【转】二叉树、B树、B-树、B+树、B*树
二叉树
1.所有非叶子结点至多拥有两个儿子(Left和Right);
2.所有结点存储一个关键字;
3.非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
如:

二叉树的搜索,从根结点开始,如果查询的关键字与结点的关键字相等,那么就命中;
否则,如果查询关键字比结点关键字小,就进入左儿子;如果比结点关键字大,就进入
右儿子;如果左儿子或右儿子的指针为空,则报告找不到相应的关键字;
如果二叉树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么二叉树
的搜索性能逼近二分查找;但它比连续内存空间的二分查找的优点是,改变二叉树结构
(插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销;
如:

但二叉树在经过多次插入与删除后,有可能导致不同的结构:

右边也是一个二叉树,但它的搜索性能已经是线性的了;同样的关键字集合有可能导致不同的
树结构索引;所以,使用二叉树还要考虑尽可能让二叉树保持左图的结构,和避免右图的结构,也就
是所谓的“平衡”问题;
实际使用的二叉树都是在原二叉树的基础上加上平衡算法,即“平衡二叉树”;如何保持二叉树
结点分布均匀的平衡算法是平衡二叉树的关键;平衡算法是一种在二叉树中插入和删除结点的
策略;
B树
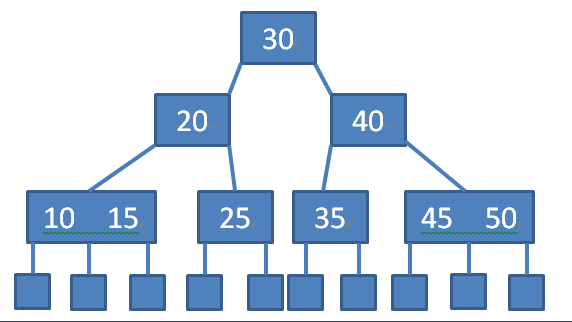
B-树
是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的
子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;
如:(M=3)

B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果
命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为
空,或已经是叶子结点;
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少
利用率,其最底搜索性能为:

其中,M为设定的非叶子结点最多子树个数,N为关键字总数;
所以B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题;
由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占
M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并;
B+树
B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树
(B-树是开区间);
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
如:(M=3)

B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在
非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好
是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储
(关键字)数据的数据层;
4.更适合文件索引系统;
B*树
是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针;

B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3
(代替B+树的1/2);
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据
复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父
结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分
数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字
(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之
间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
小结
二叉树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于
走右结点;
B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键
字范围的子结点;
所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点
中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率
从1/2提高到2/3;
【转自】http://blog.csdn.net/nashouat/article/details/8494946
【转】二叉树、B树、B-树、B+树、B*树的更多相关文章
- 排序二叉树、平衡二叉树、红黑树、B+树
一.排序二叉树(Binary Sort Tree,BST树) 二叉排序树,又叫二叉搜索树.有序二叉树(ordered binary tree)或排序二叉树(sorted binary tree). 1 ...
- 二叉树、平衡二叉树、红黑树、B树、B+树与B*树
转: 二叉树.平衡二叉树.红黑树.B树.B+树与B*树 一.二叉树 1️⃣二叉查找树的特点就是左子树的节点值比父亲节点小,而右子树的节点值比父亲节点大,如图: 基于二叉查找树的这种特点,在查找某个节点 ...
- Java实现二叉搜索树的添加,前序、后序、中序及层序遍历,求树的节点数,求树的最大值、最小值,查找等操作
什么也不说了,直接上代码. 首先是节点类,大家都懂得 /** * 二叉树的节点类 * * @author HeYufan * * @param <T> */ class Node<T ...
- B树、B+树、红黑树、AVL树
定义及概念 B树 二叉树的深度较大,在查找时会造成I/O读写频繁,查询效率低下,所以引入了多叉树的结构,也就是B树.阶为M的B树具有以下性质: 1.根节点在不为叶子节点的情况下儿子数为 2 ~ M2. ...
- AVL树、红黑树以及B树介绍
简介 首先,说一下在数据结构中为什么要引入树这种结构,在我们上篇文章中介绍的数组与链表中,可以发现,数组适合查询这种静态操作(O(1)),不合适删除与插入这种动态操作(O(n)),而链表则是适合删除与 ...
- 从二叉搜索树到AVL树再到红黑树 B树
这几种树都属于数据结构中较为复杂的,在平时面试中,经常会问理解用法,但一般不会问具体的实现,所以今天来梳理一下这几种树之间的区别与联系,感谢知乎用户@Cailiang,这篇文章参考了他的专栏. 二叉查 ...
- 二叉查找树、平衡二叉树(AVLTree)、平衡多路查找树(B-Tree),B+树
B+树索引是B+树在数据库中的一种实现,是最常见也是数据库中使用最为频繁的一种索引. B+树中的B代表平衡(balance),而不是二叉(binary),因为B+树是从最早的平衡二叉树演化而来的. 在 ...
- 各种查找算法的选用分析(顺序查找、二分查找、二叉平衡树、B树、红黑树、B+树)
目录 顺序查找 二分查找 二叉平衡树 B树 红黑树 B+树 参考文档 顺序查找 给你一组数,最自然的效率最低的查找算法是顺序查找--从头到尾挨个挨个遍历查找,它的时间复杂度为O(n). 二分查找 而另 ...
- Bw树:新硬件平台的B树(内存数据库中的b树索引)
Bw树:新硬件平台的B树 Bw树:新硬件平台的B树 1. 概述 1.1 原子记录存储(Atomic Record Stores) 1.2 新的环境 1.3 实现 2 Bwtree的体系结构 2.1 现 ...
- 【BZOJ】1146: [CTSC2008]网络管理Network(树链剖分+线段树套平衡树+二分 / dfs序+树状数组+主席树)
http://www.lydsy.com/JudgeOnline/problem.php?id=1146 第一种做法(时间太感人): 第二种做法(rank5,好开心) ================ ...
随机推荐
- C/C++程序内存分类
程序中内存分类主要有下面几种: (1)栈存储区:主要存储局部变量.函数參数.函数返回值等. 栈内存由编译器在须要时自己主动分配,使用完后自己主动释放. (2)堆存储区:由new.malloc申请到的空 ...
- 对UserDict的研究
# -*- coding: utf-8 -*- #python 27 #xiaodeng #对UserDict的研究 class UserDict(): def __init__(self, dict ...
- laravel5.4中{{$name}} 和 {{!! $name !!}} 的区别:后者原生输出。前者转义
- PHP中的密码加密的解决方案
层出不穷的类似事件对用户会造成巨大的影响,因为人们往往习惯在不同网站使用相同的密码,一家“暴库”,全部遭殃 一般的解决方案 1.将明文密码做单向hash $password = md5($_POST[ ...
- JavaScript-jQuery报TypeError $(...) is null错误(jQuery失效)解决办法
出现这种错误一般都是jQuery的$方法被覆盖, 解决办法: 1.把$改为jQuery使用 jQuery.noConflict();//将变量$的控制权让渡给给其他插件或库 jQuery(functi ...
- you need to know those webs !
J2me开发网 http://www.j2medev.com/bbs/index.asp J2me社区 http://www.j2meforums.com/forum/ csdn http://www ...
- Python 多进程教程
Python2.6版本中新添了multiprocessing模块.它最初由Jesse Noller和Richard Oudkerk定义在PEP 371中.就像你能通过threading模块衍生线程一样 ...
- python中如何对list之间求交集,并集和差集
最近遇到一个从list a里面去除list b的元素的问题,由于a很大,b也不小.所以遇到点困难,现在mark一下. 先说最简单的方法: a = [1, 2, 3, 4, 5, 6, 7, 8, 9, ...
- checkbox选择框如果被选中value值就可以传过去,没有被选中value就不能穿过去(调试了近一天,坑爹的说)
因为要适合各种分辨率,所以将原来的单选按钮radio换成单个的checkbox
- iOS - BSDSocket 的使用
1.BSDSocket 一套 unix 系统下的 socket API(纯 C). iOS 系统基于 unix,所以支持底层的 BSD Socket,在 Xcode 中可以直接使用. 2.基本使用 2 ...