Hadoop2.0 HA集群搭建步骤
上一次搭建的Hadoop是一个伪分布式的,这次我们做一个用于个人的Hadoop集群(希望对大家搭建集群有所帮助):
集群节点分配:
Park01
Zookeeper
NameNode (active)
Resourcemanager (active)
Park02
Zookeeper
NameNode (standby)
Park03
Zookeeper
ResourceManager (standby)
Park04
DataNode
NodeManager
JournalNode
Park05
DataNode
NodeManager
JournalNode
Park06
DataNode
NodeManager
JournalNode
安装步骤:
0.永久关闭每台机器的防火墙
执行:service iptables stop
再次执行:chkconfig iptables off
1.为每台机器配置主机名以及hosts文件
配置主机名=》执行: vim /etc/sysconfig/network =》然后执行 hostname 主机名=》达到不重启生效目的
配置hosts文件=》执行:vim /etc/hosts
示例:
127.0.0.1 localhost
::1 localhost
192.168.234.21 hadoop01
192.168.234.22 hadoop02
192.168.234.23 hadoop03
192.168.234.24 hadoop04
192.168.234.25 hadoop05
192.168.234.26 hadoop06
2.通过远程命令将配置好的hosts文件 scp到其他5台节点上
执行:scp /etc/hosts hadoop02: /etc
3.为每天机器配置ssh免秘钥登录
执行:ssh-keygen ssh-copy-id root@hadoop01 (分别发送到6台节点上)
4.前三台机器安装和配置zookeeper配置conf目录下的zoo.cfg以及创建myid文件(zookeeper集群安装具体略)
5.为每台机器安装jdk和配置jdk环境
6.为每台机器配置主机名,然后每台机器重启,(如果不重启,也可以配合:hostname hadoop01生效)
执行: vim /etc/sysconfig/network 进行编辑

7.安装和配置01节点的hadoop
配置hadoop-env.sh
配置jdk安装所在目录配置hadoop配置文件所在目录
8.配置core-site.xml
<configuration>
<!--用来指定hdfs的老大,ns为固定属性名,表示两个namenode-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!--用来指定hadoop运行时产生文件的存放目录--> <property>
<name>hadoop.tmp.dir</name> <value>/home/software/hadoop-2.7.1/tmp</value> </property>
<!--执行zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
</configuration>
9.配置01节点的hdfs-site.xml
配置:
<configuration>
<!--执行hdfs的nameservice为ns,和core-site.xml保持一致-->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property> <!--ns下有两个namenode,分别是nn1,nn2-->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!--nn1的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop01:9000</value>
</property>
<!--nn1的http通信地址-->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop01:50070</value>
</property>
<!--nn2的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>hadoop02:9000</value>
</property>
<!--nn2的http通信地址-->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>hadoop02:50070</value>
</property>
<!--指定namenode的元数据在JournalNode上的存放位置,这样,namenode2可以从jn集群里获取最新的namenode的信息,达到热备的效果-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop04:8485;hadoop05:8485;hadoop06:8485/ns</value>
</property>
<!--指定JournalNode存放数据的位置-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/software/hadoop-2.7.1/journal</value>
</property>
<!--开启namenode故障时自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--配置切换的实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--配置隔离机制-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--配置隔离机制的ssh登录秘钥所在的位置-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--配置namenode数据存放的位置,可以不配置,如果不配置,默认用的是core-site.xml里配置的hadoop.tmp.dir的路径-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/software/hadoop-2.7.1/tmp/namenode</value>
</property>
<!--配置datanode数据存放的位置,可以不配置,如果不配置,默认用的是core-site.xml里配置的hadoop.tmp.dir的路径-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/software/hadoop-2.7.1/tmp/datanode</value>
</property>
<!--配置block副本数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--设置hdfs的操作权限,false表示任何用户都可以在hdfs上操作文件-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
10.配置mapred-site.xml
<configuration>
<property>
<!--指定mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
11.配置yarn-site.xml
配置代码:
<configuration>
<!-- 开启YARN HA -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定两个resourcemanager的名称 -->
<property> <name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 配置rm1,rm2的主机 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop03</value>
</property>
<!--开启yarn恢复机制-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--执行rm恢复机制实现类-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 配置zookeeper的地址 -->
<property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
<description>For multiple zk services, separate them with comma</description> </property>
<!-- 指定YARN HA的名称 --> <property>
<name>yarn.resourcemanager.cluster-id</name> <value>yarn-ha</value>
</property>
<property>
<!--指定yarn的老大 resoucemanager的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop03</value>
</property>
<property>
<!--NodeManager获取数据的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
12.配置slaves文件
配置代码:
hadoop04
hadoop05
hadoop06
13.配置hadoop的环境变量(可不配)
JAVA_HOME=/home/software/jdk1.8
HADOOP_HOME=/home/software/hadoop-2.7.1
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export JAVA_HOME PATH CLASSPATH HADOOP_HOME
14.根据配置文件,创建相关的文件夹,用来存放对应数据
在hadoop-2.7.1目录下创建:
①journal目录
②创建tmp目录
③在tmp目录下,分别创建namenode目录和datanode目录
15.通过scp 命令,将hadoop安装目录远程copy到其他5台机器上
比如向hadoop02节点传输:
scp -r hadoop-2.7.1 hadoop02:/home/software
Hadoop集群启动
16.启动zookeeper集群
在Zookeeper安装目录的bin目录下执行:sh zkServer.sh start
17.格式化zookeeper
在zk的leader节点上执行:
hdfs zkfc -formatZK,这个指令的作用是在zookeeper集群上生成ha节点(ns节点)

注:18--24步可以用一步来替代:进入hadoop安装目录的sbin目录,执行:start-dfs.sh 。但建议还是按部就班来执行,比较可靠。
18.启动journalnode集群
在04、05、06节点上执行:
切换到hadoop安装目录的bin目录下,执行:
sh hadoop-daemons.sh start journalnode
然后执行jps命令查看:
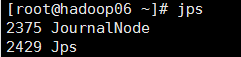
19.格式化01节点的namenode
在01节点上执行:
hadoop namenode -format
20.启动01节点的namenode
在01节点上执行:
hadoop-daemon.sh start namenode
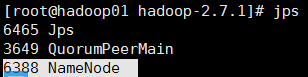
21.把02节点的namenode节点变为standby namenode节点
在02节点上执行:
hdfs namenode-bootstrapStandby

22.启动02节点的namenode节点
在02节点上执行:
hadoop-daemon.sh start namenode
23.在04,05,06节点上启动datanode节点
在04,05,06节点上执行:hadoop-daemon.sh start datanode
24.启动zkfc(启动FalioverControllerActive)
在01,02节点上执行:
hadoop-daemon.sh start zkfc

25.在01节点上启动主Resourcemanager
在01节点上执行:start-yarn.sh

启动成功后,04,05,06节点上应该有nodemanager 的进程
26.在03节点上启动副Resoucemanager
在03节点上执行:yarn-daemon.sh start resourcemanager
27.测试
输入地址:http://192.168.234.21:50070,查看namenode的信息,是active状态的
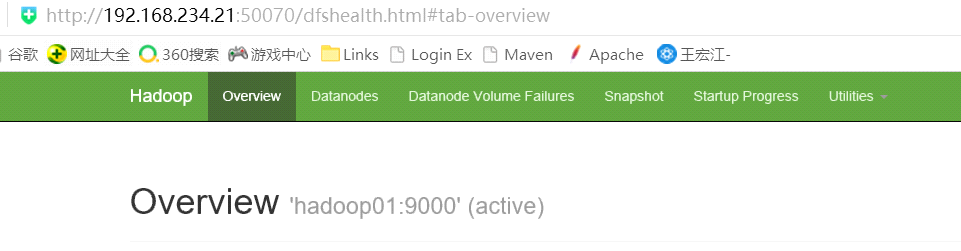
输入地址:http://192.168.234.22:50070,查看namenode的信息,是standby状态
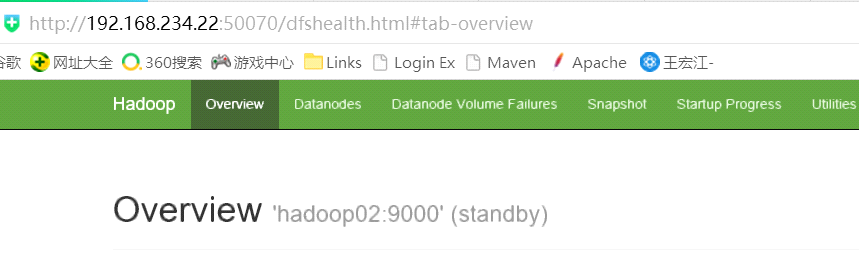
然后停掉01节点的namenode,此时返现standby的namenode变为active。
28.查看yarn的管理地址
http://192.168.234.21:8088(节点01的8088端口)
好了,集群搭建就OK了!
Hadoop2.0 HA集群搭建步骤的更多相关文章
- hadoop2.8 ha 集群搭建
简介: 最近在看hadoop的一些知识,下面搭建一个ha (高可用)的hadoop完整分布式集群: hadoop的单机,伪分布式,分布式安装 hadoop2.8 集群 1 (伪分布式搭建 hadoop ...
- hadoop HA集群搭建步骤
NameNode DataNode Zookeeper ZKFC JournalNode ResourceManager NodeManager node1 √ √ √ √ node2 ...
- Hadoop2.7.4 yarn(HA)集群搭建步骤(CentOS7)
群节点分配: Park01:Zookeeper.NameNode(active).ResourceManager(active) Park02:Zookeeper.NameNode(standby) ...
- 懒人记录 Hadoop2.7.1 集群搭建过程
懒人记录 Hadoop2.7.1 集群搭建过程 2016-07-02 13:15:45 总结 除了配置hosts ,和免密码互连之外,先在一台机器上装好所有东西 配置好之后,拷贝虚拟机,配置hosts ...
- hadoop ha集群搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 zookeeper-3.4.8 linux系统环境:Centos6.5 3台主机:master.slave01.slave02 Hado ...
- 菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章
菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章 cheungmine, 2014-10-25 0 引言 在生产环境上安装Hadoop高可用集群一直是一个需要极度耐心和体力的细致工作 ...
- Redis 5.0.5集群搭建
Redis 5.0.5集群搭建 一.概述 Redis3.0版本之后支持Cluster. 1.1.redis cluster的现状 目前redis支持的cluster特性: 1):节点自动发现 2):s ...
- 菜鸟玩云计算之十九:Hadoop 2.5.0 HA 集群安装第2章
菜鸟玩云计算之十九:Hadoop 2.5.0 HA 集群安装第2章 cheungmine, 2014-10-26 在上一章中,我们准备好了计算机和软件.本章开始部署hadoop 高可用集群. 2 部署 ...
- hadoop2.7.2集群搭建
hadoop2.7.2集群搭建 1.修改hadoop中的配置文件 进入/usr/local/src/hadoop-2.7.2/etc/hadoop目录,修改hadoop-env.sh,core-sit ...
随机推荐
- 201521123106 《Java程序设计》第5周学习总结
1. 本章学习总结 2. 书面作业 Q1. 代码阅读:Child压缩包内源代码 1.1 com.parent包中Child.java文件能否编译通过?哪句会出现错误?试改正该错误.并分析输出结果. 答 ...
- 201521123071《Java程序设计》第五周学习总结
第5周作业-继承.多态.抽象类与接口 1. 本周学习总结 1.1 思维导图总结: 1.2在本周的学习中,主要学习了以下几点: - 初步接触了接口的定义,用interface关键字定义接口,使用impl ...
- 201521123072《Java程序》第二周总结
201521123072<Java程序>第二周总结 标签(空格分隔): Java学习 [TOC] 1,本周小结 1,字符串的使用, (字符串变量作为对象来处理),所以字符串相等就要用到eq ...
- 201521123006 《java程序设计》 第12周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多流与文件相关内容. 2. 书面作业 将Student对象(属性:int id, String name,int age,doubl ...
- 201521123030 《Java程序设计》 第14周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多数据库相关内容. 2. 书面作业 1. MySQL数据库基本操作 建立数据库,将自己的姓名.学号作为一条记录插入.(截图,需出现自 ...
- java is-a、has-a和like-a、组合、聚合和继承 两组概念的区别
is a 代表的是类之间的继承关系,比如PC机是计算机,工作站也是计算机.PC机和工作站是两种不同类型的计算机,但都继承了计算机的共同特性.因此在用 Java语言实现时,应该将PC机和工作站定义成两种 ...
- 多线程面试题系列(2): CreateThread与_beginthreadex本质区别
本文将带领你与多线程作第一次亲密接触,并深入分析CreateThread与_beginthreadex的本质区别,相信阅读本文后你能轻松的使用多线程并能流畅准确的回答CreateThread与_beg ...
- SpringMVC第五篇【方法返回值、数据回显、idea下配置虚拟目录、文件上传】
Controller方法返回值 Controller方法的返回值其实就几种类型,我们来总结一下-. void String ModelAndView redirect重定向 forward转发 数据回 ...
- org.hibernate.HibernateException: No Hibernate Session bound to thread, and configuration does not a
如果出现了这个错误,看看在使用Hibernate的时候有没有在事务的环境下执行操作!
- @SuppressWarnings抑制警告
@SuppressWarnings(“XXXX”) 来抑制编译时的警告信息.参数如下: 关键字 用途 all to suppress all warnings boxing to suppress ...