python 3.x 爬虫基础---Requersts,BeautifulSoup4(bs4)
python 3.x 爬虫基础
python 3.x 爬虫基础---http headers详解
python 3.x 爬虫基础---Requersts,BeautifulSoup4(bs4)
前言
其实前两章都是python内置的爬虫函数,大家都知道python有强大的第三方库,今天我们就来说一下requests,BeautifulSoup4,selenium,lxml ,顺便正则re也会在这篇文章中提及。
Requersts
参考文档:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
python实现的简单易用的HTTP库(第三方库记得去导入)你不需要手动为 URL 添加查询字串,也不需要对 POST 数据进行表单编码。Keep-alive 和 HTTP 连接池的功能是 100% 自动化的,一切动力都来自于根植在 Requests 内部的 urllib3,使用起来比urllib简洁很多。上面的得文档有详细的介绍,所以如果想系统的学习就直接观看文档即可。
操作属性
import requests
response = requests.get('http://www.baidu.com')
print('文本形式的网页源码')
print(response.text)
print('二进制流形式打印')
print(response.content)
print('返回JSON格式,可能抛出异常')
print(response.json)
print('状态码')
print(response.status_code)
print('请求url')
print(response.url)
print('头信息')
print(response.headers)
print('cookie信息')
print(response.cookies)
看一下运行结果:

传递参数
import requests
payload = {'key1': 'value1', 'key2': 'value2', 'key3': None}
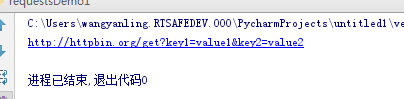
r = requests.get('http://httpbin.org/get', params=payload)
print(r.url)
运行结果:
传递headers
这个在python 3.x 爬虫基础---http headers详解 有详细的介绍不管是urllib还是request headers都是至关重要的,在这不过多叙述有兴趣的自己去看一下吧。
请求方式
requests.get('http://httpbin.org/get')
requests.post('http://httpbin.org/post')
requests.put('http://httpbin.org/put')
requests.delete('http://httpbin.org/delete')
requests.head('http://httpbin.org/get')
requests.options('http://httpbin.org/get')
post访问
通常,你想要发送一些编码为表单形式的数据—非常像一个HTML表单。 要实现这个,只需简单地传递一个字典给 data 参数。你的数据字典 在发出请求时会自动编码为表单形式:
import requests
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.post("http://httpbin.org/post", data=payload)
print(r.text)
运行结果:

传递文件:
import requests
url = 'http://httpbin.org/post'
files = {'file': open('wyl.xls', 'rb')}
r = requests.post(url, files=files)
这个方式对你传递的复杂参数有很好的控制。
传递字符串:
import requests
import json
url = 'https://xxxxxxxx'
payload = {'some': 'data'}
r = requests.post(url, data=json.dumps(payload))
#或者
r = requests.post(url, json=payload)
提示:选择适当的http访问。
超时设置
requests.get('http://xxxxx.com', timeout=1)
注:timeout 仅对连接过程有效,与响应体的下载无关。 timeout 并不是整个下载响应的时间限制,而是如果服务器在 timeout 秒内没有应答,将会引发一个异常。
代理
import requests
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080',
}
requests.get('http://xxxx.com', proxies=proxies)
防爬虫会涉及到ip限制,所以ip代理在爬虫中会常用到,还有vpn代理等等吧。
重定向与请求历史
默认情况下,除了 HEAD, Requests 会自动处理所有重定向。可以使用响应对象的 history 方法来追踪重定向,head可以通过 allow_redirects 参数禁用重定向处理。
import requests
s=requests.get('http://github.com')
print(s.url)
print(s.status_code)
r=requests.get('http://github.com', allow_redirects=False)
print(r.url)
print(r.history)
r=requests.head('http://github.com');
print(r.url)
print(r.status_code)
r=requests.head('http://github.com', allow_redirects=True)
print(r.url)
print(r.history)
运行结果:

异常处理
所有Requests显式抛出的异常都继承自 requests.exceptions.RequestException
import requests
from requests.exceptions import ReadTimeout,HTTPError,RequestException
try:
response = requests.get('http://www.baidu.com',timeout=0.5)
print(response.status_code)
except ReadTimeout:
print('timeout')
except HTTPError:
print('httperror')
except RequestException:
print('reqerror')
HTTPError:如果 HTTP 请求返回了不成功的状态码
Timeout:请求超时
ConnectionError:遇到网络问题(如:DNS 查询失败、拒绝连接等)
TooManyRedirects:若请求超过了设定的最大重定向次数
RequestException:所有的requerst 异常
requests登陆的几种方法
通过账号与密码
loginurl='https://xxxxx.com/check'
formData={'username':'*****',
'password':'*****'}
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:9.0.1) Gecko/20100101 Firefox/52.0'}
res=req.post(loginurl,data=formData,headers=headers)
通过cookies
raw_cookies="k1=v1; k2=v2; k3=v3;
cookies={}
for line in raw_cookies.split(';'):
key,value=line.split('=',1)
cookies[key]=value
loginurl='http://xxxxxx.com'
res=req.post(loginurl,cookies=cookies)
print res.content
"访问其它的页面"
logi1="http://xxxxx.htm"
print req.post(logi1,cookies=cookies).content
其中的cookies获取后将cookies的值以字典的方式存储,然后进行使用
通过session
import requests as req
s=req.Session()
param={'username':'****',
'password':'***'}
url='https://xxxxxx'
r=s.post(url,data=param,verify=False) #登录获取登录后的session
print r.content
print s.get('http://xxxxxxx',verify=False).content #通过session访问其它url
如果有ssl认证,可以在post的时候,加入认证的参数,取消ssl的认证校验 requests.post(url,data=dataform,verify=False)
BeautifulSoup4(bs4)
参考文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.urllib或者request请求完之后,就要对其操作,那么下面就来操作吧。其实可以把它理解为js/css中的选择器来使用。
解析器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是LXML ,后面会有介绍。

对象的种类
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSoup , Comment
#1.tag
此对象与html和xml 中的tag相同
soup = BeautifulSoup('<div class="className">wangyanling</div>')
tag = soup.div
print('tag 对象输出:')
print(tag)
print('查看类型')
print(type(tag))
print('#获取tag的名字')
print(tag.name)
print('#Attributes')
print('#Attributes:获取tag的属性值 注tag是有多个属性')
print(tag['class'])
print('添加属性')
tag['id']='wylId'
print(tag)
print('#删除属性')
del tag['class']
print(tag)
print('#多值属性')
css_soup = BeautifulSoup('<p class="body strikeout"></p>')
print(css_soup.p['class'])
print('#不明确的多值属性')
id_soup = BeautifulSoup('<p id="my id"></p>')
print(id_soup.p['id'])
print('# 重新赋值')
print('#重复的值会进行合并')
rel_soup = BeautifulSoup('<p>Back to the <a rel="index">homepage</a></p>')
print(rel_soup.a['rel'])
rel_soup.a['rel'] = ['index', 'contents']
print(rel_soup.p)
print('xml 多值属性')
'''xml_soup = BeautifulSoup('<p class="body strikeout"></p>', 'xml')
print(xml_soup.p['class'])'''
输出结果:


#2.NavigableString
操作标签吓得字符串,我们就要用到NavigableString 类
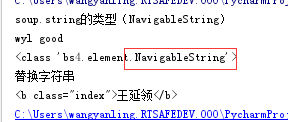
soup = BeautifulSoup('<b class="index">wyl good</b>')
print('soup.string的类型(NavigableString)')
print(soup.string)
print(type(soup.string))
print('替换字符串')
soup.string.replace_with("王延领")
print(soup)
输出结果:
注:一个字符串不能包含其它内容(tag能够包含字符串或是其它tag),字符串不支持 .contents 或 .string 属性或 find() 方法.
#3.BeautifulSoup
表示的是一个文档的全部内容,大部分时候,可以把它当作 Tag 对象。它支持 遍历文档树 和 搜索文档树 中描述的大部分的方法.他是没有name合attribute的。
#4.Comment
以上三个对象几乎包换了你所有html与xml的内容,但是你是不是觉得还有一个东西没有涉及到,那就是html xml不编辑的注解。
markup = "<b><!--我是一个注释不要意思--></b>"
soup = BeautifulSoup(markup)
comment = soup.b.string
print('html中的注释')
print(comment)
print(type(comment))
输出结果:

看输出Comment是不是一个特殊的NavigableString管他呢。
遍历文档树
上面有提到遍历文档树与搜索文档树,那么就来一起学习一下。其实从名字就能知道踏实去循环遍历获取html xml内容的。
我们可以把它分为子节点,父节点,兄弟节点,回退与前进是不是css/js选择器的感觉其实差不多。
为了方便我写了一些html
html_doc = """
<html>
<head>
<title>The Dormouse's story</title>
<stype>
.body{
color:red;
}
</stype>
</head>
<p class="title"><b>这是一个不太好的html</b></p>
<p class="story">这是一个段落
<a href="http:http://www.cnblogs.com/kmonkeywyl/p/8482962.html%20" id="link1">python 3.x 爬虫基础---常用第三方库</a>,
<a href="http://www.cnblogs.com/kmonkeywyl/p/8458442.html" class="sister" id="link2">python 3.x 爬虫基础---Urllib详解</a>
<a href="http://www.cnblogs.com/kmonkeywyl/p/8435533.html" class="sister" id="link3">python 3.x 爬虫基础---http headers详解</a>;
</p>
<p class="story">...</p>
"""
#1.子节点
soup = BeautifulSoup(html_doc)
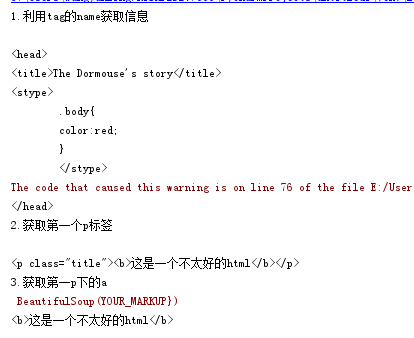
print('1.利用tag的name获取信息')
print(soup.head)
print('2.获取第一个p标签')
print(soup.p)
print('3.获取第一p下的a')
print(soup.p.b)
print('4.tag的 .contents 属性可以将tag的子节点以列表的方式输出')
head_tag = soup.head
print(head_tag)
print(head_tag.contents)
print('5.通过tag的 .children 生成器,可以对tag的子节点进行循环')
i=0
for child in head_tag.children:
print(i)
i=i+1
print(child)
print('6.descendants 操作soup的子孙节点(包括字符串)')
for child in head_tag.descendants:
print(i)
i=i+1
print(child)
print('7.如果tag只有一个 NavigableString 类型子节点,那么这个tag可以使用 .string 得到子节点')
s_titl=soup.title
print(s_titl.string)
print('8.如果有多个字符串可以用strings循环获得')
for string in soup.strings:
print(repr(string))
print('9.stripped_strings去除空格')
for string in soup.stripped_strings:
print(repr(string))




#2.父节点
print('通过 .parent 属性来获取某个元素的父节点')
soup = BeautifulSoup(html_doc)
title_tag = soup.title
print(title_tag)
print('title 父节点')
print(title_tag.parent)
print('html 的父节点')
html_tag = soup.html
print(type(html_tag.parent))
print('BeautifulSoup的父节点 ')
print(soup.prent)
print('通过元素的 .parents 属性可以递归得到元素的所有父辈节点')
link = soup.a
for parent in link.parents:
if parent is None:
print(parent)
else:
print(parent.name)
输出结果:


#3.兄弟节点
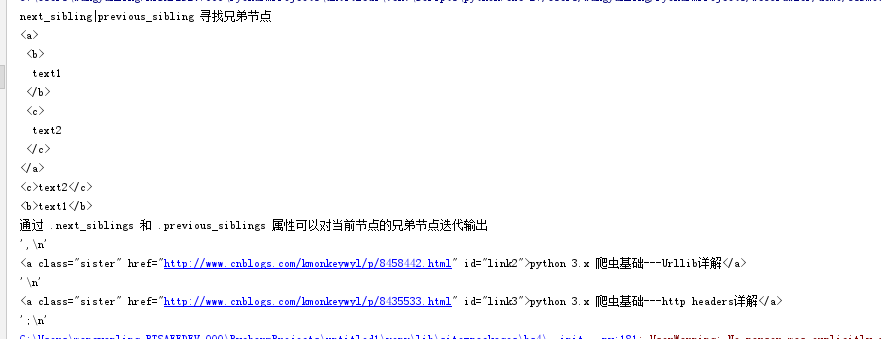
sibling_soup = BeautifulSoup("<a><b>text1</b><c>text2</c></a>")
print('next_sibling|previous_sibling 寻找兄弟节点')
print(sibling_soup.prettify())
print(sibling_soup.b.next_sibling)
print(sibling_soup.c.previous_sibling)
print('通过 .next_siblings 和 .previous_siblings 属性可以对当前节点的兄弟节点迭代输出')
soup = BeautifulSoup(html_doc)
for sibling in soup.a.next_siblings:
print(repr(sibling))
输出结果:
#4.回退与前进
HTML解析器把这段字符串转换成一连串的事件: “打开<html>标签”,”打开一个<head>标签”,”打开一个<title>标签”,”添加一段字符串”,”关闭<title>标签”,”打开<p>标签”,等等.Beautiful Soup提供了重现解析器初始化过程的方法.
通过 .next_elements 和 .previous_elements 的迭代器就可以向前或向后访问文档的解析内容,就好像文档正在被解析一样:
soup = BeautifulSoup(html_doc)
for element in soup.a.next_elements:
print(repr(element))

搜索文档树
未完待续
python 3.x 爬虫基础---Requersts,BeautifulSoup4(bs4)的更多相关文章
- python 3.x 爬虫基础---正则表达式
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 python 3.x 爬虫基础---Requer ...
- python 3.x 爬虫基础---常用第三方库(requests,BeautifulSoup4,selenium,lxml )
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 python 3.x 爬虫基础---常用第三方库 ...
- python 3.x 爬虫基础---Urllib详解
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 前言 爬虫也了解了一段时间了希望在半个月的时间内 ...
- python爬虫基础_requests和bs4
这些都是笔记,还缺少详细整理,后续会更新. 下面这种方式,属于入门阶段,手动成分比较多. 首先安装必要组件: pip3 install requests pip3 install beautifuls ...
- python 3.x 爬虫基础---http headers详解
前言 上一篇文章 python 爬虫入门案例----爬取某站上海租房图片 中有对headers的讲解,可能是对爬虫了解的不够深刻,所以老觉得这是一项特别简单的技术,也可能是简单所以网上对爬虫系统的文档 ...
- 【Python学习】爬虫报错处理bs4.FeatureNotFound
[BUG回顾] 在学习Python爬虫时,运Pycharm中的文件出现了这样的报错: bs4.FeatureNotFound: Couldn’t find a tree builder with th ...
- Python BeautifulSoup4 爬虫基础、多线程学习
针对 崔庆才老师 的 https://ssr1.scrape.center 的爬虫基础练习.Threading多线程库.Time库.json库.BeautifulSoup4 爬虫库.py基本语法
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
- python从爬虫基础到爬取网络小说实例
一.爬虫基础 1.1 requests类 1.1.1 request的7个方法 requests.request() 实例化一个对象,拥有以下方法 requests.get(url, *args) r ...
随机推荐
- ES6——Symbol数据类型
什么是 Symbol ? Symbol 表示独一无二的值,他是js中的 第七种数据类型. 基本的数据类型:null, undefined number boolean string symbol 引用 ...
- sqlserver排名函数
在做开发的时候,排名函数是sqlserver经常用到的函数,在分页的时候需要用,分组的时候也要用,主要排名函数有row-number,rank(),dense-rank(),NTILE()接下来详细说 ...
- poj 2981 Strange Way to Express Integers (中国剩余定理不互质)
http://poj.org/problem?id=2891 Strange Way to Express Integers Time Limit: 1000MS Memory Limit: 13 ...
- Neutron FWaaS 原理
理解概念 Firewall as a Service(FWaaS)是 Neutron 的一个高级服务.用户可以用它来创建和管理防火墙,在 subnet 的边界上对 layer 3 和 layer 4 ...
- 【Oracle 12c】CUUG OCP认证071考试原题解析(29)
29.choose the best answer Evaluate the following query: SQL> SELECT promo_name || q'{'s start dat ...
- 【OCP|052】OCP最新题库解析系列-2
2.Which two are true about Optimizer Statistics? ❑ A) They do not persist across Instance restarts. ...
- 音频audio,加层父级
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Python str转化成数字
原地址 http://www.cnblogs.com/wuxiangli/p/6046800.html int(x [,base ]) 将x转换为一个整数 long(x [ ...
- [javascript]——将变量转化为字符串
这是一个非常常用,但是我自己却经常忘记的一个方法: var item = 'textssdf'; console.log("'"+item+"'") > ...
- K:java中的安全模型(沙箱机制)
本博文整合自:Java安全--理解Java沙箱.Java 安全模型介绍.Java的沙箱机制原理入门 相关介绍: 我们都知道,程序员编写一个Java程序,默认的情况下可以访问该机器的任意资源,比如读取 ...