Oracle-1 - :超级适合初学者的入门级笔记,CRUD,事务,约束 ......
Oracle
更改时间:
- 2017-10-25 - 21:33:49
- 2017-10-26 - 11:43:19
- 2017-10-27 - 19:06:57
- 2017-10-28 - 15:21:47
- 2017-10-30 - 21:43:21
- 2017-11-01 - 20:51:07
今天开始接触oracle,2017-10-25 - 08:48:06,以下内容是记录自己的学习过程,也是oracle的自学笔记吧,感觉可以的给个赞哦,如果不对的地方请及时指出来 ,谢谢~~
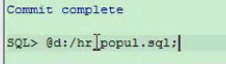
这是我自己创建的表
--------------------------------------------------------
-- 文件已创建 - 星期五-十月-27-2017
--------------------------------------------------------
--------------------------------------------------------
-- DDL for Table FRR
-------------------------------------------------------- CREATE TABLE "SYSTEM"."FRR"
( "ID" NUMBER(10,0),
"NAME" VARCHAR2(20 BYTE),
"MONEY" NUMBER(20,0),
"TIME" DATE
) PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255
NOCOMPRESS LOGGING
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1
BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ;
REM INSERTING into SYSTEM.FRR
SET DEFINE OFF;
Insert into SYSTEM.FRR (ID,NAME,MONEY,TIME) values (1,'纯菜鸟',100,to_date('25-10月-17','DD-MON-RR'));
Insert into SYSTEM.FRR (ID,NAME,MONEY,TIME) values (2,'懒蛋
',null,to_date('25-10月-17','DD-MON-RR'));
Insert into SYSTEM.FRR (ID,NAME,MONEY,TIME) values (3,'纯菜鸟',100,to_date('25-10月-17','DD-MON-RR'));
Insert into SYSTEM.FRR (ID,NAME,MONEY,TIME) values (6,null,null,null);
Insert into SYSTEM.FRR (ID,NAME,MONEY,TIME) values (5,'期_待',666,to_date('21-10月-14','DD-MON-RR'));
Insert into SYSTEM.FRR (ID,NAME,MONEY,TIME) values (555,'null',555,null);
- 使用的数据库是12c 版本的,
- select sysdate from dual; 查询现在的年份及时间
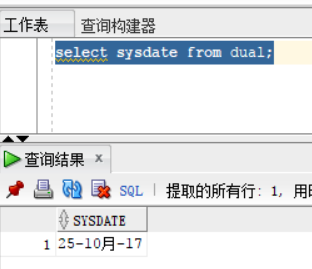
- select sysdate from dual; 查询现在的年份及时间
- 导入sql 文件, @d:/file.sql ; 就可以导入指定目录路径下的sql文件
- sql 语句分为
- DML:数据操纵语言:包括sql 的增删改查
- DDL:数据定义语言:用于定义数据库的结构,比如:创建表,更改表结构,删除表,建立索引。删除索引等。
- DCL:数据控制语言:是用来控制数据库的访问:包括授予与撤销访问权限,提交事务以及回滚事务,设置保存点等
- desc tableName;查看表的列的信息
- select * from user_tables; 查看自己用户下的所有的表的视图;
select :查询关键字
- select * from tableName;从指定的tableName 表中查询全部的信息出来,* 表示全部。
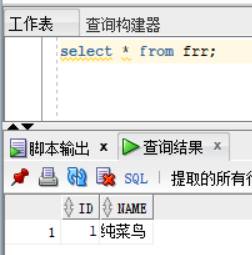 frr表是自己创建的
frr表是自己创建的 - select id from tableName;从制定的tableName表中查询指定的列,相较于上一个命令,这个的查询结果只显示了需要的列,指定的列名必须存在于表中,desc tableName可查看表列信息
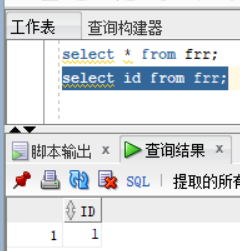
- sql 语言的大小写不敏感,sql语句可以分行来写,
- 关键字不能被缩写,也不能分行写,大小写不敏感
- 计算符号 + - * / 可用于类型为number 的列值 和 类型为date 的列值
- 表的信息
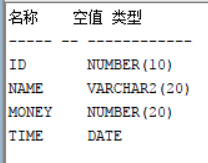
- 可以进行计算数字的运算结果,dual是一个伪表
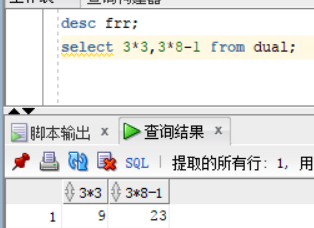
- 时间的计算使用:
- y年
- M月
- d日
- H 时在一天中的
- m分
- s秒
- 下列中的时间的格式中的 MI和MM的区别
- MI是在现在的实时时间上加上指定的时间
- MM是表示月份与java中的时间有些差别
- date函数的乘法和除法运算是无效的
- 表的信息
定义空值 null,凡是与空值参与的运算结果都为空,null不是0或者空格
查询frr表,id为2 的懒蛋用户的money字段为空
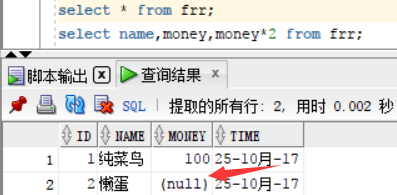
进行第二个命令 :select name,money,money*2 from frr;
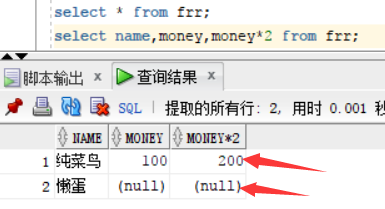 可见懒蛋用户的计算结果也为null,
可见懒蛋用户的计算结果也为null,
为列名起别名。别名就是在家老爸老妈叫你的小名儿,为了方便我们可以为任何想改变的字段的名起一个小名儿。
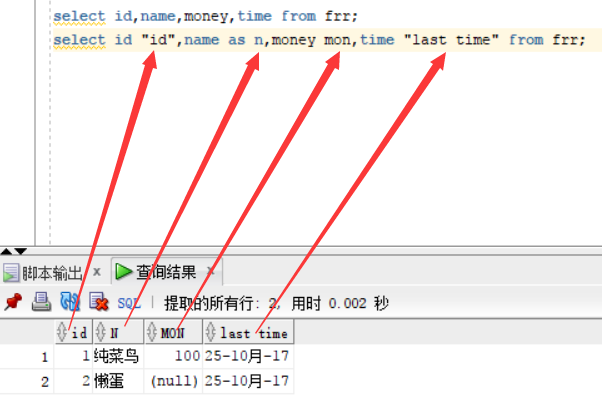
- 查询frr表,select id,name,money,time from frr;,所查询出来的表的字段默认为大写形式,

- 再次查询此表,用别名的方式查询,在查询的时候可以使用as关键字来指定列的别名,也可以忽略使用as不影响,查询出来的列名默认为大写,如果想使用小写来显示,那么把别名用双引号引起来即可,如果两个单词想表示一个列的列名,那么使用双引号引起来一样有效,如下图
- 连接符: ||, select name ||'的出生日期是 :' ||time from frr;

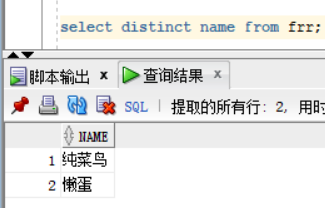
- 去除重复的内容:distinct,distinct必须放在最开头
- 查询frr表,表中有两id,名字一样的名为 纯菜鸟的 行信息

- 根据名字去重
- 有时候也会根据多个字段一起来判断重复的行进行去重
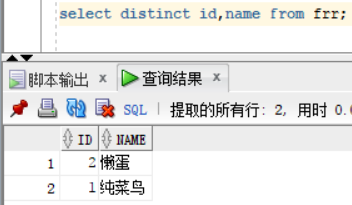
- 查询frr表,表中有两id,名字一样的名为 纯菜鸟的 行信息
where条件查询: 在查找信息内容的时候可以用where进行条件的筛选
现在表中的信息的情况如下

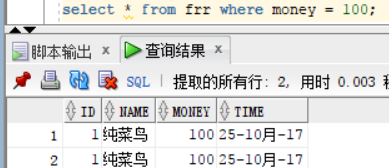
我们将money等于100的查询出来:select * from frr where money = 100;where 关键字后面是跟的查询的条件
具体的查询的条件的符号以及意思如下

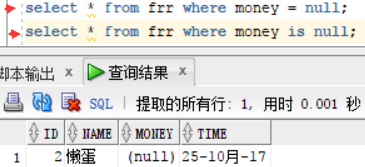
再查询money等于空值的信息:select * from frr where money = null ;这么进行查询的是不会的到结果的,因为这样查询的意思不是在判断是否为空值,如果此字段为空的话用 is 关 键字,下图第一个查询是没有结果的,执行的是第二个查询出来的“懒蛋”
where条件为字符或者日期格式的 ,需要用单引号引起来,单引号中严格区分大小写
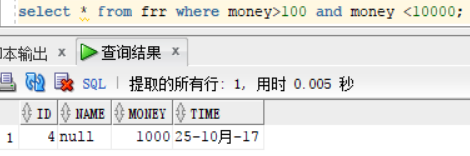
查询money字段大于100 小于10000的人的信息:select * from frr where money>100 and money <10000; 在这 新关键字 and 代表并列的一起,代表所查询的值的区间是大于100 与 小于10000的
其他的比较运算符的关键字

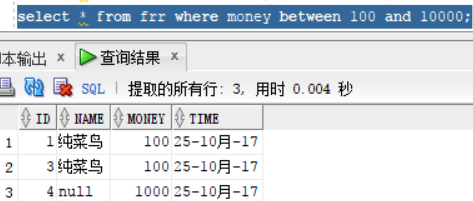
between--and--:查询money在100 与 10000之间的人的信息:select * from frr where money between 100 and 10000;,对照上一个查询就可以看出来,between-and 包含临界值
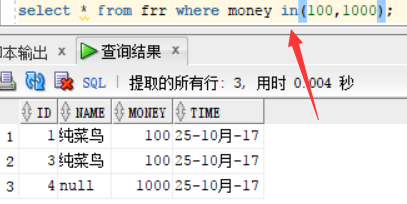
in:查询money等于100 与等于1000的人的信息:
方法一:select * from frr where money =100 or money =1000; 这里我们使用了 or 关键字,区别与上述的 and 关键字,or 关键字是或者的意思,意思就是,满足等于100 或者 满足 等于1000都会被 查询到

方法二: 这里我们是用的in关键字,作用跟or关键字查询结果一样,但是in关键字不可以取一个范围的值,
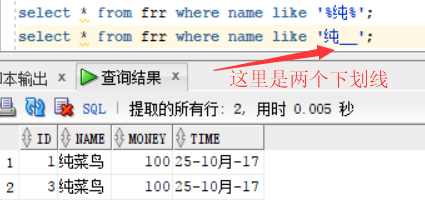
like:用于模糊查询的关键字,
查询名字中带有“纯”字的人的信息出来:在图中的两种方式的出现的% 与 _ 做一下说明,%就是代表任意数量的字符,而_ 只代表一位字符,
select * from frr where name like '%纯%';
select * from frr where name like '纯__';
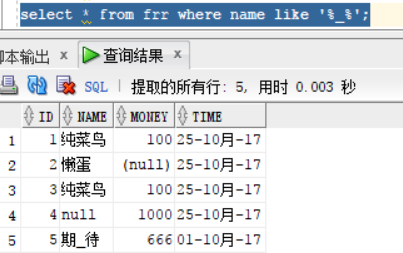
如果我们想查询名字中带有 _ 得人的名字,
select * from frr where name like '%_%'; 这样会把所有人的名字全部查询出来,这时候_也是会被当做成任意一位的字符处理,显示结果如下
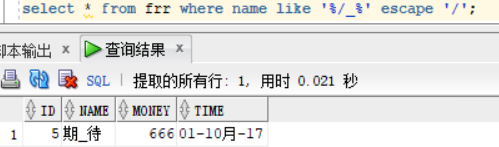
正确姿势: select * from frr where name like '%/_%' escape '/'; escape 关键字规定的后面单引号中的内容为转移符,在这里 / 被定义为转移符,'%/_%' 中 转移符/ 后的_ 就会被当作为一个普通的 字符进行处理
order by: 用来排序的,可以按照不同的列名进行升序与降序的排序,asc 从小到大,desc 从大到小,默认为asc
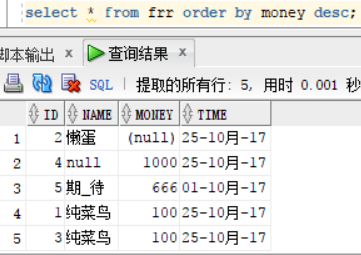
select * from frr order by money asc;
select * from frr order by money desc;
 。。
。。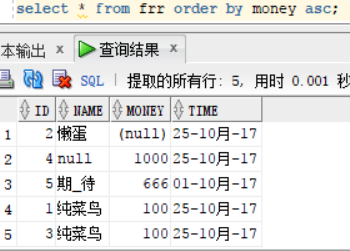
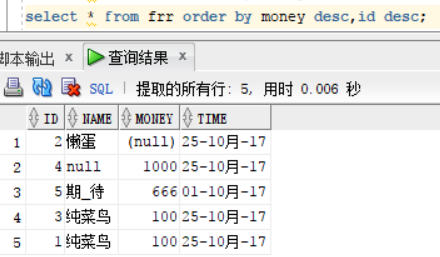
我们看到按照money排序后,出现两个money为100的,我们需要再次根据id从大到小排序的话,我们只需要在后面进行添加需要排序的字段以及对应的排序规则即可
select * from frr order by money desc,id desc;
函数

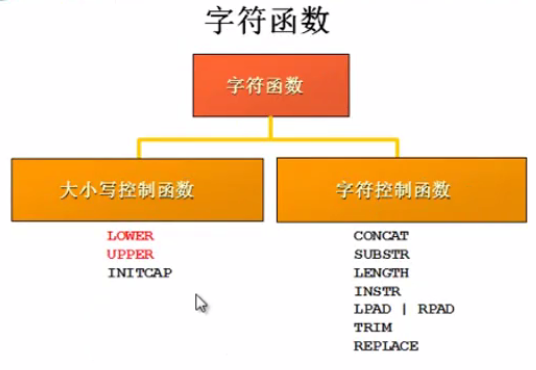
大小写控制函数 : lower , upper , initcap,从下面就可以看出三个函数的功能
lower:将大写字母全部转换为小写字母
upper:将小写字母全部转换成大写字母
initcap:将每个单词的首字母进行转换大写处理

如果我们不知道查询的用户的名字或者其他信息的大小写状态的话,我们可以将名字全部转换成大小写,然后去判断即可
字符控制函数:

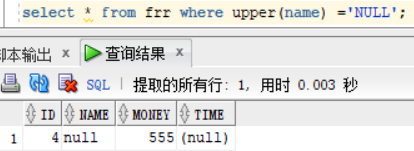
concat('str1','str2'):就是把两个字符串str1 和 str2 拼接在一起
substr('str1',1,5):从字符串str1 的第一位开始,输出五位字符
select concat('Qidai',' in Oracle'),substr('Qidai in Oracle',1,7) from dual;
length('str1'):返回str1 的长度
instr('str1','w'):返回字母w 在str1 中首次出现的位置
select length('Qidai in Oracle'),instr('Qidai in Oracle','i') from dual;

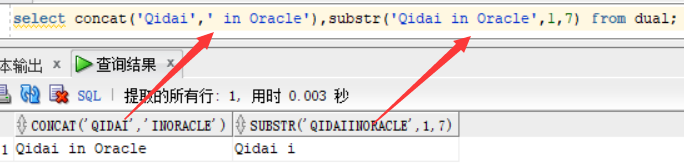
lpad('str1',10,'-'):以十个字符位置显示str1,不够的用 "-" 左补齐,str1 超出的话,只显示str1 前十位
rpad('str1',10,'-'):以十个字符位置显示str1,不够的用 "-" 右补齐,str1 超出的话,只显示str1 前十位
select lpad('Qidai',10,'-'),rpad('Qidai',10,'-') from dual;
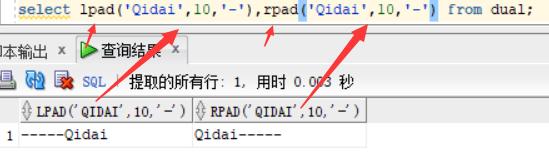
trim('d' from 'str1 '): 将d 从str1 中去除掉,只去除首尾的指定字母,如下图中首尾已经将指定的字母去掉,而中间的字母没有去掉,
replace('str1','s','r'):将str1 中的 指定字母s 全部替换成 指定字母 r,
select trim('d' from 'dddQdidaiddd'),replace('dddQdidaiddd','d','r') from dual;
数字函数

round(num1,num2): 将num1 按照num2 的保留位数四舍五入
select round(53.444,2),round(53.444),round(53.444,-1) from dual;
round(53.444,2) 安四舍五入 保留两位小数
round(53.444) 不写保留位数的话,默认为0,所以它会先按一位小数进行四舍五入 : 例 round(53.544) = 54 即 53.5 四舍五入为54.0
round(53.444,-1) 参数为负数的话,就是在小数点右边进行按参数位的四舍五入操作:例 round(55.444,-1) = 60 即 55 四舍五入

trunc(num1,num2):按照参数num2 的指定位数进行对num1 的截断,不进行四舍五入操作
select trunc(53.444,2), trunc(53.544),trunc(55.544,-1) from dual;所有操作区别与上一个函数round,此函数直接截断,

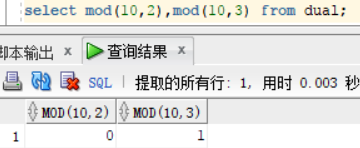
mod 求余函数,下表中,10/2=5是没有余数的,所以为0 , 10/3=3 余1,所以 结果为1
日期函数
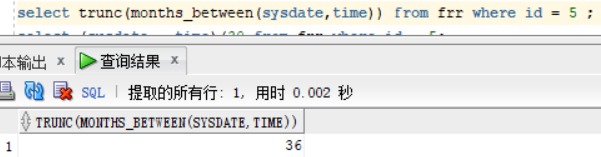
months_between:计算两个日期的相差的月份 :id 为5 的创建时间为 14年-10 月-21号
select trunc(months_between(sysdate,time)) from frr where id = 5 ; 先进行函数的运算,然后用trunc去截断,取出整数
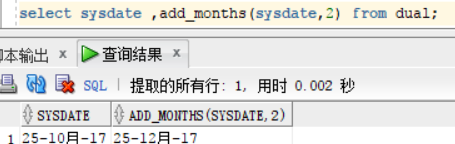
add_months(date,number):在指定日期上加上number 个月份,上面在运算符的时候,有提到不用函数进行日期的运算
select sysdate ,add_months(sysdate,2) from dual; 查询结果为:当前日期,,已经处理过的当前日期
next_day(date,'星期几') :结果为指定date日期上的 下一个指定星期几,
select next_day(sysdate,'星期六') from dual;指定当前日期的下一个周六是几号
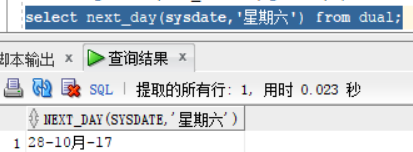
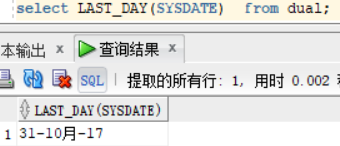
last_day(sysdate) :本月的最后一天
select LAST_DAY(SYSDATE) from dual;
对于时间的 trunc 和 round:结果为 当前时间,按月进行四舍五入,按小时进行四舍五入,按月进行截断,按小时进行截断。
select to_char(sysdate,'yyyy-mm-dd HH:MI:SS'),round(sysdate,'mm'), round(sysdate,'hh'),trunc(sysdate,'mm'),trunc(sysdate,'hh') from dual;

转换函数.重点
涉及到数据类型的转换,
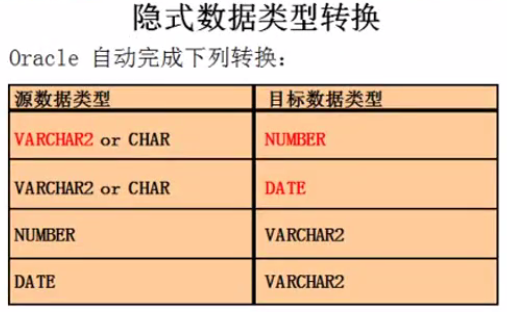
从上图可以看出来Oracle会自动完成上述的类型的相互转换 date <> varcahar2 or char <> number 这一类关系
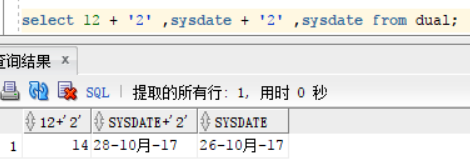
select 12 + '2' ,sysdate + '2' ,sysdate from dual; 从结果也可以看出来,Oracle会帮我们自动的做转换,这里区别与java中的 + ,如果想做连接操作可以使用 || 或者使用concat 函数来进行连接操作
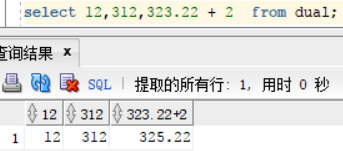
但是往往有时候有些运算用隐式转换不能够处理好问题 , 例 : 12,312,323.22 + 2 这个运算,Oracle会以 “,” 为分割看成三列,只有最后一列与2 做运算
select 12,312,323.22 + 2 from dual;
这时候我们就要进行将这一串数字进行显示的转换后进行运算了,
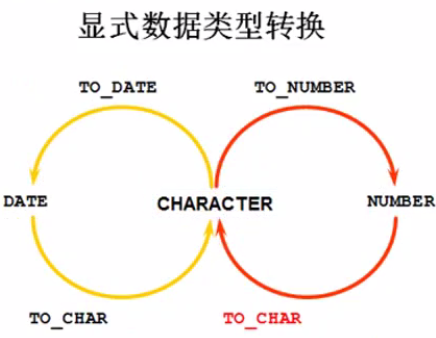
从上图中我们可以看出,将char类型或者varchar类型的哪来举例子,char 可以 通过 to_number 转换成 number类型。number 类型也可以通过to_char来转换回来,char类型通过to_date转换成日期类 型,日期类型也可以通过to_char再次转换回去
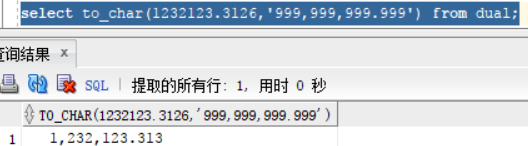
数字到字符的转换:select to_char(1232123.3126,'999,999,999.999') from dual; 从图中可以看出来,把数字按照指定格式进行了输入,会自动进行四舍五入操作,
数字到字符的转换:select to_char(1213.1,'$999,999,999.999'),to_char(1213.1,'L000,000,000.000') from dual;如下图,可以进行加入美元符。也可以用L来表示当地的货币符号,这里使用0来进行 格式化数字,不满的数字位数都进行补零操作。

字符到数字的转换:select to_number('¥000,001,213.100','L000,000,000.000'), to_number('$000,001,213.100','$999,999,999.999') from dual;需要注意的是互相转换的符号必须一致,在这里就可以 解决上述隐式转换出现的问题了,

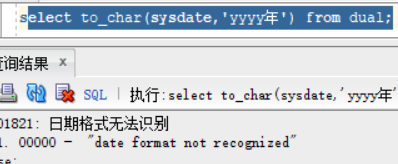
实例问题:需求我们输出 2017年10月27日,这时候直接使用 select to_char(sysdate,'yyyy年') from dual;就会出错
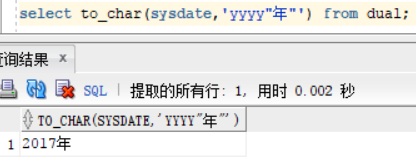
我们操作这个问题的时候,需要用双引号来引起“年”,就可以解决问题
通用函数

NVL(s1,s2):如果s1不为空就使用s1,如果为空就用s2代替,将空值转换成一个已知的值,可以使用的数据类型有:日期,字符,数字,
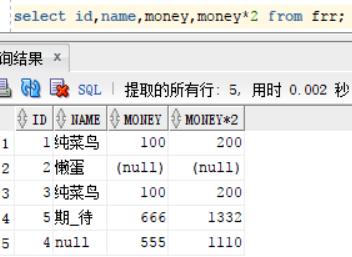
我们看到下列中的id为2 的money为空。select * from frr;

所以与空值运算的结果为空 select id,name,money,money*2 from frr;,所以下图中的 money*2 就为空,
但是有时候我们希望没有值的会给一个默认值代替这个null值,所以我们就可以用到了NVL 函数
select id,name,money,nvl(money,0) from frr; 图中money为空,我们就用0代替了null 了
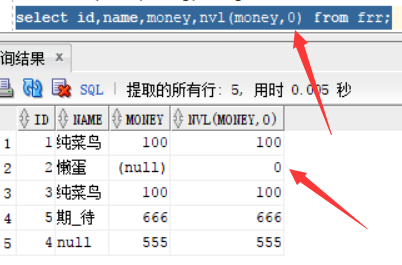
但是我们想用字符去代替就会出错了 : select id,name,money,nvl(money,'穷鬼')from frr;,因为money是number类型的,两个参数间替换的话会出现不兼容的情况,所以会出现错误
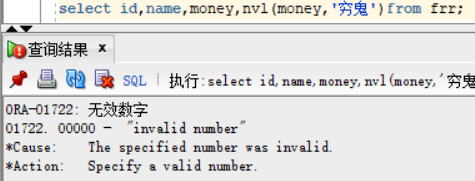
我们可以把他转换成char类型的再去替换就好了,select id,name,money,nvl(to_char(money),'穷鬼')from frr; 在这也可以看出函数是可以嵌套使用的
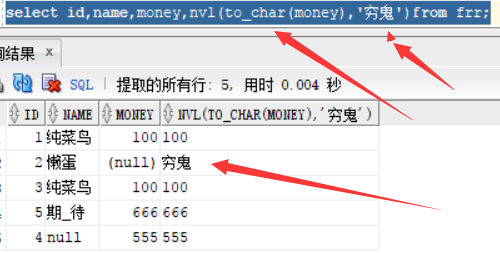
NVL2(s1 , s2 , s3):当s1参数不为 null 的话返回 s2参数的值,为null 的话返回s3 参数的值,下面查询 如果frr表中的 money为空的话返回没钱,不为空的话返回有钱和具体的钱的金额数量,相当于Java中 的: s1 ? s2 : s3
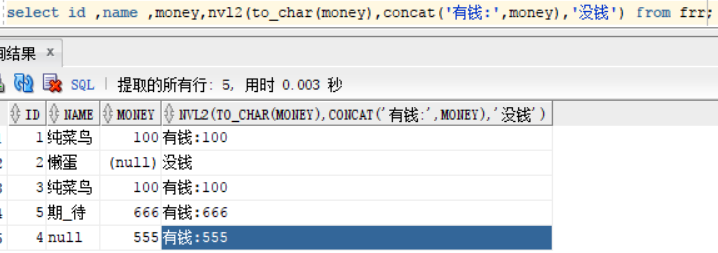
select id ,name ,money,nvl2(to_char(money),concat('有钱:',money),'没钱') from frr;
NULLIF(s1 , s2) : 相等返回 null,不相等返回 s1,
我们查出表中的id 为 555的用户如下
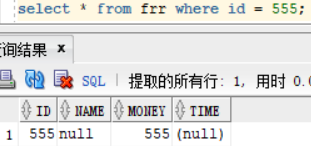
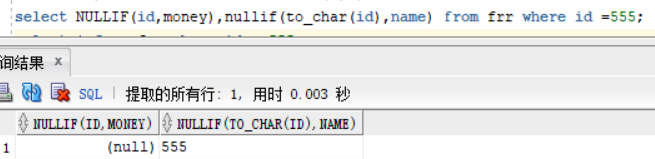
从图中看出id 与 money相等,id与名字不相等,我们使用函数查询:select nullif(id,money),nullif(to_char(id),name) from frr where id =555; 图中就能看出此函数的效果
COALESCE(s1 , s2 , s3...):相较于nvl优点是可以处理多个表达式的值,如果s1 为空 返回s2,s2 为空返回s3,以此类推
我们查看表中id 为6 的用户,只有id 有值,其余字段全部为空 :查询的时候注意参数要全部类型一致。
select COALESCE(to_char(name),to_char(money),to_char(time),to_char(id)),COALESCE(name,to_char(money),to_char(sysdate),to_char(id)) from frr where id =6;
从图中第二个查询表达式来看,他并没有返回id,而是返回的现在时间,就能显示出函数的作用了
条件表达式

case表达式语法格式:

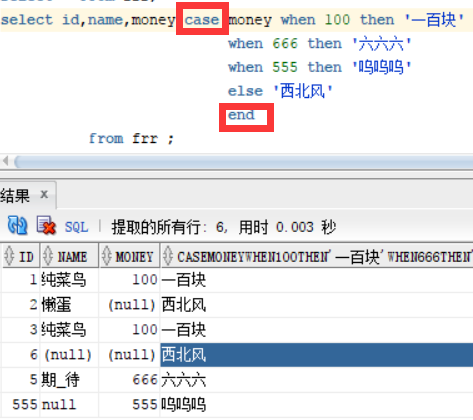
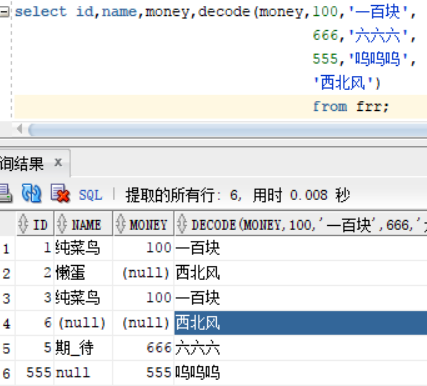
frr表中有四个不同的money的值 分别为:100,555,666 和null ,我们来用case表达式来进行演示。当money=100的时候输出一百块,等于666的时候输出六六六,等于555的时候输出呜呜呜,其他的值 直接输出西北风!!这个case函数有点类似于java中的switch
select id,name,money,case money when 100 then '一百块'
when 666 then '六六六'
when 555 then '呜呜呜'
else '西北风'
end
from frr ;
图中标注的end为结束符,case 后面可以跟一个变量或者常量数字
decode表达式语法格式
decode表达式与case 比较类似,只是去掉了一些关键字,查询跟case中相同:当money=100的时候输出一百块,等于666的时候输出六六六,等于555的时候输出呜呜呜,其他的值直接输出西北 风!!
select id,name,money,decode(money,100,'一百块',
666,'六六六',
555,'呜呜呜',
'西北风')
from frr;
decode表达式相较于case表达式,decode使用小括号来开始和结束表达式,而且必须带有逗号加以分割,而case 则是用关键字来分割条件的。
多表查询
建表语句
--建表
--student表+注释
create table student(
sno varchar2(3) not null,
sname varchar2(9) not null,
ssex varchar2(3) not null,
sbirthday date,
sclass varchar2(5),
constraint pk_student primary key(sno)
);
comment on column student.sno is '学号(主键)';
comment on column student.sname is '学生姓名';
comment on column student.ssex is '学生性别';
comment on column student.sbirthday is '学生出生年月日';
comment on column student.sclass is '学生所在班级';
--course表+注释
create table course(
cno varchar2(5) not null,
cname varchar2(15) not null,
tno varchar2(3) not null,
constraint pk_course primary key(cno)
);
comment on column course.cno is '课程编号(主键)';
comment on column course.cname is '课程名称';
comment on column course.tno is '教工编号(外键)';
--score表+注释
create table score(
sno varchar2(3) not null,
cno varchar2(5) not null,
degree number(4,1),
constraint pk_score primary key(sno,cno)
);
comment on column score.sno is '学号(主键)';
comment on column score.cno is '课程编号(主键)';
comment on column score.degree is '成绩';
--teacher表+注释
create table teacher(
tno varchar2(3) not null,
tname varchar2(9) not null,
tsex varchar2(3) not null,
tbirthday date,
prof varchar2(9),
depart varchar2(15) not null,
constraint pk_teacher primary key(tno)
);
comment on column teacher.tno is '教工编号(主键)';
comment on column teacher.tname is '教工姓名';
comment on column teacher.tsex is '教工性别';
comment on column teacher.tbirthday is '教工出生年月';
comment on column teacher.prof is '职称';
comment on column teacher.depart is '教工所在单位';
--添加外键
alter table course add constraint fk_tno foreign key(tno) references teacher(tno);
alter table score add constraint fk_sno foreign key(sno) references student(sno);
alter table score add constraint fk_cno foreign key(cno) references course(cno);
--添加数据
--Student表
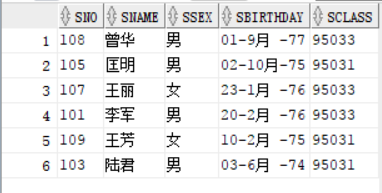
insert into student(sno,sname,ssex,sbirthday,sclass) values(108,'曾华','男',to_date('1977-09-01','yyyy-mm-dd'),95033);
insert into student(sno,sname,ssex,sbirthday,sclass) values(105,'匡明','男',to_date('1975-10-02','yyyy-mm-dd'),95031);
insert into student(sno,sname,ssex,sbirthday,sclass) values(107,'王丽','女',to_date('1976-01-23','yyyy-mm-dd'),95033);
insert into student(sno,sname,ssex,sbirthday,sclass) values(101,'李军','男',to_date('1976-02-20','yyyy-mm-dd'),95033);
insert into student(sno,sname,ssex,sbirthday,sclass) values(109,'王芳','女',to_date('1975-02-10','yyyy-mm-dd'),95031);
insert into student(sno,sname,ssex,sbirthday,sclass) values(103,'陆君','男',to_date('1974-06-03','yyyy-mm-dd'),95031);
--teacher表
insert into teacher(tno,tname,tsex,tbirthday,prof,depart) values(804,'李诚','男',to_date('1958/12/02','yyyy-mm-dd'),'副教授','计算机系');
insert into teacher(tno,tname,tsex,tbirthday,prof,depart) values(856,'张旭','男',to_date('1969/03/12','yyyy-mm-dd'),'讲师','电子工程系');
insert into teacher(tno,tname,tsex,tbirthday,prof,depart) values(825,'王萍','女',to_date('1972/05/05','yyyy-mm-dd'),'助教','计算机系');
insert into teacher(tno,tname,tsex,tbirthday,prof,depart) values(831,'刘冰','女',to_date('1977/08/14','yyyy-mm-dd'),'助教','电子工程系');
--course表(添加外键后要先填teacher表中数据去满足外键约束)
insert into course(cno,cname,tno) values('3-105','计算机导论',825);
insert into course(cno,cname,tno) values('3-245','操作系统',804);
insert into course(cno,cname,tno) values('6-166','数字电路',856);
insert into course(cno,cname,tno) values('9-888','高等数学',831);
--score表(添加外键后要先填Student,course表中数据去满足外键约束)
insert into score(sno,cno,degree) values(103,'3-245',86);
insert into score(sno,cno,degree) values(105,'3-245',75);
insert into score(sno,cno,degree) values(109,'3-245',68);
insert into score(sno,cno,degree) values(103,'3-105',92);
insert into score(sno,cno,degree) values(105,'3-105',88);
insert into score(sno,cno,degree) values(109,'3-105',76);
insert into score(sno,cno,degree) values(101,'3-105',64);
insert into score(sno,cno,degree) values(107,'3-105',91);
insert into score(sno,cno,degree) values(108,'3-105',78);
insert into score(sno,cno,degree) values(101,'6-166',85);
insert into score(sno,cno,degree) values(107,'6-166',79);
insert into score(sno,cno,degree) values(108,'6-166',81);
执行sql语句后,会建立四个表,注意在复制过去后需要把数字删掉才行,,如图
关系:每个student 表中有学号主键sno,外键为表score中对应的sno,每一个score表中有课程号,去对应课程表course,表course中有教职工的tno,对应teacher表中的tno

我们来查看一下student中的数据
内连接:合并具有同一列的两个以上的表的行,结果中不包含一个表与另一个表不匹配的行
等值连接:
下面我们来查 sno为101的李军同学。他所对应所修的课程号和课程的成绩,那么这时候就需要查询student 和 score表了。
select student.sno,sname,ssex,degree,cno from student,score where student.sno = score.sno and student.sno =101;
查询出李军的学号,名字,性别,专业课成绩,专业课的课程号,在这里,如果两个表中都有sno或者其他相同字段。需要用表名“.”去指定是查哪一个表中的字段,否则会报错“未明确定义列”
student表名有点长,我们可以起一个别名。下面的查询命令与上面的作用一样,
select stu.sno,sname,ssex,degree,cno from student stu,score sco where stu.sno = sco.sno and stu.sno =101;

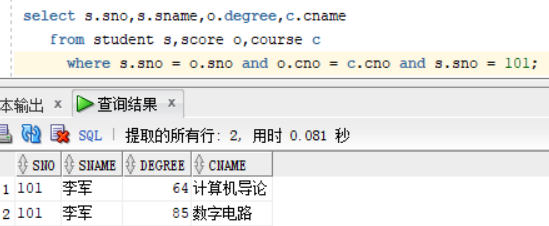
查询sno为101 李军的,课程号,课程名,课程成绩,这时候就会涉及到三个表的查询, 课程号来自scorce表,sno和李军名字来自student表,课程名来自cource表
select s.sno,s.sname,o.degree,c.cname
from student s,score o,course c
where s.sno = o.sno and o.cno = c.cno and s.sno = 101; 图
终极查询:查101 的 李军的,课程号。课程名,所修课程分数,任课老师,在进行比较多的查询的时候,我们可以看着表关系图来写查询语句,这样的思路更加清晰
select stu.sno,stu.sname,sco.degree,cou.cname,tea.tname
from student stu,score sco,course cou,teacher tea
where stu.sno = sco.sno and sco.cno = cou.cno and cou.tno = tea.tno and stu.sno = 101;

表关系图的位置:从图中可以看出有一个查询构造器
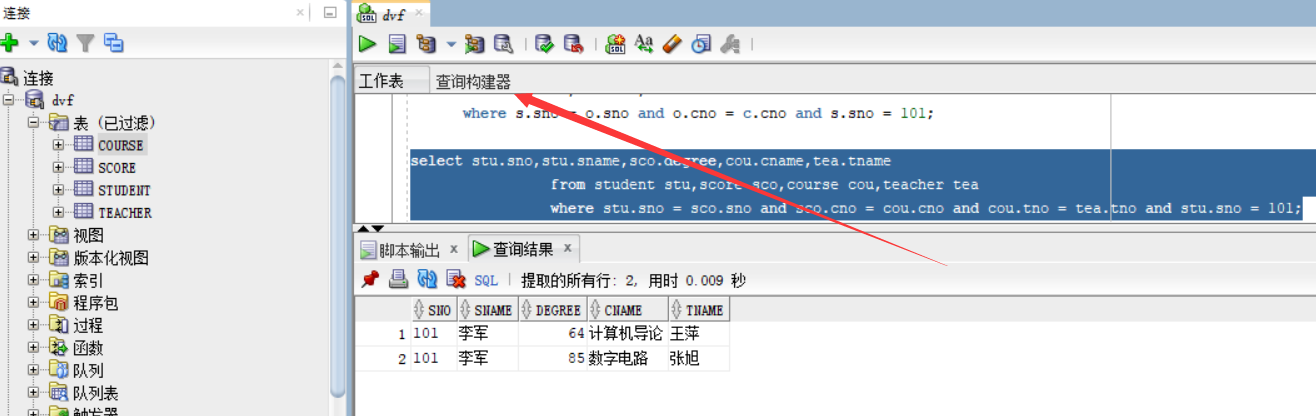
我们只要把自己创建的表鼠标左击选中不松拖过去就可以显示表关系图了
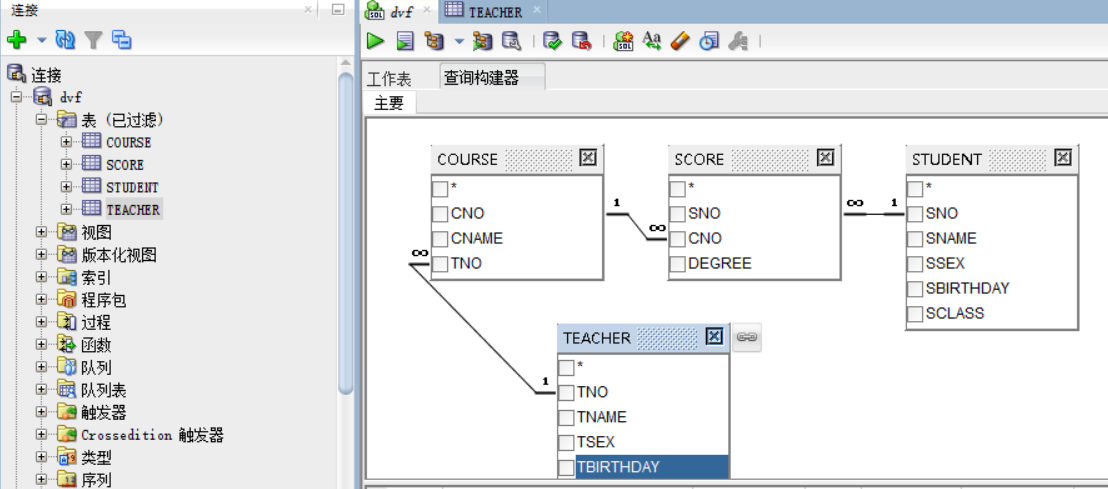
非等值连接
其实与等值连接差不多,就是where后的条件不相等,
查询sno为101 李军的成绩在80到100之间的课程名
select stu.sno,stu.sname,sco.degree,cou.cname,tea.tname
from student stu,score sco,course cou,teacher tea
where stu.sno = sco.sno and sco.cno = cou.cno and cou.tno = tea.tno and stu.sno = 101 and degree between 80 and 100;
查询结果相较于上面的,去除了成绩为65 的信息
外连接:两个表在连接过程中除了返回满足连接条件的行以外还返回左或者右表中不满足条件的 行,这种称为左外连接或者右外连接,没有匹配的行时,结果表中相应的列为空,外连接的 where子句条件类似内部连接,但连接条件中没有匹配行的表的列后面要加外连接运算 符,即用圆括号括起来的加号(+).
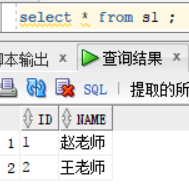
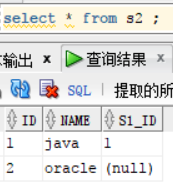
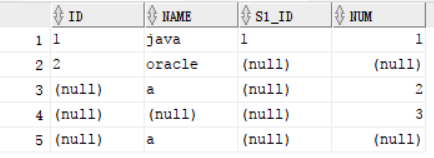
创建了两个新表s1与s2:数据如下。左边为s1 的数据,右边为s2的数据,从中可以看出来oracle并没有老师任课
 。
。
但是我们想查询课程吗名以及所对应的老师的名字的时候,会出现下面的情况, 由于oracle没有任课老师就没有显示出来。但其实是有这门课程的,这时候就需要用到了外连接。
select s1.id,s2.name,s1.name from s1,s2 where s1.id = s2.s1_id;
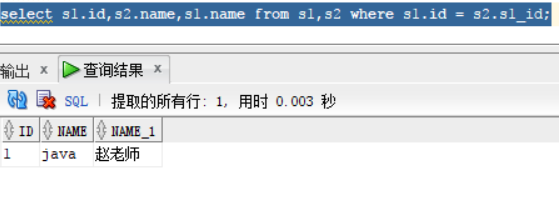
select s1.id,s2.name,s1.name from s1,s2 where s1.id(+) = s2.s1_id; 想显示oracle,因为oracle在s2 表中,s1 表为老师表,所以需要在s1 表的条件后加 “(+)”,相反如果想显示老师的话,就要在 s2后加“(+)”
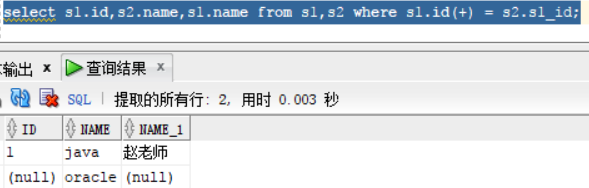
select s1.id,s2.name,s1.name from s1,s2 where s1.id = s2.s1_id(+);
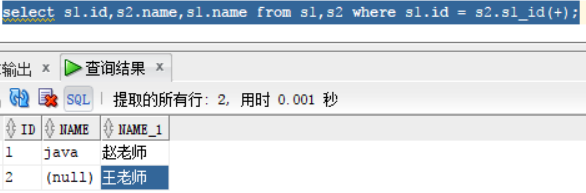
但是想查看两方的内容的话不能两边条件都加"(+)"否则会报错,
叉集和笛卡尔机是相同的,使用cross join子句使连接的表产生叉集。叉集意思是 ,如图,意思就是两个表中的字段都进行关联,结果数为 s1 表的字段数 * s2 表的字段数

三种方式来进行多表查询的等值连接查询
1. 第一种上面已经说了
2. 第二种是使用join--using 来进行查询的,与上面的查询结果是一样的,但是有局限性,那就是最后小括号里的字段名,必须两个表中同时具有,并且类型一直
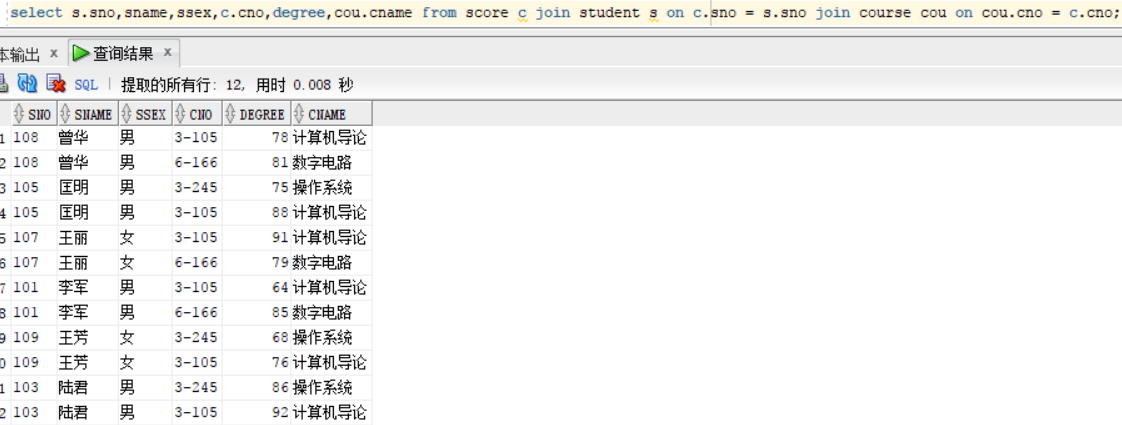
3. 第三种是使用join--on 来进行查询,查询结果相同,join代表两个表进行联查,on关键字后面是填写的查询条件。

当我们进行多个表的join时,在两个表或者多个表有相同字段的时候一定要指定某个字段的归属表,否则报错
select s.sno,sname,ssex,c.cno,degree,cou.cname from score c join student s on c.sno = s.sno join course cou on cou.cno = c.cno;
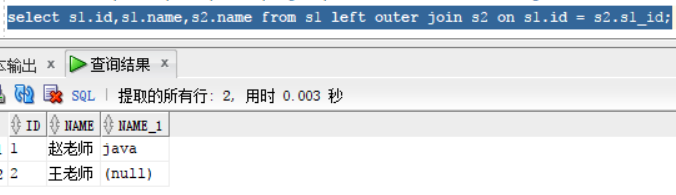
对于上面的左外右外连接,除了使用条件一边加(+)的方式我们还可以使用以下方式
left outer join -- on:左外连接。相当于上边提到的在右边表条件后加(+)
select s1.id,s1.name,s2.name from s1 left outer join s2 on s1.id = s2.s1_id;
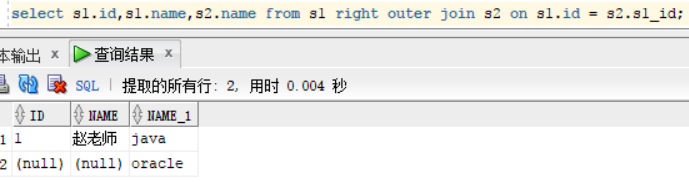
right outer join -- on:右外连接。相当于上边提到的在左边的表条件后加(+)
select s1.id,s1.name,s2.name from s1 right outer join s2 on s1.id = s2.s1_id;
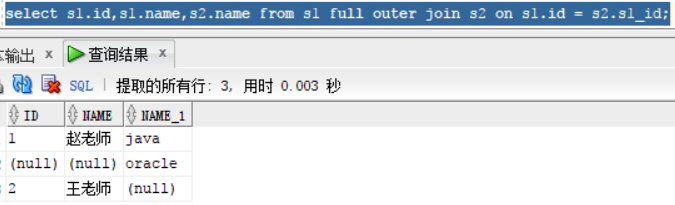
解决上面只能一边连接的问题,full outer join -- on:满外连接,返回满足条件的和不满足条件的行。
select s1.id,s1.name,s2.name from s1 full outer join s2 on s1.id = s2.s1_id;
自连接,即在一个表上查询,可以用一个表的两个镜像来进行查询,查询出所需要的结果,
例:老师表中,校长也算是老师吧,然后查询名字叫李冰老师的所对应的校长的名字和各类信息,如下图,右侧表信息中 boos_id对应着校长的tno。boos打错了,应该是boss
select tea.tno,tea.tname,tea.prof,tea.depart,
tea2.tno,tea2.tname,tea2.prof,tea2.depart
from teacher tea,teacher tea2 where tea.boos_id = tea2.tno and tea.tname ='刘冰';
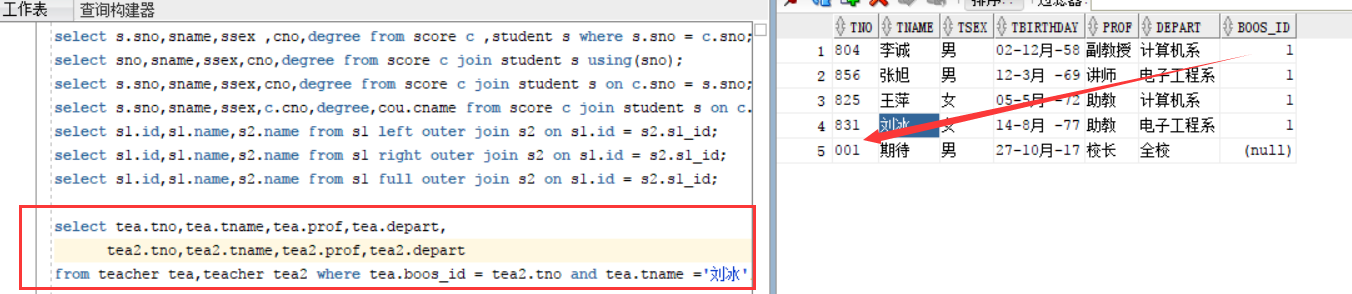
查询结果为

组函数:AVG:平均数 。 COUNT:计数。 , MAX :最大值。 , MIN:最小值 。 , SUM:求和 。,STDDEV:求标准差(很少用,除了专业的分析的时候用到)
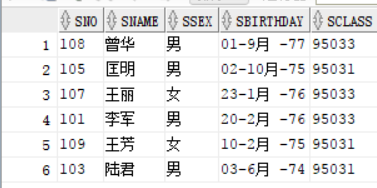
max与min:分别是求最大值与最小值,参数可以为数字,日期,和字符。
排序规则,数字是排大小,日期是最近的日期是大的,反之是小的,字符是按照ASCII码拍的,这里不是很确定,但是我试了试,a与b,最后max输出的为b
select max(sno),min(sno),
max(sname),min(sname),
max(sbirthday),min(sbirthday)
from student;
下面是表中的信息和结果

avg和sum:分别是用来求平均数和求和用的,参数只能为数字类型,其他类型报错,表数据还是上表,结果为
select avg(sno),sum(sno) from student;

count,用来计数用的,参数不为空,表数据还是一样的表数据,我们来看结果
select count(sno),count(sname),count(123123),count('4'),count('') from student;
前四个均为6.也是就student表中的行数,说明了count参数为类名或者数字都行,一样会返回行数,这里就意思就是:只要有一条数据就会count加一次,前提是必须有参数,但是看后两个字 符型的,第一个是有字符 4 的,但第二个是没有参数的,只有一个空字符,在这猜测可能count的参数不限制,只要有值就可以计算行数,处理空字符和null都返回0,如果不对请指正
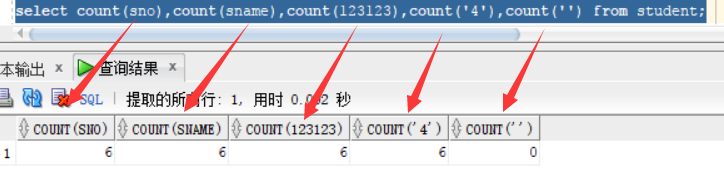
select avg(sno),sum(sno)/count(sno) from student; 从图中可以看出来哦 avg = sum / count
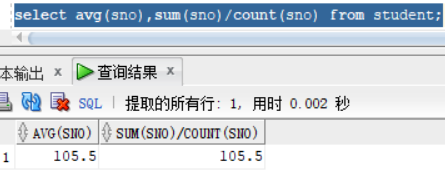
表数据:里面有很多空值
我们可以看到count 并没有计算字段为null的值的数量。同样avg同样没有计算为null的字段:avg = (3+2+1)/3,因为只有三行是有效的,表数据有中name字段有两个a,我们在这可以去重操作

group by:分组函数。
表信息:
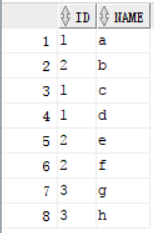
可以看到id列有许多一样的,我们可以根据一样的列的信息对他进行分组,查询结果如下,分组为 1,2,3。但是这里需要注意的是select 后面的列名,在group by函数后面必须有,而group by函数 后列名select后可以没 有,select后的聚合函数除外,否则就会报错

如果想有一些过滤条件的话,我们直接在 from 后面加where 过滤就行,对照着上面的表信息。我们就可以看出来效果了,name 在a和b之中的就只有id 为1 和 2

表数据
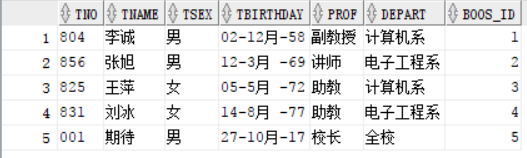
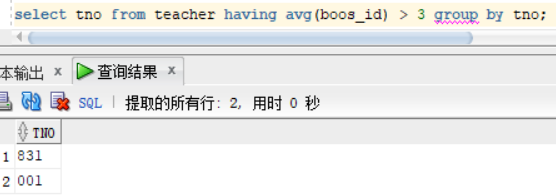
查找出boos_id 大于 3 的tname,我们习惯是用where来过滤条件,但是这里是用到了组函数,where后是不能加函数的,如图

这时候我们就需要使用having 来替换where关键字,
子查询:


表数据:
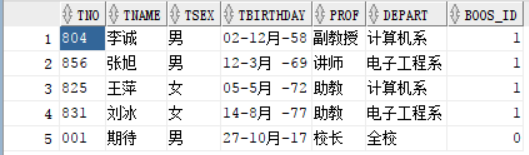
我们来查询“谁比名字叫做李诚的人的tno小”,首先我们需要查询出名字为李诚的tno为多少,再根据tno的值再去查询谁比这个tno的值小,这是要分两步来查的,
select tno from teacher where tname ='李诚';-- tno : 804
select tname,prof from teacher where tno < 804;
结果图:
首先执行第一条查询的结果图
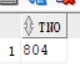
第二条查询的结果图,后面的804是根据第一个查询语句的结果进行查询的

我们利用子查询就能解决分两步才能查出来的结果,
select tname,prof
from teacher
where tno <(select tno from teacher where tname='李诚');
这里的查询是吧名字为李诚的tno查询结果直接作为主查询的条件了,由于这里的括号里的查询只返回了一条结果,也称作为 单行子查询

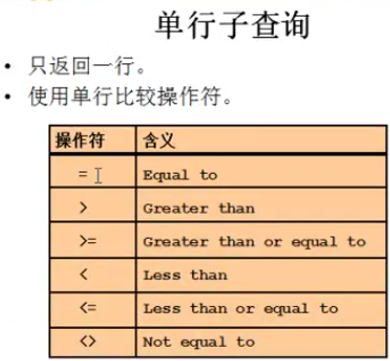
还是上面的数据表的数据,这次我们来查“跟李冰boos_id相同的,但是比李冰tno大的人的姓名,性别,职位”
select tname,tsex,prof from teacher
where boos_id=(
select boos_id from teacher where tname='刘冰')
and tno>(
select tno from teacher where tname = '刘冰');
查询结果图
 、
、
表数据不变,在子查询中使用组函数:“查询tno最小的人的tname”
select tno,tname from teacher where tno = (select min(tno) from teacher );

表数据不变,“”--查询boosid为1 的最小tno的老师的姓名,性别,职位“”,其中 校长的tno 为001 是最小的,我们需要排除掉校长,去查询老师中的信息
select tname,tsex,prof from teacher where boos_id= 1
and tno=(select min(tno) from teacher where tno != 001);
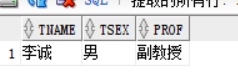
下面这个在子查询中是返回的按照department_id进行分组的每组的最低工资salary ,主查询中最后的where条件使用的是 = ,主函数中salary不能去匹配返回的多行信息,所以就出错了,单行只能用 上面图中列出来的符号

当子查询中返回了空值的话,查询语句不会报错,只会显示 0返回 ,即没有返回结果
多行子查询:子查询中返回多行的信息供主查询使用
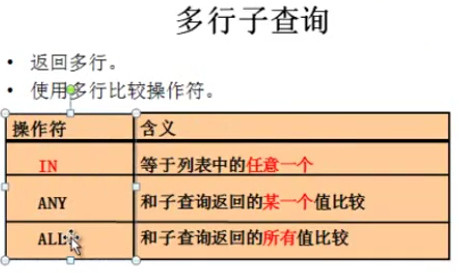
in前面提到过就是只由这几个数值的条件,比如:in(11,2,3); 代表查询条件只能等于11或2 或者3
any表示任一,某一个满足就可以。 比如:> any (11,2,3),代表只要满足大于11或者大于2或者大于3 的,只要满足其中一个条件就行,
all表示任意,全部所有,比如> any (11,2,3),代表必须大于所有的数,其中11最大,在这也就是必须大于11
表数据不变,我们来查询boos_id 为 1 或者 0 的老师的名字和性别
select tname , tsex from teacher where boos_id = 1 or boos_id =0;
select tname ,tsex from teacher where boos_id in(1,0);
这两条查询结果都相同
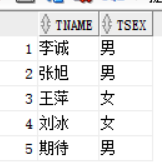
除了这两个方法之外,我们可以用多行子查询来进行查询
select tname , tsex from teacher where boos_id = any (select boos_id from teacher group by boos_id);
any是任一一个即可,所以效果相当于上面的两条查询语句,只要满足一个就可以
查询结果与上图相同
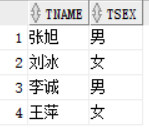
我们来查询 boos_id >= 1或者 0 的老师的名字和姓名
select tname ,tsex from teacher where boos_id >=1;这一句是最简单的查询了
下面我们用多行子查询来查
select tname ,tsex from teacher where boos_id >= all (select boos_id from teacher group by boos_id);
在这这句查询语句的意思就是:查询老师的名字和姓名,其boos_id 必须大于等于0和1 ,由于1>0,所以在这就是boos_id 必须>=1,下面的老师的boos_id都为1,所以满足条件
如果我们是查询boos_id <= 0和 1 的话,其实就是在说 boos_id必须小于等于0,
select tname ,tsex from teacher where boos_id <= all (select boos_id from teacher group by boos_id);
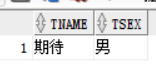
在多行子查询中,当子查询返回null 空值的时候。主查询不会报错。跟单行子查询一样,是无返回的值的
常见的数据库对象
- 表:基本的数据存储集合,由行和列组成
- 视图:从表中抽出的逻辑上相关的数据集合
- 序列:提供有规律的数值
- 索引:提高查询效率
- 同义词:给对象起别名,这里区别于在上面给表起的别名:employee as e ,同义词起好之后就可以一直使用
创建表 :
创建一张指定名字和列的空表
create table emp1(
id number(10),
name varchar2(20),
salary number(10,2),
hire_date date
)
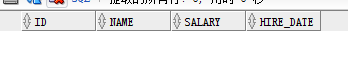
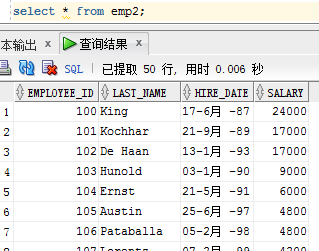
根据一个其他的表来创建一张新表,利用子查询来查询已存在表的列信息,以此创建新表,已经存在的表的信息一样会插入进新表
create table emp2 as select employee_id,last_name,hire_date,salary from employees;
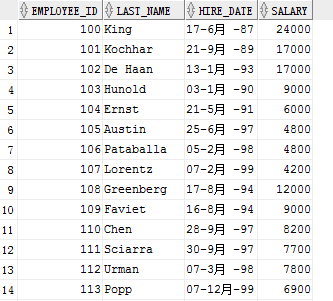
同样我们可以在已经存在表上的数据进行筛选后的,在进行插入新表
create table emp3 as select employee_id,last_name,hire_date,salary from employees where department_id = 100;
同样可以只选择旧表中的列信息,不选择插入数据
create table emp4 as select employee_id,last_name,hire_date,salary from employees where 1=2;
更改表:
上述创建的emp1 为一张空表,我们为这个表再增加一列 email
alter table emp1 add(email varchar2(20));,相比上面的表结构,这时候我们就增加了一列 类型为varchar2 的 email列
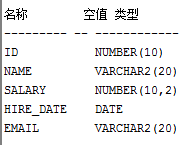
我们现在可以修改id 长度为 15,
alter table emp1 modify (id number(15));在这里同样可以更改他的类型,注意要修改数据类型,则要吧需改的列必须为空。增加长度是没问题的
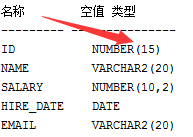
更改 工资列 salary 的默认值为1000,也就是在插入数据的时候,我们不给这一个列的值的话,他默认的就是1000
alter table emp1 modify (salary number(10,2) default 1000); 对默认值的修改只影响今后对表的修改
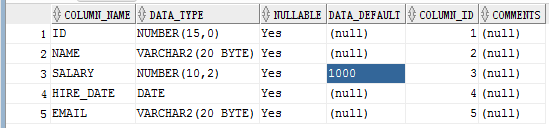
我们来删除一个列 email,
alter table emp1 drop column email; 相比较上面我们就可以看到 列 email 已经删除了

重命名一列 salary 为 gongzi
alter table emp1 rename column salary to gongzi; 在这说的是更改了名字,和创建修改表之类的修改是无法回滚的,只有增删改是可以回滚的 rollback

删除表
1. 数据和结构都被删除
2. 所有正在运行的相关事务被提交
3. 所有相关索引被删除
4. 不可以回滚
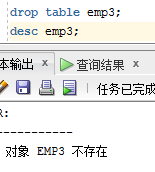
删除emp3 表,也可以用图形管理工具删除比较方便
drop table emp3;
清空表
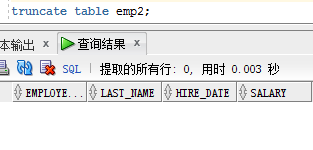
truncate table emp2,表结构在,但是数据是没有了。同样不可以回滚、慎用
改变表的名称 :rename emp4 to emp444; 这时候我们查询emp4是查不出来了。 只能查emp444;
设置列不可用 :alter table emp set unused column test_column; 在查询表结构的时候不在显示
删除一列 : alter table emp drop column test;
插入数据:insert into ----values --- 使用这种只能向表中插入一条数据
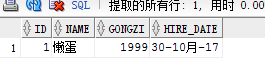
insert into emp1 values(
1,
'懒蛋',
1999,
sysdate
); 这的数据类型必须和表结构中的数据类型一致,这里的数据类型date 也可以自己用 todate函数自己转换
也可以指定插入的列数
insert into emp1(id,name,gongzi) values (2,'纯菜鸟','99999'); 也可以打乱插入的顺序,只要一一对应就行了。

上述的更改一个值的默认值,在这就能看出来了,当不给某一列值 的时候,不给值的那一列就会成认设置的默认值,但是一行为不能为空的时候,是必须给值的,图中是都可以为空的,如果为no就必须给值了
字符和日期类型都应该包含在单引号中

从其他表中拷贝数据,insert的另一种方式,下面插入数据中并没有上面的values关键字,下面的sql 的意思是从employees 中查出对应的列插入新表中
insert into emp1 (id,name,gongzi,hire_date) select employee_id,last_name,salary,hire_date from employees where department_id = 100;除了前面的是自己添加的后面的都是从employees表中获得的
 、
、
更新表:update -- set
途中有两个名字叫纯菜鸟的用户,而且id重复。我们把工资是1000的用户的id 改成3 , 那么改成 纯垃圾
update emp1 set id=3,name='纯垃圾' where id = 2 and gongzi = 1000;
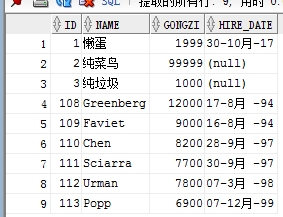
在这提醒,如果没有where条件,该表的所有数据都将变成 3,纯垃圾
commit提交与rollback回滚,简单的用一下,以后会在说的,在事务里
commit提交就相当于保存了,不能再更改了。rollback 就是相当于ctrl + z 撤回
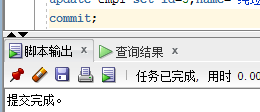
我们将所有信息都变成纯垃圾:update emp1 set id=3,name='纯垃圾' ;
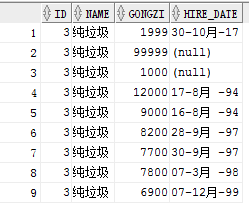
我们现在并没有提交,因为数据更改错误,我们先回滚一下
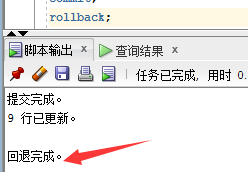
我们再来查的时候,所有数据已经恢复成了原来的数据
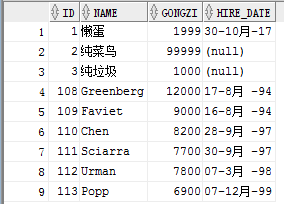
删除表 delete from -- where : 如果不加where条件,表中的所有数据将被删除
删除id 为3 的数据,,此操作可以回滚
delete from emp1 where id = 3;
数据库事务:一组逻辑操作单元,是数据从一种状态变换到另一种状态
以下面的其中之一作为结束
- commit 或者 rollback 语句
- ddl 语句 自动提交,比如删除创建表
- 用户会话正常结束
- 系统异常终止
comiit 和rollback 的优点
- 确保数据完整性
- 数据改变被提交之前预览
- 将逻辑上的相关的操作分组
表数据:
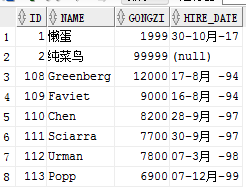
先把懒蛋用户删掉,只要不commit提交,是可以通过rollback 回来的。
delete from emp1 where id =1; 删除懒蛋用户,表中已经没有了懒蛋用户的信息
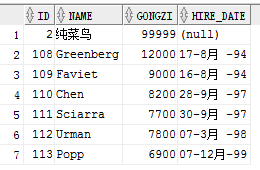
回滚,rollback;找回我们刚才删除的懒蛋用户

如下图
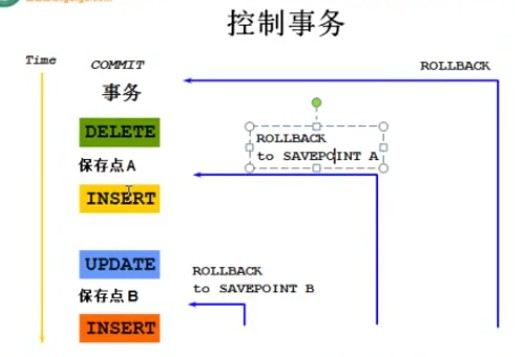
我们在进行一系列的增删改之后,其实只要执行一个rollback就会回到增删改之后的最原始状态,例如最大的最长的那个蓝色线,在其中我们可以设置一个另外的保存点A,当我们回滚的时候,我们的数据会回到保存点A 的状态,再次回滚就会回滚到上一次的commit后 的状态了
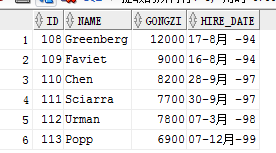
表数据上一个图,我们先把id 1 用户删掉,然后设置保存点,在删除 id 为2 的用户,然后rollback 查看效果
delete from emp1 where id = 1 ;
savepoint A; 设置保存点A
delete from emp1 where id = 2 ;
select * from emp1;
上面命令执行完之后,表数据为
下面我们进行回滚操作,第一次回滚到保存点A: rollback to savepoint A; 当然也可以直接rollback,直接回滚就会忽略中间设置的保存点直接回滚到上一次的提交之后的结果
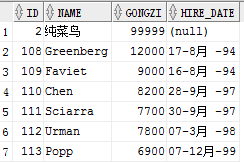
再次回滚就会回到commit在之后的结果,就是没有删除的时候的表数据
当数据库用户A更新数据了,只要A用户不提交数据,其他数据库用户是不可能看到未提交的数据的,更新的行也会被锁定,其他用户不能操作,知道A提交结束事务
约束,
1. not null 是否为空,只能定义在列上
2. unique 是否唯一,只可以插入一个数据,不可相同
3. primary key 是否为主键,创建为主键后,已经就是唯一了并且不能为空。
4. foreign key 是否为外键
5. check 检查的条件
注意: 如果不指定约束名,Oracle会自动的按照 SYS_Cn的格式指定约束名
我们可以在创建表的同时创建约束或者表创建以后在修改约束
列级约束:只能作用在一个列上,只能写在字段后面
表级约束:可以作用在多个列上,当然表级约束也可以作用在一个列上,在需要建立多列的约束时使用此约束,比如联合主键,不可以写在字段后面
定义方式:列约束必须跟在列的定义后面,表约束不与列一起,而是单独定义
下面的表中就存在约束,date_type 数据类型也是一种约束,约束数值的类型,还有后面nullable 是否可以为空等等一些约束 。

首先是在创建表的时候来创建约束
constraint:可以为创建的约束起名,
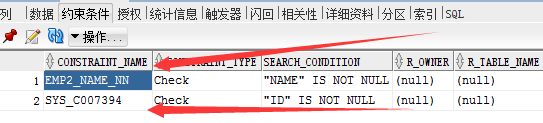
create table emp2(
id number(12) not null,
name varchar2(30) constraint emp2_name_nn not null,
salary number(30)
); 这此创建的表中,为id 创建了一个非空的约束,为name同样创建了非空的约束,并为name的约束起了个名字 :emp2_name_nn
 、
、
我们可以看到创建的表中的约束条件为刚才创建的约束:一个是自定义的约束名的约束,一个是系统给的一个约束名的约束
当我们向约束不能为空的字段插入 空值的时候,就会出现错误
insert into emp2 values (1,null,2000);

unique 约束:约束字段唯一,可以作为表级也可以作为列级
我们向刚才创建的表中的添加数据
insert into emp2 values (1,'j',2000);
现在的表数据中已经有了此条数据,但是由于没有唯一性约束,所以可以不断的进行插入信息,
运行三次的结果为

为了不让name相同的话 我们再创建一个具有唯一约束条件的表
create table emp3(
id number(12) not null,
name varchar2(30) constraint emp3_name_uk unique,
salary number(30)
);
创建的表结构为:

当我们继续插入同一条数据时就会出现错误

但是这里注意的是:当一列不为空约束的时候,插入多个null,是不会报错的!!!
下面是表级以及列级约束的创建方式
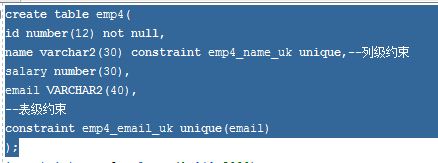
primary key,主键约束,就是区别与其它行的唯一标识,就比如身份证号,在为一列创建了主键约束后,这一列就成为了主键列,并且主键列不能为空而且唯一

这时候id 就会成为这一行数据的唯一标识,在此表中就不能重复此id了
插入null会报错,重复插入一个id也会报错,就不截图了
建立表以及外键约束
create table emp1 (
id number(12) primary key,
name varchar2(30) not null,
email varchar2(30)
);
create table emp2 (
id number(12) ,
name varchar2(30) not null,
email varchar2(30),
constraint emp1_id_fk foreign key (id) REFERENCES emp1(id)
);
constraint emp4_fk foreign key(id) references emp5(id),这一句是关键的创建外键的sql语句,constraint 外键名 foreign key(表中的那一列作为外键的列名) refrences 其他需要关联的表名(其他表中的主键)
这里注意的是 关联的表中的字段必须是该表的主键
A表中的emp_id 将 B表中的id作为外键,也就是 当B中有 id 值为1 的话。A表中才可以插入相关联的列的字段为 1 ,否则插入失败
emp1 创建后的表结构:
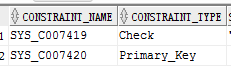
查看emp1中的数据:
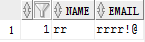
向emp2中插入数据
insert into emp2 values (1,'tt2','tt@'); 这时候就可以插入成功,因为id 列的值对应了上面emp1表中的id值,
insert into emp2 values (2,'tt2','tt@'); 失败,因为emp1 表数据id并没有为 2 的值
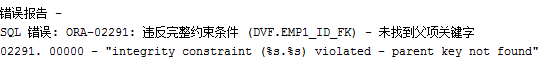
· 
上图可以看到 employees表中的 department_id 与 departments表中的 department_id做了外键的关联,当employees插入department_id 的时候 ,所对应的department表中的 department_id 必须有这个值 才可以插入
外键级联删除与级联置空
级联删除,:就是上表中的departments表中的一个department_id 删除。下面的employees表中的与这个删除的id所对应的 外键列中的一行也会跟着删除,如果employees表中多行的department_id都 是刚才departments表中删除的id值的话,多行一起删除(当浮标中的列被删除时,子表中相对应的列也会被删除)
是在创建表的时候 constraint emp1_id_fk foreign key (id) REFERENCES emp1(id) on delete cascade
级联置空:与级联删除类似,只是不删除employees表中的行了。是把相应的行中的外键列置空,设置为空,(子表中相应的列置空)
constraint emp1_id_fk foreign key (id) REFERENCES emp1(id) on delete set null
check约束,设置检查条件
create table emp3(
id number(10),
salary number(10) check(salary > 100) 设置必须大于100
);
当插入的小于100时:insert into emp3 values(1,1);,,

当插入的数据大于100 就能满足check检查条件,就可以成功
续篇也在我的Oracle分组里哦,给个赞吧!
Oracle-1 - :超级适合初学者的入门级笔记,CRUD,事务,约束 ......的更多相关文章
- Oracle-2 - :超级适合初学者的入门级笔记--定义更改约束,视图,序列,索引,同义词
接着我上一篇的写,在这感觉到哇 内容好多啊 上一篇,纯手打滴,希望给个赞! 添加约束的语法: 使用 alter table 添加或删除约束,但是不能修改约束 有效化或无效化约束 添加not nul ...
- Oracle-4 - :超级适合初学者的入门级笔记:plsql,基本语法,记录类型,循环,游标,异常处理,存储过程,存储函数,触发器
初学者可以从查询到现在的pl/sql的内容都可以在我这里的笔记中找到,希望能帮到大家,视频资源在 资源, 我自己的全套笔记在 笔记 在pl/sql中可以继续使用的sql关键字有:update del ...
- Oracle-3 - :超级适合初学者的入门级笔记--用户权限,set运算符,高级子查询
上一篇的内容在这里第二篇内容, 用户权限:创建用户,创建角色,使用grant 和 revoke 语句赋予和回收权限,创建数据库联接 创建用户:create user xxx identified b ...
- 推荐10个适合初学者的 HTML5 入门教程
HTML5 作为下一代网站开发技术,无论你是一个 Web 开发人员或者想探索新的平台的游戏开发者,都值得去研究.借助尖端功能,技术和 API,HTML5 允许你创建响应性.创新性.互动性以及令人惊叹的 ...
- [C#] Timer + Graphics To Get Simple Animation (简单的源码例子,适合初学者)
>_<" 这是一个非常简单的利用C#的窗口工程创立的程序,用来做一个简单的动画,涉及Timer和Graphics,适合初学者,高手略过~
- 5、WPF实现简单计算器-非常适合初学者练习
Sample Calculator 这是微软社区WPF的一个示例,在源程序的基础上我进行了一点点修改,非常适合初学者练习,详细代码解释. 源程序的下载地址 http://code.msdn.micro ...
- Oracle User Management FAQ翻译及学习笔记
转载 最近了解到AME 的东西,很迫切,先转载一篇 [@more@] Oracle User Management FAQ翻译及学习笔记 写在前面 本文主要是翻译的英文版的Oracle User Ma ...
- 强烈推荐visual c++ 2012入门经典适合初学者入门
强烈推荐visual c++ 2012入门经典适合初学者入门 此书循序渐进,用其独特.易于理解的教程风格来介绍各个主题,无论是编程新手,还是经验丰富的编程人员,都很容易理解. 此书的目录基本覆盖了Wi ...
- Linux内核开发进阶书籍推荐(不适合初学者)
Linux内核开发进阶书籍推荐(不适合初学者) 很早之前就想写一篇文章总结一下Linux Kernel开发的相关资料,项目的原因,再加上家里的一些事情,一直没能找到闲暇,今天终于有些时间,希望可以完成 ...
随机推荐
- Spark官方1 ---------Spark SQL和DataFrame指南(1.5.0)
概述 Spark SQL是用于结构化数据处理的Spark模块.它提供了一个称为DataFrames的编程抽象,也可以作为分布式SQL查询引擎. Spark SQL也可用于从现有的Hive安装中读取数据 ...
- 【ASP.NET MVC】jqGrid 增删改查详解
1 概述 本篇文章主要是关于JqGrid的,主要功能包括使用JqGrid增删查改,导入导出,废话不多说,直接进入正题. 2 Demo相关 2.1 Demo展示 第一部分 第二部分 2.2 ...
- OpenVPN client端配置文件详细说明(转)
本文将介绍如何配置OpenVPN客户端的配置文件.在Windows系统中,该配置文件一般叫做client.ovpn:在Linux/BSD系统中,该配置文件一般叫做client.conf.虽然配置文件名 ...
- 关于python中的pickle函数
8-7参考阅读 - 读文件.写文件.异常处理.文件保存游戏.pickle数据转成文本的过程又被称为"序列化",即将对象状态转换为可保持或传输的格式的过程.对应的,从序列化的格式中解 ...
- Python自学笔记-关于切片(来自廖雪峰的官网Python3)
感觉廖雪峰的官网http://www.liaoxuefeng.com/里面的教程不错,所以学习一下,把需要复习的摘抄一下. 以下内容主要为了自己复习用,详细内容请登录廖雪峰的官网查看. 切片 L[0: ...
- MVC 中获取Json数据
@{ ViewBag.Title = "json示例项目"; } @Scripts.Render("~/bundles/jquery") <h2>j ...
- c#中字节数组byte[]、图片image、流stream,字符串string、内存流MemoryStream、文件file,之间的转换
字节数组byte[]与图片image之间的转化 字节数组转换成图片 public static Image byte2img(byte[] buffer) { MemoryStream ms = ne ...
- Object类—复写equals方法,hashCode方法,toString方法
Object:所有类的根类. Object是不断抽取而来,具备着所有对象都具备的共性内容. class Person extends Object { private int age; Person( ...
- vs2012中使用localdb实例还原一个sql server 2008r2版本的数据库
use localdb sometime is easy than sql server ,and always use visual studio make you stupid. vs2012中还 ...
- Windows 10 快捷键汇总表格
Windows 10 快捷键汇总表格 Windows 10 快捷键汇总 Win键 + Tab 激活任务视图 Win键 + A 激活操作中心 Win键 + C 通过语音激活Cortana Win键 + ...