基于Flink秒级计算时CPU监控图表数据中断问题
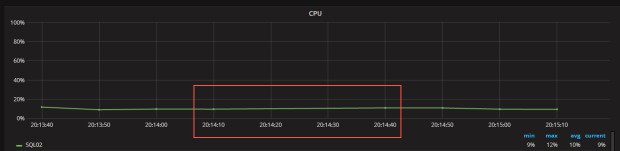
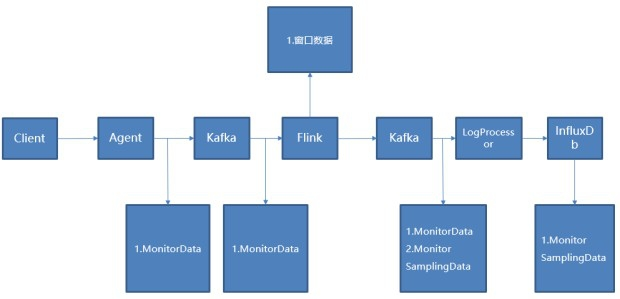
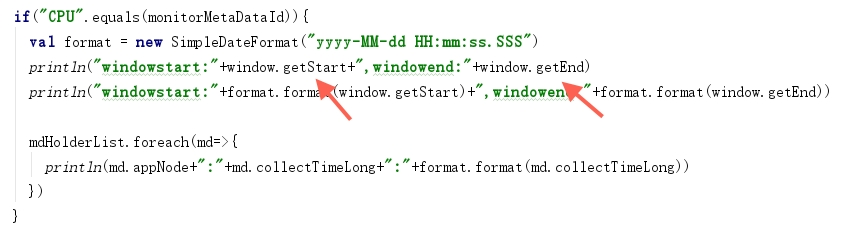
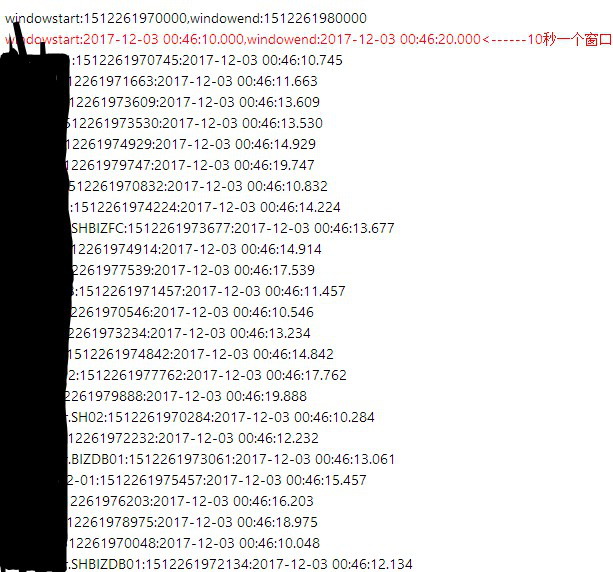
基于Flink秒级计算时CPU监控图表数据中断问题的更多相关文章
- 《阿里如何实现秒级百万TPS?搜索离线大数据平台大数据平台架构解读》读后感
在使用淘宝时发现搜索框很神奇,它可以将将我们想要的商品全部查询出来,但是我们并感觉不到数据库查询的过程,速度很快.通过阅读这篇文章让我知道了搜索框背后包含着很多技术,对我以后的学习可能很有借鉴. 平时 ...
- [开源]CSharpFlink(NET 5.0开发)分布式实时计算框架,PC机10万数据点秒级计算测试说明
github地址:https://github.com/wxzz/CSharpFlinkgitee地址:https://gitee.com/wxzz/CSharpFlink 1 计算 ...
- 基于supervisor秒级Laravel定时任务
背景介绍 公司需要实现X分钟内每隔Y秒轮训某个接口,Linux自带的crontab貌似只精确到分钟,虽然可以到精确到秒,但是并不满足需求. 选型 公司项目都是 基于 Laravel 框架,所以这个没得 ...
- js 小数计算时出现多余的数据
根据资料显示:是由于十进制换算成二进制,处理后,再由二进制换算成十进制时,造成的误差. 得出:所以(0.1+0.2)!=0.3 而是=0.30000000000000004的结果 解决方法: 参考:h ...
- 腾讯新闻基于 Flink PipeLine 模式的实践
摘要 :随着社会消费模式以及经济形态的发展变化,将催生新的商业模式.腾讯新闻作为一款集游戏.教育.电商等一体的新闻资讯平台.服务亿万用户,业务应用多.数据量大.加之业务增长.场景更加复杂,业务对实时 ...
- 基于 Flink 的实时数仓生产实践
数据仓库的建设是“数据智能”必不可少的一环,也是大规模数据应用中必然面临的挑战.在智能商业中,数据的结果代表了用户反馈.获取数据的及时性尤为重要.快速获取数据反馈能够帮助公司更快地做出决策,更好地进行 ...
- 基于Kafka的实时计算引擎如何选择?Flink or Spark?
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
- 基于 HTML5 WebGL 的 CPU 监控系统
前言 科技改变生活,科技的发展带来了生活方式的巨大改变.随着通信技术的不断演进,5G 技术应运而生,随时随地万物互联的时代已经来临.5G 技术不仅带来了更快的连接速度和前所未有的用户体验,也为制造业, ...
- (二)基于商品属性的相似商品推荐算法——Flink SQL实时计算实现商品的隐式评分
系列随笔: (总览)基于商品属性的相似商品推荐算法 (一)基于商品属性的相似商品推荐算法--整体框架及处理流程 (二)基于商品属性的相似商品推荐算法--Flink SQL实时计算实现商品的隐式评分 ( ...
随机推荐
- CSS组件
下拉菜单 .dropdown:将下拉菜单触发器和下拉菜单包含在其中 .dropdown-menu:给<ul>制定下拉菜单的样式 .dropup:向上弹出菜单 .dropdown-menu- ...
- js的事件循环绑定和jQuery的隐式迭代
js的事件循环绑定和jQuery的隐式迭代 js事件循环绑定 jQuery隐式迭代 先举一个例子:给定一个ul,点击列表内的每一个li元素,使它的背景色变红,下边分别用js代码和jQuery实现. & ...
- Spring源码情操陶冶-AOP之Advice通知类解析与使用
阅读本文请先稍微浏览下上篇文章Spring源码情操陶冶-AOP之ConfigBeanDefinitionParser解析器,本文则对aop模式的通知类作简单的分析 入口 根据前文讲解,我们知道通知类的 ...
- Azure环境中Nginx高可用性和部署架构设计
前几篇文章介绍了Nginx的应用.动态路由.配置.在实际生产环境部署时,我们需要同时考虑Nginx的高可用性和部署架构. Nginx自身不支持集群以保证自身的高可用性,商业版本的Nginx+推荐: T ...
- nvm进行node多版本管理
写在前面 nvm(nodejs version manager)是nodejs的管理工具,如果你需要快速更新node版本,并且不覆盖之前的版本:或者想要在不同的node版本之间进行切换: 使用nvm来 ...
- asp.net上传文件限制解决方案
环境:VS2012,IIS7 利用web uploader实现了一个文件上传的功能,但是遇到上传大小的限制,在web.config的<system.web>节点下添加如下代码: <h ...
- svn 常用命令行
1.将文件checkout到本地目录 svn checkout path(path是服务器上的目录) 例如:svn checkout svn://192.168.1.1/pro/domai ...
- 搭建yeoman自动化构建工具
yeoman可以快速的搭建一个项目的手脚架,初次接触yeoman,在搭建的过程中遇到了很多的问题. yeoman需要node.js(http://nodejs.org)和git(http://git- ...
- HDU 2665 Kth number(划分树)
Kth number Time Limit: 15000/5000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total S ...
- Long Long Message(后缀数组)
Long Long Message Time Limit: 4000MS Memory Limit: 131072K Total Submissions: 30427 Accepted: 12 ...