阿里开源Mysql分布式中间件:Cobar
目前在从事数据库中间件的开发和维护工作,我们使用的数据库中间件就是由cobar改造而来,所以对于cobar的一些说明一看就明白了; 下面是看到的一个很不错的分析文档
这里整理了下方便自己学习使用。
Cobar是阿里巴巴研发的关系型数据的分布式处理系统(Amoeba的升级版,该产品成功替代了原先基于Oracle的数据存储方案,目前已经接管了3000+个MySQL数据库的schema,平均每天处理近50亿次的SQL执行请求。)(github上面的是源码,大家下来需要自己用maven2编译后运行、者放Eclipse/IDEA里面运行)
首先,使用Cobar的核心功能如下:
分布式:
Cobar的分布式主要是通过将表放入不同的库来实现:
1. Cobar支持将一张表水平拆分成多份分别放入不同的库来实现表的水平拆分
2. Cobar也支持将不同的表放入不同的库
3. 多数情况下,用户会将以上两种方式混合使用
这里需要强调的是,Cobar不支持将一张表,例如test表拆分成test_1, test_2, test_3.....放在同一个库中,必须将拆分后的表分别放入不同的库来实现分布式。
HA:
在用户配置了MySQL心跳的情况下,Cobar可以自动向后端连接的MySQL发送心跳,判断MySQL运行状况,一旦运行出现异常,Cobar可以自动切换到备机工作。但需要强调的是:
1. Cobar的主备切换有两种触发方式,一种是用户手动触发,一种是Cobar的心跳语句检测到异常后自动触发。那么,当心跳检测到主机异常,切换到备机,如果主机恢复了,需要用户手动切回主机工作,Cobar不会在主机恢复时自动切换回主机,除非备机的心跳也返回异常。
2. Cobar只检查MySQL主备异常,不关心主备之间的数据同步,因此用户需要在使用Cobar之前在MySQL主备上配置双向同步,详情可以参阅MySQL参考手册。
其次,我们也需要注意Cobar的功能约束:
1) 不支持跨库情况下的join、分页、排序、子查询操作。
2) SET语句执行会被忽略,事务和字符集设置除外。
3) 分库情况下,insert语句必须包含拆分字段列名。
4) 分库情况下,update语句不能更新拆分字段的值。
5) 不支持SAVEPOINT操作。
6) 暂时只支持MySQL数据节点。
7) 使用JDBC时,不支持rewriteBatchedStatements=true参数设置(默认为false)。
8) 使用JDBC时,不支持useServerPrepStmts=true参数设置(默认为false)。
9) 使用JDBC时,BLOB, BINARY, VARBINARY字段不能使用setBlob()或setBinaryStream()方法设置参数。
然后,我们来分析一下Cobar逻辑层次图:

* dataSource:数据源,表示一个具体的数据库连接,与物理存在的数据库schema一一对应。
* dataNode:数据节点,由主、备数据源,数据源的HA以及连接池共同组成,可以将一个dataNode理解为一个分库。
* table:表,包括拆分表(如tb1,tb2)和非拆分表。
* tableRule:路由规则,用于判断SQL语句被路由到具体哪些datanode执行。
* schema:cobar可以定义包含拆分表的schema(如schema1),也可以定义无拆分表的schema(如schema2)。
Cobar支持的数据库结构(schema)的层次关系具有较强的灵活性,用户可以将表自由放置不同的datanode,也可将不同的datasource放置在同一MySQL实例上。在实际应用中,我们需要通过配置文件(schema.xml)来定义我们需要的数据库服务器和表的分布策略,这点我们将在后面的安装和配置部分中介绍到。
接着,我们来介绍Cobar的安装和配置步骤:
下面我们将使用一个最简单的分库分表的例子来说明Cobar的基本用法,数据库schema如下图(该实例也可参考:Cobar产品首页)。
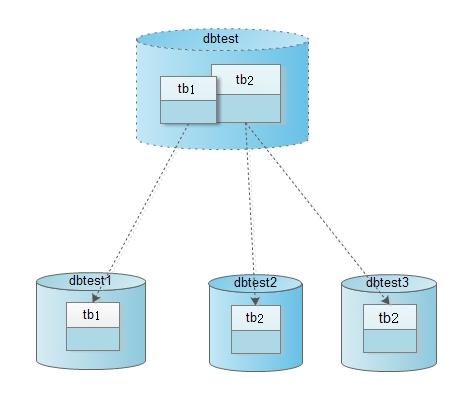
1) 系统对外提供的数据库名是dbtest,并且其中有两张表tb1和tb2。
2) tb1表的数据被映射到物理数据库dbtest1的tb1上。
3) tb2表的一部分数据被映射到物理数据库dbtest2的tb2上,另外一部分数据被映射到物理数据库dbtest3的tb2上。
1、环境准备
操作系统:Linux或者Windows (推荐在Linux环境下运行Cobar)
MySQL:http://www.mysql.com/downloads/ (推荐使用5.1以上版本)
JDK:http://www.oracle.com/technetwork/java/javase/downloads/ (推荐使用1.6以上版本)
Cobar:https://github.com/alibaba/cobar (下载tar.gz或者zip文件,特意说明下,阿里的开源全部移到github上去了,里面有很多阿里人的作品,当然包含著名的dubbo,地址是:https://github.com/alibaba/)
2、数据准备
假设本文MySQL所在服务器IP为192.168.0.1,端口为3306,用户名为test,密码为空,我们需要创建schema:dbtest1、dbtest2、dbtest3,table:tb1、tb2,SQL如下:
- #创建dbtest1
- drop database if exists dbtest1;
- create database dbtest1;
- use dbtest1;
- #在dbtest1上创建tb1
- create table tb1(
- id int not null,
- gmt datetime);
- #创建dbtest2
- drop database if exists dbtest2;
- create database dbtest2;
- use dbtest2;
- #在dbtest2上创建tb2
- create table tb2(
- id int not null,
- val varchar(256));
- #创建dbtest3
- drop database if exists dbtest3;
- create database dbtest3;
- use dbtest3;
- #在dbtest3上创建tb2
- create table tb2(
- id int not null,
- val varchar(256));
3、配置Cobar
Cobar解压之后有四个目录:
bin/:可执行文件目录,包含启动(start)、关闭(shutdown)和重启(restart)脚本
lib/:逻辑类库目录,包含了Cobar所需的jar包
conf/:配置文件目录,下面会详细介绍
logs/:运行日志目录,最主要的log有两个:程序日志(stdout.log)和控制台输出(console.log)
配置文件的用法如下:
log4j.xml:日志配置,一般来说保持默认即可
schema.xml:定义了schema逻辑层次图中的所有元素,并利用这些元素以及rule.xml中定义的规则组建分布式数据库系统
rule.xml:定义了分库分表的规则
server.xml:系统配置文件
我们在schema.xml中配置数据库结构(schema)、数据节点(dataNode)、以及数据源(dataSource)。
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE cobar:schema SYSTEM "schema.dtd">
- <cobar:schema xmlns:cobar="http://cobar.alibaba.com/">
- <!-- schema定义 -->
- <schema name="dbtest" dataNode="dnTest1">
- <table name="tb2" dataNode="dnTest2,dnTest3" rule="rule1" />
- </schema>
- <!-- 数据节点定义,数据节点由数据源和其他一些参数组织而成。-->
- <dataNode name="dnTest1">
- <property name="dataSource">
- <dataSourceRef>dsTest[0]</dataSourceRef>
- </property>
- </dataNode>
- <dataNode name="dnTest2">
- <property name="dataSource">
- <dataSourceRef>dsTest[1]</dataSourceRef>
- </property>
- </dataNode>
- <dataNode name="dnTest3">
- <property name="dataSource">
- <dataSourceRef>dsTest[2]</dataSourceRef>
- </property>
- </dataNode>
- <!-- 数据源定义,数据源是一个具体的后端数据连接的表示。-->
- <dataSource name="dsTest" type="mysql">
- <property name="location">
- <location>192.168.0.1:3306/dbtest1</location> <!--注意:替换为您的MySQL IP和Port-->
- <location>192.168.0.1:3306/dbtest2</location> <!--注意:替换为您的MySQL IP和Port-->
- <location>192.168.0.1:3306/dbtest3</location> <!--注意:替换为您的MySQL IP和Port-->
- </property>
- <property name="user">test</property> <!--注意:替换为您的MySQL用户名-->
- <property name="password">test</property> <!--注意:替换为您的MySQL密码-->
- <property name="sqlMode">STRICT_TRANS_TABLES</property>
- </dataSource>
- </cobar:schema>
我们注意到,上述配置实际上已经把图2中的数据库结构配置好了。dbtest主要映射的是dnTest1库(即192.168.0.1:3306/dbtest1库),而其中的tb2表则是按照规则rule1,被分配到dnTest2库(即192.168.0.1:3306/dbtest2库)和dnTest3库(即192.168.0.1:3306/dbtest3库)中。此外,规则rule1的定义可以在rule.xml中找到,代码如下:
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE cobar:rule SYSTEM "rule.dtd">
- <cobar:rule xmlns:cobar="http://cobar.alibaba.com/">
- <!-- 路由规则定义,定义什么表,什么字段,采用什么路由算法。-->
- <tableRule name="rule1">
- <rule>
- <columns>id</columns>
- <algorithm><![CDATA[ func1(${id})]]></algorithm>
- </rule>
- </tableRule>
- <!-- 路由函数定义,应用在路由规则的算法定义中,路由函数可以自定义扩展。-->
- <function name="func1" class="com.alibaba.cobar.route.function.PartitionByLong">
- <property name="partitionCount">2</property>
- <property name="partitionLength">512</property>
- </function>
- </cobar:rule>
结合schema.xml中的内容,我们可以看出分表的规则是,按照id字段把tb2表中的数据分配到dnTest2和dnTest3两个分区中,其中id小于512的数据会被放到dnTest2库的分区中,而其余的会被放到dnTest3库的分区中,更多路由算法可以参考《路由文档》。最后,我们来看一下server.xml的配置,代码如下。
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE cobar:server SYSTEM "server.dtd">
- <cobar:server xmlns:cobar="http://cobar.alibaba.com/">
- <!--定义Cobar用户名,密码-->
- <user name="root">
- <property name="password">passwd</property>
- <property name="schemas">dbtest</property>
- </user>
- </cobar:server>
这里的server.xml配置比较简单,只配置了本地Cobar服务的数据库结构、用户名和密码。在启动Cobar服务之后,使用用户名root和密码passwd就可以登录Cobar服务。
4、运行Cobar
启动Cobar服务很简单,运用bin目录下的start.sh即可(停止使用shutdown.sh)。启动成功之后,可以在logs目录下的stdout.log中看到如下日志:
- 10:54:19,264 INFO ===============================================
- 10:54:19,265 INFO Cobar is ready to startup ...
- 10:54:19,265 INFO Startup processors ...
- 10:54:19,443 INFO Startup connector ...
- 10:54:19,446 INFO Initialize dataNodes ...
- 10:54:19,470 INFO dnTest1:0 init success
- 10:54:19,472 INFO dnTest3:0 init success
- 10:54:19,473 INFO dnTest2:0 init success
- 10:54:19,481 INFO CobarManager is started and listening on 9066
- 10:54:19,483 INFO CobarServer is started and listening on 8066
- 10:54:19,484 INFO ===============================================
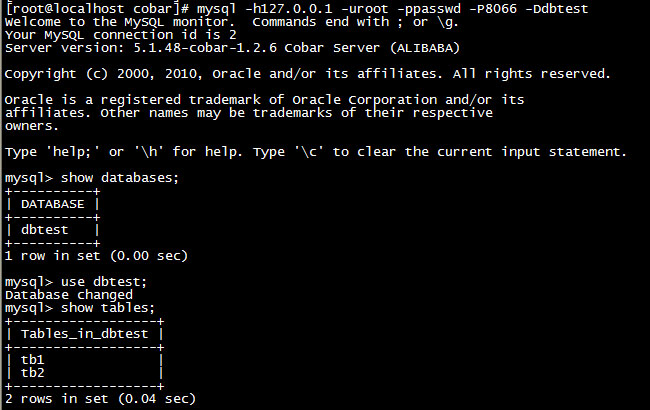
接着,我们就可以使用“mysql -h127.0.0.1 -uroot -ppasswd -P8066 -Ddbtest”命令来登录Cobar服务了,再接下来的操作就和在其他MySQL Client中一样了。比如,我们可以使用“show databases”命令查看数据库,使用“show tables”命令查看数据表,如下图:
接着,我们按照下图中的SQL指定向数据表插入测试记录。
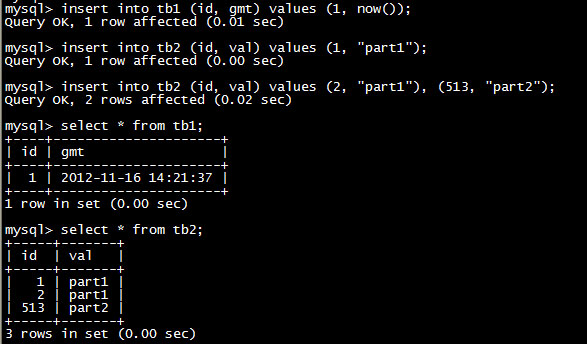
可以看到,这里的tb2中包含了id为1、2、513的3条记录。而实际上,这3条记录存储在不同的物理数据库上的,大家可以到物理库上验证一下。
至于Cobar的连接和使用方法和MySQL一样,Java程序中可以使用JDBC(建议5.1以上的版本),PHP中可以使用PDO。当然,Cobar还提供HA、集群等高级的功能,更多信息请参考其《产品文档》。此外,产品文档中还为我们提供了详细的PPT文档《Cobar原理及应用.ppt》来介绍Cobar在实际生产环境中的使用方法。
此外,特别解释一下大家可能比较关心的心跳检测问题,Cobar的心跳检测主要用在以下两个地方。
1、在配置数据节点的时候,我们需要使用心跳检测来探测数据节点的运行状况。Cobar中使用执行SQL的方式来进行探测,简单且实用。例如,我们可以把前面实例中的schema.xml中的dataNode配置成下面的样子。
- ... ...
- <!-- 数据节点定义,数据节点由数据源和其他一些参数组织而成。-->
- <dataNode name="dnTest1">
- <property name="dataSource">
- <dataSourceRef>dsTest[0]</dataSourceRef>
- </property>
- <!--Cobar与后端数据源连接池大小设置-->
- <property name="poolSize">256</property>
- <!--Cobar通过心跳来实现后端数据源HA,一旦主数据源心跳失败,便切换到备数据源上工作-->
- <!--Cobar心跳是通过向后端数据源执行一条SQL语句,根据该语句的返回结果判断数据源的运行情况-->
- <property name="heartbeat">select user()<property>
- </dataNode>
- ... ...
2、当我们需要对Cobar作集群(cluster),进行负载均衡的时候,我们也需要用到心跳机制。不过此处的配置则是在server.xml中,代码如下:
- ... ...
- <!--组建一个Cobar集群,只需在cluster配置中把所有Cobar节点(注意:包括当前Cobar自身)都配置上便可-->
- <cluster>
- <!--node名称,一个node表示一个Cobar节点,一旦配置了node,当前Cobar便会向此节点定期发起心跳,探测节点的运行情况-->
- <node name="cobar1">
- <!--Cobar节点IP, 表示当前Cobar将会向192.168.0.1上部署的Cobar发送心跳-->
- <property name="host">192.168.0.1</property>
- <!--节点的权重,用于客户端的负载均衡,用户可以通过命令查询某个节点的运行情况以及权重-->
- <property name="weight">1</property>
- </node>
- <!--当前Cobar将会向192.168.0.2上部署的Cobar发送心跳-->
- <node name="cobar2">
- <property name="host">192.168.0.2</property>
- <property name="weight">2</property>
- </node>
- <!--当前Cobar将会向192.168.0.3上部署的Cobar发送心跳-->
- <node name="cobar3">
- <property name="host">192.168.0.3</property>
- <property name="weight">3</property>
- </node>
- <!--用户还可以将Cobar节点分组,以便实现schema级别的细粒度负载均衡-->
- <group name="group12">
- <property name="nodeList">cobar1,cobar2</property>
- </group>
- <group name="group23">
- <property name="nodeList">cobar2,cobar3</property>
- </group>
- </cluster>
- ... ...
最后,简单看一下Cobar的实现原理。
首先是系统模块架构。
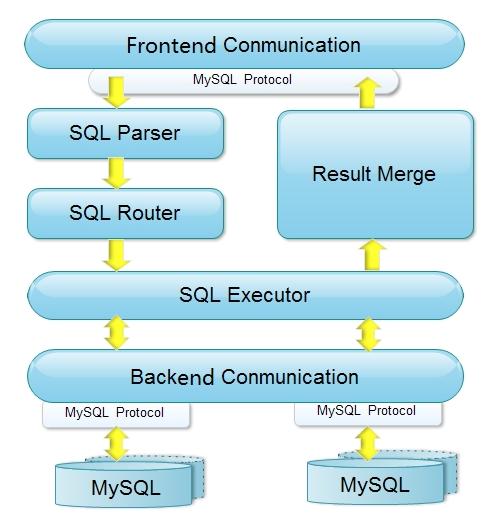
从上图中可以看到,Cobar的前、后端模块都实现了MySQL协议;当接受到SQL请求时,会依次进行解释(SQL Parser)和路由(SQL Router)工作,然后使用SQL Executor去后端模块获取数据集(后端模块还负责心跳检测功能);如果数据集来自多个数据源,Cobar则需要把数据集进行组合(Result Merge),最后返回响应。整个过程应该比较容易理解,
下面是Cobar的网络通讯模块架构。
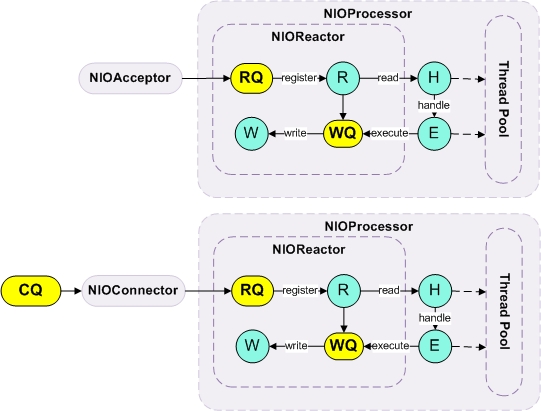
从上图中可以看出,Cobar采用了主流的Reactor设计模式来处理请求,并使用NIO进行底层的数据交换,这大大提升系统的负载能力。其中,NIOAcceptor用于处理前端请求,NIOConnector则用于管理后端的连接,NIOProcessor用于管理多线程事件处理,NIOReactor则用于完成底层的事件驱动机制,就是看起来和Mina和Netty的网络模型比较相似。如果有兴趣,大家还可以到Cobar站点的下载页面(https://github.com/alibaba/cobar)获取该项目的源码,感谢阿里人的付出!
阿里开源Mysql分布式中间件:Cobar的更多相关文章
- 转:阿里开源Mysql分布式中间件:Cobar
原文来自于:http://hualong.iteye.com/blog/2102798 这几天研究了下Cobar, Cobar是阿里巴巴研发的关系型数据的分布式处理系统(Amoeba的升级版,该产品成 ...
- MySQL分布式集群之MyCAT(转)
原文地址:http://blog.itpub.net/29510932/viewspace-1664499/ 隔了好久,才想起来更新博客,最近倒腾的数据库从Oracle换成了MySQL,研究了一段时间 ...
- MySQL分布式集群之MyCAT(一)简介【转】
隔了好久,才想起来更新博客,最近倒腾的数据库从Oracle换成了MySQL,研究了一段时间,感觉社区版的MySQL在各个方面都逊色于Oracle,Oracle真的好方便!好了,不废话,这次准备记录一些 ...
- 开源的分布式事务框架 springcloud Alibaba Seata 的搭建使用 一次把坑踩完。。。
seata的使用 1. Seata 概述 Seata 是 Simple Extensible Autonomous Transaction Architecture 的简写,由 feascar 改名而 ...
- dubbo(soa分布式)与cobar(mysql分布式)
http://www.jianshu.com/p/0dde591f21d0 (Dubbo编译不是个顺利的事) Cobar是提供关系型数据库(MySQL)分布式服务的中间件,它可以让传统的数据库得到良好 ...
- 阿里开源消息中间件RocketMQ的前世今生-转自阿里中间件
昨天,我们将分布式消息中间件RocketMQ捐赠给了开源软件基金会Apache. 孵化成功后,RocketMQ或将成为国内首个互联网中间件在Apache上的顶级项目. 消息一出,本以为群众的反应是这样 ...
- 对比7种分布式事务方案,还是偏爱阿里开源的Seata,真香!(原理+实战)
前言 这是<Spring Cloud 进阶>专栏的第六篇文章,往期文章如下: 五十五张图告诉你微服务的灵魂摆渡者Nacos究竟有多强? openFeign夺命连环9问,这谁受得了? 阿里面 ...
- 开源分布式中间件 DBLE 快速入门指南
GitHub:https://github.com/actiontech/dble 官方中文文档:https://actiontech.github.io/dble-docs-cn/ 一.环境准备 D ...
- 实战!Spring Boot 整合 阿里开源中间件 Canal 实现数据增量同步!
大家好,我是不才陈某~ 数据同步一直是一个令人头疼的问题.在业务量小,场景不多,数据量不大的情况下我们可能会选择在项目中直接写一些定时任务手动处理数据,例如从多个表将数据查出来,再汇总处理,再插入到相 ...
随机推荐
- .gitigore 相关
为什么要配置.gitigore 在我们使用git的过程当中,不是任何文件都需要commit到本地或者远程仓库的,比如一些三方库文件.那么作为一个git新手,很多人不知道如何配置.gitignore文件 ...
- 项目管理实践教程一、工欲善其事,必先利其器【Basic Tools】
今天,我们首先安装一些必须的软件,主要有下面的4个,其中软件1和2使用在服务器机上,软件3和4安装在客户端机上.另外,我们还有用到MSBuild.RoboCopy.WebDeployment等等,在下 ...
- selenium和pythond的区别
selenium和pythond的区别 天宇6169 | 浏览 137 次 2016-03-18 10:25 2016-03-18 12:24 最佳答案 selenium ide是用来录制的!大概 ...
- HDU2579--Dating with girls(2)--(DFS, 判重)
Dating with girls(2) Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Oth ...
- mapreduce 依赖组合
mport java.io.IOException;import java.util.StringTokenizer; import org.apache.hadoop.conf.Configurat ...
- 转:【WebDriver】封装GET方法来解决页面跳转不稳定的问题
在大多数测试环境中,网络或者测试服务器主机之间并不是永远不出问题的,很多时候一个客户端的一个跳转的请求会因为不稳定的网络或者偶发的其它异常hang死在那里半天不动,直到人工干预动作的出现. ...
- circularprogressbar/smoothprogressbar开源视图使用学习
github地址:https://github.com/castorflex/SmoothProgressBar 多彩圆形进度条和多彩水平进度条 colors.xml 定义变化的颜色内容,用gplus ...
- linux无法解析主机地址(could not resolve host)解决办法
修改/etc/hosts文件: ip地址 域名 例:192.30.253.120 codeload.github.com
- 转:Eclipse Debug 界面应用详解——Eclipse Debug不为人知的秘密
今天浏览csdn,发现一文详细的描述了Eclipse Debug中的各个知识点,非常详尽!特此记录. Eclipse Debug不为人知的秘密 http://blog.csdn.net/mgoann/ ...
- Regionals 2010 :: NEERC Eastern Subregional
遇到的问题:题目看错...(TAT英语渣渣没办法) 这里具体就讲一些思想和trick ①A题遇到了公式里面的单位问题. ②E题就是变量初始化忘记了 ③J题就是分情况讨论,实际上没有那么难...(题目读 ...