The P4 Language Specification v1.0.2 Introduction部分
Introduction
P4 is a declarative language for expressing how packets are processed by the pipeline of a network forwarding element such as a switch, NIC, router or network function appliance.
It is based upon an abstract forwarding model consisting of a parser and a set of match+action table resources, divided between ingress and egress. The parser identifies the headers present in each incoming packet. Each match+action table performs a lookup on a subset of header fields and applies the actions corresponding to the first match within each table.
关键词:declarative language 声明型语言, pipeline of network forwarding element 流水线转发元, lookup 查表, corresponding 符合。
The parser identifies the headers present in each incoming packet.Parser辨别及确认每一个进来的数据报的首部。
P4 itself is protocol independent but allows for the expression of forwarding plane protocols. A P4 program specifies the following for each forwarding element.
- Header definitions: the format (the set of fields and their sizes) of each header within a packet.
- Parse graph: the permitted header sequences within packets.在包中被允许的首部序列称作Parse表。
- Table definitions: the type of lookup to perform, the input fields to use, the actions that may be applied, and the dimensions(重要性) of
each table.
- Action definitions: compound(调和) actions composed(组成) from a set of primitive(原始的) actions.大意是,复合的动作是由初始动作组合而成的。
- Pipeline layout and control flow: the layout(布局) of tables within the pipeline and the packet flow through the pipeline.
P4 addresses the configuration of a forwarding element.转发元的配置结构;Once configured, tables may be populated and packet processing takes place. **These post-configuration operations are referred to as "run time" in this document. **post-configuration操作 被称作“run time”;This does not preclude updating a forwarding element’s configuration while it is running. 不排除 在run的过程中更新转发元的配置。
1.1 The P4 Abstract Model
The following diagram(图) shows a high level representation of the P4 abstract model. The P4 machine operates with only a few simple rules.
接下来的图很好说明了P4抽象模型。
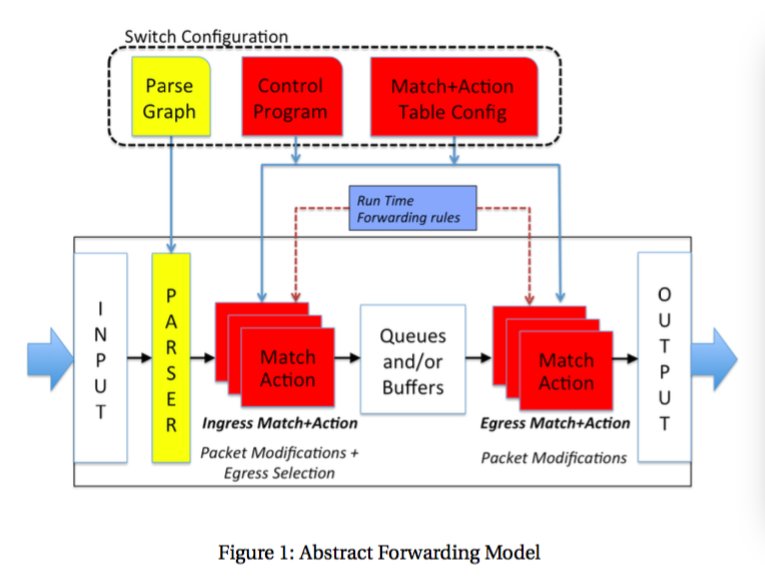
(1)For each packet, the parser produces a Parsed Representation on which match+action tables operate.
解析器针对每个包,都生成一个对应的 匹配+动作 操作 的表示/描述(Parsed Representation)。
(2)The match+action tables in the Ingress Pipeline generate an Egress Specification which determines the set of ports (and number of packet instances for each port) to which the packet will be sent.
在Ingress过程中的MA表,形成一种“Egress Specification”,Egress描述,该描述说明了 包将会发往的端口号的集合,还有每一个端口上包的数量。
(3)The Queuing Mechanism队列结构 processes(处理) this Egress Specification, generates the necessary instances of the packet and submits each to the Egress Pipeline. Egress queuing may buffer packets when there is over-subscription for an output port, although this is not mandated by P4.
中间的队列结构,处理Ingress过程中形成的Egress描述,形成十分必要的packet instances,并将其推送到Egress流水线。在输出端口过载的情况下,Egress队列起到一个缓冲器的作用,但它并没有被P4授权。
(4)A packet instance’s physical destination is determined before entering the Egress Pipeline. Once it is in the Egress Pipeline, this destination is assumed not to change (though the packet may be dropped or its headers further modified).
packet instances的物理目的地在进入Egress流水线之前就已经被决定了,一旦它进入了Egress流水线,认为packet instance的目的地不会被改变(虽然有可能被丢弃,首部有可能被更改)。
(5)After all processing by the Egress Pipeline is complete, the packet instance’s header is formed from the Parsed Representation (as modified by match+action processing) and the resulting packet is transmitted.
在 Egress 过程结束之后,根据Parser生成的 Parsed Representation(在Ingress和Egress过程中被操作)给 packet instances 加上首部,出包 packet-out。
P4专注于以下几个方面:parser的描述,match+action的表,在流水线上的流控制程序。程序员们通过编写P4程序定义底层交换机的配置,就像图一干的那样。
Target:能跑P4程序的机器,叫做target。注:我们从Github上下载下来的P4factory,是软件形式的machine。
虽然机器可能可以直接跑P4程序,但是一般来说还是需要对P4程序进行编译,然后变成对于机器来说比较合适的配置。
In the current version, P4 does not expose.比如,Queuing Mechanism 队列结构的功能,以及Egress Specification的语义(semantics),并没有指明。
总结:
我所理解的抽象模型大概过程是这样的:
(1)packet in
->
(2)Parser(解析过程:由P4程序中的Parse Graph定义的header格式 + 描述用于在真实的packet中匹配出header 的 Parser状态函数)
->
(3)解析结束,生成Parsed Representations + Data
->
(4)Ingress(对Parsed Representations进行操作 和 生成 Egress Specification)
->
(5)Queuing Mechanism(<1>根据 Egress Specification 选择Egress流水线的端口;<2>根据Data生成 packet instances;<3>判断端口是否过载,决定是否需要进入缓冲器)
->
(6)Egress(对Parsed Presentation进行操作)
->
(7)根据 <1>packet instances 和 <2>经过Ingress和Egress过程中的一系列操作的 Parsed Presentation 组合成包
->
(8)Output:packet out。
除了以上的过程之外,P4还支持recirculation和cloning of packets。
1.2 The mTag Example
最原始的P4论文包括一个叫做mTag的实例,我们自始至终使用这个例子来说明一些最为基础的P4语言特征,在P4的web网站上,有完整的来源和一些样品run-time API。
在原文描述中,介绍了P4在这个案例中最大的优点,P4提供了一种对网络架构影响最小的解决问题的方案。
论文原文节选:
Consider an example L2 network deployment with top-of-rack (ToR) switches at the edge connected by a two-tier core. We will assume the number of end-hosts is growing and the core L2 tables are overflowing. . . . P4 lets us express a custom solution with minimal changes to the network architec- ture. . . . The routes through the core are encoded by a 32-bit tag composed of four single-byte fields. The 32-bit tag can carry a "source route".... Each core switch need only examine one byte of the tag and switch on that infor- mation. [1]
在这个样例中,定义了两个P4程序:一个是为了 edge switches(在上文中叫做 ToR);另外一个是为了aggregation switches(在上文中叫做 core switches)。
这两个程序,提供了对headers,parser,actions的定义。
1.3 P4 Abstractions
P4提供了以下的几个抽象概念,一个P4的程序包括它们的实例。
(1)Header Type:对header中fields的描述。A specification of fields within a header.
(2)Header instance:一个具体的(specific)packet header实例 或者metadata实例。
(3)Parser State Function:定义了在解析的过程中如何在packet内确认headers。Defines how headers are identified within a packet.
(4)Action Function:一个由基础(primative)动作相互协调应用(be applied together)所组成的结构(composition)。
(5)Table instance:指定(specified)了如何使用fields进行匹配,还有允许使用的动作。
(6)Control flow function:是 table application order 表的匹配顺序 的必要(imperative)描述。
(7)Stateful memories:计数器,计量器,寄存器,它们的数据能够长期存在。
此外,还有一些与其中的几个抽象概念相关的内容:
对于Header Instance而言:
相关内容包括(1)Metadata (2)Header Stack (3)Dependent fields
- Metadata:是每一个数据报的状态数据(per-packet state),除非把Metadata和packet header一样看待,否则不一定会从包数据中导出(derived)。
- Header Stack:header instances的连续数组(a contiguous array),或者说,栈。
- Dependent fields:field的值,取决于 某种应用于 其它field或者常量(constants) 的计算结果(calculation)。
对于parser而言:
相关内容包括(1)Value Set (2)Checksum calculations
- Value Set:随着run time更新的值,决定了解析过程中状态的转移。
- Checksum calculations:对数据报中bytes集合的函数应用能力(The ability to apply a function to a set of bytes from the packet),以及用于测试field是否和计算结果匹配(test that a field matches the calculation)。
2016/10/2
The P4 Language Specification v1.0.2 Introduction部分的更多相关文章
- The P4 Language Specification v1.0.2 Header and Fields
前言 本文参考P4.org网站给出的<The P4 Language Specification v1.0.2>的第二部分首部及字段,仅供学习:). 欢迎交流! Header and Fi ...
- The P4 Language Specification v1.0.2 Parser
<p4规范>解析器部分详解 p4解析器是根据有限状态机的思想来设计的. 解析器中解析的过程可以被一个解析图(parser graph)所表示,解析图中所表示的某一个状态(或者说,在P4语言 ...
- C# Language Specification 5.0 (翻译)第一章 引言
C#(念作 See Sharp)是一种简单.现代.面向对象并且类型安全的编程语言.C# 源于 C 语言家族,因此 C.C++ 和 Java 工程师们能迅速上手.ECMA 国际[1](ECMA Inte ...
- C# Language Specification 5.0 (翻译)第二章 词法结构
程序 C# 程序(program)由至少一个源文件(source files)组成,其正式称谓为编译单元(compilation units)[1].每个源文件都是有序的 Unicode 字符序列.源 ...
- C# Language Specification 5.0 (翻译)第三章 基本概念
应用程序启动 拥有进入点(entry point)的程序集称应用程序(application).当运行一应用程序时,将创建一新应用程序域(application domain).同一个应用程序可在同一 ...
- C# Language Specification 5.0 (翻译)第四章 类型
C# 语言的类型分为两大类:值类型(value type)和引用类型(reference type),而它们又都同时具有至少一个类型形参的泛型类型(generic type).类型形参(type pa ...
- C# Language Specification 5.0 (翻译)第五章 变量
变量(variable)表示存储的位置.每个变量都有类型,类型决定变量保存的值的类型.C# 是一门类型安全的语言,C# 编译器会确保变量中保存一个适合类型的值.变量的值可通过赋值或通过使用 ++ 与 ...
- Bittorrent Protocol Specification v1.0 中文
翻译:小马哥 日期:2004-5-22 BitTorrent 是一种分发文件的协议.它通过URL来识别内容,并且可以无缝的和web进行交互.它基于HTTP协议,它的优势是:如果有多个下载者并发的下载同 ...
- C# Language Specification 5.0 (翻译)第六章 转换
转换使表达式可以当做一个明确的类型来加以处理.转换使得所给定类型的表达式以不同类型来处理,或使得没有某个类型的表达式获得该类型.转换可以是显式或隐式的,而这决定了是否需要显式地强制转换.比方说,从类型 ...
随机推荐
- navicat 激活流程
Navicat Premium 12激活 我自己测试了一下可以激活,很好用 原作链接:https://blog.csdn.net/loveer0/article/details/82016644 Na ...
- centos7上安装iptables
centos7上安装iptables的步骤 注意:CentOS7默认的防火墙不是iptables,而是firewalle. 安装iptable iptable-service #安装iptables ...
- SMGP3.0协议的概念知识
该项目主页在https://code.google.com/archive/p/smgp/,可以使用VPN进去看看,该项目是开源的,根据SMGP3.0协议写的API,我们要用的话直接调用就好了,这里主 ...
- SQL SERVER大话存储结构(5)_SQL SERVER 事务日志解析
本系列上一篇博文链接:SQL SERVER大话存储结构(4)_复合索引与包含索引 1 基本介绍 每个数据库都具有事务日志,用于记录所有事物以及每个事物对数据库所作的操作. 日志的记录 ...
- Java开发环境的搭建(jdk,eclipse)
一.java 开发环境的搭建 这里主要说的是在windows 环境下怎么配置环境. 1.首先安装JDK java的sdk简称JDK ,去其官方网站下载最近的JDK即可. http://www.orac ...
- 170526、spring 执行定时任务
Spring 定时任务之 @Scheduled cron表达式 一.使用 Spring配置文件xmlns加入 xmlns:task="http://www.springframework.o ...
- Oracle HA 之 oracle 11.2 rac库配置active dataguard
目录 configing active dataguard for 11.2 rac. 1 一.建组.建用户.配置环境变量.内核参数等... 1 二.配置共享磁盘... 3 1)创建4块共享磁盘并fd ...
- Linux学习-->如何通过Shell脚本实现发送邮件通知功能?
1.安装和配置sendmail 不需要注册公网域名和MX记录(不需要架设公网邮件服务器),通过Linux系统自带的mail命令即可对公网邮箱发送邮件.不过mail命令是依赖sendmail的,所以我们 ...
- Mirror--日志流压缩
在SQL SERVER 2008之后,主库和镜像库之间的日志流传送会默认使用压缩,压缩一方面降低了网络压力,另一方面增大了镜像两端的CPU压力. 可以打开 TF 1462 来关闭日志流压缩 SQL S ...
- onvif协议client与server对接
happytimesoft有完整的c语言开发的onvif client和server,一共1000$,真便宜,haha. http://www.happytimesoft.com/products/m ...