Intellij IDEA 2017 通过scala工程运行wordcount
首先是安装scala插件,可以通过idea内置的自动安装方式进行,也可以手动下载可用的插件包之后再通过idea导入。
scala插件安装完成之后,新建scala项目,右侧使用默认的sbt
点击Next,到这一步就开始踩坑了,scala的可选版本比较多,从2.12到2.10都有,我的环境下用wordcount的例子尝试了几种情况:
先贴上测试代码,以下的测试全都是基于这段代码进行的。
package com.hq import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object WordCount {
def main(args: Array[String]) {
if (args.length < 1) {
System.err.println("Usage: <file>")
System.exit(1)
} val conf = new SparkConf()
val sc = new SparkContext("local","wordcount",conf)
val line = sc.textFile(args(0)) line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect().foreach(println) sc.stop()
}
}
1. scala如果用2.12.4的版本,运行时就会报错。可能跟我写的代码有关,scala 2.12.x使用spark的方式可能不一样,后面再看。不过官网上有说spark-2.2.1只能与scala-2.11.x兼容,所以这个就没有再试了

2. scala如果使用2.11.x的版本,我这边最初按照网上的各种教程,一直在尝试使用spark-assembly-1.6.3-hadoop2.6.0.jar,结果也是报错。

然后想着试一下最新的spark-2.2.1-bin-hadoop2.7,但是里面没有spark-assembly-1.6.3-hadoop2.6.0.jar,就索性把jars目录整个加到工程中,运行也是出错,但明显是能运行了。
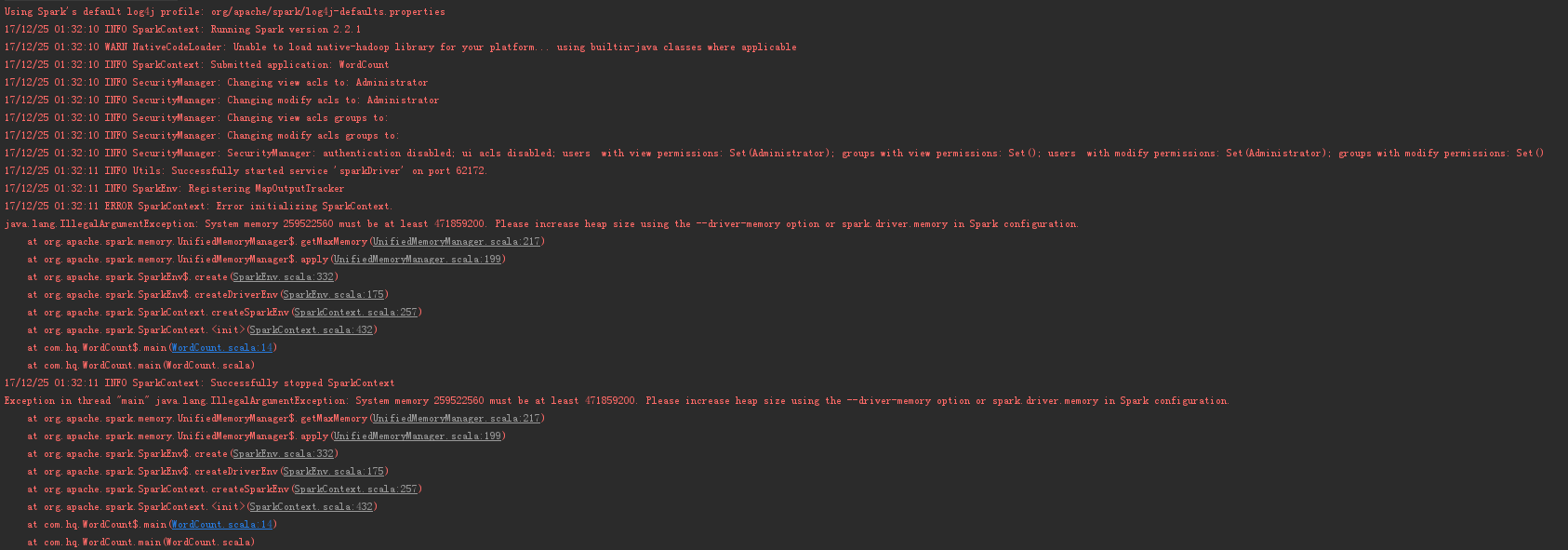
百度之,加上一句设置就可以了
conf.set("spark.testing.memory", "2147480000")
3. scala如果使用2.10.x,根据网上的各种教程,我使用的是2.10.6,只需要在工程中加入spark-assembly-1.6.3-hadoop2.6.0.jar这个包即可,当然,还有内存大小的配置。
另外,在使用2.10.6的时候,idea在下载scala-library, scala-compiler, scala-reflect各种包时都出错,只能手动下载,再放到缓存目录下: "C:\Users\Administrator\.ivy2\cache\org.scala-lang"。
顺便收藏一个网址,也许以后还要用: http://mvnrepository.com/artifact/org.scala-lang/scala-library
待处理的问题:
1. 运行时内存大小的设置,应该可以通过修改idea的配置项来做到,就不用在代码里面加这个
2. idea的缓存目录还需要修改,不然用的时间长了,C盘要崩...
3. 虽然wordcount运行成功了,但是会有warning...
Intellij IDEA 2017 通过scala工程运行wordcount的更多相关文章
- IntelliJ IDEA 2017.3 配置Tomcat运行web项目教程(多图)
小白一枚,借鉴了好多人的博客,然后自己总结了一些图,尽量的详细.在配置的过程中,有许多疑问.如果读者看到后能给我解答的,请留言.Idea请各位自己安装好,还需要安装Maven和Tomcat,各自配置好 ...
- Spark编程环境搭建(基于Intellij IDEA的Ultimate版本)(包含Java和Scala版的WordCount)(博主强烈推荐)
福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
- Intellij IDEA下导出Java工程的可运行JAR包
Intellij IDEA下导出Java工程的可运行JAR包 昨天一直向导出一个Java工程的可运行JAR包,然后查阅网上的资料以及自己一遍一遍的尝试,均以失败告终.可以导出JAR包,但是导出的JAR ...
- 使用IntelliJ IDEA创建Maven聚合工程、创建resources文件夹、ssm框架整合、项目运行一体化
一.创建一个空的项目作为存放整个项目的路径 1.选择 File——>new——>Project ——>Empty Project 2.WorkspaceforTest为项目存放文件夹 ...
- 【转载】使用IntelliJ IDEA创建Maven聚合工程、创建resources文件夹、ssm框架整合、项目运行一体化
一.创建一个空的项目作为存放整个项目的路径 1.选择 File——>new——>Project ——>Empty Project 2.WorkspaceforTest为项目存放文件夹 ...
- 下载安装tomcat和jdk,配置运行环境,与Intellij idea 2017关联
第一篇博客,最近公司要用java和jsp开发新的项目,第一次使用Intellij idea 2017,有很多地方需要一步步配置,有些按照网上的教程很快就配置好了,有的还是琢磨了一会儿,在这里做一个记录 ...
- IntelliJ IDEA的下载、安装和WordCount的初步使用(本地模式和集群模式)
包括: IntelliJ IDEA的下载 IntelliJ IDEA的安装 IntelliJ IDEA中的scala插件安装 用SBT方式来创建工程 或 选择Scala方式来创建工程 本地模式或集群 ...
- Spark学习笔记-如何运行wordcount(使用jar包)
IDE:eclipse Spark:spark-1.1.0-bin-hadoop2.4 scala:2.10.4 创建scala工程,编写wordcount程序如下 package com.luoga ...
- Intellij IDEA 2017 详细图文教程之概述
天天编码 , 版权所有丨本文标题:Intellij IDEA 2017 详细图文教程之概述 转载请保留页面地址:http://www.tiantianbianma.com/intellij-idea- ...
随机推荐
- 【[APIO2007]动物园】
我好\(sb\)啊,把\(>>\)打成\(<<\)结果就写了两节课 那个一个人只能看到五个动物显然很鬼畜 那我们就可以压这一维了 \(dp[i][s]\)表示从第\(i\)个位 ...
- CORS support for ASP.NET Web API (转载)
CORS support for ASP.NET Web API Overview Cross-origin resource sharing (CORS) is a standard that al ...
- cocos2dx lua 一键资源管理PowerShell脚本实现
特别说明 此管理脚本不包含图片资源加密,热更新资源文件列表是md5 和 文件路径构成的txt,如下 脚本文件是放在和res src 同级的文件夹里面 脚本内容如下 clear $PSDefaultPa ...
- 一次“Error Domain=AVFoundationErrorDomain Code=-11841”的调试
一次"Error Domain=AVFoundationErrorDomain Code=-11841"的调试 起因 最近在重构视频输出模块的时候,调试碰到AVAssetReade ...
- MySQL案例03:(MyCAT报错) [ERROR][$_NIOREACTOR-3-RW] caught err: java.lang.OutOfM emoryError: Unable to acquire 131072 bytes of memory, got 0
上班坐下来没多久,接同事电话说有两台mysql服务器无法访问,其中这两台服务器是mycat服务器+MySQL服务器,具体处理过程如下: 一.错误信息 错误信息01: :: ::, [INFO ][$_ ...
- Redis报(error) NOAUTH Authentication required.问题解决
启动后 输入auth+空格+密码 ok
- Spring retry实践
在开发中,重试是一个经常使用的手段.比如MQ发送消息失败,会采取重试手段,比如工程中使用RPC请求外部服务,可能因为网络波动出现超时而采取重试手段......可以看见重试操作是非常常见的一种处理问题, ...
- laravel Eloquent ORM联合查询出现Class not found,就算在Moel中存在这个类
今天发现一个坑,在处理Eloquent ORM的联合查询时,一直报错Class 'AdminGroup' not found ,可是我的项目中明明存在这个类,如下 这是我的模型类: 它们的控制器方法: ...
- C语言/C++编程学习:栈的代码实现之数组方案
C语言是面向过程的,而C++是面向对象的 C和C++的区别: C是一个结构化语言,它的重点在于算法和数据结构.C程序的设计首要考虑的是如何通过一个过程,对输入(或环境条件)进行运算处理得到输出(或实现 ...
- Go语言中结构体的使用-第2部分OOP
1 概述 结构体的基本语法请参见:Go语言中结构体的使用-第1部分结构体.结构体除了是一个复合数据之外,还用来做面向对象编程.Go 语言使用结构体和结构体成员来描述真实世界的实体和实体对应的各种属性. ...