Python中模块
模块
模块对我来说是什么
模块对我来说,感觉就像亲属或者朋友已经走过的路,他们已经趟过的浑水、掉过的坑、践行过的路线,全部提供给你,在你需要的时候请求帮助,借鉴他们的解决方法一样。都是为了方便走好人生路,用最短的路程走到成功的终点。
内置模块就像亲属,生来即有;自定义模块就像自己走过一次的路,吃一堑长一智做好了攻略,下次按攻略来就可以;第三方模块就像之后接触到的朋友,他们成功的经验借鉴给你,自己选择,规避坑陷。
模块调用的方法
import 模块名
from 模块名 import 方法名
emmm……python官方的开源模块库下载地址(防遗忘)
内置模块
time/datetime模块(还有一个calendar模块,只了解过)
处理与时间有关的,感觉目前时间模块我多用于测试(例如:time.sleep( ))和日志中。
特别重要,也是使用次数较多的:
在写方法前先解释下时间戳、结构化时间、字符串时间这些概念,当然也防止自己以后再看到时间戳的时候怀疑自己这是个啥玩意儿。
时间戳:1970纪元后经过的浮点秒数。
结构化时间:输出结果是这种的,以时间是由什么结构组成的输出,总之方便调用或修改。(tm_year,tm_mon,tm_mday,tm_hour,tm_min,tm_sec,tm_wday,tm_yday,tm_isdst)
字符串时间:就是正常显示的时间
time.time():获取当前时间的时间戳
这里例一个字符串时间t:
t='2019-01-01 10:00:00'
f=time.strptime(t,'%Y-%m-%d %X') 这一步是将字符串时间t转为结构化
f=time.mktime(f) 这一步是将结构化时间转为时间戳
f=time.localtime(f) 这一步是将时间戳转成结构化时间
f=time.strftime('%Y-%m-%d %X',f) 将结构化时间转为字符串时间
字符串转结构化用的是time.strptime()
结构化转为字符串用的是time.strftime()
我以strp和strf来区别,p代表输入,f代表格式化输出,当然这是我的区别方法,至于是不是真的代表这个意思就不是很清楚了。
time是datetime的底层模块,貌似我不怎么用到,这里就不详写了。
from datetime import datetime,timedelta # import datetime # print(datetime.now()) # # 时间对象 # f=datetime.now() # a=datetime.timestamp(datetime.now()) #将时间对象转换成时间戳 # print(datetime.fromtimestamp(a)) #将时间戳转成时间对象 print(datetime.now()-timedelta(days=2))
random、hmac模块(随机模块,做验证客户端合法性的hmac模块)
random模块特别重要,实现随机数功能,或随机抽取这种的都需要用到它。
import random 内置的 print(random.random()) 0-1之间随机小数 print(random.random(1,10)) 起始位置,终止位置 两头都包含 print(random.random(1,11,2)) 起始位置,终止位置(不包含),步长 print(random.choice([1,2,2])) 从可迭代、有序对象中随机选 print(random.choices([1,2,3],k=2)) 选择两个,但有重复 print(random.sample([1,2,3],k=2)) 选择两个,没有重复 li=[1,2,3,4,6] random.shuffle(li) 洗牌 打乱顺序 print(li)
hmac模块(做验证客户端合法性的,虽然我觉得它有可能不止用在验证合法性。)
os.urandom(32):随机的32位字节,每执行一次变一次
import os import hmac hmac=hmac.new(b’zhao’,os.urandom(32)) hmac.digest():以固定字节内容和随机内容组合加密,然后与客户端进行相同方法加密比较,如果相同则合法。
os模块
得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd()
返回指定目录下的所有文件和目录名:os.listdir()
函数用来删除一个文件:os.remove()
删除多个目录:os.removedirs(r“c:\python”)
检验给出的路径是否是一个文件:os.path.isfile()
检验给出的路径是否是一个目录:os.path.isdir()
判断是否是绝对路径:os.path.isabs()
检验给出的路径是否真地存:os.path.exists()
返回一个路径的目录名和文件名:os.path.split() e.g os.path.split('/home/swaroop/byte/code/poem.txt') 结果:('/home/swaroop/byte/code', 'poem.txt')
分离扩展名:os.path.splitext() e.g os.path.splitext('/usr/local/test.py') 结果:('/usr/local/test', '.py')
获取路径名:os.path.dirname()
获得绝对路径: os.path.abspath()
获取文件名:os.path.basename()
运行shell命令: os.system()
读取操作系统环境变量HOME的值:os.getenv("HOME")
返回操作系统所有的环境变量: os.environ
设置系统环境变量,仅程序运行时有效:os.environ.setdefault('HOME','/home/zhao')
给出当前平台使用的行终止符:os.linesep Windows使用'\r\n',Linux and MAC使用'\n'
指示你正在使用的平台:os.name 对于Windows,它是'nt',而对于Linux/Unix用户,它是'posix'
重命名:os.rename(old, new)
创建多级目录:os.makedirs(r“c:\python\test”)
创建单个目录:os.mkdir(“test”)
获取文件属性:os.stat(file)
修改文件权限与时间戳:os.chmod(file)
获取文件大小:os.path.getsize(filename)
结合目录名与文件名:os.path.join(dir,filename)
改变工作目录到dirname: os.chdir(dirname)
获取当前终端的大小: os.get_terminal_size()
杀死进程: os.kill(10884,signal.SIGKILL)

sys模块
这个模块我一般多用于反射和递归深度里
sys.argv 命令行参数List,第一个元素是程序本身路径.之后的元素会传入程序本身。第二个元素在sys.argv列表中索引为【1】
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout.write('please:') #标准输出 , 引出进度条的例子, 注,在py3上不行,可以用print代替
val = sys.stdin.readline()[:-1] #标准输入
sys.getrecursionlimit() #获取最大递归层数
sys.setrecursionlimit(1200) #设置最大递归层数
sys.getdefaultencoding() #获取解释器默认编码
sys.getfilesystemencoding #获取内存数据存到文件里的默认编码
序列化模块(json/pickle/shelve模块)
序列化:差不多就是把任何数据类型转换成str/bytes的过程。
import json/pickle/shelve
json模块:
json.load() 将文件中的字符串转换成字典 json.dump() 将字典转换成字符串写入到文件中 json.dumps() 将字典转换成字符串 json.loads() 将字符串转换成字典
pickle模块:
pickle.load() 将文件中的字节转换成字典 pickle.dump() 将字典转换成字节写入到文件中 pickle.dumps() 将字典转换成字节 pickle.loads() 将字节转换成字典
json和pickle的优缺点:
json:
优点:跨语言、体积小
缺点:只能支持Int\str\list\tuple\dict
pickle:
优点:专为python设计,支持python所有的数据类型
缺点:只能在python中使用,存储数据占空间大
shelve模块(不怎么了解,copy的):
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
序列化:
import shelve
f = shelve.open('shelve_test') # 打开一个文件
names = ["alex", "rain", "test"]
info = {'name':'alex','age':22}
f["names"] = names # 持久化列表
f['info_dic'] = info
f.close()
反序列化:
import shelve
d = shelve.open('shelve_test') # 打开一个文件
print(d['names'])
print(d['info_dic'])
#del d['test'] #还可以删除
hashlib模块(加密)
hashlib包括:MD5,sha1,sha256,sha512
加密步骤:
- 先导入模块
- 创建一个加密方式
- 将要加密的内容编码成字节后加密
- 生成密文
import hashlib md5 = hashlib.md5(b‘alex’) md5.update(‘alex3714’.encode(‘utf-8’)) print(md5.hexdigest())
logging模块(日志模块)
日志模块可以记录正常的访问操作日志,而且可以记录错误、警告等信息,可以更直观的告诉开发应该注意哪里的问题。
python的logging模块提供了标准的日志接口,你可以通过它存储各种格式的日志,logging的日志可以分为 debug(), info(), warning(), error() and critical()5个级别,下面我们看一下怎么用。
为什么要写日志
一个卡务系统 : 记录时间 地点 金额
谁在什么时候 删掉了某一个用户
某时某刻登录了系统
检测代码是不是像我们想像的这样执行的
写文件 ,输出到屏幕
f.write,print
时间格式,级别控制,更加便捷
*** logging模块不能自动生成你需要的日志
logging模块的使用
简单配置法 *** 编码问题
logger对象法 *****
import logging
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S')
logging.debug('debug message') # 调试
logging.info('info message') # 普通信息
logging.warning('warning message') # 警告
logging.error('error message') # 错误信息
logging.critical('critical message')# 严重错误
默认情况下 不打印warning以下级别的信息
1.中文显示乱码
2.不能同时输出到文件和屏幕
logger对象的方式来使用logging模块
首先 先创建logger对象
第二 创建一个文件操作符
第三 创建一个屏幕操作符
第四 创建一个格式
logger 绑定 文件操作符
logger 绑定 屏幕操作符
文件操作符 绑定格式
屏幕操作符 绑定格式
import logging
用logger
首先 先创建logger对象
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
第二 创建一个文件操作符
fh = logging.FileHandler('log',encoding='utf-8')
第三 创建一个屏幕操作符
sh = logging.StreamHandler()
第四 创建一个格式
fmt = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger 绑定 文件操作符
logger.addHandler(fh)
logger 绑定 屏幕操作符
logger.addHandler(sh)
文件操作符 绑定格式
fh.setFormatter(fmt)
屏幕操作符 绑定格式
sh.setFormatter(fmt)
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
re模块(正则)
正则表达式就是字符串的匹配规则,在多数编程语言里都有相应的支持,python里对应的模块是re。
常用的表达式规则:
'.' :默认匹配除\n之外的任意一个字符
'^':匹配字符开头
'$' :匹配字符结尾
'*' :匹配*号前的字符0次或多次
'+' :匹配前一个字符1次或多次
'?' :匹配前一个字符1次或0次
'{m}' :匹配前一个字符m次
'{n,m}' :匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' :匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' :分组匹配,re.search("(abc){2}a(123|45)", "abcabca456c").group() 结果为'abcabca45'
'\A' :只从字符开头匹配
'\Z' :匹配字符结尾,同$
'\d' :匹配数字0-9
'\D' :匹配非数字
'\w' :匹配[A-Za-z0-9]
'\W' :匹配非[A-Za-z0-9]
's' :匹配空白字符
'(?P<name>...)' :分组匹配
re的匹配语法:
找到所有的符合正则表达式的内容
ret=re.findall('正则表达式','内容')
print(ret)
找到第一个符合正则表达式的内容就停止,通过group取值,找不到时ret返回None,ret.group报错,所以一般if ret:和ret.group搭配使用。
ret=re.search('正则表达式','内容')
if ret:
print(ret.group())
从头开始找第一个。用ret.group取值
ret=re.match('正则表达式','内容')
print(ret.group())
找到符合条件的默认替换所有,设置换n次
ret=re.sub(‘正则表达式’,’新值’,’完整字符串’) ret=re.sub(‘正则表达式’,’新值’,’完整字符串’,’n’)
找到符合条件的替换,并返回出现了几次
ret=re.subn(‘正则表达式’,’新值’,’完整字符串’) print(ret)
分为列表
ret=re.split(‘\d+’,’内容’)
abc模块(抽象类)
抽象类概念:是一个特殊的类,只能被继承,不能实例化
抽象类的意义:抽象类中只能有抽象方法(没有实现功能),该类不能被实例化,只能被继承,且子类必须实现抽象方法。这一点与接口有点类似,但其实是不同的,看以下示例。
示例代码:
#一切皆文件
import abc #利用abc模块实现抽象类 class All_file(metaclass=abc.ABCMeta):
all_type='file'
@abc.abstractmethod #定义抽象方法,无需实现功能
def read(self):
'子类必须定义读功能'
pass @abc.abstractmethod #定义抽象方法,无需实现功能
def write(self):
'子类必须定义写功能'
pass # class Txt(All_file):
# pass
#
# t1=Txt() #报错,子类没有定义抽象方法 class Txt(All_file): #子类继承抽象类,但是必须定义read和write方法
def read(self):
print('文本数据的读取方法') def write(self):
print('文本数据的读取方法') class Sata(All_file): #子类继承抽象类,但是必须定义read和write方法
def read(self):
print('硬盘数据的读取方法') def write(self):
print('硬盘数据的读取方法') class Process(All_file): #子类继承抽象类,但是必须定义read和write方法
def read(self):
print('进程数据的读取方法') def write(self):
print('进程数据的读取方法') wenbenwenjian=Txt() yingpanwenjian=Sata() jinchengwenjian=Process() #这样大家都是被归一化了,也就是一切皆文件的思想
wenbenwenjian.read()
yingpanwenjian.write()
jinchengwenjian.read() print(wenbenwenjian.all_type)
print(yingpanwenjian.all_type)
print(jinchengwenjian.all_type)
multiprocessing模块(多进程模块)
第一次接触到它是在多进程中,使用它里面的Process类可以达到异步传输的效果,使用方法如下:
import time
from multiprocessing import Process
def func(a,b,c):
time.sleep(1)
print(a,b,c)
if __name__ == '__main__':
Process(target=func,args=(1,2,3)).start() #这里的target是目标的意思,固定搭配
Process(target=func,args=(2,3,4)).start() #所有的Process()都是子进程,子进程都放在if下。
Process(target=func,args=(3,4,5)).start()
开启的子进程:
需要注意的是:下面标红区域必须是元组,当只传一个值时,必须也为元组形式。
import time
from multiprocessing import Process
def func(a):
time.sleep(1)
print(a)
if __name__ == '__main__':
Process(target=func,args=(1,)).start()
Process(target=func,args=(2,)).start()
multiprocessing中的方法:
Lock 锁
同一时间点上只有一个进程可以进行操作,lock.acquire() 获取钥匙 如果这个人没拿走钥匙,那么就可以直接进入下面的代码;如果有人拿走了钥匙,则需等待钥匙归还后才可以进入下面的代码。lock.release() 归还钥匙
锁的应用场景:当多个进程需要操作同一个文件/数据库时,需要通过加锁
Queue 队列
队列是进程安全的,自带了锁调节生产者的个数或者消费者的个数来让程序的效率达到最平衡和最大化
Manager 共享资源
Manager类的作用共享资源,manger的的优点是可以在poor进程池中使用,缺点是windows下环境下性能比较差,因为windows平台需要把Manager.list放在if name='main'下,而在实例化子进程时,必须把Manager对象传递给子进程,否则lists无法被共享,而这个过程会消耗巨大资源,因此性能很差。
threading模块(处理多线程)
threading模块和multiprocessing模块
先有的threading模块
没有池的功能
multiprocessing完全模仿threading模块完成的
实现了池的功能
concurrent.futures
实现了线程池\进程池
一个进程中的多线程:
import os
import time
from threading import Thread
def func(i):
time.sleep(1)
print('in func', i,os.getpid())
print('in main', os.getpid())
for i in range(20):
Thread(target=func,args=(i,)).start()
注:
在线程部分不需要通过import来为新的线程获取代码
因为新的线程和之前的主线程共享同一段代码
不需要import 也就不存在在子线程中又重复了一次创建线程的操作
所以就不必要if __name__==’__main__’
threading 与 multiprocessing效率对比(代码):
import time
from multiprocessing import Process
from threading import Thread
def func(a):
a += 1
if __name__ == '__main__':
start = time.time()
t_l = []
for i in range(100):
t = Thread(target=func, args=(i,)) #多线程
t.start()
t_l.append(t)
for t in t_l: t.join()
print('Thread :', time.time() - start)
start = time.time()
t_l = []
for i in range(100):
t = Process(target=func, args=(i,)) #多进程
t.start()
t_l.append(t)
for t in t_l: t.join()
print('Process', time.time() - start)
结果:
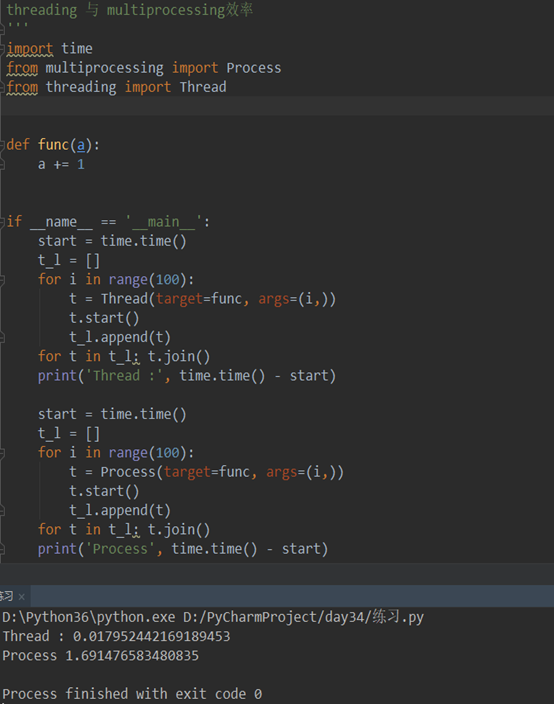
多个线程之间的全局变量是共享的,进程是数据隔离的(代码):
from threading import Thread
tn = 0
def func():
global tn
tn += 1
t_l = []
for i in range(100):
t = Thread(target=func)
t.start()
t_l.append(t)
for t in t_l: t.join()
print(tn)
结果:
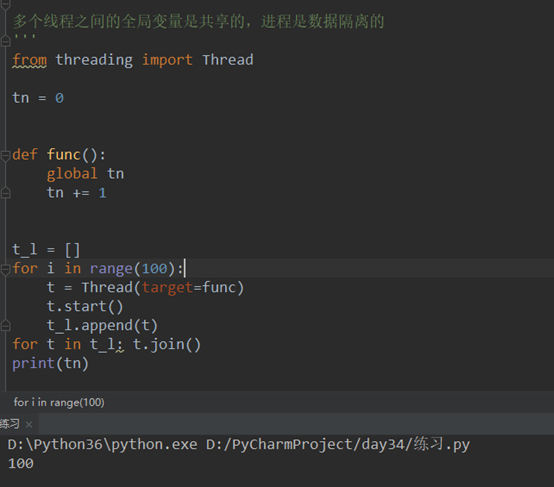
进程是数据隔离的(代码):
from multiprocessing import Process
pn = 0
def func():
global pn
pn += 1
if __name__ == '__main__':
p_l = []
for i in range(100):
p = Process(target=func)
p.start()
p_l.append(p)
for p in p_l: p.join()
print(pn)
结果:
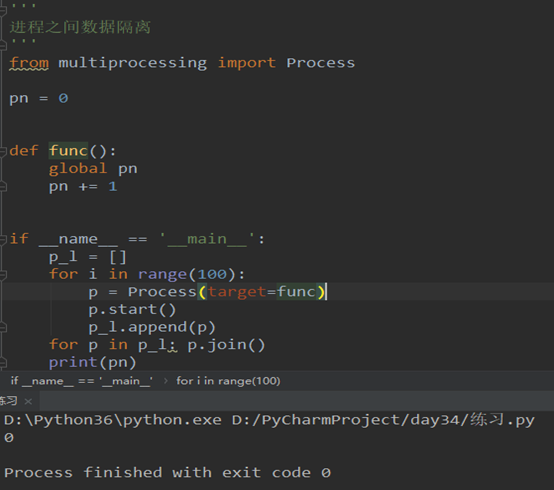
threading模块提供的方法:
threading.currentThread(): 返回当前的线程变量。
threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
import os
from threading import Thread, currentThread
def func():
t = currentThread()
print(t.name, t.ident, os.getpid())
tobj = Thread(target=func)
tobj.start()
print('tobj :', tobj)
t2 = currentThread()
print(t2.name, t2.ident, os.getpid())
线程有terminate么?
没有terminate 不能强制结束
所有的子线程都会在执行完所有的任务之后自动结束
Python中模块的更多相关文章
- Python中模块之os的功能介绍
Python中模块之os的功能介绍 1. os的变量 path 模块路径 方法:os.path 返回值:module 例如:print(os.path) >>> <module ...
- 查看python中模块的所有方法
查看python中模块的所有方法 安装的python模块,现将查看方法总结如下 一.CMD命令行下使用pydoc命令 在命令行下运行$ pydoc modules即可查看 二.在python交 ...
- [python]关于在python中模块导入问题追加总结
[背景] 最近在写程序时,我使用的eclipse编辑器运行都没有问题,然后部署到自动化环境上却偏偏报找不到相应模块问题,现在对该问题在之前的贴子上追加总结 原帖子:[python]关于python中模 ...
- [笔记]Python中模块互相调用的例子
python中模块互相调用容易出错,经常是在本地路径下工作正常,切换到其他路径来调用,就各种模块找不到了. 解决方法是通过__file__定位当前文件的真实路径,再通过sys.path.append( ...
- 关于python中模块的import路径
前两天被一个同事问了一个python的问题: 为什么一个目录里的python文件引用不要另一个兄弟目录的python文件,但是这两个目录的父母录运行时是可以引用到了.当时感觉一直是模块和包的机制问题, ...
- Python中模块之time&datetime的功能介绍
time&datetime的功能介绍 1. time模块 1. 时间的分类 1. 时间戳:以秒为单位的整数 2. 时间字符格式化:常见的年月日时分秒 3. 时间元祖格式:9大元素,每个元素对应 ...
- Python中模块json与pickle的功能介绍
json & pickle & shelve 1. json的序列化与反序列化 json的使用需要导入该模块,一般使用import json即可. json的序列化 方法1:json. ...
- Python中模块之copy的功能介绍
模块之copy的功能介绍 copy主要分两种: 1.浅拷贝 2.深拷贝 赋值: 在python中赋值算特殊的拷贝,其实赋值可以理解为同一个对象有两个名字,所以当其中一个发生变化,另一个也跟着会变化. ...
- python中模块的__all__属性
python模块中的__all__属性,可用于模块导入时限制,如:from module import *此时被导入模块若定义了__all__属性,则只有__all__内指定的属性.方法.类可被导入. ...
- Python中模块的发布与安装
模块(Module) Python中有一个概念叫做模块(module),这个和C语言中的头文件以及Java中的包很类似,比如在Python中要调用sqrt函数,必须用import关键字引入math这个 ...
随机推荐
- 使用WICleanup清理Windows Installer 冗余文件
使用WICleanup清理Windows Installer 冗余文件 | 浏览:816 | 更新:2015-11-02 10:43 | 标签:Win7 Win10 1 2 3 4 5 6 7 分步阅 ...
- 微信小程序开发9-宿主环境(2)
1.一个小程序页面可以分解成多个部分组成,组件就是小程序页面的基本组成单元.为了让开发者可以快速进行开发,小程序的宿主环境提供了一系列基础组件.组件是在WXML模板文件声明中使用的,WXML的语法和H ...
- php 空格无法替换,utf-8空格惹的祸
一次坑爹的小bug.读取一段文字(编码utf-8),想替换掉空格,str_replace(" "..).preg_replace("/\s/"..)都不起作用. ...
- FTP上传和WEB上传的区别
说区别之前,咱先说说什么是上传?上传就是将信息从个人计算机(本地计算机)传递到中央计算机(远程计算机)系统上,让网络上的人都能看到.将制作好的网页.文字.图片等发布到互联网上去,以便让其他人浏览 ...
- resin发布spring-boot项目报错“java.lang.NoSuchMethodError: org.jboss.logging.Logger.getMessageLogger”
说白了还是jar包冲突问题,直接说解决方式: 首先将resin/lib下的validation-api-1.0.0.GA.jar替换成项目中的包validation-api-2.0.1.Final.j ...
- Exchange2016 & Skype for business 集成之三统一联系人存储
Exchange2016&Skype for business集成之二统一联系人存储 利用统一的联系人存储库,用户可以维护单个联系人列表,然后使这些联系人适用于多个应用程序,包括 Skype ...
- linux 三大利器 grep sed awk 正则表达式
正则表达式目标 正则表达式单字符: 特定字符 范围字符:单个字符[ ] :代表查找单个字符,括号内为字符范围 数字字符:[0-9],[259] 查找 0~9 和 2.5 .9 中的任意一个字符 小写字 ...
- Java中的Scanner类
java.util.Scanner是Java5的新特征,我们可以通过Scanner类来获取用户的输入.创建Scanner对象的基本语法: Scanner s = new Scanner(System. ...
- 没有什么问题是sudo rm -rf /* 解决不了的
没有什么问题是sudo rm -rf /* 解决不了的. . . . . . . 如果有的话,赶紧跑.
- [19/04/15-星期一] 基于Socket(套接字)的TCP和UDP通讯的实现
一.TCP 在网络通讯中,第一次主动发起通讯的程序被称作客户端(Client)程序,简称客户端,而在第一次通讯中等待连接的程序被称作服务器端(Server)程序, 简称服务器.一旦通讯建立,则客户端和 ...