Re-Order Buffer
Re-order Buffer(ROB)是处理器中非常重要的一个模块,它位于renamer与scheduler(RS)之间,并且也是execution unit(EU)的出口。ROB作为指令处理的后端,其主要任务是存储指令经由EU处理后得到的结果,并把该结果按照in-order顺序写回到寄存器文件。
Intel没有给出详细的ROB pipeline,下面的pipeline的描述以及分析主要基于参考资料以及本人的一些推断,不一定准确,仅供参考。
Early ROB
ROB的目的为存储out-of-order的处理结果,并以in-order写回寄存器。不过早期的ROB与现在的ROB相比,虽然目的相同,但是实现却存在较大的区别,并且这部分的区别不仅仅在于ROB本身,还牵扯到out-of-order engine的其它部分。
早期的ROB的实现方式一直延续到Nehalem微处理器,从Sandy Bridge微处理器开始采用新的ROB实现方式。
早期ROB的相关部分的pipeline:
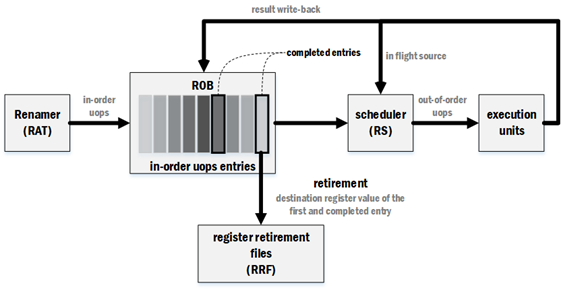
μops流经上述pipeline的过程分为以下几个步骤:
- μops以in-order顺序从renamer传输到RS,途中会经过ROB。
- 每个经过ROB的μop都会占用ROB中的一个项,主要都用于存储μop处理完成时得到的result,并且这些项会以μops经过的先后顺序(in-order)进行排列。
- 经过ROB后,μops会在RS内等待source operand就绪,一旦某μop所有的source都已就绪并且相应的EU可用的时,往EU发送μop。
- EU在处理完成μop后,会把处理的结果写回ROB中相应的那项。
- 同时,如果RS中有其他的μop需要该处理结果作为source,该结果可以直接从EU传输到RS。由于这种数据转移方式不经过front end以及back end(ROB),因此被称为in flight。
- 在ROB中,处理完成的μop需要按照in-order的顺序把执行结果写回寄存器文件,因此会把第一项(最早进入项)按照先后顺序把执行结果写入寄存器文件,这个过程叫做retirement。
另外,有些μops是不需要经过EU的处理的,这些μops可以直接在ROB内等待retirement。
ROB Read Port Stalls
如上面的描述,μop在source就绪前会在RS内等待,在此期间,就绪的source会被传送到RS,一旦所有的source都就绪,并且相应的EU可用时,μop就会被调度过去执行。
source分为memory operand、register operand、immediate operand,其中需要等待的只有memory以及register相关的source,我们这里讨论的是register operand。
RS的source入口有三个:
- in flight。μop从EU处理完成后,执行结果会被写回ROB,如果此时RS也有μop需要该结果,则该执行结果作为source进入RS。一般来说,大部分指令的source都是in flight的,并且intel微处理器也基于这种情况对in flight的source传输进行了优化。
- ROB read。如果在执行结果被写回ROB时,RS中并没有需要该结果的μop,则该执行结果不会进入RS,如果后来有新的μop需要以该执行结果作为source,只能从ROB中获取。不过这种获取source的方式可能会带来一些性能上的下降,我们会在下面进行分析。
- register read。如果在执行结果被写回ROB时,RS中并没有需要该结果的μop,则该执行结果不会进入RS,如果后来有新的μop需要以该执行结果作为source,但是此时执行结果已被写回RRF,则直接从RRF中获取。这种情况的出现的机率较小,以Core微处理器为例,Core微处理器上的ROB有96项,RS有32项,也就是说只有当某个μop所需的source来自位于其之前超过128的μop才会出现这种情况。
in flight与register read在传输数据时都很块,问题在于ROB read。ROB向RS传输source的通道被称为ROB read port,每个read port在一个时钟周期内可以传输一个register operand,在P6上有两个read port,到了Core以及Nehalem时为3个。
以Core微处理器为例,现假设有两条如下的指令,并且edi、esi、esp、ebp都要从ROB获取:
mov [edi + esi], eax
mov [esp + ebp], ebx
它们分解成μops:
tmp1 ← edi + esi
mov [tmp1], eax
tmp2 ← esp + ebp
mov [tmp2], ebx
按由于两条指令之间没有依赖关系,所以如果EU可用的话,按理说第一、第三个μop可以同时被调度到不同的ALU(EU)执行。不过由于Core上只有3个read port,因此无法一次性读取四个source,那么就有一个μop需要延迟执行。
从程序上来说,出现这种情况的原因主要是频繁使用了Based Indexed Addressing以及对寄存器写入后间隔较长才去读取。因此避免出现ROB read port stalls的措施也比较简单:不要频繁使用Based Indexed Addressing以及对寄存器的写后读取读操作尽量别间隔太长。
Recent ROB
从Sandy Bridge微处理器开始,intel就采用了全新的ROB pipeline,其中ROB不再用于存储执行结果,而是只用于记录μops的状态,如下图所示

EU在处理完μop后直接写回物理寄存器(PRF)并改变ROB中μop的状态,然后RAT就可以根据ROB中的状态调整PRF映射,使得用户层看起来指令在以in-order的方式执行。这种ROB实现方式没有了ROB read port的限制,因此ROB read port stalls的现象不复存在。
Reference:
Intel® 64 and IA-32 Architectures Optimization Reference Manual
Agner Fog - The microarchitecture of Intel, AMD and VIA CPUs
David Kanter - Inside Nehalem: Intel’s Future Processor and System
David Kanter - Intel’s Sandy Bridge Microarchitecture
Re-Order Buffer的更多相关文章
- MySQL InnoDB存储引擎
200 ? "200px" : this.width)!important;} --> 介绍 本篇文章是对Innodb存储引擎的概念进行一个整体的概括,innodb存储引擎的 ...
- TextureView+SurfaceTexture+OpenGL ES来播放视频(三)
引自:http://www.jianshu.com/p/291ff6ddc164 做好的Demo截图 opengl-video 前言 讲了这么多,可能有人要问了,播放视频用个android封装的Vid ...
- Method and apparatus for speculative execution of uncontended lock instructions
A method and apparatus for executing lock instructions speculatively in an out-of-order processor ar ...
- PatentTips - Compare and exchange operation using sleep-wakeup mechanism
BACKGROUND Typically, a multithreaded processor or a multi-processor system is capable of processing ...
- Java 内存映射文件
import java.io.*; import java.nio.MappedByteBuffer; import java.nio.channels.FileChannel; import jav ...
- Intel Ivy Bridge Microarchitecture Events
This is a list of all Intel Ivy Bridge Microarchitecture performance counter event types. Please see ...
- Intel Sandy Bridge Microarchitecture Events
This is a list of all Intel Sandy Bridge Microarchitecture performance counter event types. Please s ...
- 【基础知识】Intel CPU体系结构|x86是什么意思
看了<计算机系统结构>.<深入理解计算机系统>.<大话处理器>等经典书籍,也在google上搜了一大堆资料,前前后后.断断续续的折腾了一个多月,终于想通了,现在把自 ...
- nodejs(三)Buffer module & Byte Order
一.目录 ➤ Understanding why you need buffers in Node ➤ Creating a buffer from a string ➤ Converting a b ...
- JAVA NIO Buffer
所谓的输入,输出,就是把数据移除或移入缓冲区. 硬件不能直接访问用户控件(JVM). 基于存储的硬件设备操控的是固定大小的数据块儿,用户请求的是任意大小的或非对齐的数据块儿. 虚拟内存:使用虚 ...
随机推荐
- 软件工程(GZSD2015)第二次作业进度
贵州师范大学软件工程第二次作业 徐 镇 王铭霞 张 英 涂江枫 张 燕 安 坤 周 娟 杨明颢 杨家堂 罗文豪 娄秀盛 周 娟 李盼 岳庆 张颖 李丽思 邓婷 唐洁 郑倩 尚清丽 陈小丽 毛茸 宋光能 ...
- 第二次项目冲刺(Beta阶段)5.24
1.提供当天站立式会议照片一张 会议内容: ①检查前一天的任务情况. ②制定新一轮的任务计划. 2.每个人的工作 (1)工作安排 队员 今日进展 明日安排 王婧 #63Web输出以文件名为标题 #63 ...
- 201521123060 《Java程序设计》第8周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结集合与泛型相关内容. 1.2 选做:收集你认为有用的代码片段 2. 书面作业 本次作业题集集合 List中指定元素的删除(题目4-1 ...
- 201521123111《Java程序设计》第5周学习总结
1. 本章学习总结 你对于本章知识的学习总结 1.1 尝试使用思维导图总结有关多态与接口的知识点. 1.2 可选:使用常规方法总结其他上课内容. 2. 书面作业 1.代码阅读:Child压缩包内源代码 ...
- 201521123026 《Java程序设计》第5周学习总结
1. 本章学习总结 尝试使用思维导图总结有关多态与接口的知识点 使用常规方法总结其他上课内容 1.接口的出现时为了实现多态,多态的实现不一定依赖于接口. 2.接口的常见成员有:全局常量和抽象方法. 3 ...
- 201521123078 《Java程序设计》第十三周学习总结
1. 本周学习总结 2. 书面作业 1. 网络基础 1.1 比较ping www.baidu.com与ping cec.jmu.edu.cn,分析返回结果有何不同?为什么会有这样的不同? 查询Ip地址 ...
- YYHS-Floor it
题目描述 输入 输出 样例输入 5 97 样例输出 11 提示 题解 先不管p,通过列举前面几项,不难发现当i为偶数时,a[i]=a[i-1]+a[i-2],当i为奇数时,a[i]=a[i ...
- Python学习笔记007_图形用户界面[EasyGui][Tkinter]
EasyGui官网:http://easygui.sourceforge.net/ EasyGui最新版:easygui-0.97.rar 小甲鱼根据官网文档翻译之后的中文文档地址: http://b ...
- HttpServletRequest获取URL、URI
从Request对象中可以获取各种路径信息,以下例子: 假设请求的页面是index.jsp,项目是WebDemo,则在index.jsp中获取有关request对象的各种路径信息如下 import j ...
- const在c和c++中的不同
最近开始由学习c转到c++:从面向过程到面向对象的转变中,总是以面向过程的思路思考,发现有很多的不同,今天就稍微发表一下我的见解,如果那里出错,希望大神可以帮忙指出来. 首先是const : 在C语法 ...