redis 梳理笔记(二)
一.redis 分布式
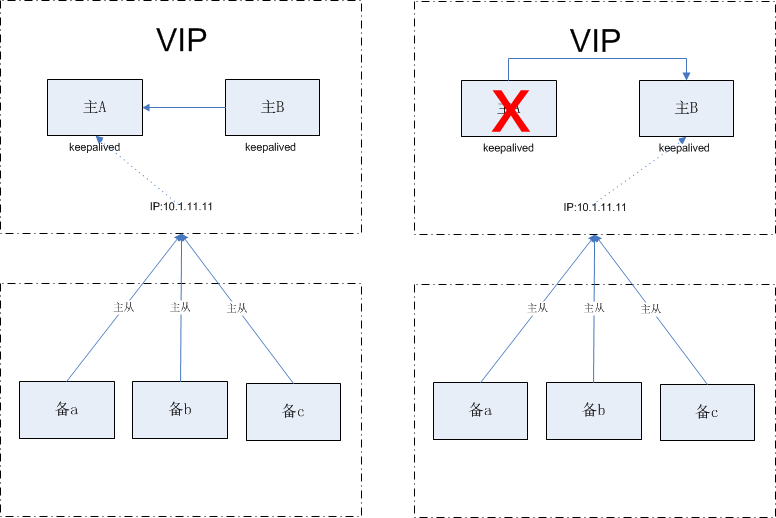
redis+keepalived (虚ip漂移)
- redis 100秒平均写入并发 3.6w (写入与keepalived监控程序无关)
- .redis 数据库内存已占有80% 100秒平均写入并发 2.6w
- 6g的redis 数据库 执行一次bgsave需要 32s 内存消耗 3g 期望内存至少预留4g
- .6g的redis 数据库 执行一次bgrewriteaof 需要 13-20秒, 1g 用完 期望预留4g
- .测试主备切换时间花费及服务可用性,数据量为6g(A 为主库, B为备库,C为从库)
A库 手动kill (13:32)keepalived 切换 服务到B库(13:35)B库备份数据库到 *.rdb, cpu 飙升 ,开始执行主从同步(13:36)B库rdb 执行完成花费37秒 开始传输*.rdb到c 库 (14:13)C库接受完毕*.rdb传输,传输花费34秒 (14:47秒)C库执行load *.rdb到内存中 (花费47秒)次秒从库数据库不可用 (15:34)主库挂掉 到完全服务可用 花费122秒
- 带宽:最大峰值 805Mb/s,约100MB/s (6g)
总结:在此过程:写3秒不可用;读 47秒不可用;切换到完全可用近2分钟
sentinel
twemproxy(vips之前架构)
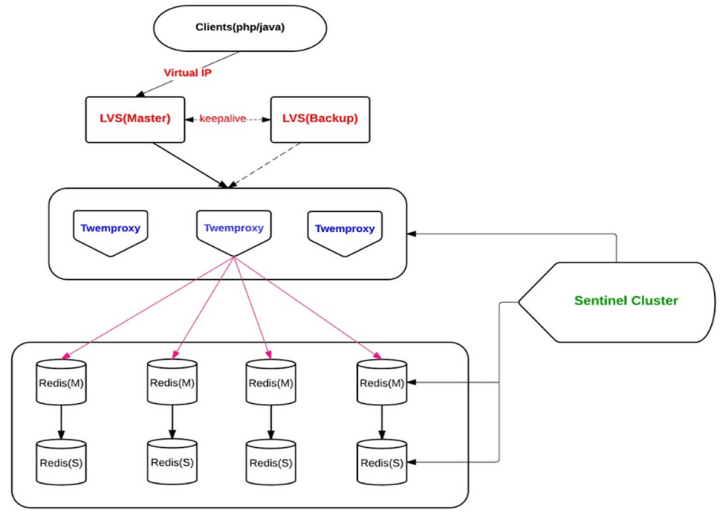
- 优点
- sharding逻辑对开发透明,读写方式跟单个redis一致
- 可以作为cache和storage的proxy
- 缺点
- 架构复杂,层次多 包含lvs、twemproxy、redis、sentinel
- 管理成本跟硬件成本很高
- 流量高的系统、proxy节点数和redis个数接近
- redis层仍然扩容能力差,预分配足够的redis存储节点
crc32 katema 网卡流量
二、redis 几种数据结构
hash
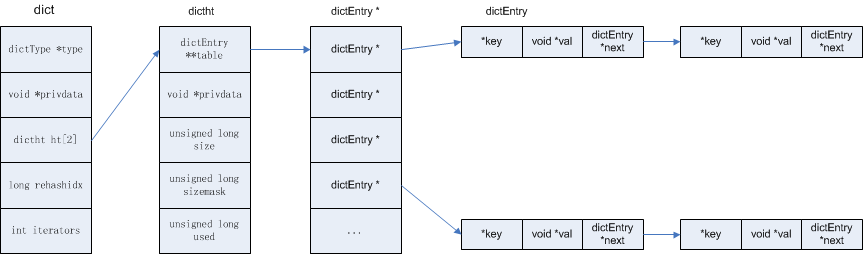
//单向链表结构
typedef struct dictEntry {
void *key;//key值指针
union {//
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;//单向链表下个元素指针
} dictEntry;
//hash表类型
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);//哈希计算方法,返回整形变量 time33
//hash*33+hash+ord(1)
void *(*keyDup)(void *privdata, const void *key);//对key进行拷贝
void *(*valDup)(void *privdata, const void *obj);//对value进行拷贝
int (*keyCompare)(void *privdata, const void *key1, const void *key2);//key比较器
void (*keyDestructor)(void *privdata, void *key);//销毁key,析构函数
void (*valDestructor)(void *privdata, void *obj);//销毁value,析构函数
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
//hash表结构
typedef struct dictht {
dictEntry **table; //hash 表中如果出现hash 碰撞 就用单向连表保存数据结构
unsigned long size;//桶个数
unsigned long sizemask;//size-1,方便定位
unsigned long used;//实际保存的元素数
} dictht;
//hash表主表
typedef struct dict {
dictType *type;//hash表类型
void *privdata;
dictht ht[];//新旧两张hash 表
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
//迭代器
typedef struct dictIterator {
dict *d; //当前hash 字典
long index;//当前索引
int table, safe;//
dictEntry *entry, *nextEntry;//循环结构体 以及下一个dictEntry * 结构体
/* unsafe iterator fingerprint for misuse detection. */
long long fingerprint;
} dictIterator;
#当发生hash碰撞时,dict_can_resize会变成真 当bgsave(快照)&© on write(aof)也会强制变成真 rehash
# use "activerehashing yes" if you don't have such hard requirements but
# want to free memory asap when possible.
# 每100毫秒,redis将用1毫秒的时间对Hash表进行重新Hash。
# 采用懒惰Hash方式:操作Hash越多,则重新Hash的可能越多,若根本就不操作Hash,则不会重新Hash
# 默认每秒10次重新hash主字典,释放可能释放的内存
# 重新hash会造成延迟,如果对延迟要求较高,则设为no,禁止重新hash。但可能会浪费很多内存
activerehashing yes
list
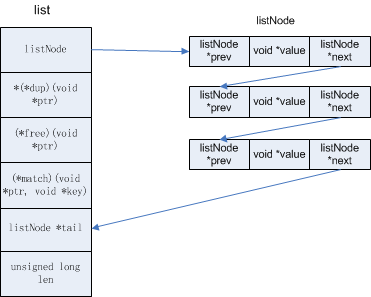
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct listIter {
listNode *next;
int direction;
} listIter;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
三、一些建议
- Master最好不要做任何持久化工作(AOF日志文件),特别是不要启用内存快照做持久化。(一旦主库挂了或者不可用,没啥毛用)
- 如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
- 为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内。
- 尽量避免在压力较大的主库上增加从库
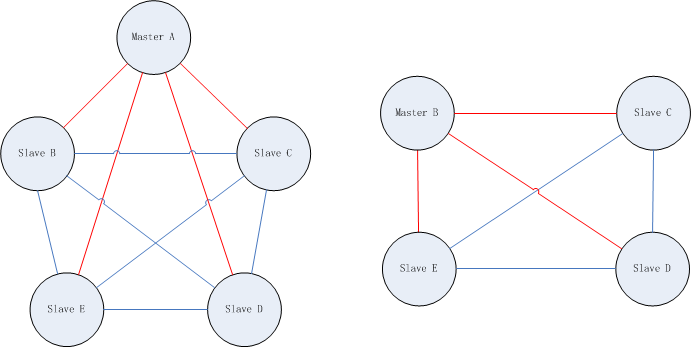
- 为了Master的稳定性,主从复制不要用图状结构,用单向链表结构更稳定,即主从关系为:Master<--Slave1<-- Slave2<--Slave3.......,这样的结构也方便解决单点故障问题,实现Slave对Master的替换,也即,如果Master 挂了,可以立马启用Slave1做Master,其他不变(现在看来也是然并卵)。
如果问题,欢迎指教
redis 梳理笔记(二)的更多相关文章
- Redis学习笔记二 (BitMap算法分析与BitCount语法)
Redis学习笔记二 一.BitMap是什么 就是通过一个bit位来表示某个元素对应的值或者状态,其中的key就是对应元素本身.我们知道8个bit可以组成一个Byte,所以bitmap本身会极大的节省 ...
- redis相关笔记(二.集群配置及使用)
redis笔记一 redis笔记二 redis笔记三 1.配置:在原redis-sentinel文件夹中添加{8337,8338,8339,8340}文件夹,且复制原8333中的配置 在上述8333配 ...
- redis 学习笔记二 (简单动态字符串)
redis的基本数据结构是动态数组 一.c语言动态数组 先看下一般的动态数组结构 struct MyData { int nLen; char data[0]; }; 这是个广泛使用的常见技巧,常用来 ...
- redis 梳理笔记(一)
一 redis 数据格式 短连接 长连接pconnect tcp协议 交互数据格式 交互采用特殊的格式 \r\n 1."+"号开头表示单行字符串的回复 set aa aa ...
- StackExchange.Redis学习笔记(二) Redis查询 五种数据类型的应用
ConnectionMultiplexer ConnectionMultiplexer 是StackExchange.Redis的核心对象,用这个类的实例来进行Redis的一系列操作,对于一个整个应用 ...
- redis 学习笔记二
redis启动: 直接 redis-server.exe 启动服务,是按照redis默认配置启动的,如果想按照自己的配置文件启动,要加上 redis-server.exe redis.windows ...
- Redis学习笔记二
学习Redis添加Object时,由于Redis只能存取字符串String,对于其它数据类型形容:Int,long,double,Date等不提供支持,因而需要设计到对象的序列化和反序列化.java序 ...
- Redis学习笔记二:单机数据库的实现
1. 数据库 服务器中的数据库 Redis服务器将所有数据库都保存在服务器状态redis.h/redisServer结构的db数组中,db数组的每个项都是一个redis.h/redisDb结构,每个r ...
- Redis入门笔记(二)-配置及运行
转自: http://gly199.iteye.com/blog/1056424 1.redis基本参数 redis的配置文件中的常见参数如下: daemonize 是否以后台进程运行,默认为no ...
随机推荐
- python的re正则表达
正则表达式,又称正规表示式.正规表示法.正规表达式.规则表达式.常规表示法(英语:Regular Expression,在代码中常简写为regex.regexp或RE),是计算机科学的一个概念.正则表 ...
- DNS over TLS到底有多牛?你想知道的都在这儿
DNS over TLS,让电信.移动等各种ISP无法监视你的浏览轨迹...... SSL证书有助于客户端浏览器和网站服务器之间的加密连接. 这意味着在连接期间,所有的通信和活动都被遮蔽. 但通常意义 ...
- JAVA基础知识总结:七
一.面向对象编程 1.什么是面向对象? 万物皆对象 案例一:我想吃大盘鸡 面向过程 面向对象 1.我自己去买一只鸡 1.委托一个会砍价的人去帮忙买鸡 2.我自己宰鸡 2.委托一个胆大的人宰鸡 3.我自 ...
- Linux下MySQL5.7.19
第一次在自己虚机上安装mysql 中间碰到很多问题 在这里记下来,分享一下. linux centOS 6 mysql版本 mysql-5.7.19-linux-glibc2.12-x86_64.ta ...
- abapGit分支策略
各位ABAP公民们.特别是使用abapGit的各位,你们好. 我的团队和我将向大家分享我公司内引入abapGit后产生的某些开发问题.我所在的公司是一家创作SAP第三方软件的公司,目前主要使用ABAP ...
- gulp-prompt入个了门
gulp-prompt版本:0.4.1 源码:gulp-prompt 一.gulp-prompt的简介 gulp-prompt 是一个基于gulp的命令行提示. 我们可以用它来完成命令行中互动功能. ...
- javascript 之变量对象-09
变量对象 变量对象:每个执行环境(执行上下文)都有一个对应的变量对象(variable object),环境中(执行上下文中)定义的所有变量.函数都保存在这个对象中. 在上篇中说到,当执行流执行一个函 ...
- 玩转 HTML5 下 WebGL 的 3D 模型交并补
建设性的立体几何具有许多实际用途,它用于需要简单几何对象的情况下,或者数学精度很重要的地方,几乎所有的工程 CAD 软件包都使用 CSG(可以用于表示刀具切削,以及零件必须配合在一起的特征).CSG ...
- HTML表单设计(上)
1,表单标记<form>...</form> <form>...</form>定义表单的开始位置和结束位置,表单提交时的内容就是<form> ...
- python模块导入的方法与区别
import .. #导入整个模块 from .. import .. #导入模块中的类.函数或者变量 from .. import * #导入模块中的所有公开成员 from .. import ...