记录几个爬取动态网页时的问题(下拉框,旧的元素无法获取,获取的源代码和f12看到的不一致,爬取延迟)
更新。。。。。这个动态网页其实直接抓取ajax请求就可以了,很简单,我之前想复杂了,虽然也实现了,但是效率极低,不过没关系,就当作是对Selenium的一次学习吧
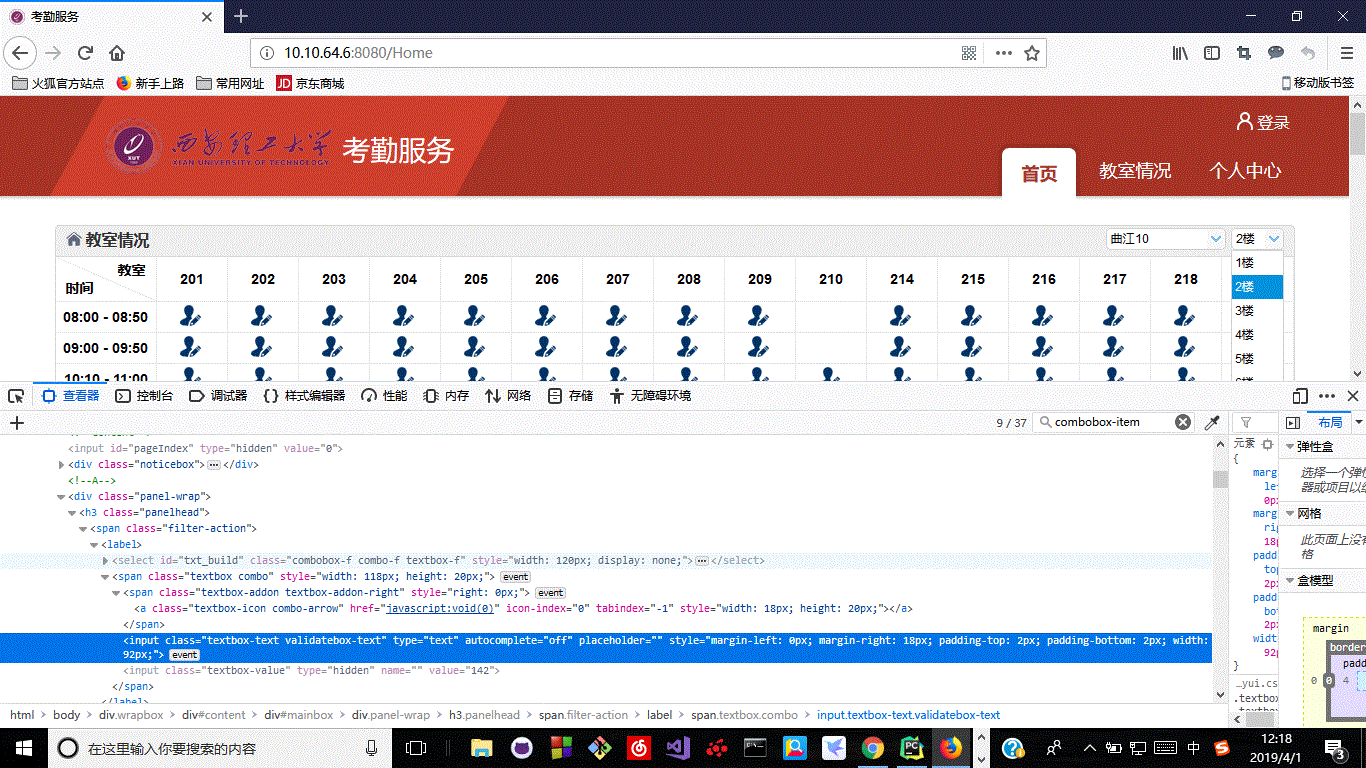
1.最近在爬取一个动态网页,其中为了更新页面,需要选择不同的选项,即对下拉框进行处理,这里的下拉框是用input实现的假的下拉框,但是他后面又有一个隐藏的select,我原本想着是将隐藏的select使用js脚本进行修改变得可见,之后进行点击等操作,但是使用网上方法之后,发现select可见到是可见了,但是点击之后却没有任何效果,各方搜索无果,最后决定自己解决这个问题,解决方案如下
思路使用selenium完全模拟人类的操作,一步一步点击可见的按钮
,一,定位下拉框按钮,并进行点击,
二,点击下拉框按钮之后会出现一个列表,定位这个列表之中的某一项元素,进行点击,注意这一步必须在下拉框按钮点击之后才能进行(使用time.sleep() 等待几秒,不然会提示点击内容不存在)
通过这两步,我们就可以改变动态网页的信息了,代码如下
def getButton(browser):
# 获取下拉框按钮
Button = browser.find_elements_by_class_name("textbox-icon") # 定位哪一栋楼按钮
buildButton = Button[]
floorButton = Button[]
buildingsAndFloors = browser.find_elements_by_class_name("combobox-item") # 楼选项
floors = buildingsAndFloors[:]
buildings = buildingsAndFloors[:]
info = dict()
info['floors'] = floors
info['buildings'] = buildings
info['buildButton'] = buildButton
info['floorButton'] = floorButton
return info
2.还有就是在爬取的时候,经常会提示点击的按钮或者什么不存在之类的,所以必须设置延迟才行,
3.动态网页有的你获取到的源代码和在网页上f12看到的不一样,我的解决方案是你先在网页上进行一次操作,之后再获取源代码就正常了
4.动态网页存在不断刷新问题,但是每次刷新之后,会提示你旧的元素不能够使用,所以这时你必须重新获取一次不能使用的信息才行,如下,getButton() 函数获取按钮信息,每次页面刷新后需要点击按钮时都重新进行获取,
# 获取某一栋楼某一层的信息所对应页面的源代码
def getSoup(buildNumber, floor):
info = getButton(browser)
info['buildButton'].click() # 点击指定楼
info['buildings'][buildNumber].click()
time.sleep()
info = getButton(browser) # 重新获取信息
time.sleep()
info['floorButton'].click() # 点击指定楼层
info['floors'][floor].click()
soup = BeautifulSoup(browser.page_source, 'html.parser')
return soup
记录几个爬取动态网页时的问题(下拉框,旧的元素无法获取,获取的源代码和f12看到的不一致,爬取延迟)的更多相关文章
- InstallShield Limited Edition for Visual Studio 国内注册时国家无下拉框解决方法
注册地址:http://learn.flexerasoftware.com/content/IS-EVAL-InstallShield-Limited-Edition-Visual-Studio 火狐 ...
- jquery+html三级联动下拉框及详情页面加载时的select初始化问题
html写的三个下拉框,如下: <select name="ddlQYWZYJ" id="ddl_QYWZYJ" class="fieldsel ...
- QTP测试.NET程序的时候,ComboBox下拉框控件选择后,运行时对象不可见解决方案
解决方法: 录制时,选择下拉框数据的时候,不要鼠标单击选择,而是要用ENTER(回车键)来选择,才能完成选择,这样录制就OK了.
- R语言爬取动态网页之环境准备
在R实现pm2.5地图数据展示文章中,使用rvest包实现了静态页面的数据抓取,然而rvest只能抓取静态网页,而诸如ajax异步加载的动态网页结构无能为力.在R语言中,爬取这类网页可以使用RSele ...
- python网络爬虫抓取动态网页并将数据存入数据库MySQL
简述以下的代码是使用python实现的网络爬虫,抓取动态网页 http://hb.qq.com/baoliao/ .此网页中的最新.精华下面的内容是由JavaScript动态生成的.审查网页元素与网页 ...
- 【转】详解抓取网站,模拟登陆,抓取动态网页的原理和实现(Python,C#等)
转自:http://www.crifan.com/files/doc/docbook/web_scrape_emulate_login/release/html/web_scrape_emulate_ ...
- selenium抓取动态网页数据
1.selenium抓取动态网页数据基础介绍 1.1 什么是AJAX AJAX(Asynchronouse JavaScript And XML:异步JavaScript和XML)通过在后台与服务器进 ...
- 使用scrapy-selenium, chrome-headless抓取动态网页
在使用scrapy抓取网页时, 如果遇到使用js动态渲染的页面, 将无法提取到在浏览器中看到的内容. 针对这个问题scrapy官方给出的方案是scrapy-selenium, 这是一个把sel ...
- scrapy和selenium结合抓取动态网页
1.安装python (我用的是2.7版本的) 2.安装scrapy: 详情请参考 http://blog.csdn.net/wukaibo1986/article/details/8167590 ...
随机推荐
- rocketmq 集群环境搭建配置
rocketmq环境搭建配置: 一. 搭建三主集群,环境:centos-64 7.4 + RocketMQ-4.3.2 Master01: 192.168.102.68 Master02: 192 ...
- python基础学习小结
Python是一门面向对象的解释性语言(脚本语言),这一类语言的特点就是不用编译,程序在运行的过程中,由对应的解释器向CPU进行翻译,个人理解就是一边编译一边执行.而JAVA这一类语言是需要预先编译的 ...
- JavaScript 高级
在线JS编辑 JS 编写规范 阮一峰 ES 6 阮一峰 廖雪峰 操作文件 <html> <head> <script src='./jquery-2.2.3.min.js ...
- 微信退款时候报”请求被中止: 未能创建 SSL/TLS 安全通道“或”The request was aborted: Could not create SSL/TLS secure channel“的错误
如题,英文中文表述的是一个意思 退款测试在我本机测试一切都是正常的,但是发布到了服务器就报这样的一个错啦 但是无论百度或者google或者bing,你能够搜索到的结果都很类似,综合起来就是加这样一些代 ...
- 认识Modbus协议
1.什么是Modbus? Modbus协议是应用于电子控制器上的一种通用语言.通过此协议,控制器相互之间,控制器经由网络(例如以太网)和其它设备之间可以通信.Modbus协议定义了一个控制器能认识使用 ...
- 解析中国天气网页面获取七日天气 (Java, Python)
说明 解析中国天气网的页面,获取七日天气. 使用 htmlparser .这是它的 API 文档. 代码 SevenDayWeather.java import java.io.BufferedRea ...
- Mac终端命令自动补全
在这里我们首先说一下mac终端执行命令的时候,不会像在windows系统中安装的linux一样支持自动补全,需要自己去调试 步骤如下: (1)打开终端输入nano .inputrc(这里一定要注意na ...
- 「JavaScript面向对象编程指南」对象
对象的属性名可加上引号,下面三行代码所定义的内容是完全相同的 var hero = { occupation : 1 }; var hero = { "occupation" : ...
- ARDUINO驱动LCD1602 (利用库函数)
LCD 1602简介 工业字符型液晶,能够同时显示16x02即32个字符.(16列2行) 1602液晶也叫1602字符型液晶,它是一种专门用来显示字母.数字.符号等的点阵型液晶模块.它由若干个5X7或 ...
- python时间模块小结
1.datetime 模块 为日期和时间处理同时提供了简单和复杂的方法.支持日期和时间算法的同时,实现的重点放在更有效的处理和格式化输出.该模块还支持时区处理: 简单例子: from datetime ...