Pandas常用函数入门
一.Pandas
Python Data Analysis Library或Pandas是基于NumPy的一种工具,该工具是为了解决数据分析任务而创建的。Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
二.Series
Series是一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近,其区别是List中的元素可以是不同的数据类型,而Array和Series中则只允许存储相同的数据类型。
1.创建
# 通过list创建Series
s1 = pd.Series([7, 3, 6, 2, 9, 5, 8])
# 通过dict创建Series
s2 = pd.Series({"a":1, "b":2, "c":3})
# 通过list创建Series,并指定index
s3 = pd.Series([5, 2, 7, 4],["a", "b", "c", "b"])

2.选取
# 获取前3个数据
s1.head(3)
# 获取后3个数据
s1.tail(3)
# 获取index为2的数据
s1[2]
# 获取1<=index<4的数据
s1[1:4]
# 获取index>3的数据
s1[s1.index>3]
# 获取数据值>5的数据
s1[s1>5]
3.增加、删除、修改
# 增加数据index=8
s1[8] = -1
# 删除数据index=3,不修改原Series
s1 = s1.drop(3)
# 对1<=index<3的数据赋值30
s1[1:3] = 30
# 对index为4,6的数据赋值50
s1[4, 6] = 50
三.DataFrame
DataFrame是二维的表格型数据结构。可以将DataFrame理解为Series的容器。
1.创建
# 通过dict创建DataFrame
data = {'name':["google", "amazon", "apple", "youtube", "oracle"], 'age':[33, 44, 11, 66, 44], "money" : [400, 200, 100, 800, 500]}
df1 = pd.DataFrame(data, columns = ["name", "age", "money"])

2.时间序列类型index
# 月
dates = pd.date_range('2017-10-08', periods = 10, freq = "M")
# 天
dates = pd.date_range('2017-10-08', periods = 10, freq = "D")
# 时
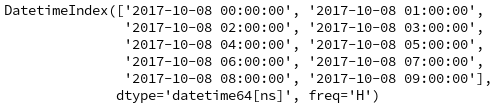
dates = pd.date_range('2017-10-08', periods = 10, freq = "H")
3.选取
# 获取前3行数据
df1.head(3)
# 获取后3行数据
df1.tail(3)
# 获取列
df1.name, df1['name'], df1[["name", "money"]]
# 获取行
df1[0:3], df1.loc[0:3]
# 同时获取行列
df1.loc[0:3, ["name", "money"]]
4.增加、删除、修改
# 增加列
df1["new"] = 6
# 删除列,不修改原DataFrame
df1 = df1.drop("new", axis = 1)
# 增加行,修改原DataFrame
df1.loc[df1.index.max() + 1] = {"name": "microsoft", "age": 70, "money": 300}
# 增加行,不修改原DataFrame
df1 = df1.append([{"name": "facebook", "age": 701, "money": 900}], ignore_index = True)
# 删除行,不修改原DataFrame
df1 = df1.drop([2])
# 修改数据
df1.loc[5,"age"] = 888
df1.loc[8:10, ["age", "money"]] = [11, 222]
5.WHERE
# 过滤数据,使用DataFrame.dtypes查看数据类型
df1[df1["age"] > 30]
df1[(df1["age"] > 30) & (df1["money"] < 600)], df1[(df1.age > 40) & (df1.money < 600)]
df1[df1["name"].isin(["amazon", "youtube"])]
6.DISTINCT
# 去重
df1.age.drop_duplicates()
df1[["age", "money"]].drop_duplicates()
7.JOIN
# 联接
df3 = pd.merge(df1, df2, how="left", left_on = "name", right_on = "name")
df3 = pd.merge(df1, df2, how="right", left_on = "name", right_on = "name")
8.GROUP BY
# 分组
df1.groupby("age")["money"].sum()
df1.groupby(["age", "name"])["money"].count()
9.ORDER BY
# 排序
df1.sort_values("age", ascending=True)
df1.sort_values(["age", "money"], ascending=[True, False])
10.UNION
# 合并
df2 = df1.copy(True)
df3 = pd.concat([df1,df2], ignore_index = True)
df3 = df1.append(df2, ignore_index = True)
11.导入和保存
Excel格式需要安装openpyxl、xlrd包
# 保存为csv格式
df1.to_csv("data.csv", encoding="utf-8")
# 从csv文件读取
df1 = pd.read_csv("data.csv")
# 保存为excel格式
df1.to_excel("data.xlsx", sheet_name = "Sheet1", encoding="utf-8")
# 从excel文件读取
df1 = pd.read_excel("data.xlsx", sheet_name = "Sheet1")
Pandas常用函数入门的更多相关文章
- pandas常用函数之shift
shift函数是对数据进行移动的操作,假如现在有一个DataFrame数据df,如下所示: index value1 A 0 B 1 C 2 D 3 那么如果执行以下代码: df.shift() 就会 ...
- pandas常用函数之diff
diff函数是用来将数据进行某种移动之后与原数据进行比较得出的差异数据,举个例子,现在有一个DataFrame类型的数据df,如下: index value1 A 0 B 1 C 2 D 3 如果执行 ...
- pandas 常用函数整理
pandas常用函数整理,作为个人笔记. 仅标记函数大概用途做索引用,具体使用方式请参照pandas官方技术文档. 约定 from pandas import Series, DataFrame im ...
- 【转载】pandas常用函数
原文链接:https://www.cnblogs.com/rexyan/p/7975707.html 一.import语句 import pandas as pd import numpy as np ...
- pandas常用函数
1. df.head(n): 显示数据前n行,不指定n,df.head则会显示所有的行 2. df.columns.values获取所有列索引的名称 3. df.column_name: 直接获取列c ...
- 整理 pandas 常用函数
1. df.head(n): 显示数据前n行,不指定n,df.head则会显示所有的行 2. df.columns.values获取所有列索引的名称 3. df.column_name: 直接获取列c ...
- 5.2 pandas 常用函数清单
文件读取 df = pd.read_csv(path='file.csv') 参数:header=None 用默认列名,0,1,2,3... names=['A', 'B', 'C'...] 自定义列 ...
- python,pandas常用函数
一.rename,更改df的列名和行索引 df=pd.DataFrame(np.arange(,).reshape(,)) print(df) print(type(df)) 结果为: <cla ...
- pandas 常用函数
随机推荐
- leetCode in Java (一)
前言 感觉写博客是一个很耗心力的东西T_T,简单的写了似乎没什么用,复杂的三言两语也只能讲个大概,呸呸...怎么能有这些消极思想呢QAQ!那想来想去,先开一个leetcode的坑,虽然已经工作了 ...
- 简单说明如何设置系统中的NLS_LANG环境变量
概述:本地化是系统或软件运行的语言和文化环境.设置NLS_LANG环境参数是规定Oracle数据库软件本地化行为最简单的方式.NLS_LANG参数不但指定了客户端应用程序和Oracle数据库所使用的语 ...
- 由 System.arraycopy 引发的巩固:对象引用 与 对象 的区别
作者:林冠宏 / 指尖下的幽灵 掘金:https://juejin.im/user/587f0dfe128fe100570ce2d8 博客:http://www.cnblogs.com/linguan ...
- this到底指向哪里
this指向调用它的对象 首先要明确,this指向调用方,谁调用,this指向谁. 直接调用 举个栗子: var test = 'window' ; function testThis () { va ...
- Jquery.Uploadify实现批量上传显示进度条 取消 上传后缩略图显示 可删除
<%@ Page Language="C#" AutoEventWireup="true" CodeFile="UpLoad.aspx.cs&q ...
- 将 C# 枚举反序列化为 JSON 字符串 实践
一.定义枚举 public enum SiteTypeEnum { 中转部 = 1, 网点 = 2 } 还有 BooleanEnum 和 OptTypeEnum 这两个枚举,这里暂且省略了它们的定义. ...
- 当谈到 GitLab CI 的时候,我们该聊些什么(上篇)
"微服务"这个概念近两年非常热,正在慢慢改变 DevOps 的思路.微服务架构把一个庞大的业务系统拆解开来,每一个组件变得更加独立自治.松耦合.但是,同时也伴随着部署单元粒度越来越 ...
- IDoc 基础知识
Application Link Enabling ALE主要为了分布式业务系统而设计的.它可以使业务流程中的每个步骤分布在不同的SAP系统上,系统间可以通过IDoc交互数据.IDoc可以认为是个信封 ...
- vb6.0的各种SHELL,CMD内部命令、外部命令、SHELL任意文件
Private Declare Function ShellExecute Lib "shell32.dll" Alias "ShellExecuteA" (B ...
- XamlReader动态使用xaml
xamlload先在xaml做出一个grid,命名xgrid <Page x:Class="xamlload.MainPage" xmlns="http://sch ...