果进行融合作为最终图像解析的结果。
网络结构采用encoder-decoder的形式,为了提高效率,语义分割与实例分割共享decoder的输出,将二者的输出结果进行融合作为最终图像解析的结果。
对于图像解析任务来说,输入需要较高的分辨率(本文基于 Mapillary Vistas数据集,分辨率大小为1441x1441)会造成大量的内存占用及冗余。本文详细介绍了如何克服上述问题,进而在准确率及内存占用上得到一个最优的平衡处理。
Encoder
本文基于高效的深度可分离卷积实验了两个网络结构:1)标准的Xception-71用于获得较高的准确率,2)更宽的MobileNetV2用于更快的推理。虽然标准的MobilenetV2在输入大小为224x224的ImageNet图像分类任务中表现较好。但是对于较高输入分辨率的图像解析任务,其有限的感受野(491x491)无法捕捉大范围的上下文信息。正如Xception-71那样,叠加更多3x3的卷积是增大感受野的一种方式,然而增加的额外的网络层会造成大量的内存占用。考虑到计算资源有限,将MobileNetV2中的所有3x3的卷积替换为5x5的卷积。这种方法在不增加内存占用的条件下有效的增加了感受野的大小(981x981),计算量会稍有增加。本文称其为更宽的MobileNetV2。
本文增加了网络中的ASPP结构,encoder输出的feature map stride为16,其空间分辨率为输入上每个分辨率以16的倍数进行降采样得到的分辨率。
Decoder
decoder的目的是恢复目标物边界的细节信息,参考DeeplabV3+,本文采用将encoder输出的激活层的feature map(stride=16)与backbone的较低层次的feature map(stride=4)进行融合。ASPP的输出与低层feature map的通道数首先经过1x1的卷积进行降维处理来减少通道数。DeeplabV3+考虑到不同分辨率的将降维后的ASPP输出进行基于双线性插值进行上采样,然而上采样的操作会大大增加内存的消耗。本文对低层次的feature map采用了space-to-depth的操作,如下图,使占用的内存不会发生改变。

与encoder相似,decoder使用大小为7x7的深度卷积来增加感受野的范围。通道数为4096,然后,通过depth-to-space操作来实现上采样操作,得到一个通道数为256,stride为4的feature map,作为image parsing处理的输入。
Image Parsing Prediction Heads
图像解析部分的顶部包含五大部分,每一个都单独的拼接到共享的decoder输出,同时包含两个卷积大小分别为7x7及1x1的两个卷积层。一端用于语义分割(第一个7x7的卷积核的通道数为256),其余4个用于类别不可分的实例分割(第一个7x7的卷积核的通道数为64)
Semantic Segmentation Head
基于引导性交叉熵损失对分割进行训练,即将每个像素按照其对应的交叉熵损失进行排序,只对其前K个位置的像素进行反向传播(hard example mining),本文设置K的大小为0.158xN,N为图像中所有像素的个数。此外,根据实例的大小,对像素的损失进行了加权重操作,从而更加关注小样本。提出的引导型加权交叉熵损失定义如下:
 Instance Segmentation Heads
Instance Segmentation Heads
本文采用基于关键点的形式对目标实例进行表示,本文考虑边界框的四个顶点及中心作为P为5的目标物关键点。参照PersonLab网络,定义四个head用于实例分割。
与PersonLab相类似,定义了四个用于实例分割的四个预测heads:a keypoint heatmap , long-range, short-range及 middle range offset maps。这些heads用于预测每个像素点与对应实例关键点之间的联系。四个heads如下图。
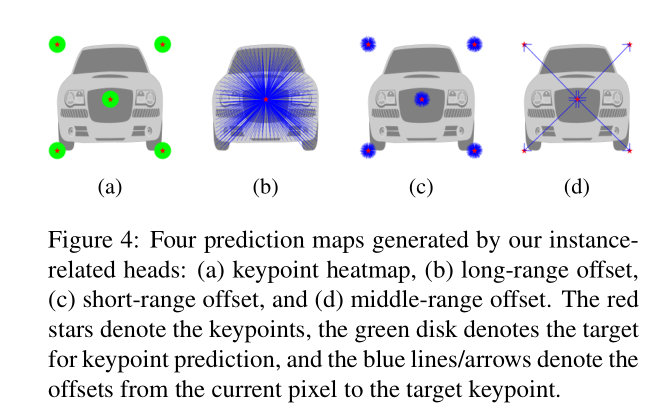
The keypoint heatmap:用于预测像素是否位于以对应关键点为中心半径为R的disks中。如果在其中,则目标激活值为1,否则为0.无论实例多大,统一设置R为25。对于每个关键点,预测得到的kepoint heatmap通道数为P,基于标准的sigmoid交叉熵损失对误差进行惩罚。
The long-range offset map:用于预测一个像素相对于所有关键点的偏移,编码每个像素的长距离信息。得到的长偏移map通道数为2P。每两个通道用于预测每个关键点水平及垂直方向上的偏移,使用L1损失,只激活属于目标实例的像素。
The short-range offset map:与 long-range offset map相似,只是半径变为25,损失函数同上。
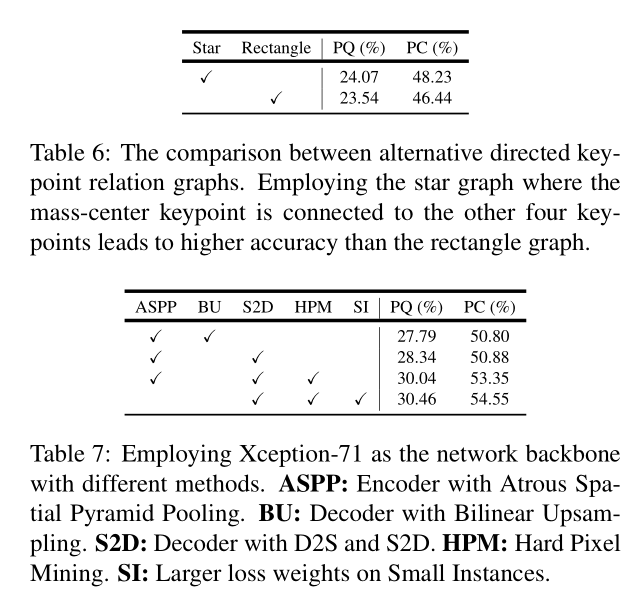
The middle-range offset map:用于预测有向关键点练习图(DKRG)关键点对之间的偏移。该map用于组合来自形同目标实例的关键点。本文采用star-graph,质心点与四角的点基于双线性连接。预测得到的map通道数为2E,其中E为DKRG中有向边的数量(E=8).损失函数同上。
Prediction Fusion
本文首先说明如何将前面得到的四个预测maps融合为一个类别不可分的实例分割map。基于预测出的语义及实例分割maps,对于图像中的每个像素将语义及实例label都进行融合。
Instance Prediction:与PersonLab相类似,根据实例相关的四个预测maps生成实例分割map。
Recursive offset refinement:本文观察到距离关键点越近则预测的准确率就越高,因此,像PersonLab一样递归的增强偏移maps.
Keypoint localization:对于每个关键点,在short-range偏移map上使用霍夫投票,同时使用对应关键点heatmap的激活值作为投票权重用于从而生成short-range score map。同样,在long-range偏移map上使用霍夫投票,权重都为1,生成long-range的score map。两个score maps按照权重相加进行融合。通过在融合后的score maps中寻找局部最大值从而定位关键点。最后,使用 Expected-OKS对所有关键点重新打分。
Instance detection:为了实例检测,基于贪婪算法对关键点进行聚合。首先,所有关键点被推入一个优先队列中,同时,一次只弹出一个来。如果被弹出的关键点已经在检测的实例中存在,则丢弃继续执行。否则,根据middle-range offsets 来确认保留四个关键点的位置,从而形成一个新的检测实例。新检测实例的置信分数为各个关键点分数的平均值。检测完所有实例后使用NMS去除重叠较大的实例。
Assignment of pixels to instances:最后,对检测到的实例通过使用long-range offset map进行label操作。将每个像素分配到检测到的实例中,该实例中的关键点与该像素预测到的关键点二者之间的L2距离最短。
Semantic and Instance Prediction Fusion:本文选择简单的融合方法,考虑“stuff”类别(像天空)及“thing”类别(人)两种情况从预测的语义分割开始。对于预测的像素为“stuff”类的则标记一个独一无二的实例Label.对于其他像素,实例标签由实例分割结果确定,而语义标签,则由语义分割中投票数较多的情况决定。
评价机制
回顾了Panoptic Quality (PQ)机制并扩展了存在的 Covering metric提出了 Parsing Covering (PC) metric。PQ的定义如下

PQ忽略实例的大小并将将所有具有相同“stuff”类的区域当作一个实例。比如,10x10大小的实例与1000x1000大小的实例的效果是等价的。因此,PQ对于小区域的误报会很敏感,通过删除一些小区域等启发式方法可以提高性能。因此,PQ适用对于不同实例的尺寸,其图像解析质量相同的应用中。在一些应用中,会关注更大的物体,因此,本文考虑了实例的大小,扩展了已经存在的 Covering metric用于评估图像解析质量- Parsing Covering (PC),定义如下。
 本文发现由于Covering无法计算背景类别,同时受其他类别假样本的影响,因此无法惩罚假样本。而在图像解析中需要考虑每个像素及类别,因此,上述情形是不存在的。
本文发现由于Covering无法计算背景类别,同时受其他类别假样本的影响,因此无法惩罚假样本。而在图像解析中需要考虑每个像素及类别,因此,上述情形是不存在的。
PQ与本文提出的PC的不同点在于,PC不进行匹配,因此也就不涉及匹配阈值,尝试将“stuff”与“thing”类同等对待,则如果分割的部分为正确的,则分割的“stuff”类仍可以部分接受PC score。比如,有三个大小相同的树,其中一棵被完美分割,则无论将树看作是“stuff”类还是“thing”类,使用PC进行评估,二者的分数是相同的。
实验



Reference
[1] Z. Tu, X. Chen, A. L. Yuille, and S.-C. Zhu, “Image parsing: Unifying segmentation, detection, and recognition,”
IJCV, 2005. 1, 2
[2] A. Kirillov, K. He, R. Girshick, C. Rother, and P. Dollár,“Panoptic segmentation,” arXiv:1801.00868, 2018. 1, 2, 3,
5, 6
[3] G. Neuhold, T. Ollmann, S. R. Bulò, and P. Kontschieder,“The mapillary vistas dataset for semantic understanding of
street scenes.,” in ICCV, 2017. 1, 2, 6
[4] P. Arbelaez, M. Maire, C. Fowlkes, and J. Malik, “Contour detection and hierarchical image segmentation,” PAMI,
2011. 2, 3, 5, 6
论文阅读笔记四十三:DeeperLab: Single-Shot Image Parser(CVPR2019)的更多相关文章
- 论文阅读笔记四:CTPN: Detecting Text in Natural Image with Connectionist Text Proposal Network(ECCV2016)
前面曾提到过CTPN,这里就学习一下,首先还是老套路,从论文学起吧.这里给出英文原文论文网址供大家阅读:https://arxiv.org/abs/1609.03605. CTPN,以前一直认为缩写一 ...
- 论文阅读笔记五十三:Libra R-CNN: Towards Balanced Learning for Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.02701.pdf github:https://github.com/OceanPang/Libra_R-CNN 摘要 相比模型的结构 ...
- 论文阅读笔记四十九:ScratchDet: Training Single-Shot Object Detectors from Scratch(CVPR2019)
论文原址:https://arxiv.org/abs/1810.08425 github:https://github.com/KimSoybean/ScratchDet 摘要 当前较为流行的检测算法 ...
- 论文阅读笔记四十八:Bounding Box Regression with Uncertainty for Accurate Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1809.08545.pdf github:https://github.com/yihui-he/KL-Loss 摘要 大规模的目标检测数据集在 ...
- 论文阅读笔记四十六:Feature Selective Anchor-Free Module for Single-Shot Object Detection(CVPR2019)
论文原址:https://arxiv.org/abs/1903.00621 摘要 本文提出了基于无anchor机制的特征选择模块,是一个简单高效的单阶段组件,其可以结合特征金字塔嵌入到单阶段检测器中. ...
- 论文阅读笔记四十四:RetinaNet:Focal Loss for Dense Object Detection(ICCV2017)
论文原址:https://arxiv.org/abs/1708.02002 github代码:https://github.com/fizyr/keras-retinanet 摘要 目前,具有较高准确 ...
- 论文阅读笔记六十三:DeNet: Scalable Real-time Object Detection with Directed Sparse Sampling(CVPR2017)
论文原址:https://arxiv.org/abs/1703.10295 github:https://github.com/lachlants/denet 摘要 本文重新定义了目标检测,将其定义为 ...
- 论文阅读笔记四十七:Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression(CVPR2019)
论文原址:https://arxiv.org/pdf/1902.09630.pdf github:https://github.com/generalized-iou 摘要 在目标检测的评测体系中,I ...
- 论文阅读笔记四十五:Region Proposal by Guided Anchoring(CVPR2019)
论文原址:https://arxiv.org/abs/1901.03278 github:code will be available 摘要 区域anchor是现阶段目标检测方法的重要基石.大多数好的 ...
随机推荐
- fetch和axios获取数据
fetch("/api/goods") .then(res => { return res.json(); }) .then(response => { console ...
- [模板] 区间mex && 区间元素种数
区间mex 问题 给定序列\({a_i}\), 每次询问给出\(l\), \(r\), 询问 \(\text{mex} \{a_i\}, i \in \{l, l+1, \cdots r\}\) 解法 ...
- poj 3764 The xor-longest Path (01 Trie)
链接:http://poj.org/problem?id=3764 题面: The xor-longest Path Time Limit: 2000MS Memory Limit: 65536K ...
- JMeter5.1开发TCP协议接口脚本
最简单的方法,就是找开发给报文,直接复制到tcp取样器中,将需要变化的值做参数化就可以了.(xml报文要去掉回车换行) 下面是一个通讯头定义 通讯头56个字节(1个字符一个字节) 3 + 9 + 9 ...
- Linux-Centos破解安装confluene6.3.1
Centos 安装企业wiki confluence是一个专业的企业知识管理与协同软件,可以用于构建企业wiki.通过它可以实现团队成员之间的协作和知识共享.现在大多数公司都会部署一套confluen ...
- 位运算之——按位与(&)操作——(快速取模算法)
学习redis 字典结构,hash找槽位 求槽位的索引值时,用到了 hash值 & sizemask操作, 其后的scan操作涉及扫描顺序逻辑,对同模的槽位 按一定规则扫描! 其中涉及位运算 ...
- 关于opencv的cv2.WINDOW_一类
用法:cv2.namedWindow('窗口标题',默认参数) 默认参数:cv2.WINDOW_AUTOSIZE+cv2.WINDOW_KEEPRATIO+cv2.WINDOW_GUI_EXPANDE ...
- Maven pom文件标签解析大全
<span style="padding:0px; margin:0px"><project xmlns="http://maven.apache.or ...
- Pycharm中Django安装配置Mongodb
一.安装mongo plugs插件 File->Setting Plugins查询Mongo选择Search in repositories 选择Mongo plugins,选择install ...
- wiki中文语料的word2vec模型构建
一.利用wiki中文语料进行word2vec模型构建 1)数据获取 到wiki官网下载中文语料,下载完成后会得到命名为zhwiki-latest-pages-articles.xml.bz2的文件,里 ...