Flink学习笔记-新一代Flink计算引擎
说明:本文为《Flink大数据项目实战》学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程:
Flink大数据项目实战:http://t.cn/EJtKhaz
新一代Flink计算引擎
(1) Flink概述
目前开源大数据计算引擎有很多的选择,比如流处理有Storm、Samza、Flink、Spark等,批处理有Spark、Hive、Pig、Flink等。既支持流处理又支持批处理的计算引擎只有Apache Flink和Apache Spark。
虽然Spark和Flink都支持流计算,但Spark是基于批来模拟流的计算,而Flink则完全相反,它采用的是基于流计算来模拟批计算。从技术的长远发展来看,Spark用批来模拟流有一定的技术局限性,并且这个局限性可能很难突破。而Flink基于流来模拟批,在技术上有更好的扩展性。所以大家把Flink称之为下一代大数据计算引擎。
从长远发展来看,阿里已经使用Flink作为统一的通用的大数据引擎,并投入了大量的人力、财力、物力。目前阿里巴巴所有的业务,包括阿里巴巴所有子公司都采用了基于Flink搭建的实时计算平台。同时Flink计算平台运行在开源的Hadoop集群之上。采用Hadoop的YARN做为资源管理调度,以 HDFS作为数据存储。因此,Flink可以和开源大数据框架Hadoop无缝对接。
基于目前市面上Flink资料比较少,而且不系统、不全面、不深入,在这里跟大家一起分享Flink大数据技术。本书中我们使用Flink1.6.2,它是目前最新的稳定版本,本书中我们既会讲到Flink批计算和流计算, 同时也会通过2个项目实战让大家学习的Flink技术能够快速应用到具体的项目实战中。
1. Flink定义
1.1简介
Apache Flink是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态计算。可部署在各种集群环境,对各种大小的数据规模进行快速计算。
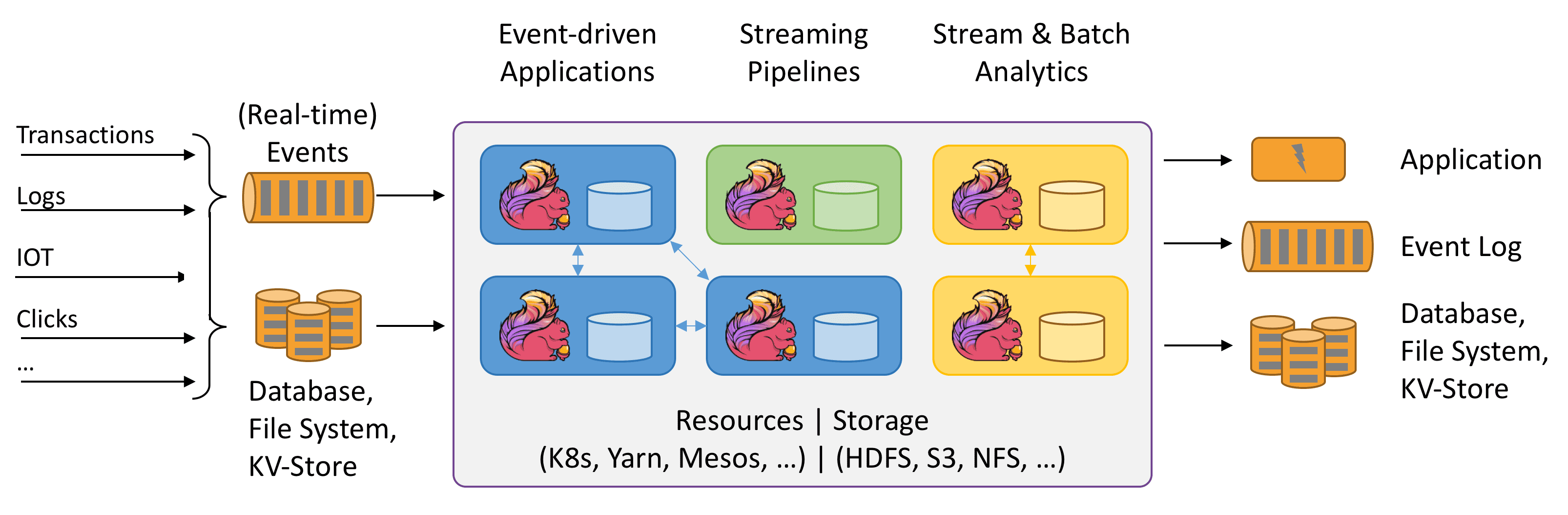
上图大致可以分为三块内容:左边为数据输入、右边为数据输出、中间为Flink数据处理。
Flink支持消息队列的Events(支持实时的事件)的输入,上游源源不断产生数据放入消息队列,Flink不断消费、处理消息队列中的数据,处理完成之后数据写入下游系统,这个过程是不断持续的进行。
数据源:
1.Clicks:即点击流,比如打开搜狐网站,搜狐网站页面上埋有很多数据采集点或者探针,当用户点击搜狐页面的时候,它会采集用户点击行为的详细信息,这些用户的点击行为产生的数据流我们称为点击流。
2.Logs:比如web应用运行过程中产生的错误日志信息,源源不断发送到消息队列中,后续Flink处理为运维部门提供监控依据。
3.IOT:即物联网,英文全称为Internet of things。物联网的终端设备,比如华为手环、小米手环,源源不断的产生数据写入消息队列,后续Flink处理提供健康报告。
4.Transactions:即交易数据。比如各种电商平台用户下单,这个数据源源不断写入消息队列,
后续Flink处理为用户提供购买相关实时服务。
数据输入系统:
Flink既支持实时(Real-time)流处理,又支持批处理。实时流消息系统,比如Kafka。批处理系统有很多,DataBase(比如传统MySQL、Oracle数据库),KV-Store(比如HBase、MongoDB数据库),File System(比如本地文件系统、分布式文件系统HDFS)。
Flink数据处理:
Flink在数据处理过程中,资源管理调度可以使用K8s(Kubernetes 简称K8s,是Google开源的一个容器编排引擎)、YARN、Mesos,中间数据存储可以使用HDFS、S3、NFS等,Flink详细处理过程后续章节详细讲解。
数据输出:
Flink可以将处理后的数据输出下游的应用(Application),也可以将处理过后的数据写入消息队列(比如Kafka),还可以将处理后的输入写入Database、File System和KV-Store。
1.2Flink的前世今生
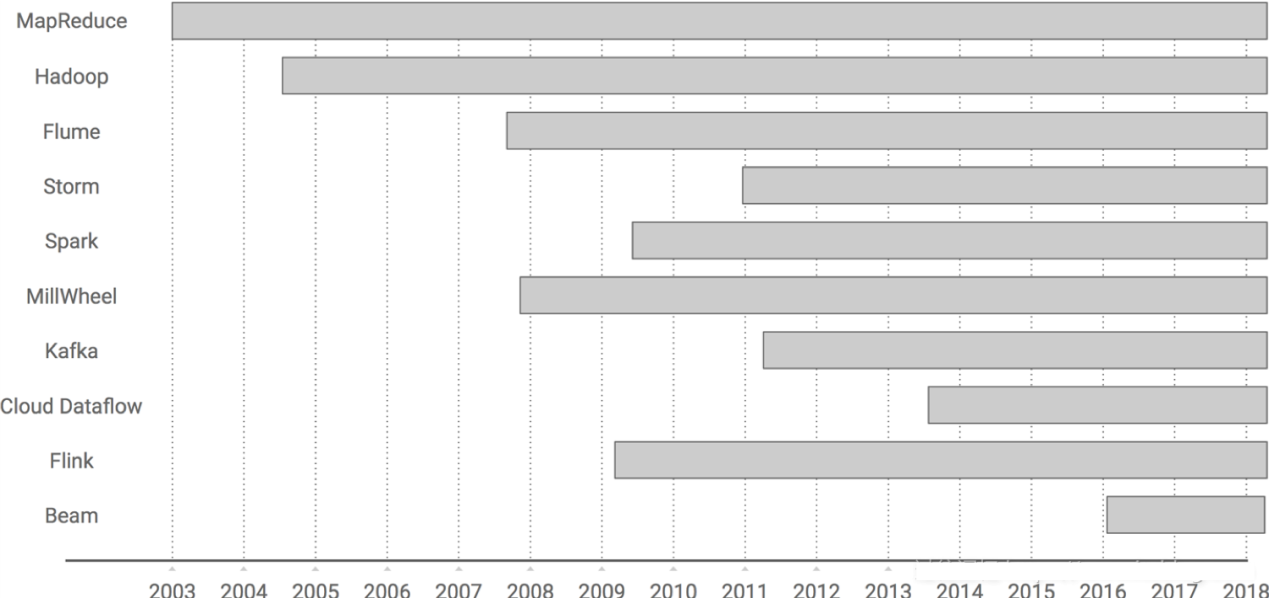
Hadoop在2005年左右诞生2009年刚刚崭露头角,这之后逐步受到各大公司的欢迎。Flink也早在2009年已经出现,此后一直默默无闻,但是直到在 2015 年突然出现在大数据舞台,然后似乎在一夜之间从一个无人所知的系统迅速转变为人人皆知的流式处理引擎。可以说Apache Flink起了个大早,赶了个晚集,主要原因在于很多流式计算框架往Hadoop迁移的过程中,发现当前流行的很多框架对流式处理对不是太好,即使是Storm,这个时候大家发现Apache Flink对流式处理支持的比较好,并逐步进入大家的视野,越来越受欢迎。
Flink在发展过程的关键时刻:
- 诞生于2009年,原来叫StratoSphere,是柏林工业大学的一个研究性项目,早期专注于批计算。
- 2014年孵化出Flink项目并捐给了Apache。
- 2015年开始引起大家注意,出现在大数据舞台。
- 2016年在阿里得到大规模应用。
1.3Flink的诞生

Flink诞生于欧洲的一个大数据研究项目,原名 StratoSphere。该项目是柏林工业大学的一个研究性项目,早期专注于批计算。2014 年,StratoSphere 项目中的核心成员孵化出 Flink,并在同年将 Flink 捐赠 Apache,后来 Flink 顺利成为 Apache 的顶级大数据项目。同时 Flink 计算的主流方向被定位为流计算,即用流式计算来做所有大数据的计算工作,这就是 Flink 技术诞生的背景。
1.4Flink崭露头角
2014 年 Flink 作为主攻流计算的大数据引擎开始在开源大数据行业内崭露头角。区别于 Storm、Spark Streaming 以及其他流式计算引擎的是:它不仅是一个高吞吐、低延迟的计算引擎,同时还提供很多高级功能。比如它提供有状态的计算,支持状态管理,支持强一致性的数据语义以及支持 Event Time,WaterMark 对消息乱序的处理等。
2015 年是流计算百花齐放的时代,各个流计算框架层出不穷。Storm, JStorm, Heron, Flink, Spark Streaming, Google Dataflow (后来的 Beam) 等等。其中 Flink 的一致性语义和最接近 Dataflow 模型的开源实现,使其成为流计算框架中最耀眼的一颗。也许这也是阿里看中 Flink的原因,并决心投入重金去研究基于 Flink的 Blink框架。

1.5Flink为何受青睐
Flink之所以受到越来越多公司的青睐,肯定有它很多过人之处。
1.支持批处理和数据流程序处理。
2.优雅流畅的支持java和scala api。
3.同时支持高吞吐量和低延迟。
4.支持事件处理和无序处理通过SataStream API,基于DataFlow数据流模型。
5.在不同的时间语义(事件时间,摄取时间、处理时间)下支持灵活的窗口(时间,滑动、翻滚,会话,自定义触发器)。
6.拥有仅处理一次的容错担保,Flink支持刚好处理一次。
7.拥有自动反压机制,当Flink处理数据达到上限的时候,源头会自动减少数据的输入,避免造成Flink应用的崩溃。
8.支持图处理(批)、 机器学习(批)、 复杂事件处理(流)。
9.在dataSet(批处理)API中内置支持迭代程序(BSP)。
10.高效的自定义内存管理和健壮的在in-memory和out-of-core中的切换能力。
11.同时兼容hadoop的mapreduce和storm。
12.能够集成YARN,HDFS,Hbase 和其它hadoop生态系统的组件。
2. Flink生态与未来
2.1核心组件栈
Flink发展越来越成熟,已经拥有了自己的丰富的核心组件栈,如下图所示。

从上图可以看出Flink的底层是Deploy,Flink可以Local模式运行,启动单个 JVM。Flink也可以Standalone 集群模式运行,同时也支持Flink ON YARN,Flink应用直接提交到YARN上面运行。另外Flink还可以运行在GCE(谷歌云服务)和EC2(亚马逊云服务)。
Deploy的上层是Flink的核心(Core)部分Runtime。在Runtime之上提供了两套核心的API,DataStream API(流处理)和DataSet API(批处理)。在核心API之上又扩展了一些高阶的库和API,比如CEP流处理,Table API和SQL,Flink ML机器学习库,Gelly图计算。SQL既可以跑在DataStream API,又可以跑在DataSet API。
2.2生态
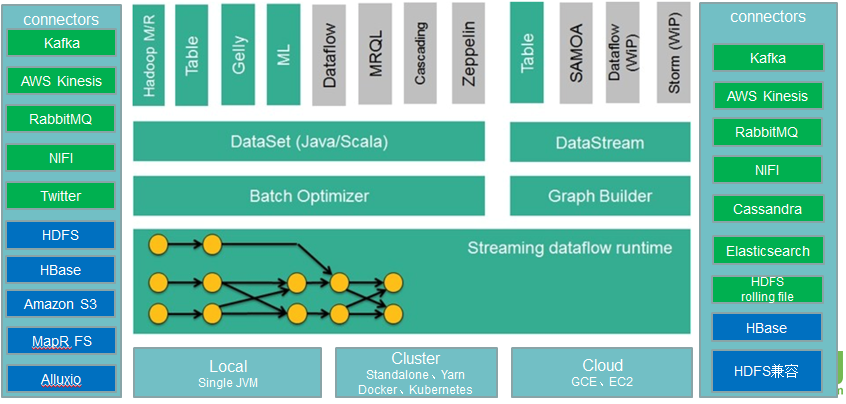
从上图可以看出Flink拥有更大更丰富的生态圈:
中间最底层Deploy模式包含 Local本地模式、Cluster(包含Standalone和YARN)集群模式以及Cloud云服务模式,然后它的上层是Flink runtime运行时,然后它的上层是Flink DataSet批处理和DataStream流处理,然后它的上层又扩展了Hadoop MR、Table、Gelly(图计算)、ML(机器学习)、Zoppelin(可视化工具)等等。
左边为输入Connectors。流处理方式包含Kafka(消息队列),AWS kinesis(实时数据流服务),RabbitMQ(消息队列),NIFI(数据管道),Twitter(API)。批处理方式包含HDFS(分布式文件系统),HBase(分布式列式数据库),Amazon S3(文件系统),MapR FS(文件系统),ALLuxio(基于内存分布式文件系统)。
右边为输出Connectors。流处理方式包含Kafka(消息队列),AWS kinesis(实时数据流服务),RabbitMQ(消息队列),NIFI(数据管道),Cassandra(NOSQL数据库),ElasticSearch(全文检索),HDFS rolling file(滚动文件)。批处理包含HBase(分布式列式数据库),HDFS(分布式文件系统)。
2.3未来
Flink会进行批计算的突破、流处理和批处理无缝切换、界限越来越模糊、甚至混合。
Flink会开发更多语言支持
Flink会逐步完善Machine Learning 算法库,同时 Flink 也会向更成熟的机器学习、深度学习去集成(比如Tensorflow On Flink)。
3. Flink应用场景
主要应用场景有三类:
1.Event-driven Applications【事件驱动】
2.Data Analytics Applications【分析】
3.Data Pipeline Applications【管道式ETL】
3.1 Event-driven Applications

上图包含两块:Traditional transaction Application(传统事务应用)和Event-driven Applications(事件驱动应用)。
Traditional transaction Application执行流程:比如点击流Events可以通过Application写入Transaction DB(数据库),同时也可以通过Application从Transaction DB将数据读出,并进行处理,当处理结果达到一个预警值就会触发一个Action动作,这种方式一般为事后诸葛亮。
Event-driven Applications执行流程:比如采集的数据Events可以不断的放入消息队列,Flink应用会不断ingest(消费)消息队列中的数据,Flink 应用内部维护着一段时间的数据(state),隔一段时间会将数据持久化存储(Persistent sstorage),防止Flink应用死掉。Flink应用每接受一条数据,就会处理一条数据,处理之后就会触发(trigger)一个动作(Action),同时也可以将处理结果写入外部消息队列中,其他Flink应用再消费。
典型的事件驱动类应用:
1.欺诈检测(Fraud detection)
2.异常检测(Anomaly detection)
3.基于规则的告警(Rule-based alerting)
4.业务流程监控(Business process monitoring)
5.Web应用程序(社交网络)
3.2 Data Analytics Applications

Data Analytics Applications包含Batch analytics(批处理分析)和Streaming analytics(流处理分析)。
Batch analytics可以理解为周期性查询:比如Flink应用凌晨从Recorded Events中读取昨天的数据,然后做周期查询运算,最后将数据写入Database或者HDFS,或者直接将数据生成报表供公司上层领导决策使用。
Streaming analytics可以理解为连续性查询:比如实时展示双十一天猫销售GMV,用户下单数据需要实时写入消息队列,Flink 应用源源不断读取数据做实时计算,然后不断的将数据更新至Database或者K-VStore,最后做大屏实时展示。
3.3 Data Pipeline Applications

Data Pipeline Applications包含Periodic (周期性)ETL和Data Pipeline(管道)
Periodic ETL:比如每天凌晨周期性的启动一个Flink ETL Job,读取传统数据库中的数据,然后做ETL,最后写入数据库和文件系统。
Data Pipeline:比如启动一个Flink 实时应用,数据源(比如数据库、Kafka)中的数据不断的通过Flink Data Pipeline流入或者追加到数据仓库(数据库或者文件系统),或者Kafka消息队列。
3.4阿里Flink应用场景
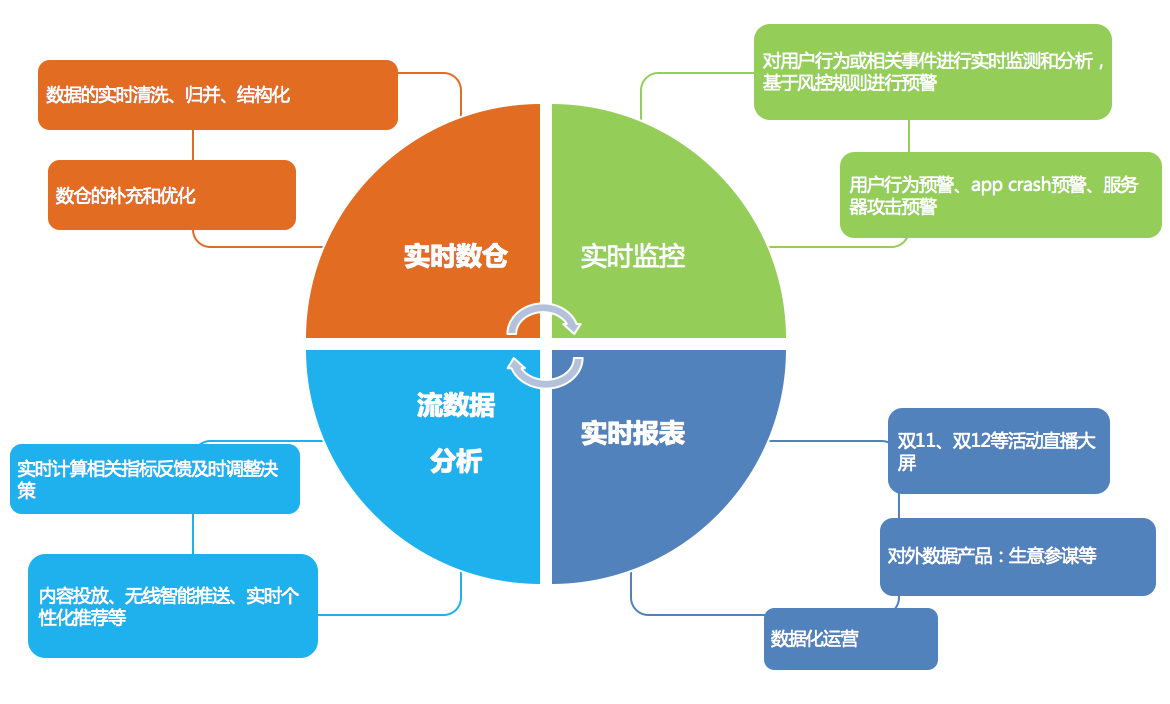
阿里在Flink的应用主要包含四个模块:实时监控、实时报表、流数据分析和实时仓库。
实时监控:
- 用户行为预警、app crash 预警、服务器攻击预警
- 对用户行为或者相关事件进行实时监测和分析,基于风控规则进行预警
实时报表:
- 双11、双12等活动直播大屏
- 对外数据产品:生意参谋等
- 数据化运营
流数据分析:
- 实时计算相关指标反馈及时调整决策
- 内容投放、无线智能推送、实时个性化推荐等
实时仓库:
- 数据实时清洗、归并、结构化
- 数仓的补充和优化
欺诈检测
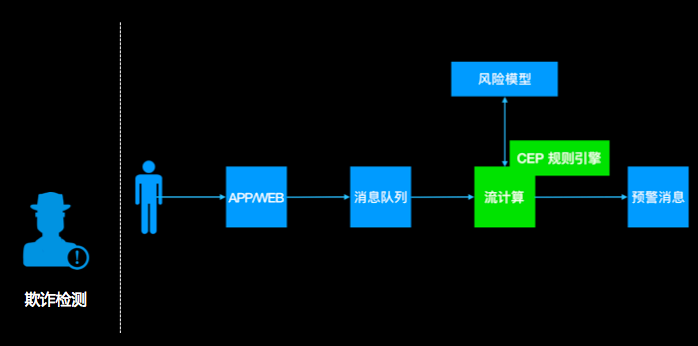
背景:
假设你是一个电商公司,经常搞运营活动,但收效甚微,经过细致排查,发现原来是羊毛党在薅平台的羊毛,把补给用户的补贴都薅走了,钱花了不少,效果却没达到。
怎么办呢?
你可以做一个实时的异常检测系统,监控用户的高危行为,及时发现高危行为并采取措施,降低损失。
系统流程:
1.用户的行为经由app 上报或web日志记录下来,发送到一个消息队列里去;
2.然后流计算订阅消息队列,过滤出感兴趣的行为,比如:购买、领券、浏览等;
3.流计算把这个行为特征化;
4.流计算通过UDF调用外部一个风险模型,判断这次行为是否有问题(单次行为);
5.流计算里通过CEP功能,跨多条记录分析用户行为(比如用户先做了a,又做了b,又做了3次c),整体识别是否有风险;
6.综合风险模型和CEP的结果,产出预警信息。
4. FlinkVSSpark
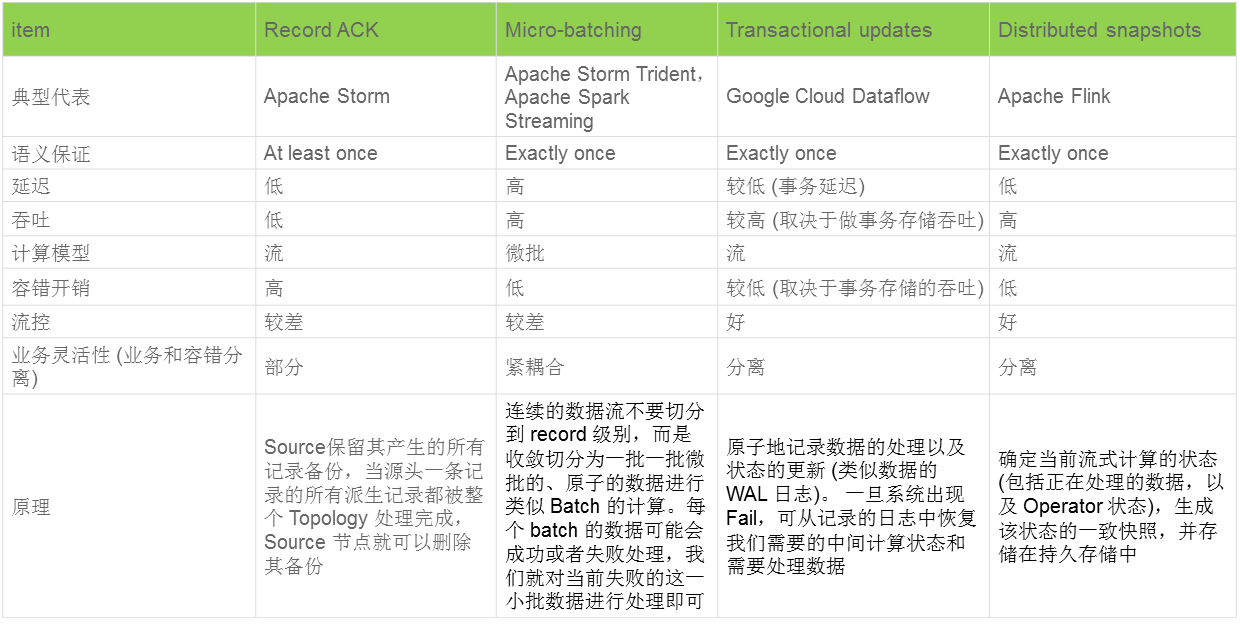
4.1流处理的几个流派
在流式计算领域,同一套系统需要同时兼具容错和高性能其实非常难,同时它也是衡量和选择一个系统的标准。
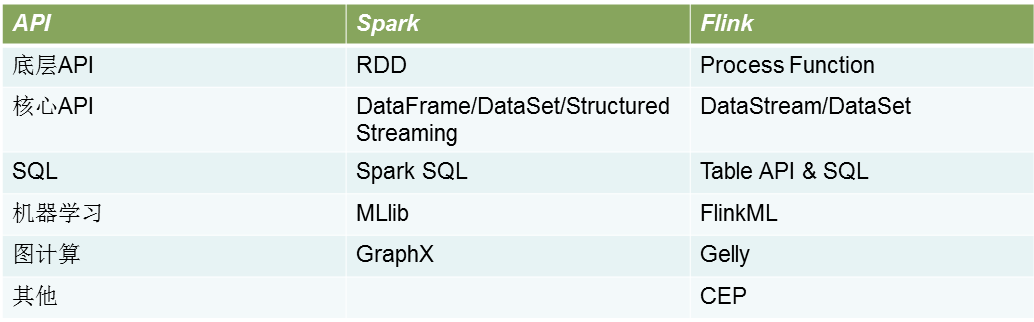
4.2Flink VS Spark 之 API
Spark与Flink API pk如下所示:
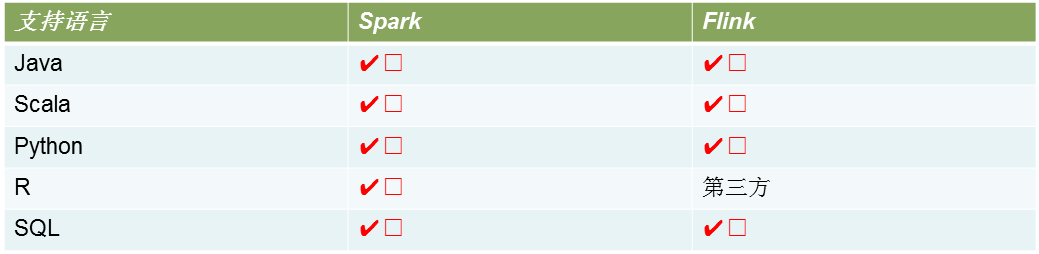
Spark与Flink 对开发语言的支持如下所示:
4.3 Flink VS Spark 之 Connectors
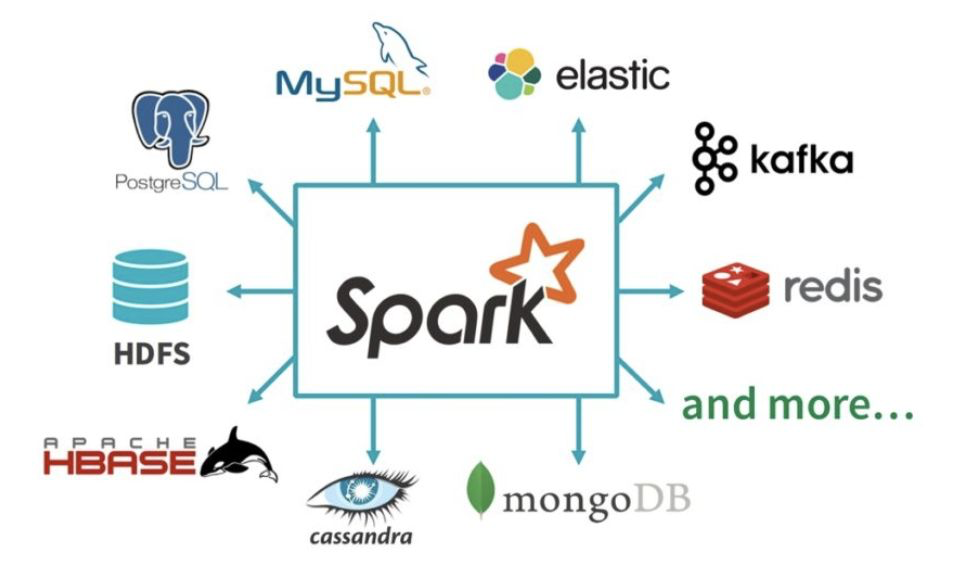
Spark 支持的Connectors如下所示:
Flink支持的Connectors如下所示:
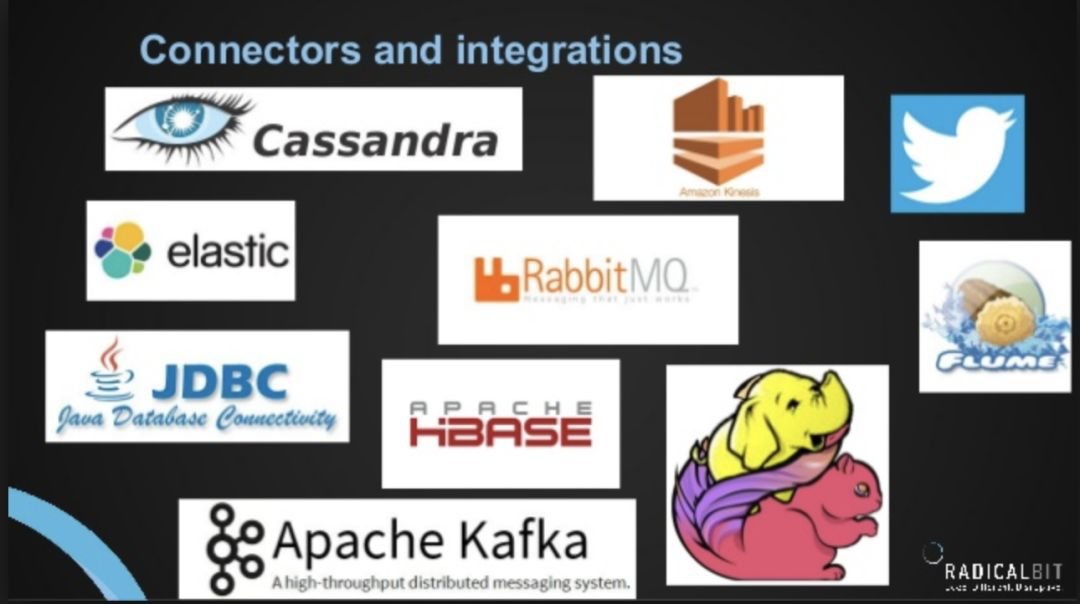
从Flink和Spark Connectors对比可以看出,Spark与Flink支持的Connectors的数量差不多,目前来说可能Spark支持更多一些,Flink后续的支持也会逐步的完善。
4.4 Flink VS Spark 之 运行环境
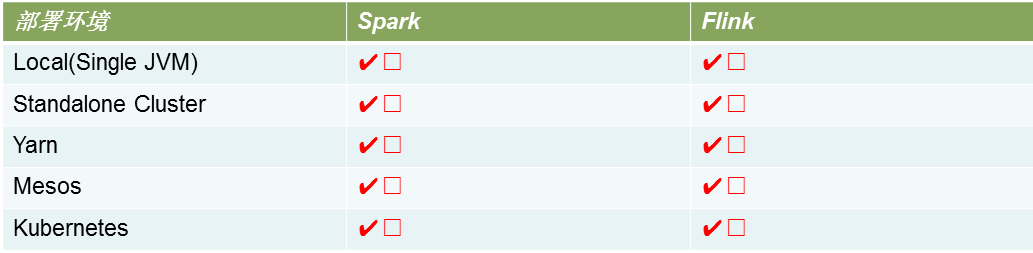
Spark 与Flink所支持的运行环境基本差不多,都比较广泛。
4.5 Flink VS Spark 之 社区
Spark 社区在规模和活跃程度上都是领先的,毕竟多了几年发展时间,同时背后的商业公司Databricks由于本土优势使得Spark在美国的影响力明显优于Flink
而且作为一个德国公司,Data Artisans 想在美国扩大影响力要更难一些。不过 Flink 社区也有一批稳定的支持者,达到了可持续发展的规模。
在中国情况可能会不一样一些。比起美国公司,中国公司做事情速度更快,更愿意尝试新技术。中国的一些创新场景也对实时性有更高的需求。这些都对 Flink 更友好一些。
近期 Flink 的中国社区有一系列动作,是了解 Flink 的好机会。
Flink 的中文社区在 :http://flink-china.org/
另外,2018 年 12 月 20 日 -21 日在国家会议中心举办的首届 Flink Forward China 峰会(千人规模),参与者将有机会了解阿里巴巴、腾讯、华为、滴滴、美团、字节跳动等公司为何将 Flink 作为首选的流处理引擎。
4.6总结
Spark 和 Flink 都是通用的开源大规模处理引擎,目标是在一个系统中支持所有的数据处理以带来效能的提升。两者都有相对比较成熟的生态系统。是下一代大数据引擎最有力的竞争者。
Spark 的生态总体更完善一些,在机器学习的集成和易用性上暂时领先。
Flink 在流计算上有明显优势,核心架构和模型也更透彻和灵活一些。
在易用性方面两者也都还有一些地方有较大的改进空间。接下来谁能尽快补上短板发挥强项就有更多的机会。
总而言之,Flink与Spark没有谁强谁弱,只有哪个更适合当前的场景。

Flink学习笔记-新一代Flink计算引擎的更多相关文章
- Flink学习笔记:Flink Runtime
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Flink API 通用基本概念
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Apache Flink学习笔记
Apache Flink学习笔记 简介 大数据的计算引擎分为4代 第一代:Hadoop承载的MapReduce.它将计算分为两个阶段,分别为Map和Reduce.对于上层应用来说,就要想办法去拆分算法 ...
- flink学习笔记-各种Time
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记:Flink开发环境搭建
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记:DataSream API
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Operators串烧
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Time的故事
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Operators之CoGroup及Join操作
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
随机推荐
- nSum “已知target再求和”类型题目总结:n-2重循环+left/right
Sum类的题目一般这样: input: nums[], target output: satisfied arrays/ lists/ number 拿到题目,首先分析: 1. 是几个数的sum 2. ...
- 手动制作CA证书
一.安装 CFSSL 证书下载官方地址:https://pkg.cfssl.org #下面三个安装包,无需下载,之前百度云中的压缩包中都有[root@linux-node1 ~]# cd /usr/l ...
- c语言伪常量const理解
const是伪常量,无法用于数组的初始化和全局变量的初始化,本质就是限定一个变量不能直接赋值. 如以下代码: #define A 10 int arr[A]; //const本质,伪常量 ,无法用于数 ...
- shell编程9*9乘法表
</pre>脚本内容<pre name="code" class="plain">#!/bin/bash for i in " ...
- MYISM表并发写请求过多 导致无法被读取解决方案
MyISAM锁调度是如何实现的呢,这也是一个很关键的问题.例如,当一个进程请求某个MyISAM表的读锁,同时另一个进程也请求同一表的写锁,此时MySQL将会如优先处理进程呢?通过研究表明,写进程将先获 ...
- lnmp 一键安装包 nginx配置tp5 phpinfo模式 隐藏index.php
tp5 url 线上访问 在nginx 上 出现404错误 那是因为pathinfo没有被支持 修改如下:找到 /usr/local/nginx/config/vhost/项目名.config s ...
- win7更改路由器wifi 密码
1.有线.无线都能进入192.168.1.1路由设置界面 (也可能是192.168.0.1看路由底面IP) ps: 无线(笔记本与路由没使用网线相连)情况下必须开启wifi连接上该路由才能进入. 无法 ...
- 书籍索引 #C++
卷 计算机 的文件夹 PATH 列表卷序列号为 00000200 0001:8890F:.│ 21天学通C++.pdf│ C++ Primer Plus 第6版 中文版.pdf│ C++ Templa ...
- 团队-Forward-团队一阶段互评
学号:2015035107105得分:4原因:代码不规范,有一些错误,需要我们的帮助. 学号:2015035107109得分:7原因:与队员沟通少,代码衔接有问题. 学号:2015035107113得 ...
- c+内存管理机制
内存管理是C++最令人切齿痛恨的问题,也是C++最有争议的问题,C++高手从中获得了更好的性能,更大的自由,C++菜鸟的收获则是一遍一遍的 检查代码和对C++的痛恨,但内存管理在C++中无处不在,内存 ...