互联网级监控系统必备-时序数据库之Influxdb集群及踩过的坑
上篇博文中,我们介绍了做互联网级监控系统的必备-Influxdb的关键特性、数据读写、应用场景:
本文中,我们介绍Influxdb数据库集群的搭建,同时分享一下我们使用集群遇到的坑!
一、环境准备
- 同一网段内,3个CentOS 节点,相互可以ping通
- 3个节点CentOS配置Hosts文件,相互可以解析主机名
- Azure 虚拟机启用root用户
- influxdb-0.10.3-1.x86_64.rpm
- 设置端口8083 8086 8088 8091例外
二、一步一步搭建Influxdb集群
1. 在各个节点的主机上配置Hosts文件,这样可以保证每个节点直接的互相通讯

2. 各个节点主机安装InfluxDB rpm,只是安装不启动Influxdb

3. 三个节点主机上依次 编辑Influxdb.conf文件(.etc/influxdb/influxdb.conf)
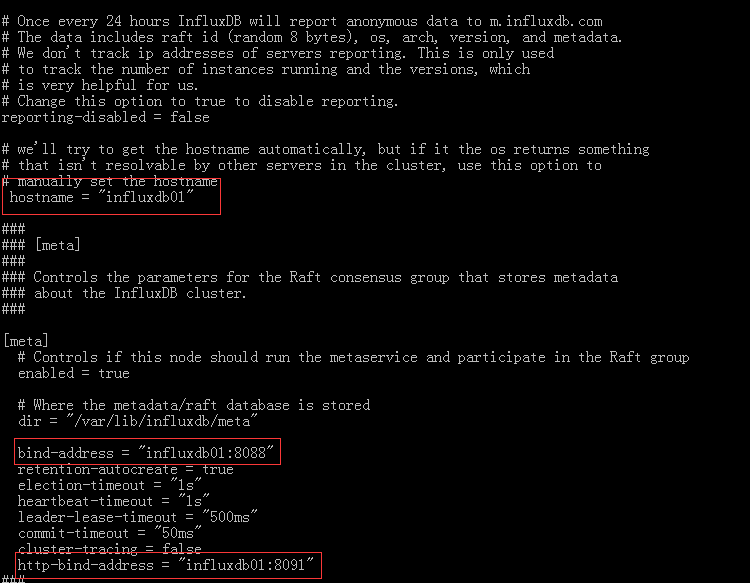
主要修改HostName、bind-address、http-bind-address三个选项
依次修改三个主机节点的配置文件
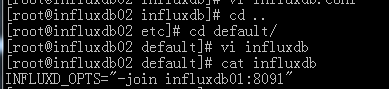
4. InfluxDB01机器上启动Influxdb



互联网级监控系统必备-时序数据库之Influxdb集群及踩过的坑的更多相关文章
- 互联网级监控系统必备-时序数据库之Influxdb
时间序列数据库,简称时序数据库,Time Series Database,一个全新的领域,最大的特点就是每个条数据都带有Time列. 时序数据库到底能用到什么业务场景,答案是:监控系统. Baidu一 ...
- 互联网级监控系统必备-时序数据库之Influxdb技术
时间序列数据库,简称时序数据库,Time Series Database,一个全新的领域,最大的特点就是每个条数据都带有Time列. 时序数据库到底能用到什么业务场景,答案是:监控系统. Baidu一 ...
- 亿级Web系统搭建:单机到分布式集群
亿级Web系统搭建:单机到分布式集群 当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压 ...
- [转]亿级Web系统搭建:单机到分布式集群
当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压力带来问题,我们需要在Web系统架构层 ...
- 亿级Web系统搭建:单机到分布式集群【转】
当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压力带来问题,我们需要在Web系统架构层 ...
- 亿级 Web 系统搭建:单机到分布式集群
本文内容 Web 负载均衡 HTTP 重定向 反向代理 IP 负载均衡 DNS 负载均衡 Web 系统缓存机制的建立和优化 MySQL 数据库内部缓存 搭建多台 MySQL 数据库 MySQL 数据库 ...
- 互联网企业级监控系统 OpenFalcon
Open-Falcon 人性化的互联网企业级监控系统,Open-Falcon 整体可以分为两部分,即绘图组件.告警组件.其中: 安装绘图组件 负责数据的采集.收集.存储.归档.采样.查询.展示(Das ...
- 认识Influxdb时序数据库及Influxdb基础命令操作
认识Influxdb时序数据库及Influxdb基础命令操作 一.什么是Influxdb,什么又是时序数据库 Influxdb是一个用于存储时间序列,事件和指标的开源数据库,由Go语言编写而成,无需外 ...
- Linux系统下安装Redis和Redis集群配置
Linux系统下安装Redis和Redis集群配置 一. 下载.安装.配置环境: 1.1.>官网下载地址: https://redis.io/download (本人下载的是3.2.8版本:re ...
随机推荐
- 开涛spring3(6.9) - AOP 之 6.9 代理机制
Spring AOP通过代理模式实现,目前支持两种代理:JDK动态代理.CGLIB代理来创建AOP代理,Spring建议优先使用JDK动态代理. JDK动态代理:使用java.lang.reflect ...
- SVN如何迁移到Git?
最近在使用华为软件开发云进行开发项目管理,目前华为软件开发云支持500M的免费项目空间,而且还可以在线编译和构建,不用担心开发环境和生产环境的不同,很好的体现了DevOps的开发理念. 之前一直是用s ...
- PHP开发微信模版消息换行的问题
微信是个坑!微信是个坑!微信是个坑!重要的时间说三遍 关键的地方是空白换行符到底是什么也不说,百度说是"\n":但是在发送消息的时候发现原样输出,发现json_encode对\n进 ...
- Flume简介及安装
Hadoop业务的大致开发流程以及Flume在业务中的地位: 从Hadoop的业务开发流程图中可以看出,在大数据的业务处理过程中,对于数据的采集是十分重要的一步,也是不可避免的一步,从而引出我们本文的 ...
- haproxy-代码阅读-内存管理
haproxy内存池概述 内存池按照类型分类,每个类型的内存池都有一个名字,用链表记录空闲的内存块,每个内存块大小相等,并按照16字节对齐. haporxy用pool_head 结构记录内存池 str ...
- xtrabackup原理、备份日志分析、备份信息获取
一. xtrabackup备份恢复工作原理: extrabackup备份简要步骤 InnoDB引擎很大程度上与Oracle类似,使用redo,undo机制,XtraBackup在备份的时候,以read ...
- <bits/stdc++.h>头文件介绍(包含源代码)
注:转自http://blog.csdn.net/charles_dong2/article/details/56909347,同为本人写的,有部分修改. 之前在一个小OJ上刷题时发现有人是这么写的: ...
- 使用Eclipse进行Javaweb项目开发时,如何设置外置浏览器Chrome
使用Eclipse开发Javaweb项目时,在Eclipse中显示页面不是很好,那么如何让它自动打开外置浏览器呢?操作如下
- Python中Swithch Case语法实现
而python本身没有switch语句,解决方法有以下3种:A.使用dictionaryvalues = { value1: do_some_stuff1, value2: do_some_stuff ...
- 『珍藏】eclipse快捷键
提示所有快捷键的快捷键是 ctrl+shift+L 菜单是在: window-->preferences-->general-->keys 提供能容帮助是 alt+/ Ctrl+1 ...