Hadoop集群环境搭建(一)
1集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起
HDFS集群:
负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
YARN集群:
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
本集群搭建案例,以3节点为例进行搭建,角色分配如下:
hdp-node- NameNode SecondaryNameNode ResourceManager
hdp-node- DataNode NodeManager
hdp-node- DataNode NodeManager
2服务器准备
本案例使用虚拟机服务器来搭建HADOOP集群,所用软件及版本:
▨ Vmware 12.0
▨ Centos 7.0 64bit
3网络环境准备
▨ 采用NAT方式联网
▨ 网关地址:192.168.33.1
▨ 3个服务器节点IP地址:192.168.33.101、192.168.33.102、192.168.33.103
▨ 子网掩码:255.255.255.0
4服务器系统设置
▨ 添加HADOOP用户
▨ 为HADOOP用户分配sudoer权限
▨ 同步时间
▨ 设置主机名
◈ hdp-node-01
◈ hdp-node-02
◈ hdp-node-03
▨ 配置内网域名映射:
◈ 192.168.33.101 hdp-node-01
◈ 192.168.33.102 hdp-node-02
◈ 192.168.33.103 hdp-node-03
▨ 配置ssh免密登陆
▨ 配置防火墙
5JDK环境安装
▨ 上传jdk安装包
▨ 规划安装目录 /home/hadoop/apps/jdk_1.7.65
▨ 解压安装包
▨ 配置环境变量 /etc/profile
6HADOOP安装部署
▨ 上传HADOOP安装包
▨ 规划安装目录 /home/hadoop/apps/hadoop-2.6.5
▨ 解压安装包 tar –zxvf hadoop-2.6.5 –C apps/
▨ 修改配置文件 $HADOOP_HOME/etc/hadoop/
最简化配置如下:
vi hadoop-env.sh
# The java implementation to use.
export JAVA_HOME=/home/hadoop/apps/jdk1..0_45
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdp-node-01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/HADOOP/apps/hadoop-2.6.5/tmp</value>
</property>
</configuration>
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hdp-node-01:50090</value>
</property>
</configuration>
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
vi salves
hdp-node-02
hdp-node-03
7启动集群
初始化HDFS
bin/hadoop namenode -format
启动HDFS
sbin/start-dfs.sh
启动YARN
sbin/start-yarn.sh
查看集群状态
jps
bin/hdfs dfsadmin -report
8测试——运行一个mapreduce程序
在HADOOP安装目录下,运行一个示例mr程序
cd $HADOOP_HOME/share/hadoop/mapreduce/
hadoop jar mapredcue-example-2.6.5.jar wordcount /wordcount/input /wordcount/output
9HDFS使用
1、查看集群状态
命令: hdfs dfsadmin –report
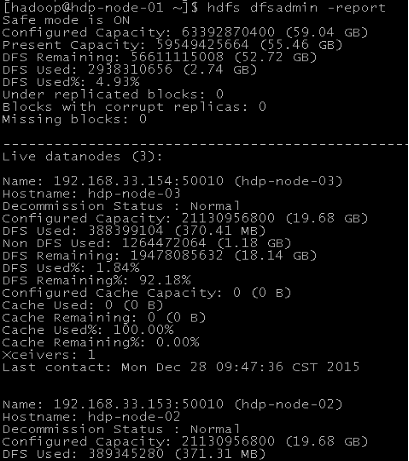
可以看出,集群共有3个datanode可用
也可打开web控制台查看HDFS集群信息,在浏览器打开http://hdp-node-01:50070/
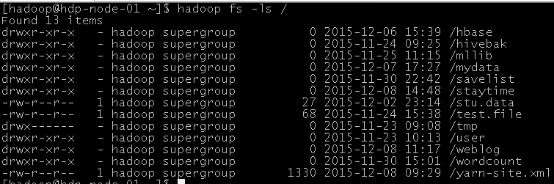
2、上传文件到HDFS
▣ 查看HDFS中的目录信息
命令: hadoop fs –ls /
▣ 上传文件
命令: hadoop fs -put ./ scala-2.10.6.tgz to /

出处:http://www.cnblogs.com/jerehedu/
版权声明:本文版权归烟台杰瑞教育科技有限公司和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
技术咨询:

Hadoop集群环境搭建(一)的更多相关文章
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
- 简单Hadoop集群环境搭建
最近大数据课程需要我们熟悉分布式环境,每组分配了四台服务器,正好熟悉一下hadoop相关的操作. 注:以下带有(master)字样为只需在master机器进行,(ALL)则表示需要在所有master和 ...
- Java+大数据开发——Hadoop集群环境搭建(一)
1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主要有 NameNode / DataN ...
- Hadoop(4)-Hadoop集群环境搭建
准备工作 开启全部三台虚拟机,确保hadoop100的机器已经配置完成 分发脚本 操作hadoop100 新建一个xsync的脚本文件,将下面的脚本复制进去 vim xsync #这个脚本使用的是rs ...
随机推荐
- Servlet Filter 中init和destroy问题
测试源码如下: package com.FilterTest.Filter; import java.io.IOException; import javax.servlet.Filter; impo ...
- 给xcode项目修改名字
在xcode项目开发中,经常会遇到需要修改项目名字的问题, 但是xcode本身修改项目名字比较麻烦,有时候修改的不完全,有时候修改了项目无法打开,无奈只能建一个新项目.这里提供一种修改xcode项目名 ...
- 学习JavaScript时的三部分
JavaScript = ECMAScript + DOM + BOM 其中ECMAScript表示的是基本语法,包括我们实现JS的基本语法,如变量的声明.基本的语句(if.for.switch等) ...
- POJ 3659 Cell Phone Network / HUST 1036 Cell Phone Network(最小支配集,树型动态规划,贪心)-动态规划做法
POJ 3659 Cell Phone Network / HUST 1036 Cell Phone Network(最小支配集,树型动态规划,贪心) Description Farmer John ...
- 深入理解javascript异步编程障眼法&&h5 web worker实现多线程
0.从一道题说起 var t = true; setTimeout(function(){ t = false; }, 1000); while(t){ } alert('end'); 1 2 3 4 ...
- 在Linux下安装Oracle12c
其实,对于oracle数据库和oracle实例的安装,借用图形化安装还是比较容易的,只是有个别地方需要特别注意外,其余的默认安装即可: 1.安装前的准备: 启动SSH工具: 先启动倒数第三个(想用图像 ...
- ueditor编辑器使用总结
ueditor使用小结 一.简介 ueditor是百度编辑器,官网地址:http://ueditor.baidu.com/website/ 完整的功能演示,可以参考:http://ueditor.ba ...
- Filter ,Interceptor,AOP
一.Filter: Filter也称之为过滤器,它是Servlet技术中比较激动人心的技术,WEB开发人员通过Filter技术,对web服务器管理的所有web资源:例如Jsp, Servlet, 静态 ...
- Mybatis Dynamic Query 框架整合
项目地址:https://github.com/wz2cool/mybatis-dynamic-query 文档地址:https://wz2cool.gitbooks.io/mybatis-dynam ...
- 【分享】01. Eclipse for PHP + phpStudy 搭建php开发环境
配置php编译器 配置phpStudy服务器项目发布目录 修改hosts文件127.0.0.1 www.350zx.cn 新建项目 启动的你的phpStudy